拿到参考资料的预训练模型,太可怕了!
NewBeeNLP公众号原创出品
公众号专栏作者 @Maple小七
北京邮电大学·模式识别与智能系统
今天和大家分享 Facebook 发表于 NeurIPS 2020 的工作,既然『闭卷考试』不理想,那不如『开卷答题』????

论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks[1]
源码:huggingface/transformers[2]
「Key insight:」 虽然以GPT-3为代表的预训练语言模型可以看作是一个隐式的大规模知识库,但这些模型在知识密集型任务上的表现依旧有不少限制和不足。本文作者在此基础上提出了RAG模型,该模型引入了文档检索模块和外部知识库来增强生成式语言模型在知识密集型任务上的表现,并避免了大规模预训练模型的一些缺点,具有很不错的应用价值和前景。
Arxiv访问不方便的同学可以后台回复『0006』便捷获取论文喔
提醒: 微信深色模式下,有些公式会看不清,建议在正常模式下(白底)阅读本文~
Introduction
近两年来,大规模通用预训练语言模型的出现刷新了整个NLP领域的模型范式(预训练+微调),实验表明预训练语言模型能够从海量数据中学习到广泛的世界知识,「这些知识以参数的形式存储在模型中,经过适当的微调就能在下游任务中取得SOTA表现,而不需要访问或检索额外的外部知识库」,比如GPT-3就可以被当作是一个参数化的大规模隐式知识库。
但是,这类通用语言模型在处理「知识密集型(knowledge-intensive)」 任务时仍旧存在一定的局限性,常常落后于面向特定任务的模型结构。所谓的知识密集型任务,就是指「如果不依靠外部知识,即使是人类也不能取得很好的表现」,因此模型容量再大,也很难记住所有知识,但是人类虽然记不住所有知识,却知道去哪里获取这些知识。
退一步讲,即使模型容量大到能够装下所有知识,「我们也很难方便地扩展或修改这些知识」,因为这些知识是分布式地存储或隐含在模型的所有参数中的,如果我们想让模型知道当前的美国总统变成拜登了,我们就必须想办法去微调模型并验证模型的确更新了相关知识。
另外,「我们很难解释模型是如何做出预测的,也很难控制模型给出的结果,无法保证模型不会给出意外的回复。」 假如GPT-3给出了带有种族歧视的回复,我们就很难去纠正模型不要生成这类回复。
综上,在当前的知识密集型任务的研究中,具有实用价值的模型基本都依赖于外部知识库,「开放域问答系统(Open-domain QA)」 是最经典也最重要的知识密集型任务之一,目前的SOTA模型基本都包含两个模块:文档检索器和文档阅读器,前者负责检索召回和查询相关的文档,后者负责从这些文档中编辑或抽取出答案片段。「这种检索-抽取范式类似于开卷考试,而单纯依靠模型参数来保存知识类似于闭卷考试」,前者当然要简单可靠得多。
Methods
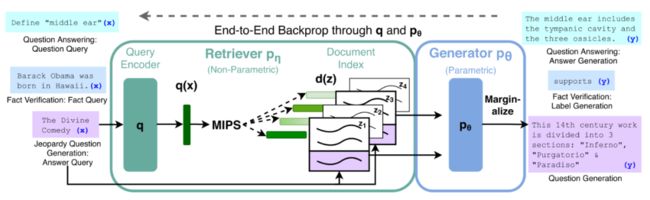
既然单纯靠参数来存储知识效果还不太好,那有没有方法利用外部知识库来增强预训练模型的表现呢?因此,人们想到可以将参数记忆(模型参数)和非参数记忆(外部数据库)结合起来,这样,知识既可以直接扩展和修改,减小训练开销,模型给出的答案也变得更容易检查和解释,同时模型也更富有灵活性。REALM: Retrieval-Augmented Language Model Pre-Training (2020)[3]就将BERT预训练模型和一个可微的检索模型结合起来实现了这一思路,但「REALM只探索了抽取式开放域问答」。而本文作者面向更难的「生成式开放域问答」,提出了基于seq2seq结构的「检索增强生成模型(retrieval-agumented generation, RAG)」。
与一般的seq2seq模型不同,RAG将输入的查询编码以后并没有直接将其送到解码器中,而是基于查询从外部知识库中检索出一组相关文档,然后将这些文档编码后和查询拼在一起输入到解码器中,生成自然语言形式的回复。这样的方式相当于为参数化的seq2seq模型赋予了检索式的非参数记忆,总结起来就是「拿到问题后先查资料再答题」,因此GPT-3和RAG虽然同为NLG模型,但RAG给出的回复是「有理有据」的,我们可以从模型检索到的文档中直接验证回复的正确性。有趣的是,作者的实验结果表明生成式的RAG在抽取式QA任务上甚至超越了一些抽取式的SOTA模型。
Model
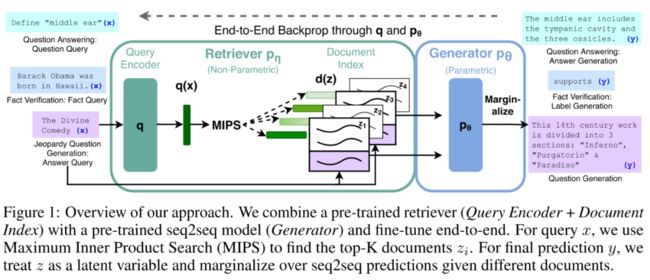
RAG的整体框架并不复杂,它包含两个部分,检索器(retriever): 和生成器(generator): 。首先输入查询句 ,检索出 个最相关的文档并编码为 来近似文档先验分布 ,然后以 和 为条件以自回归的方式生成目标句 。整个Seq2Seq结构的参数就是模型的参数知识,而外部知识库(纯文本)就是模型的非参数知识。
检索器: DPR
RAG的检索器 采用的是Dense Passage Retrieval for Open-Domain Question Answering (EMNLP 2020)[4] 提出的DPR检索模型,DPR包括一个查询编码器和一个文档编码器:
其中 和 是两个不同的BERT生成的稠密表示,计算先验概率 最高的前 个文档 是一个「最大内积搜索问题(Maximum Inner Product Search, MIPS)」,我们可以使用「近似最近邻(ANN)」 在亚线性时间复杂度内获取高精度的近似解(Billion-scale similarity search with GPUs (2017)[5])。
生成器: BART
RAG的生成器 可以是任意的encoder-decoder模型,比如T5和BART,作者采用了更先进一些的BART[6]模型。生成器的输入很简单,就是将查询表示 和文档表示 拼接起来。
Training
输入一批用于微调的训练样本 , 模型的训练目标为最小化负边际对数似然 ,需要注意的是,我们并不会提供针对某个查询,模型应该检索出哪些文档的监督信息,因为这种标签在实际应用场景下通常是不存在的。
另外,由于文档编码器的训练比较耗费时间,因为每次微调后都得重新建立MIPS索引,并且不训练它对模型最终表现影响不大,所以作者只微调了查询编码器和生成器。为了端到端地联合训练检索器和生成器,我们可以将检索到的文档看作是潜在变量 ,以概率的方式建模边际似然 , 有下面两种计算方法:
「RAG-Sequence」:生成器在生成目标句中每个词的时候使用相同的文档作为条件,每个文档相当于一个单独的潜在变量,通过top-k的方式近似边际似然:
「RAG-Token」:允许生成器在生成目标句中每个词的时候使用不同的文档作为条件,这种方式直观上更灵活,也更接近于标准的解码方式:
当任务的输出长度为1时(比如在分类任务中可以将类别看作是长度为1的序列),RAG-Sequence和RAG-Token等价。
Testing
在测试阶段,RAG-Sequence和RAG-Token以不同的方式来近似 :
「RAG-Token」:RAG-Token的解码就是标准的自回归方式,可以使用beam search寻找最优解,转移概率为
「RAG-Sequence」:RAG-Sequence的 不能分解为每个词的条件概率乘积,我们需要针对每个文档表示 运行beam search,得到一个候选集 ,为了估计候选集中每个 相对于每个文档的生成概率,作者提出了两种解码方式:Thorough Decoding和Fast Decoding,前者对那些未出现在其他文档beam seach路径的 重新计算生成概率,后者将这部分概率直接近似为 。
Experiments
在下面的实验中,模型使用的外部知识库均为2100万个Wikipedia文档,每个文档包含100个词。在训练之前,首先用文档编码器获取文档的稠密向量表示,然后利用 FAISS[7] 构建MIPS索引实现文档的快速检索。
作者在开放域问答(Open-domain QA)、生成式问答(Abstractive QA)、开放域问题生成(Open-domain QG)和事实验证(Fact Verification)这四类知识密集型任务上测试了不同模型。不同任务的特点如下:
「开放域问答」:以往的问答系统主要围绕着SQuAD数据集研究,但SQuAD本身是面向机器阅读理解(MRC)任务的,在现实生活中的应用场景和价值不如开放域问答系统广泛和明显,而开放域问答是更接近于智能搜索引擎的一种形式。
「生成式问答」:生成式问答使用的是MSMACRO数据集,MSMACRO的每个问题对应了十个搜索引擎返回的相关文档和一个位于某个文档中的完整答案片段,为了更接近于开放域问答的形式,RAG并不使用这些文档监督信息。但是MSMACRO存在不少如果不利用这些文档就无法回答的问题,比如"What is the weather in Volcano, CA?",这样的问题当然也无法在Wikipedia中找到答案,不过我们可以期待RAG可以依靠参数知识来生成相对合理的回复。
「开放域问题生成」:一般的开放域问题生成任务的问题都比较简单且短小,而危险边缘[8](Jeopardy)问题生成是一种知识密集型的问题生成任务,它的问题是关于某个实体精确的事实陈述,而答案是实体本身,比如问题"1986年,墨西哥成为第一个两次举办这项国际体育赛事的国家"的答案是"世界杯"。该项任务评估了模型对于非QA型知识密集型任务的生成能力,评估指标为Q-BLEU-1分数,比起BLEU,Q-BLEU为实体赋予了更高的权重,因此在该任务上与人类评价的相关性更高。
「事实验证」:事实验证任务要求对一个自然语言陈述是否被维基百科支持、驳斥或无法验证进行分类,同样,作者没有使用模型应该检索哪些文档的监督信息,该任务以知识密集型分类任务的形式测试了RAG的表现。
Results
在开放域问答任务中,作者对比了RAG和一些流行的抽取式QA模型,包括依赖于非参数知识(Open Book)的REALM和DPR,以及仅依靠参数知识(Closed Book)的生成式模型T5,评估指标为EM分数。在其余三项任务中,作者还对比测试了BART模型和利用了文档监督信息的SOTA模型。
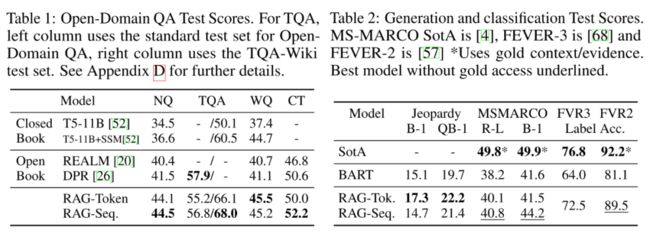
下面是一些主要结论:
总体来说,Open Book范式比Closed Book范式的表现好不少,因此引入外部知识库对开放域问答任务来说还是很重要的,而「RAG很好地将seq2seq模型的灵活性和检索模型的高效性结合了起来」,并且不像REALM,RAG的训练成本更小,另外RAG的检索器虽然是用DPR的检索器初始化的,但原始的DPR模型后续采用了BERT来对文档做重排和答案抽取,而RAG表明这两者是不必要的。
虽然可以直接从文档中抽取答案片段,但直接生成答案有一些额外的好处,比如有些文档并不直接包含整个答案,但包含答案的线索,「这些线索就能帮助模型生成更正确的答案」,而这对抽取式模型来说是做不到的。在一些极端情况下,比如被检索到的文档全都不包含正确答案,RAG也能生成相对合理的答案,此时RAG借助的就是生成器中存储的参数知识,而REALM这类抽取式QA模型就无法回答这些问题。在NQ数据集中,RAG对于这类问题的正确率是11.8%,而抽取式模型的正确率是0%。
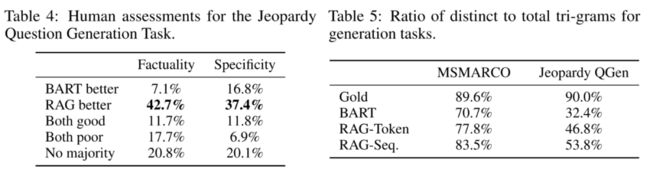
作者对BART和RAG模型在问题生成任务上的表现进行了人工评估,如左图所示,评估结果表明RAG生成的问题更符合事实(factual),也更具体(specific),而右图计算了不同的tri-grams与所有tri-grams的比值,该比值能够反映生成的多样性,计算结果和样本观察均表明RAG的生成结果是更多样化的。

另外,我们可以发现在问题生成任务中RAG-Token的表现比RAG-Sequence更好,这实际上得益于前者在生成时可以关注到多个文档,从而生成信息更丰富的问题,下面的一个例子就表明了RAG-Token在生成不同的单词时,不同文档的后验概率是不同的。有趣的是,在生成某个实体的第一个词之后,该实体对应的文档的后验概率就回归正常了,这表明「生成器依靠参数知识完全有能力补全后续部分,文档信息仅仅起到了提示和引导的作用」,因此整个RAG模型主要依靠的还是参数知识,而在生成实体时非参数知识才会起到作用。

Ablation
为了评估文档检索机制的有效性,作者对比了基于BM25的检索器和冻结了检索器的模型。实验结果表明训练检索器对所有生成任务都是有帮助的,但在事实验证任务上BM25表现却是最好的,这可能是因为该任务主要以实体为中心,因此非常适合基于单词重叠的BM25检索器,所以数据集的特征对于模型的选择还是很重要的。
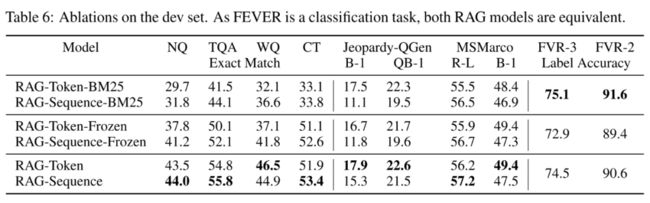
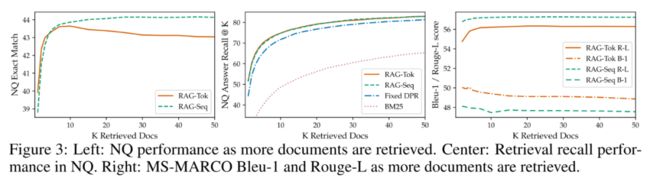
检索文档的数量 会对模型表现产生一定影响,如下图所示,对于RAG-Token来说, 值过大会带来一些负面影响,同时会导致Rouge-L分数提升,但BLEU-1分数降低,而RAG-Sequence就不存在这些问题。
Discussion
除了RAG的检索式增强范式,引入外部知识来增强模型的方式还有很多,比如在预训练模型还没有流行起来的2017年,风靡一时的记忆网络(Memory Networks)就在QA任务上得到了不少运用。
但这些网络都需要在特定任务上进行额外的训练才能使用,这个过程可以类比于对外部知识做一个"小抄",如果训练不当,质量也许还不如"先检索再理解"的方式好,而RAG模型也正表明了「靠预训练和预加载就可以以很小的代价获取知识的高质量表示」。
同时,「这样的方式也更具有可读性和可解释性,因为知识是以纯文本而不是分布式表示的形式存放的,因此可以随时更新文档内容而不需要重新训练任何模块」,这样的能力在时事问答场景下(比如美国现任总统是谁?)是很有价值的。
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
专辑 | NLP论文解读
专辑 | 情感分析
整理不易,还望给个在看!