从rocketmq到kafka:集群、一致性与重平衡
- rabbitmq的消息可靠性
- rabbitmq-幂等引出的性能分析
- 从rabbitmq到rocketmq
经过上面三篇文章的学习,本篇再来学习 kafka 就会比较简单,概念都是相通的,关键是要联系和对比。
那么直接进入正题,按照同样的思路,首先看看单个 Broker 内部逻辑结构。图片来源
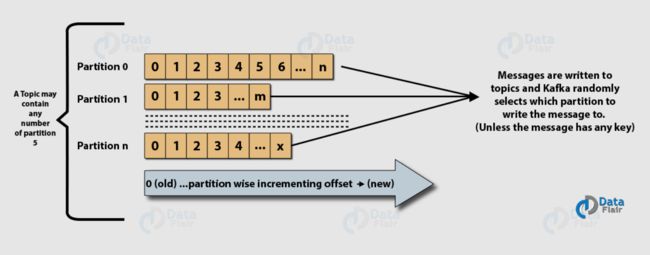
图中的 partition 看成是 rocketmq 中的队列,只不过 kafka 中叫做分区。主题、消费者组、消费者、生产者这些概念还是一样的。
顺便说一句,kafka 的分区叫法也是很合理的。本来每个主题都是由N个分区(队列)组成的,而分区(队列)又可以看成是消息存储的地方(或者说从逻辑上来看是的)。
那么,kafka 集群架构是怎么样的呢?还是看图,图片来源

同样对比 rocketmq,最大的区别就是 rocketmq 中是 NameServer,而 kafka 则是 zookeeper。为什么 kafka 没有选择自己实现类似 NameServer 的组件呢?猜测原因是受了 unix 哲学影响,举个例子:
ls t.txt | grep 'abc' | wc -l
该条指令就是统计文件中总共有几行包含 abc 字符串,其中 ls、grep、wc 三种指令都是不同的职责,但是通过管道组合在一起,就实现了特殊的功能。
那么换句话说,kafka 和 zookeeper 的关系就像这些指令一样,组合在一起实现具体系统。
但是分久必合合久必分,现在 kafka 也在准备全面脱离对 zookeeper 的依赖。kafka 和 zookeeper 的这种耦合和分离,在一定程度上也体现了一种哲学的思辨。
基于此,我们来比较一下三个消息队列在构建集群上的区别:
-
rabbitmq:节点通信的集群构建方式
-
kafka、rocketmq:基于注册中心的集群构建方式
之所以这样写,其实这就是分布式系统中两种不同的集群构建模式,我们再补充一种:
- 第三种:基于负载均衡的集群构建方式
假设集群机器是 s1、s2,那么构建集群的目的是对外提供服务的同时,提高了系统的可用性,并且分摊了负载。既然集群是对外用的,那么客户端 c1 到底该如何正确的访问到具体的服务呢?
- 第一种就是s1、s2属于无状态服务,访问任何一台均可得到正确结果。那么就是负载均衡方式来实现,在 前级增加 LB ,代理 s1、s2的请求流量。
- 第二种就是 s1、s2属于有状态服务,比如这里的 rabbitmq(因为每个 Broker 上都存储了消息数据,且不同 broker 上存在的队列可能不同)。所以当c1通过s1访问队列a时,假如队列a在 s2上,那么必然需要请求转发。要么s1将请求自动转到 s2,要么c1 重新访问s2。
- 第三种就是利用注册中心,实现客户端通过注册中心获取到集群信息后,可以根据需要直接去目标机器获取正确的服务。
三种方式,最难的肯定是第二种。关于这一点,可以参见 rabbitmq 的这篇博客 quorum-queues-local-delivery 重点针对如何减少不必要的请求路由,对 quorum 队列进行了探讨。
再来看看kafka集群中,关于数据一致性的处理。这一点上,和 rabbitmq 的 quorum 队列比较相似。kafka 也是对 分区 层面进行的数据一致性处理。
但是 kafka 没有采用 raft 算法实现,而是基于微软的 pacificA 协议实现。可能是因为 raft(2013年)落地的比 kafka 晚,而且 raft 要求至少半数以上存活才可以,并且无法灵活指定同步副本数。
所以 kafka 引入了新的概念:ISR,也就是和领导者数据是同步的节点的集合(包括领导者本身)。这里领导者和追随者的数据同步与否,是根据 replica.lag.time.max.ms 参数设定的时间间隔来判断。超过此间隔的,就不会列入到 ISR 集合中。
当生产者写入消息时,领导者节点需要根据配置的参数(acks=0,1all)来判断,当该消息同步到n个 ISR 中的节点后,才算写入成功。那么 n 到底如何确定?
- 当 acks=0,自然不用说,无法同步到任何节点。
- acks=1,只要领导者节点存储了即可。
- acks=all,这时,另一个参数就登场了
这个参数就是 min.insync.replicas = m ,当配置了该参数后,n的范围就是:
m <= n <= ISR 中节点的数量。
到这里,可以看到,同步数量是可以灵活调整的,是不是很像我们之前提到的 NWR 机制?
现在,我们可以再分析一下单个 Broker 内消息刷盘机制了。因为有了上述 NWR 机制的保证,kafka 只保留了消息写入到操作系统的 PageCache中,后面就依靠操作系统的机制来落盘。
Rebalance:重平衡
基于上面的分析,我们对 kafka 的内部原理和集群架构有了更多的理解。最后,再来看一下 kafka 中的 Rebalance 机制。重平衡说的是某个主题下面的分区重新分配给一个消费者组中的消费者。
这里就可以类比 2PC 协议的处理过程。首先是每个主题都有一个协调者,并且消费者和协调者之间存在定时的心跳。其次,两阶段为:
- joinGroup请求:请求入组
- syncGroup请求:分配队列结果
假设是新增消费者的场景,新增消费者C3,那么 C3 主动向协调者发起 joinGroup 请求,协调者就知道该启动重平衡了。协调者会在响应其他消费者的心跳中,携带发起重平衡的通知。这样,当其他消费者收到心跳响应后,就会主动发起 joinGroup 请求。
joinGroup 请求中携带的是该消费者的订阅信息。协调者会认为第一个发起 joinGroup 请求的是领导者,也即负责计算分配结果的。对于普通节点的请求,会直接返回入组成功。对于领导者的 joinGroup 请求,会在收集到所有节点入组信息后,统一返回给领导者。
那么领导者会对这些信息做判断,并按规则计算分配结果。与此同时各节点可以发起 syncGroup 请求,等到领导者的 syncGroup 请求发到协调者以后,协调者会根据分配结果,在各节点的 syncGroup 响应中携带其被分配的队列信息。这样就实现了分区的负载均衡。
不过,要特意提醒的一点是,重平衡协议在 kafka 中还有其他用途,是比较通用的分布式任务分配算法。
本篇就到这里,主要还是着眼于从之前学过的理论知识角度来看待 kafka。下篇文章,我们对 rabbitmq、rocketmq、kafka、pulsar 做一个对比总结。