【爬虫】爬取简书某ID所有文章并保存为pdf
编辑 / 昱良

1
目 标 场 景
现如今,我们处于一个信息碎片化的信息时代,遇到好的文章都有随手收藏的习惯。但过一段时间,当你想要重新查看这篇文章的时候,发现文章已经被移除或莫名其妙地消失了。
如果当时能将这些文章以 pdf 格式保存到本地,待空闲的时候慢慢地看,就不用担心这个问题了。
本文的目标是利用 Google 推出的「puppeteer」,配合无头浏览器爬取某位大佬在简书上发布的所有文章,并对页内元素进行优化样式后,以「pdf」格式保存下载到本地。
2
准 备 工 作
和前面爬虫方式不一样,这次的爬虫是在「Node.js」环境下执行的,所以需要提前安装好 node js。
然后通过 npm 安装「puppeteer」模块。
npm i puppeteer
我这里使用 Chrome 的无头浏览器模式,所以需要提前下载好「chromium」放在本地。
3
分 析 思 路
为了便于观察,首先我们利用 puppeteer 以有头模式启动浏览器。
const browser = await puppeteer.launch({
// 设置false可以看到页面的执行步骤
headless: false,
});
再设置好浏览器的大小,然后打开文章列表页面。
BASE_URL = https://www.jianshu.com ;
//文章列表地址
HOME_URL = `${BASE_URL}/u/f46becd1ed83`;
const viewport_size = {
width: 0,
height: 0,
};
const page = await browser.newPage();
//设置浏览器的宽、高
page.setViewport(viewport_size);
//打开文章主页
await page.goto(HOME_URL);
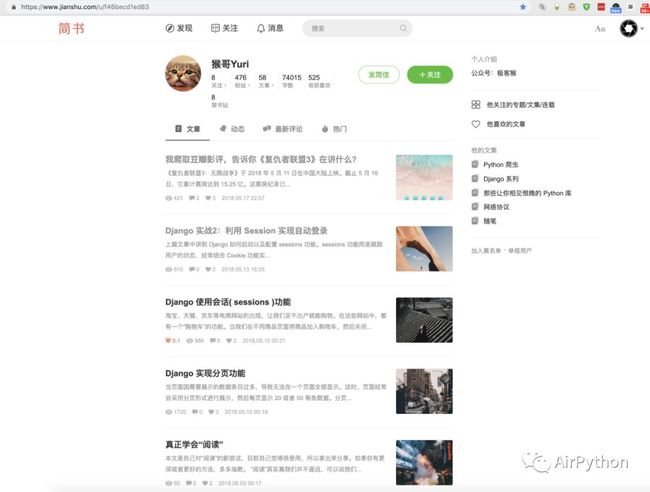
由于默认只显示第一页的文章,后面的文章需要多次从下到上的滑动才能加载出来。
这里需要定义一个函数不停的作滑动操作,直到滑动到最底部,待页面所有元素加载完成,才停止滑动。
function autoScroll(page) {
return page.evaluate(() => {
return new Promise((resolve, reject) => {
var totalHeight = 0;
var distance = 100;
var timer = setInterval(() => {
console.log( 执行间断函数 );
var scrollHeight = document.body.scrollHeight;
window.scrollBy(0, distance);
totalHeight += distance;
if (totalHeight >= scrollHeight) {
console.log( 滑动到底 );
clearInterval(timer);
resolve();
}
}, 100);
})
});
}
待所有的文章都加载出来后,就可以通过「eval」函数获取文章元素,然后再通过 css 选择器获取到文章标题和页面地址。
const articles = await page.$eval( .note-list , articles_element => {
const article_elements = articles_element.querySelectorAll( li );
const articleElementArray = Array.prototype.slice.call(article_elements);
return articleElementArray.map(item => {
const a_element = item.querySelector( .title );
return {
href: a_element.getAttribute( href ),
title: a_element.innerHTML.trim(),
};
});
});

获取到所有文章的链接地址之后,就可以通过遍历列表去打开每一篇文章。
for (let article of articles) {
const articlePage = await browser.newPage();
articlePage.setViewport(viewport_size);
articlePage.goto(`${BASE_URL}${article.href}`, {
waitUntil: networkidle2
});
articlePage.waitForSelector( .post );
console.log( 文章详情页面加载完成 );
}
等文章详情页面加载完全后,同样需要滑动页面到最底部,保证当前文章的文字信息、图片都加载完全。

为了保证最后保存的页面的美观性,需要利用「CSS样式」隐藏包含网站顶部、底部、评论、导航条等多余的元素。
await articlePage.$eval( body , body => {
body.querySelector( .navbar ).style.display = none ;
body.querySelector( #note-fixed-ad-container ).style.display = none ;
body.querySelector( .note-bottom ).style.display = none ;
body.querySelector( .side-tool ).style.display = none ;
// body.querySelector( .author ).style.display = none ;
body.querySelector( .meta-bottom ).style.display = none ;
body.querySelector( #web-note-ad-1 ).style.display = none ;
body.querySelector( #comment-list ).style.display = none ;
body.querySelector( .follow-detail ).style.display = none ;
body.querySelector( .show-foot ).style.display = none ;
Promise.resolve();
});
最后利用「pdf」函数把当前页面保存为 pdf 格式的文件。
await page.emulateMedia( screen );
await articlePage.pdf({
path: fileFullPath,
format: A4
});
需要注意的是,为了保证上面的函数正常的执行,需要修改浏览器打开的方式为无头模式,即:
const browser = await puppeteer.launch({
headless: true,
});
4
结 果 结 论
通过 node 命令就可以执行这个 js 文件。
node jian_shu.js
由于使用的是无头浏览器执行的,这里除了控制台能显示日志信息,没有任何操作。
待程序执行完毕之后,发现所有的文章都以 pdf 的形式保存到本地了。

全部源码点击文末『阅读原文』即可下载
推荐阅读

【热点】印度年轻人跟中国年轻人有什么不同
【实战】使用 Python 分析 14 亿条数据
【Python】13 个适合『中级开发者』练手的项目
何恺明:从高考状元到CV领域年轻翘楚,靠“去雾算法”成为“CVPR最佳论文”首位华人得主
【项目】用 Python 一键分析你的上网行为, 看是在认真工作还是摸鱼
