李宏毅DLHLP.09.Voice Conversion.1/2. Feature Disentangle
文章目录
- 介绍
- 什么是VC
-
- 应用
- 实操
- 分类
- Feature Disentangle
-
- Using Speaker Information
- Pre-training Encoders
- Content Encoder
- Adversarial Training
- Designing network architecture
-
- 实作结果
介绍
本门课程是2020年李宏毅老师新课:Deep Learning for Human Language Processing(深度学习与人类语言处理)
课程网站
B站视频
公式输入请参考:在线Latex公式
什么是VC
输入一段声音,输出另外一段声音
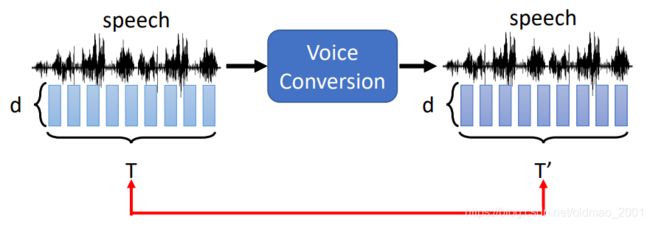
通常情况:
What is preserved?Content
What is changed?Many different aspects …
应用
常见应用就是转换说话的人
• The same sentence said by different people has different effect.
• Deep Fake: Fool humans / speaker verification system
• One simple way to achieve personalized TTS
• Singing
还有
• Emotion:说话style转换,轻柔转愤怒。
• Normal-to-Lombard:Lombard就是人在嘈杂环境下说话的声音和语调,可以想象戴耳机开很大声,然后和身边的人讲话。
• Whisper-to-Normal
• Singers vocal technique conversion加唱歌的技巧,例如:lip thrill (弹唇) or vibrato (颤音)
• Improving the speech intelligibility增加语音的可理解性
surgical patients who have had parts of their articulators removed.例如有些人先天口齿不清,可以用AI增加语音的可理解性。
• Accent conversion口音转换,例如印度英语
voice quality of a non-native speaker and the pronunciation patterns of a native speaker
Can be used in language learning
还可以用做Data Augmentation

去噪和加噪
实操
在实际过程中,为了简化,通常假设输入和输出sequence长度是一样的。
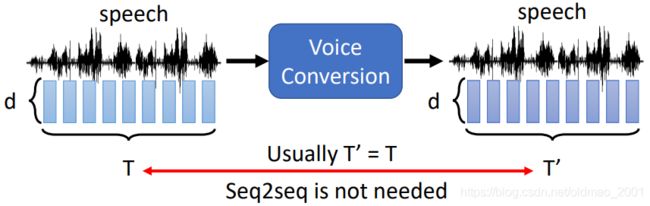
此外,voice conversion的输出是acoustic feature sequence,这个是一串向量,这串向量往往不能够直接转为声音信号,我们需要另外一个模块:Vocoder

常见的方法有:
• Rule-based: Griffin-Lim algorithm
• Deep Learning: WaveNet
Vocoder这块还比较复杂,后面会专门另外的课程来讲,这里不深入,我们只需要知道有这么个东西,通常还用在: VC, TTS, Speech Separation, etc.
分类
根据训练数据,我们可以把语音转化分为两大类:
1.成对数据Parallel Data:A和B用户都说同样的句子。那么就是吃左边的数据,希望模型吐出右边的数据。

但是这样的数据比较难收集,解决方法是:
• Model Pre-training[Huang, et al., arXiv’19],先预训练模型后再用很少的数据进行fine-tuning
• Synthesized data![Biadsy, et al., INTERSPEECH’19] ,如果有一堆A的语音数据,而且知道这些语音对应的文字,那么用语音合成的方法(用机器读一遍)来生成B的数据
2.非成对数据Unparallel Data,是常见的数据,在这类数据上,借鉴了图像上的transfer learning的方法

• This is “audio style transfer”
• Borrowing techniques from image style transfer
那么做法也有两种:
一个是Feature Disentangle:声音里面包含很多信息,如下图:内容的信息、语者的信息、背景杂音信息等。我们现在想把这些信息分离开来,然后单独把语者的信息替换掉,就完成了VC。换句话说,如果能把口音的信息提取出来并替换就可以做到口音转换,如果能把情绪的部分提取出来就可以做到情绪转换。
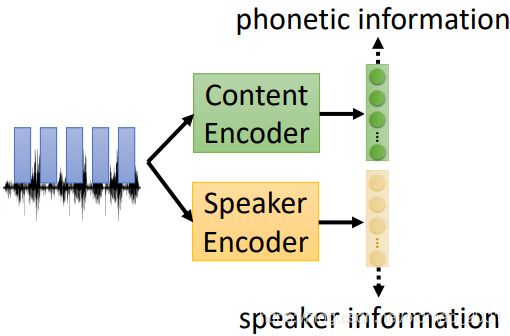
这节主要就讲Feature Disentangle。
另外一个方法是:Direct Transformation
下面以替换语者信息为例来看Feature Disentangle
Feature Disentangle
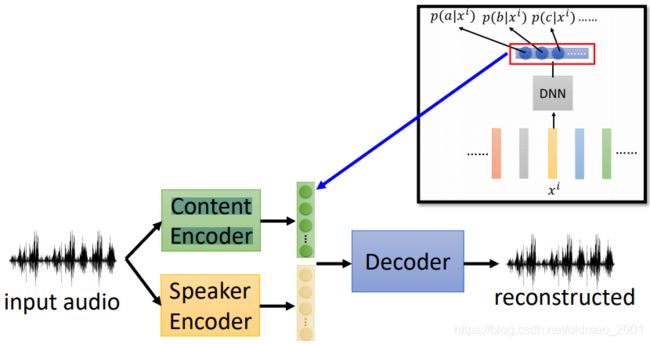
有两个encoder,分别可以将语言信号中的内容C和语者A特征提取出来,将两个特征合起来后可以用一个Decoder合成为语者A说内容C的语音信号。
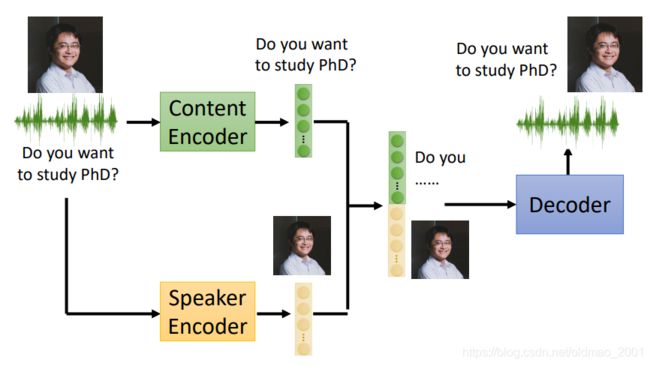
模型训练好后,当我们需要转换语者信息的时候就可以将语者B说的话丢到语者的encoder中,结合之前的内容C的特征,经过Decoder就可以得到最后的结果。
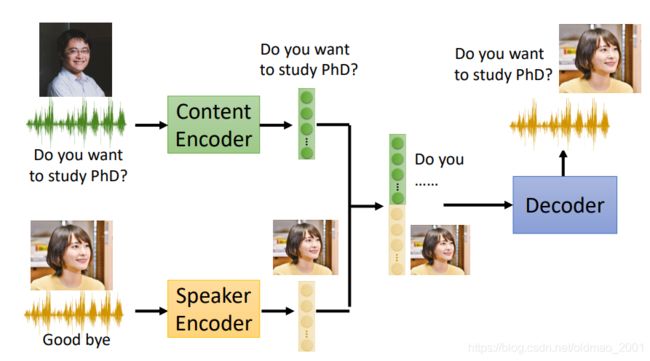
这里面涉及的模型原理和AE比较像,但是用到trick要更加复杂一些。
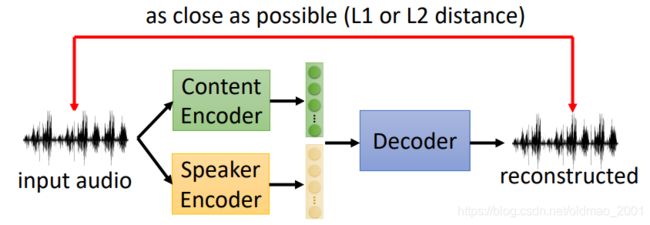
How can you make one encoder for content and one for speaker?
现在的问题是如何让两个encoder去分别提取我们指定的信息?
Using Speaker Information
第一种做法是不去训练两个Encoder,假设我们现在已经知道每句话都是谁说的,那么我们就可以用一个独热编码来代表每个语者。

然后用独热编码替代原来的speaker encoder,丢到Decoder中,还原回原来的声音信号。由于我们已经额外提供了语者的信息,因此,Content Encoder和Decoder经过训练后就不会涉及语者信息。
这样有问题: difficult to consider new speakers. 对于训练数据中没有的语者Z,就无法转换为他的声音。
Pre-training Encoders
第二种方法是预先训练好Speaker Encoder
这个Speaker Encoder 吃一段语音信号,可以输出得到这个语音信息的语者的向量表示,这个方法也叫:Speaker embedding,通常有:i-vector, d-vector, x-vector …,这里不深入,后面有专题讲语者验证再讲。
Content Encoder
对于Content Encoder而言,可以直接将一个语音识别系统直接丢到这里,语音识别系统一般都是忽略语音之外的信息。但是语音识别系统输出是文字,不是向量,没有办法接到下面的Decoder中。这里如果是用DL的语音识别,那么就可以用中间输出的每个state的概率来作为Content Encoder的输出。
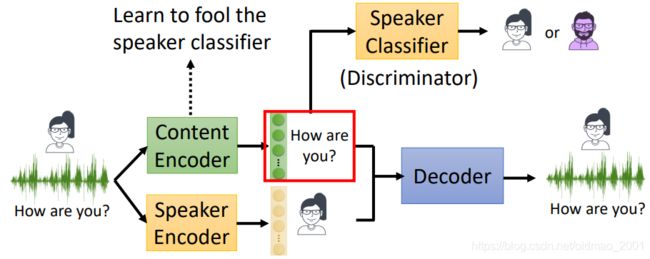
Adversarial Training
第三种方法是Adversarial Training,用GAN的思路来训练模型,加入一个classifier,然后Speaker classifier and encoder are learned iteratively
Designing network architecture
借鉴图像上用过的技术,修改网络构架,使得每个Encoder可以学习到指定特征。

具体做法就是在Content Encoder加一个 instance normalization,用来remove speaker information。下面解释其原理:
先有一段声音信号:

然后经过一组CNN的1D的filter,得到一组数值:

然后再经过另外一组1D的filter,得到另外一组数值,以此类推,若干组后,每一小段声音信号都对应到一个vector:
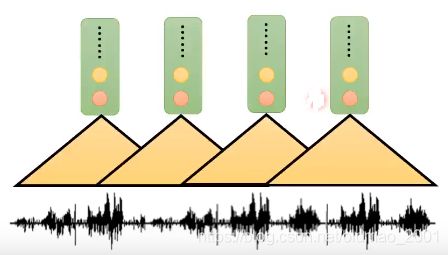
instance normalization就作用在这些vector上:
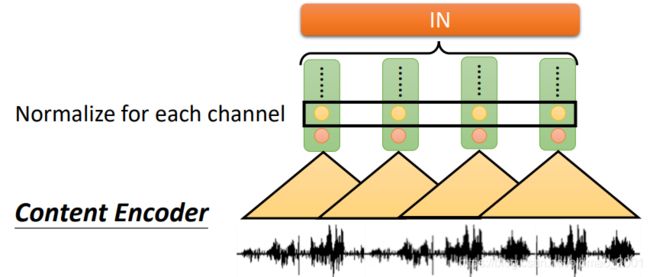
instance normalization会作用在这些vector相同的维度上,把这些维度上的mean和variance处理(前者减,后者除)后变成:
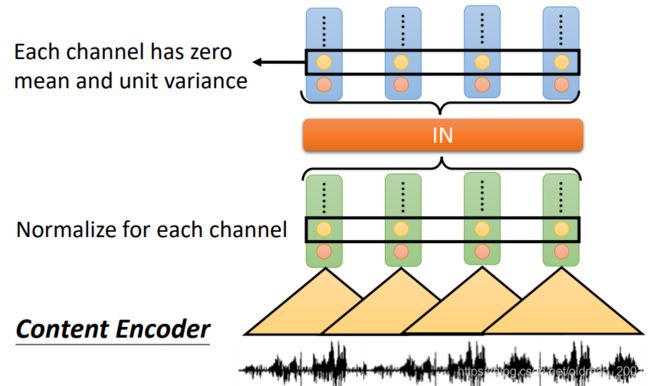
最后是mean为0,variance为1。
这样为什么能去掉语者特征?因为每个vector的维度(就是上图中的黑色矩形框内的东西)都代表一种CNN抽取出来的某个特征,假设图中矩形框是性别特征,那么男生低频特征会明显,女生高频特征会明显,如果经过instance normalization后,就相当于抹去了这些特征。
然后把模型再加入AdaIN(adaptive instance normalization),这个only influence speaker information,下面来看其原理:
首先,Decoder也有instance normalization,对CNN输出的vector每个维度做normalization,去掉语者的信息,去掉语者的信息后又如何输出语者的信息?

这些信息要从speaker encoder这里提取这些信息。speaker encoder的输出通过两个transform后分别得到 γ , β \gamma,\beta γ,β这两个变量:
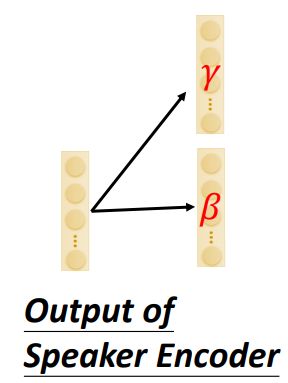
这两个变量会去影响上图中Decoder的输出(做了instance normalization之后): z 1 , z 2 , z 3 , z 4 z_1,z_2,z_3,z_4 z1,z2,z3,z4,影响的公式如下:
z i ′ = γ ⊙ z i + β z_i'=\gamma\odot z_i+\beta zi′=γ⊙zi+β
可以看到这个影响是对所有的vector都有,是全局的。

这里的IN加上 γ , β \gamma,\beta γ,β的影响两块合起来就是AdaIN。3
最后整个模型按AE进行训练即可。
实作结果
对于content encoder:
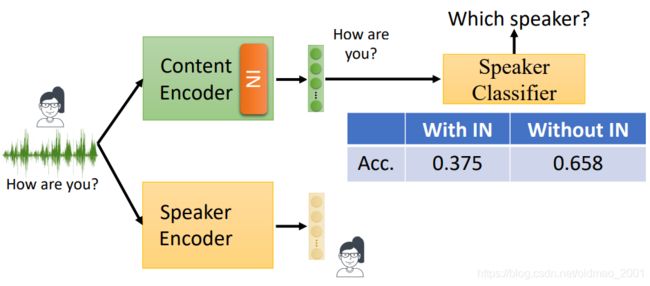
从上图可以看到加入IN后,speaker classifier的正确率降低了,说明IN效果不错,过滤掉了语者信息,导致正确率降低。
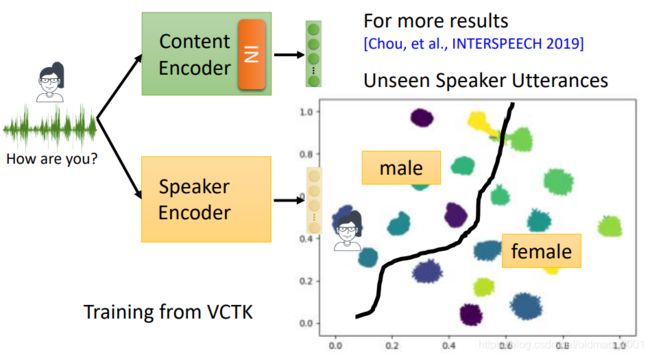
对于speaker encoder:
输入测试语音数据,会得到分类非常好的结果,每个人,性别都有分开。