深入理解HTTP协议
目标:
- 掌握 http 原理,重点掌握 http Request & Response 格式
- 掌握 http 中相关重点知识,如请求方法,属性,状态码等
- 使用 java socket 编写简易版本 http server , 深刻理解原理
- 掌握session和cookie
1、HTTP原理
理解为何要有应用层?
我们已经学过 TCP/IP , 已经知道目前数据能从客户端进程经过路径选择跨网络传送到服务器端进程[ IP+Port ],可是,仅仅把数据从A点传送到B点就完了吗?这就好比,在淘宝上买了一部手机,卖家[ 客户端 ]把手机通过顺丰[ 传送+路径选择 ] 送到买家 [ 服务器 ] 手里就完了吗?当然不是,买家还要使用这款产品,还要在使用之后,给卖家打分评论。所以,我们把数据从A端传送到B端, TCP/IP 解决的是顺丰的功能,而两端还要对数据进行加工处理或者使用,所以我们还需要一层协议,不关心通信细节,关心应用细节!
这层协议叫做应用层协议。而应用是有不同的场景的,所以应用层协议是有不同种类的,其中经典协议之一的HTTP就是其中的佼佼者。那么, Http 是解决什么应用场景呢?
早期用户,上网使用浏览器来进行上网,而用浏览器上网阅读信息,最常见的是查看各种网页【其实也是文件数据,不过是一系列的 html 文档,当然还有其他资源如图片, css , js 等】,而要把网页文件信息通过网络传送到客户端,或者把用户数据上传到服务器,就需要 Http 协议【当然,http作用不限于此】
我们用浏览器打开一个网页,基本都是基于HTTP 协议来传输的。
比如我们访问百度:
https://www.baidu.com/
访问网站使用的协议类型就是HTTPS(https是基于http 实现的,只不过在 http 基础上引入一个加密层)
http vs https
在这里 http 和 https 都是应用层协议,应用层协议很多时候都需要程序员来手动设定(自己指定协议),http 是大佬们已经定义好的现成的协议。
http 协议的优点:http 协议简单,支持的扩展能力很强,这样程序员就可以基于 http 进行自定制,节省开发成本。http 协议是基于 TCP 来实现的。
认识 url
平时我们俗称的 “网址” 其实就是说的 URL

注意服务器的地址一般是隐藏了端口号的,没有显示出来一般都是默认端口号,http(80)、https(443)
- url 中对应的path(文件路径)不同的时候,获取到的页面也是不同的
- url 中的服务器ip (域名)来确定一个服务器
- url 中的服务器端口来确定这个主机上的哪个进程
- url 中的path来确定这个进程中所管理的那个资源、文件
- 最终http 请求得到的“网页” 本质上是一个文件
https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=baidu&wd=%E7%A1%AE%E5%AE%9E%E5%BC%BA%E5%A4%A7%E7%9A%84&oq=%25E5%25BE%2597%25E5%25BE%2597&rsv_pq=9726ade400008505&rsv_t=bb1bRKFfe31d0v1TWsZop7f4HUKpykwIGV0E4Ya%2B0UMwaZHQkU3rn9lKF1w&rqlang=cn&rsv_enter=1&rsv_dl=tb&rsv_sug3=3&rsv_sug1=4&rsv_sug7=100&rsv_sug2=0&rsv_btype=t&inputT=3318&rsv_sug4=5016
我们查询字符串中,使用&符号把这些内容区分成若干个键值对,每个键值对的键和值之间使用 = 分割。
在这里键值对的具体含义外人是不清楚的,只有实现内部程序的程序员才清楚,当然不同的服务器上使用的查询字符串中的键值对内容也是不相同的。
urlencode和urldecode
像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.
比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义.转义的规则如下:将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY
格式。

就如// 被转义了
urldecode就是urlencode的逆过程;
HTTP的方法

最初设计HTTP的时候是这样的,在现在很少按照这样来使用。
最常用的 HTTP 方法是GET和 POST
GET 和 POST 的区别(面试)
很多资料写的是GET 一般把数据放到 url 中,POST 一般把数据放到body 中。其实也不是很科学的,理论上完全可以把 POST 数据放在url 中,把 GET 的数据放在body 中。
1、GET 用于从服务器获取资源,POST用于给服务器提交数据(现在很少严格遵守这样的设计初衷,两者都可以用来获取资源或者来提交数据)
2、GET 传输的数据量上限较小(URL长度有限),POST传输数据的数据量较大(在20 年前这句话说法是对的,之前的 url 最长也就是1k-2k ,但是现在的url 可能会很长,长到甚至可能有几 M )
3、POST 比 GET 更加安全(POST 的安全其实是掩耳盗铃,只是把密码啥的放在body 中,这个密码只是不在 url 地址栏中,这样懂编程的人随便抓个包就可以看到)
HTTP的状态码

最常见的状态码, 比如 200(OK), 404(Not Found), 403(Forbidden), 302(Redirect, 重定向), 504(Bad Gateway)
HTTP常见Header
- Content-Type: 数据类型(text/html等)
- Content-Length: Body的长度
- Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
- User-Agent: 声明用户的操作系统和浏览器版本信息;
- referer: 当前页面是从哪个页面跳转过来的;(有些请求是没有 referer的,例如直接在浏览器地址栏里输入 url 或者点击收藏的网站)
- location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
- Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
cookie
HTTP 的特点是无状态(两次 HTTP 请求之间是没有任何关联的),那么从业务上建立起这样的关联联系,就需要使用到 cookie。它相当于保存在浏览器中的一个字符串,这个字符串是通过服务器返回响应中的 Set-Cookie 字段中来的,后续在访问该服务器,请求就会自己带上 Cookie字段。
以登录为例,一次登录过程中会涉及两次请求:验证用户名和密码,验证成功后,需要跳转到主页。
第一次交互:
请求:(没有Cookie 字段)
响应:通过服务器返回响应中的 Set-Cookie 字段
第二次交互:
请求:(重定向到首页)
在这里就是借助 Cookie 就可以把多个请求 关联到一起(Cookie 中的内容如果是一致,这几个请求就是有关联的,就好比识别用户的身份信息,你登录一次之后,此时在访问该网站的其他页面就不在需要重新登录,但是为了安全在设计的时候 Cookie是会隔一段时间会刷新的)
浏览器 是按照域名来区分 Cookie的,百度的 Cookie 和搜狗的 Cookie 相互独立,不冲突的。
HTTP协议格式

HTTP请求

- 首行: [方法] + [url] + [版本]
- 协议头(Header): 请求的属性, 冒号空格分割的键值对;每组属性之间使用\n分隔,此处的键值对可以是用户自己定义的,但大多数都是HTTP中已经有的,具有特定含义的内容;
- 空行:遇到空行表示Header部分结束,
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度;
HTTP响应

- 首行: [版本号] + [状态码] + [状态码解释]
- 协议头(Header): 请求的属性, 冒号分割的键值对;每组属性之间使用\n分隔;
- 空行:表示Header部分结束
- Body: 空行后面的内容都是Body. Body允许为空字符串. 如果Body存在, 则在Header中会有一个Content-Length属性来标识Body的长度; 如果服务器返回了一个html页面, 那么html页面内容就是在body中.
自己实现一个HTTP协议(V1版本)
主要做这几件事情:
1、把代码格式进行整理,让代码更加规范;
2、解析 URL 中包含的参数(键值对),能够方便的处理用户传过来的参数;
3、演示 Cookie 的工作流程~
HttpRequest:
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
// 表示一个 HTTP 请求, 并负责解析.
public class HttpRequest {
private String method;
// /index.html?a=10&b=20
private String url;
private String version;
private Map<String, String> headers = new HashMap<>();
private Map<String, String> parameters = new HashMap<>();
// 请求的构造逻辑, 也使用工厂模式来构造.
// 此处的参数, 就是从 socket 中获取到的 InputStream 对象
// 这个过程本质上就是在 "反序列化"
public static HttpRequest build(InputStream inputStream) throws IOException {
HttpRequest request = new HttpRequest();
// 此处的逻辑中, 不能把 bufferedReader 写到 try ( ) 中.
// 一旦写进去之后意味着 bufferReader 就会被关闭, 会影响到 clientSocket 的状态.
// 等到最后整个请求处理完了, 再统一关闭
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(inputStream));
// 此处的 build 的过程就是解析请求的过程.
// 1. 解析首行
String firstLine = bufferedReader.readLine();
String[] firstLineTokens = firstLine.split(" ");
request.method = firstLineTokens[0];
request.url = firstLineTokens[1];
request.version = firstLineTokens[2];
// 2. 解析 url 中的参数
int pos = request.url.indexOf("?");
if (pos != -1) {
// 看看 url 中是否有 ? . 如果没有, 就说明不带参数, 也就不必解析了
// 此处的 parameters 是希望包含整个 参数 部分的内容
// pos 表示 ? 的下标
// /index.html?a=10&b=20
// parameters 的结果就相当于是 a=10&b=20
String parameters = request.url.substring(pos + 1);
// 切分的最终结果, key a, value 10; key b, value 20;
parseKV(parameters, request.parameters);
}
// 3. 解析 header
String line = "";
while ((line = bufferedReader.readLine()) != null && line.length() != 0) {
String[] headerTokens = line.split(": ");
request.headers.put(headerTokens[0], headerTokens[1]);
}
// 4. 解析 body (暂时先不考虑)
return request;
}
private static void parseKV(String input, Map<String, String> output) {
// 1. 先按照 & 切分成若干组键值对
String[] kvTokens = input.split("&");
// 2. 针对切分结果再分别进行按照 = 切分, 就得到了键和值
for (String kv : kvTokens) {
String[] result = kv.split("=");
output.put(result[0], result[1]);
}
}
// 给这个类构造一些 getter 方法. (不要搞 setter).
// 请求对象的内容应该是从网络上解析来的. 用户不应该修改.
public String getMethod() {
return method;
}
public String getUrl() {
return url;
}
public String getVersion() {
return version;
}
// 此处的 getter 手动写, 自动生成的版本是直接得到整个 hash 表.
// 而我们需要的是根据 key 来获取值.
public String getHeader(String key) {
return headers.get(key);
}
public String getParameter(String key) {
return parameters.get(key);
}
@Override
public String toString() {
return "HttpRequest{" +
"method='" + method + '\'' +
", url='" + url + '\'' +
", version='" + version + '\'' +
", headers=" + headers +
", parameters=" + parameters +
'}';
}
}
HttpResponse:
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.util.HashMap;
import java.util.Map;
// 表示一个 HTTP 响应, 负责构造
// 进行序列化操作
public class HttpResponse {
private String version = "HTTP/1.1";
private int status; // 状态码
private String message; // 状态码的描述信息
private Map<String, String> headers = new HashMap<>();
private StringBuilder body = new StringBuilder(); // 方便一会进行拼接.
// 当代码需要把响应写回给客户端的时候, 就往这个 OutputStream 中写就好了.
private OutputStream outputStream = null;
public static HttpResponse build(OutputStream outputStream) {
HttpResponse response = new HttpResponse();
response.outputStream = outputStream;
// 除了 outputStream 之外, 其他的属性的内容, 暂时都无法确定. 要根据代码的具体业务逻辑
// 来确定. (服务器的 "根据请求并计算响应" 阶段来进行设置的)
return response;
}
public void setVersion(String version) {
this.version = version;
}
public void setStatus(int status) {
this.status = status;
}
public void setMessage(String message) {
this.message = message;
}
public void setHeader(String key, String value) {
headers.put(key, value);
}
public void writeBody(String content) {
body.append(content);
}
// 以上的设置属性的操作都是在内存中倒腾.
// 还需要一个专门的方法, 把这些属性 按照 HTTP 协议 都写到 socket 中.
public void flush() throws IOException {
BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(outputStream));
bufferedWriter.write(version + " " + status + " " + message + "\n");
headers.put("Content-Length", body.toString().getBytes().length + "");
for (Map.Entry<String, String> entry : headers.entrySet()) {
bufferedWriter.write(entry.getKey() + ": " + entry.getValue() + "\n");
}
bufferedWriter.write("\n");
bufferedWriter.write(body.toString());
bufferedWriter.flush();
}
}
HttpServer:
import java.io.IOException;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class HttpServerV2 {
private ServerSocket serverSocket = null;
public HttpServerV2(int port) throws IOException {
serverSocket = new ServerSocket(port);
}
public void start() throws IOException {
System.out.println("服务器启动");
ExecutorService executorService = Executors.newCachedThreadPool();
while (true) {
Socket clientSocket = serverSocket.accept();
executorService.execute(new Runnable() {
@Override
public void run() {
process(clientSocket);
}
});
}
}
public void process(Socket clientSocket) {
try {
// 1. 读取并解析请求
HttpRequest request = HttpRequest.build(clientSocket.getInputStream());
System.out.println("request: " + request);
HttpResponse response = HttpResponse.build(clientSocket.getOutputStream());
response.setHeader("Content-Type", "text/html");
// 2. 根据请求计算响应
if (request.getUrl().startsWith("/hello")) {
response.setStatus(200);
response.setMessage("OK");
response.writeBody("hello
");
} else if (request.getUrl().startsWith("/calc")) {
// 这个逻辑要根据参数的内容进行计算
// 先获取到 a 和 b 两个参数的值
String aStr = request.getParameter("a");
String bStr = request.getParameter("b");
// System.out.println("a: " + aStr + ", b: " + bStr);
int a = Integer.parseInt(aStr);
int b = Integer.parseInt(bStr);
int result = a + b;
response.setStatus(200);
response.setMessage("OK");
response.writeBody(" result = "
+ result + "");
} else if (request.getUrl().startsWith("/cookieUser")) {
response.setStatus(200);
response.setMessage("OK");
// HTTP 的 header 中允许有多个 Set-Cookie 字段. 但是
// 此处 response 中使用 HashMap 来表示 header 的. 此时相同的 key 就覆盖
response.setHeader("Set-Cookie", "user=tz");
response.writeBody("set cookieUser
");
} else if (request.getUrl().startsWith("/cookieTime")) {
response.setStatus(200);
response.setMessage("OK");
// HTTP 的 header 中允许有多个 Set-Cookie 字段. 但是
// 此处 response 中使用 HashMap 来表示 header 的. 此时相同的 key 就覆盖
response.setHeader("Set-Cookie", "time=" + (System.currentTimeMillis() / 1000));
response.writeBody("set cookieTime
");
} else {
response.setStatus(200);
response.setMessage("OK");
response.writeBody("default
");
}
// 3. 把响应写回到客户端
response.flush();
} catch (IOException | NullPointerException e) {
e.printStackTrace();
} finally {
try {
// 这个操作会同时关闭 getInputStream 和 getOutputStream 对象
clientSocket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws IOException {
HttpServerV2 server = new HttpServerV2(9090);
server.start();
}
}
Cookie工作原理

Cookie演示
我们启动服务器,演示一下Cookie 的效果:
服务器:

客户端:(第一次设置 Cookie)

第二次就会自己加上Cookie信息,在这里存的就是用户的信息:

我们在看看服务器:

我们还可以通过Fiddler抓包看看我们构造的响应和请求: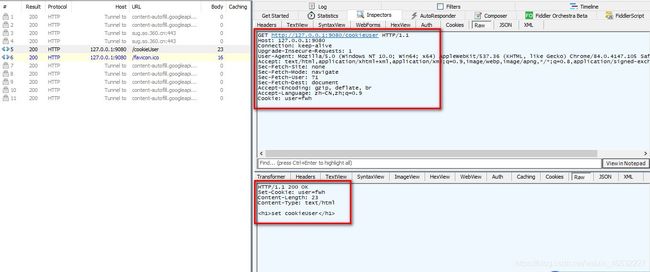
再次理解Cookie:Cookie是可以有多个的也不是一成不变的,比如我们演示一个多次访问cookieTime,每次都获取到不同的时间戳作为Cookie。
第一次访问:

第二次访问:

在这里只是修改了 time 这个cookie, user 还是登录用户的信息,是不收影响的。
如何使用cookie 完成一次登录过程,我们得看看下边这个代码是如何实现,不仅仅是浏览器,服务器也要做出相应的逻辑实现。
V3版本http 服务器
主要工作:
1、支持返回一个静态的 html 文件
2、解析处理 cookie(把 cookie处理成键值对结构)
3、解析处理 body (把body 中的数据处理成键值对结构)
4、实现完整的登录功能(session 的简单实现)
在这里我说一下主要代码:
private void doPost(HttpRequest request, HttpResponse response) {
// 2. 实现 /login 的处理
if (request.getUrl().startsWith("/login")) {
// 读取用户提交的用户名和密码
String userName = request.getParameter("username");
String password = request.getParameter("password");
// System.out.println("userName: " + userName);
// System.out.println("password: " + password);
// 登陆逻辑就需要验证用户名密码是否正确.
// 此处为了简单, 咱们把用户名和密码在代码中写死了.
// 更科学的处理方式, 应该是从数据库中读取用户名对应的密码, 校验密码是否一致.
if ("fwh".equals(userName) && "123".equals(password)) {
// 登陆成功
response.setStatus(200);
response.setMessage("OK");
response.setHeader("Content-Type", "text/html; charset=utf-8");
// 原来登陆成功, 是给浏览器写了一个 cookie, cookie 中保存的是用户的用户名.
// response.setHeader("Set-Cookie", "userName=" + userName);
// 现有的对于登陆成功的处理. 给这次登陆的用户分配了一个 session
// (在 hash 中新增了一个键值对), key 是随机生成的. value 就是用户的身份信息
// 身份信息保存在服务器中, 此时也就不再有泄露的问题了
// 给浏览器返回的 Cookie 中只需要包含 sessionId 即可
String sessionId = UUID.randomUUID().toString();
User user = new User();
user.userName = "fwh";
user.age = 20;
user.school = "邮电";
sessions.put(sessionId, user);
response.setHeader("Set-Cookie", "sessionId=" + sessionId);
response.writeBody("");
response.writeBody("欢迎您! " + userName + "");
response.writeBody("");
} else {
// 登陆失败
response.setStatus(403);
response.setMessage("Forbidden");
response.setHeader("Content-Type", "text/html; charset=utf-8");
response.writeBody("");
response.writeBody("登陆失败");
response.writeBody("");
}
}
}
session 工作原理

response.setHeader("Set-Cookie", "userName=" + userName);
如果我们用这行代码,借助 Cookie来实现登录保持功能,这样做是不太好的,用户信息在 Cookie中,每次数据传输都要把这个 Cookie 再次发给服务器,这就意味着 Cookie 中的信息很容易泄露,甚至可以伪造,绕开登录~~所以我们就需要session了!
在服务器登录成功时,把用户信息保存在一个 hash 表中(value),同时生成一个 key(这个key 是一个唯一的字符串),sessionId,最终把 sessionId 写会到 cookie 中就好了。后续访问页面的时候,Cookie 中的内容就是 sessionId,sessionId是一个没有规律的字符串,提高了安全性。服务器可以通过 sessionId 进一步找到用户的相关信息。
String sessionId = UUID.randomUUID().toString();
这行代码就会生成一个随机的字符串,每次1调用都会生成不同的。
刚开始是没有的,响应通过 set-Cookie 来保存:

接下来访问就可以获得:

通常session 是要搭配一个 过期机制,来记录线程何时创建,何时过期,如果过期也需要你重新登录,不同的网站它自己设定的过期时间也是不同的。
Cookie 和 session 的关系
- 都是为了实现客户端与服务端交互而产出
- Cookie是保存在客户端,缺点易伪造、不安全
- Session是保存在服务端,会消耗服务器资源
- Session实现有两种方式:Cookie和URL重写