详细爬虫:爬取华师教务系统
详细爬虫:爬取华师教务系统
- 前言
-
- 初衷
- 实战
-
- 1.模拟登录
- 2.登录教务系统
- 查看成绩
- 登录教务系统,并获取成绩查询所需的参数nd
- 查看成绩查询结果
前言
这篇文章是本人学了半个月的爬虫写的,如有不足之处,望各位大佬提出意见,此外,本文仅供学习与交流使用
初衷
最近学了python爬虫后,就迫不及待地想做些什么,于是就把魔爪伸向了本校的教务系统,就先以爬取自己的成绩来做个示范
实战
1.模拟登录
先打开平台登录界面并打开开发者工具(一定要在登录前提前打开),并点击网络

登录成功后在消息头里可以看到login登录所发起的请求为post请求,请求的url为 https://account.ccnu.edu.cn/cas/login?service=http://one.ccnu.edu.cn/cas/login_portal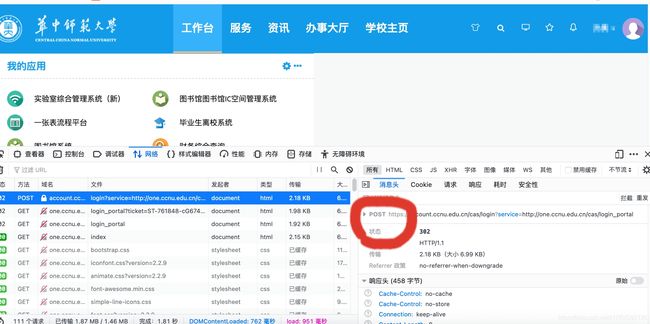
于是只要对这个url发起一个post请求并携带参数就可以实现模拟登录了。在请求里可以看到携带的相关参数

不过我发现这样并不能获得登录后的页面数据,也就是没有登录成功
后来我发现参数中的lt值每次登录都会变,于是我猜测lt值可能在登录界面的elements中

所以我们先获取lt值,在这里我们用到了session来一直携带登录后访问其它网页所需要的cookie值
import requests
from lxml import etree
# 进行UA伪装。实例化一个Session对象,用于存储登录后的cookie值
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.16; rv:78.0) Gecko/20100101 Firefox/78.0'
}
session = requests.Session()
# 获取登录需要的参数lt
def get_lt(url):
lt_text = session.get(url=url, headers=headers).text
lt = etree.HTML(lt_text).xpath('/html/body/div/div/div[2]/div/form/section[4]/input[1]/@value')[0]
return lt
然后模拟登录
# 模拟登录
username = input('用户名:')
password = input('密码:')
url = "https://account.ccnu.edu.cn/cas/login?service=http%3A%2F%2Fxk.ccnu.edu.cn%2Fsso%2Fpziotlogin"
data = {
"username": username,
"password": password,
"lt": get_lt(url),
"execution": "e1s1",
"_eventId": "submit",
"submit": "登录"
}
response = session.post(url=url, data=data, headers=headers)
2.登录教务系统
登录后发现找不到login,所以我在手机上的华师匣子里点开教务系统然后找到了登录教务系统的url
 然后可以直接用session携带着cookie值对这个url进行请求(这里登录教务系统是为了之后的一个参数的获取)
然后可以直接用session携带着cookie值对这个url进行请求(这里登录教务系统是为了之后的一个参数的获取)
查看成绩

这又是一个post请求,可以直接用session携带着cookie值对其发起请求,然后找到参数,发现nd值也是一直在变,于是到教务系统的界面进行寻找

也是在一个标签中
登录教务系统,并获取成绩查询所需的参数nd
def get_nd():
login_url = 'http://xk.ccnu.edu.cn/jwglxt/xtgl/index_initMenu.html?jsdm=&_t=1613272719507'
login_response = session.post(url=login_url, headers=headers)
nd = etree.HTML(login_response.text).xpath('/html/body/div[1]/div/div/a/img/@src')[0].split('=')[-1]
return nd
最后获取成绩查询页面的数据
查看成绩查询结果
grade_url = 'http://xk.ccnu.edu.cn/jwglxt/cjcx/cjcx_cxDgXscj.html?doType=query&gnmkdm=N305005&su=2020213351'
data = {
"xnm":"2020",
"xqm":"3",
"_search":"false",
"nd":get_nd(),
"queryModel.showCount":"15",
"queryModel.currentPage":"1",
"queryModel.sortName":"",
"queryModel.sortOrder":"asc",
"time":"0"
}
grade_response = session.post(url=grade_url, data=data, headers=headers)
page_text = grade_response.text
print(grade_response.status_code)
完整代码如下
import requests
from lxml import etree
# 进行UA伪装。实例化一个Session对象,用于存储登录后的cookie值
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.16; rv:78.0) Gecko/20100101 Firefox/78.0'
}
session = requests.Session()
# 获取登录需要的参数lt
def get_lt(url):
lt_text = session.get(url=url, headers=headers).text
lt = etree.HTML(lt_text).xpath('/html/body/div/div/div[2]/div/form/section[4]/input[1]/@value')[0]
return lt
# 模拟登录
username = input('用户名:')
password = input('密码:')
url = "https://account.ccnu.edu.cn/cas/login?service=http%3A%2F%2Fxk.ccnu.edu.cn%2Fsso%2Fpziotlogin"
data = {
"username": username,
"password": password,
"lt": get_lt(url),
"execution": "e1s1",
"_eventId": "submit",
"submit": "登录"
}
response = session.post(url=url, data=data, headers=headers)
# 登录教务系统,并获取成绩查询所需的参数nd
def get_nd():
login_url = 'http://xk.ccnu.edu.cn/jwglxt/xtgl/index_initMenu.html?jsdm=&_t=1613272719507'
login_response = session.post(url=login_url, headers=headers)
nd = etree.HTML(login_response.text).xpath('/html/body/div[1]/div/div/a/img/@src')[0].split('=')[-1]
return nd
# 查看成绩查询结果
grade_url = 'http://xk.ccnu.edu.cn/jwglxt/cjcx/cjcx_cxDgXscj.html?doType=query&gnmkdm=N305005&su=2020213351'
data = {
"xnm":"2020",
"xqm":"3",
"_search":"false",
"nd":get_nd(),
"queryModel.showCount":"15",
"queryModel.currentPage":"1",
"queryModel.sortName":"",
"queryModel.sortOrder":"asc",
"time":"0"
}
grade_response = session.post(url=grade_url, data=data, headers=headers)
page_text = grade_response.text
print(grade_response.status_code)
# 持久化存储
def store_forever():
with open('华师.html', 'w', encoding='utf-8') as fp:
fp.write(page_text)
# 调用函数
store_forever()
需要注意的是headers中的user-agent 需要自己找并修改
 运行结果出现200,表示成功。打开华师.html可以看到自己的成绩。当然,也可以再写一段python程序将成绩存入Excel表格中。
运行结果出现200,表示成功。打开华师.html可以看到自己的成绩。当然,也可以再写一段python程序将成绩存入Excel表格中。
不过看成绩只是一些基本需求,成绩都能看,那么抢课或者抢座也自然能实现了。
 如果是小白的话,request模块和lxml模块需要自行下载
如果是小白的话,request模块和lxml模块需要自行下载
