连Python都不熟也能跑通AI人脸识别?“隐藏Boss”竟是它!
摘要:先把AI人脸识别跑起来,然后研究它是如何实现的,整个过程中确实收获不少。所谓先跟着做,再跟着学,实践与理论结合,自己感觉有理解了一些基础概念入个门,在此分享一下自己的捣鼓经验。
1、买台小“电脑”
既然要做人脸识别,那得找台带摄像头的小电脑啊。首先得价格便宜,简单搜了下,基本有以下几个选择:
- 树莓派4: ARM系统,生态好。价格合适,55刀。CPU在3个中最好,算力0.1TFLOPS
- K210:RISC-V的(非ARM),价格是最实惠的,299元。算力有0.8TOPS
- Jetson Nano:ARM系统,比树莓派4还贵,但是多一个英伟达的GPU(当然是丐版的GPU),价格99刀。算力0.47TFLOPS
这3个里面,考虑到人脸识别应该有更多的AI属性,那么带GPU能做AI推理不是更香么,于是就选择了英伟达的Jetson Nano开发板(主要也是想先入门英伟达的GPU派系,谁叫现在NVIDIA比较香呢)。

参考链接:
https://www.zhihu.com/question/384561694
https://zhuanlan.zhihu.com/p/81969854
2、启动系统
这里需要先把“系统image”刷到 tf 卡里面,然后把tf卡插到开发板上,然后开机启动。启动有2个点需要注意:
- 跳线帽,需要插上(不然电源点不亮)。
- 第一次开机会卡住,需要重启一次。
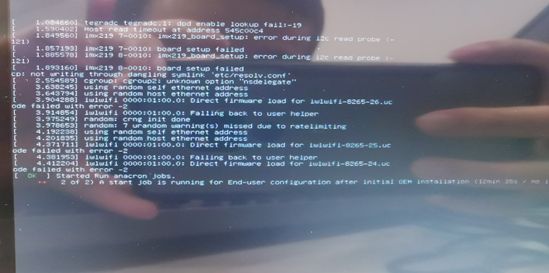

启动后,发现是个带界面的 Ubuntu系统,接上鼠标+键盘,就是最熟悉的小电脑嘛。
连接网络,设置国内Ubuntu源,安装 jtop 命令(因为nano不能敲 nvidia-smi 命令)。
设置系统参考:https://zhuanlan.zhihu.com/p/336429888
3、原来CUDA是个编译器
既然选了英伟达的GPU开发板,刚好了解一下CUDA是什么。
3.1 写个CUDA程序
当然,程序是抄课本的,如下。
https://blog.csdn.net/fb_help/article/details/79283032
可以看到是C语言的,一共就2个函数。一个main函数,一个useCUDA函数。
要跑起来,需要先进行编译。发现不使用gcc,而是使用 nvcc 编译器,有意思。
Jetson Nano的image已经安装了nvcc,所以可以直接用,只是使用前需要设置一下path。
export CUDA_HOME=/usr/local/cuda-10.0
export LD_LIBRARY_PATH=/usr/local/cuda-10.0/lib64:$LD_LIBRARY_PATH
export PATH=/usr/local/cuda-10.0/bin:$PATH设置后,才可以敲 nvcc 命令。参考:https://www.huaweicloud.com/articles/0ba49cd30493adbb37c82250408d8be4.html
于是开始编译:
nvcc -o main.out main.cu foo.cu (跟gcc编译一样)运行:./main.out 即可。呵,原来CUDA是个编译器啊(编译出给GPU跑的程序)。
3.2 CUDA在干嘛
普通的程序编译出来都是给CPU跑的;写个程序,想给GPU跑,就得使用cuda编译器了。毕竟咱们的这个GPU弱是弱了一点,也有128核呢,跑这种简单的cuda程序还是OK的。
另外,CUDA还提供了一些现成的操作GPU的函数,比如:矩阵乘法,矩阵转置 之类的。CUDA只能用于英伟达的GPU,用于利用GPU进行复杂的并行计算。然后很多AI框架都是基于CUDA搞的,所以跑个cuda程序,帮助理解挺好的。
4、检测摄像头功能OK
这里需要使用 nvgstcapture-1.0 命令,经查,字母gst原来是Gstreamer的缩写。
直接敲:
nvgstcapture-1.0发现可以把摄像头打开了。
4.1 Gstreamer
搜了下,发现是一个音视频流处理的pipeline框架。
比如Shell命令的管道符为:|
为避免冲突,Gstreamer的管道符,用了个比较像的:! 符号。
参考:https://thebigdoc.readthedocs.io/en/latest/gstreamer/gst-concept.html
5、人脸可以正常识别
按照教程:https://github.com/JetsonHacksNano/CSI-Camera/blob/master/face_detect.py
Copy了一个 face_detect.py 文件。
直接运行了:
python ./face_detect.py 发现就可以识别出人脸了,厉害了。。。(额,只是图像是倒过来的)
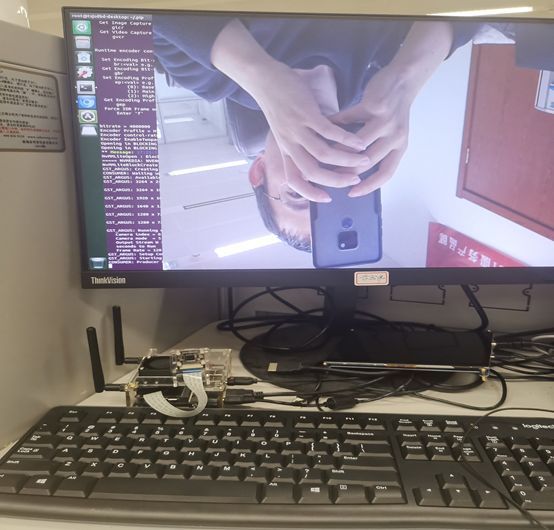
于是简单看了下代码(不会Python,但是也大概能看懂),发现有一个图像模式的参数 “flip_method=0”,我改成了6,发现图像就转过来正常了。

再看了下,发现获取摄像头拍摄的图片,还是通过 Gstreamer 来实现的。
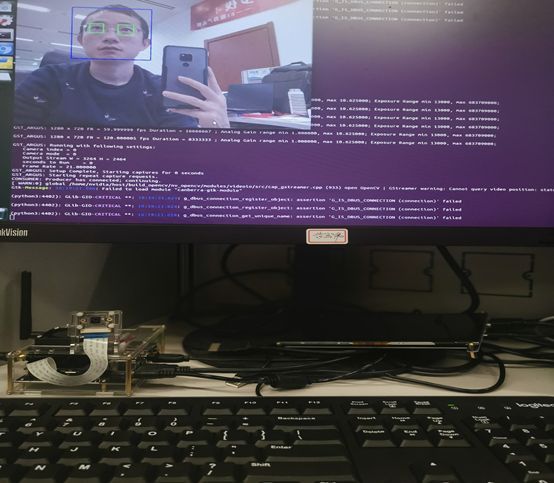
6、Opencv才是隐藏的Boss?
通过上面的章节,发现总共代码没几行,怎么就能识别人脸了呢?虽然python不熟,但好在代码少,仔细看了下:发现主要是调用了opencv的函数就可以识别人脸了,那说明opencv还是得了解一下。
你看识别人脸的代码,总共也就10行,简单过一下:
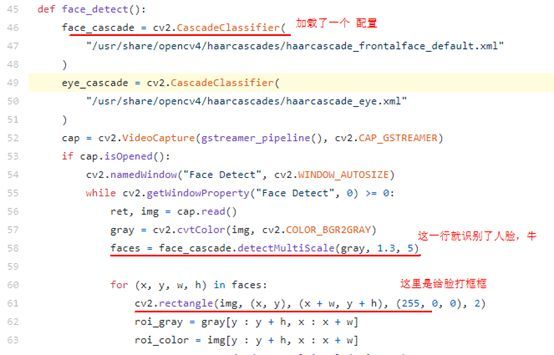
找了这篇文章,还不错:https://www.jianshu.com/p/0514c03e6727
6.1 Haar分类器
再搜索,发现这里的人脸识别用的是 “Haar分类器”这种方法实现的。学习了下,属于机器学习的范畴,没有用卷积神经网络。可参考:https://zhuanlan.zhihu.com/p/51431663
完整的Opencv的介绍:http://woshicver.com/
7、Windows上面复现人脸识别
既然通过opencv就能识别人脸,那我不需要摄像头,直接拿图片是不是也可以跑了?于是Windows上面安装个opencv试试。
7.1 安装Python
去 https://www.python.org/ 下载最新的Python,安装后就有Python了。当然执行命令是 py。
7.2 pip命令
发现pip命令,还是不行。 找到原来在:
C:\Users\tsjsdbd\AppData\Local\Programs\Python\Python39\Scripts
这个目录下。
于是把这个路径,加入到了本机的环境变量里面:

所以pip命令ok了
7.3 设置pip国内源
vi ~/pip/pip.ini然后设置内容:
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple7.4 安装 opencv 包
pip install opencv-python 这条命令会同时安装 numpy 包。
Ps:如果需要代理。设置一下
export http_proxy=http://代理:端口
export https_proxy=http://代理:端口7.5 重现Haar人脸识别
下载一个带人脸的jpg照片,这里假设名为 face.jpg
detect.py代码如下:
import cv2
# load model
detector=cv2.CascadeClassifier('C:/Users/t00402375/AppData/Local/Programs/Python/Python39/Lib/site-packages/cv2/data/haarcascade_frontalface_default.xml')
src = cv2.imread("./face.jpg")
cv2.namedWindow("image", cv2.WINDOW_AUTOSIZE);
# detect
gray=cv2.cvtColor(src,cv2.COLOR_BGR2GRAY)
faces=detector.detectMultiScale(gray,1.2,5)
# box
for x,y,w,h in faces:
cv2.rectangle(src,(x,y),(x+w,y+h),(255,0,0),2)
# show
cv2.imshow("image", src);
cv2.waitKey(0);
cv2.destroyAllWindows();运行就行了。
py detect.py得到结果:

发现确实可以,杠杠滴。
8、通过神经网络的人脸识别
现在视频图像的识别,一般走CNN,所以咱也得玩一遍。Jetson 开发板,自己配套了一套 jetson-inference 的推理项目,就是用来跑GPU推理的。
参考:https://blog.csdn.net/weixin_45319326/article/details/107956896
点击关注,第一时间了解华为云新鲜技术~