WACV 2021 论文大盘点-GAN篇

本篇总结关于 GAN 的论文,包括人脸编辑、单图像中合成、大规模视频合成、自动缺陷检测、对非均质光照图像处理等。
共计 11 篇。如有遗漏,欢迎补充。
下载包含这些论文的 WACV 2021 所有论文:
『WACV 2021 开幕,更偏重技术应用,附论文下载』
用于缺陷检测
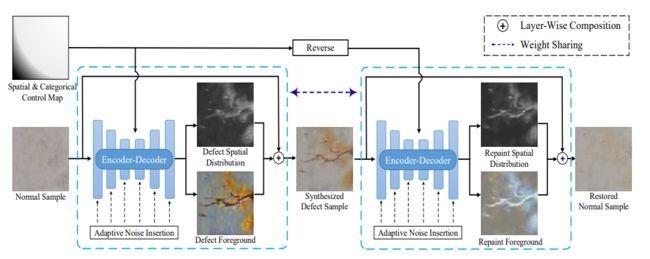
Defect-GAN: High-Fidelity Defect Synthesis for Automated Defect Inspection
自动缺陷检测对于先进制造业中有效的维护、维修和操作至关重要。但在使用深度神经网络进行任务研究时往往受缺陷样本缺乏的限制。
作者在本次研究中设计了一种自动缺陷合成网络:Defect-GAN,可以生成真实的、多样化的缺陷样本,用于训练精确的、鲁棒的缺陷检测网络。Defect GAN 通过损坏和恢复过程进行学习,其中损坏在正常表面图像上生成缺陷,而恢复则是去除缺陷生成正常图像。
它是采用了一种新颖的基于合成层的架构,用于在各种图像背景中生成具有不同纹理和外观的逼真缺陷,它还可以模拟缺陷的随机变化,并对生成的缺陷在图像背景中的位置和类别进行灵活控制。
实验验证,Defect-GAN 所合成各种缺陷具有多样性和保真度。此外,合成的缺陷样本证明了其在训练更好的缺陷检测网络方面的有效性。
作者 | Gongjie Zhang, Kaiwen Cui, Tzu-Yi Hung, Shijian Lu
单位 | 南洋理工大学等
论文 |
https://openaccess.thecvf.com/content/WACV2021/papers/Zhang_Defect-GAN_High-Fidelity_Defect_Synthesis_for_Automated_Defect_Inspection_WACV_2021_paper.pdf
用于图像合成
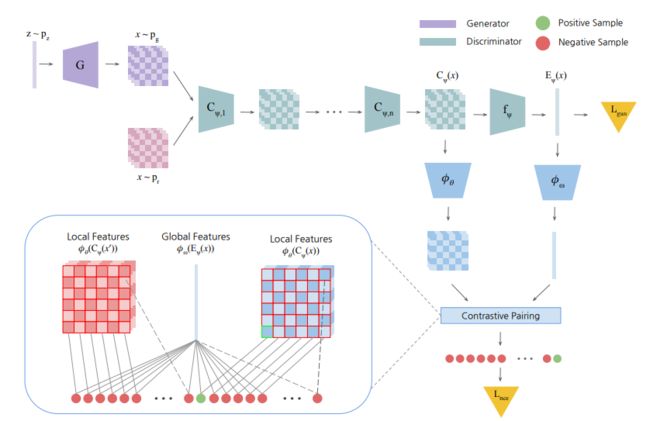
InfoMax-GAN: Improved Adversarial Image Generation via Information Maximization and Contrastive Learning
作者在本次工作中提出一个原则性框架,来同时缓解 GANs 中的两个基本问题:catastrophic forgetting of the discriminator(判别器)和 mode collapse of the generator(生成器)。并通过对 GANs 采用对比学习和相互信息最大化的方法来实现这一目标,并进行了广泛的分析以了解改进的来源。
与最先进的作品相比,所提出方法在相同的训练和评估条件下,显著稳定了GAN 训练,提高了 5 个数据集的图像合成 GAN 的性能。
特别是与 SSGAN 相比,在人脸等图像域上没有出现性能较差的问题,反而显著提高了性能。
简单易行,实用性强:它只涉及一个辅助目标,计算成本低,并且在广泛的训练设置和数据集上鲁棒地执行,无需任何超参数调整。
作者 | Kwot Sin Lee, Ngoc-Trung Tran, Ngai-Man Cheung
单位 | 剑桥大学;Snap Inc;新加坡科技设计大学
论文 | https://arxiv.org/abs/2007.04589
代码 | https://github.com/kwotsin/mimicry
A Multi-Class Hinge Loss for Conditional GANs
MHGAN 是 projection 辨别的有力补充,并能以可以忽略不计的额外计算成本改善训练。multi-hinge 损失改善了 Imagenet-128 上生成图像的质量和多样性。
在研究中,作者证明分类和识别任务不需要融合的太紧密,以及在MHSharedGAN 中如何使用 multi-hinge 损失来交换图像质量的多样性。
最后得出 MHGAN 在完全监督和半监督的环境下都能有很好的表现,并能与高质量的生成器同时学习一个相对准确的分类器。
作者 | Ilya Kavalerov, Wojciech Czaja, Rama Chellappa
单位 | 马里兰大学;约翰斯·霍普金斯大学
论文 |
https://openaccess.thecvf.com/content/WACV2021/papers/Kavalerov_A_Multi-Class_Hinge_Loss_for_Conditional_GANs_WACV_2021_paper.pdf

用于人脸属性编辑
FACEGAN: Facial Attribute Controllable rEenactment GAN
作者提出一个名为 FACEGAN 的 facial animator (人脸动画器),能够从单个源图像中进行高质量的重现。
与先前的工作不同的是,该模型对源和驱动对的兼容性不作任何限制。该模型结合了动作单元和人脸关键点运动表示的最佳特性,以减少身份泄漏问题,并优化重现质量。此外,FACEGAN 分别处理人脸和背景,提高了输出质量,并提供了额外的选择所需背景的控制。
作者将所提出方法与最先进的方法进行了比较,并在数量和质量上都获得了优越的结果。
作者 | Soumya Tripathy, Juho Kannala, Esa Rahtu
单位 | Tampere University;阿尔托大学
论文 | https://arxiv.org/abs/2011.04439
备注 | WACV 2021

用于非均匀光照图像处理
DB-GAN: Boosting Object Recognition Under Strong Lighting Conditions
本次工作中作者提出提出一种基于 GAN 的方法,DB-GAN,可以在具有挑战性照明条件下提高目标检测和 6D 物体姿势估计的性能。并且证明它明显优于基线检测器以及所有其他先进的方法。
另外,所提出方法对 image normalisation(图像归一化)是完全数据驱动的,既不需要大量的人工标注数据集,也不需要输入图像的先验知识。同样在无需输入图像先验知识下还可以处理非均匀光照。
作者对未来的工作计划是探索如何将该方法泛化到更多样化的任务中。
作者 | Luca Minciullo, Fabian Manhardt, Kei Yoshikawa, Sven Meier, Federico Tombari, Norimasa Kobori
单位 | 丰田汽车欧洲;慕尼黑工业大学;Woven CORE
论文 |
https://openaccess.thecvf.com/content/WACV2021/papers/Minciullo_DB-GAN_Boosting_Object_Recognition_Under_Strong_Lighting_Conditions_WACV_2021_paper.pdf

用于虹膜生成
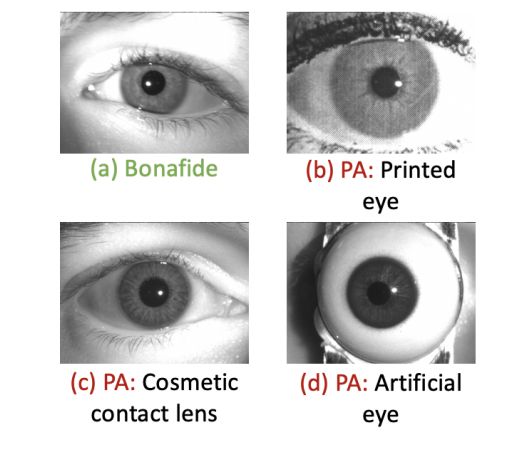
CIT-GAN: Cyclic Image Translation Generative Adversarial Network With Application in Iris Presentation Attack Detection
Cyclic Image Translation 生成对抗网络(CIT-GAN),用于多域风格迁移。
为此,引入具有学习训练数据集中所代表的每个领域风格特征能力的风格网络。帮助生成器驱动从源域到参考域的图像翻译,生成具有参考域风格特征的合成图像。每个域的学习风格特征取决于风格损失和域分类损失。这也引发了每个域内风格特征的差异性。
所提出的 CIT-GAN 被用于虹膜 presentation attack detection(PAD)的背景下,为训练集中代表性不足的类生成合成 presentation attack(PA)样本。
用当前最先进的虹膜 PAD 方法进行评估,证明了使用这种合成生成的 PA 样本来训练 PAD 方法的有效性。此外,使用Frechet Inception Distance(FID)得分来评估合成生成样本的质量。得出所提出方法生成的合成图像质量优于其他竞争方法,包括 StarGan。
作者 | Shivangi Yadav, Arun Ross
单位 | 密歇根州立大学
论文 | https://arxiv.org/abs/2012.02374
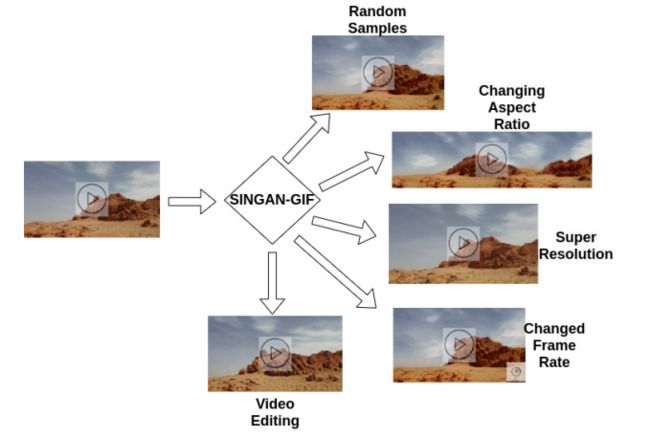
图像视频编辑“全家桶”
SinGAN-GIF: Learning a Generative Video Model From a Single GIF
SinGAN-GIF 可以生成任意长宽比的样本,进行超分辨率,改变时帧率,并可用于视频编辑应用。
作者 | Rajat Arora, Yong Jae Lee
单位 | 加利福尼亚大学戴维斯分校
论文 |
https://openaccess.thecvf.com/content/WACV2021/papers/Arora_SinGAN-GIF_Learning_a_Generative_Video_Model_From_a_Single_GIF_WACV_2021_paper.pdf
主页 | https://rajat95.github.io/singan-gif/
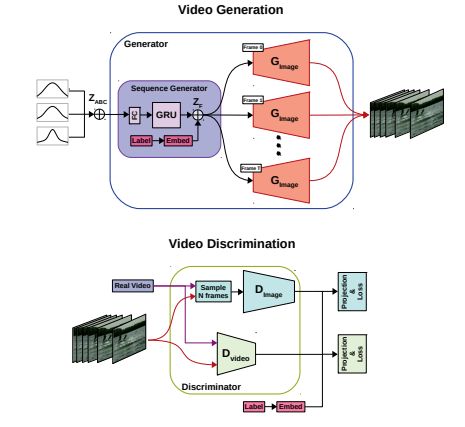
用于大规模视频生成
Temporal Shift GAN for Large Scale Video Generation
过去几年,视频生成模型越来越流行,然而目前使用的标准 2D 架构缺乏天然的 spatio-temporal 建模能力。在本次研究中,作者提出一种用于视频生成的网络架构,可以模拟时空一致性,不需要借助昂贵的 3D 架构。促进了相邻时间点之间的信息交换,提高了生成帧的高层结构以及低层细节的时空一致性。
通过在 UCF-101 数据集上的 inception score 以及更好的定性结果进行衡量,该方法实现了最先进的定量性能。
此外,引入一种新的使用下游任务进行评估的定量测量方法(S3)。提出一个新的多标签数据集 MaisToy,可以评估模型的泛化能力。
作者 | Andres Munoz, Mohammadreza Zolfaghari, Max Argus, Thomas Brox
单位 | 德国弗莱堡大学
论文 | https://arxiv.org/abs/2004.01823
用于单图像生成
Improved Techniques for Training Single-Image GANs
近期,学者们热衷于从单图像中学习生成模型。其意义在于生成模型可以用于收集大量数据集不可行的领域。但它样是一个难解问题。
作者在本次研究中就该问题进行了实验分析,并提出一些实践方法,也获得优于以往方法的结果。其中关键的部分是,不同于单图像生成方法,以顺序多阶段的方式并发训练几个阶段,可以以更少的阶段增加图像分辨率来学习模型。
与最近的先进基线相比,所提出模型的训练速度快了 6 倍,参数更少,并且可以更好地捕捉图像的全局结构。
作者 | Tobias Hinz, Matthew Fisher, Oliver Wang, Stefan Wermter
单位 | 汉堡大学;Adobe Research
论文 | https://arxiv.org/abs/2003.11512
代码 | https://github.com/tohinz/ConSinGAN

其它
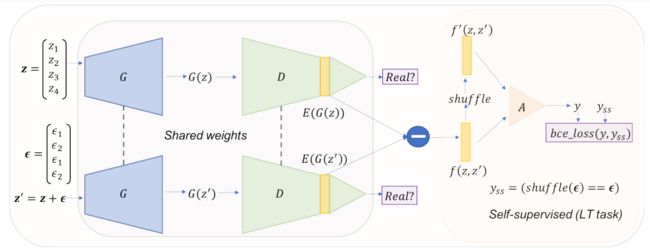
LT-GAN: Self-Supervised GAN With Latent Transformation Detection
提出一个新的自监督任务,识别 GAN 引起的 Latent Transformation,与 GAN 的对抗性训练合作,优化生成器。
证明了所提出的 LT-GAN 方法在几个不同架构的标准数据集上的功效,通过 在 Frechet inception distance(FID) 度量上改进有条件和无条件的最先进图像生成性能。LT-GAN 模型使用现有的语义编辑框架比基线模型改善了受控图像编辑。
作者 | Parth Patel, Nupur Kumari, Mayank Singh, Balaji Krishnamurthy
单位 | Adobe;Birla Institute of Technology & Science
论文 | https://arxiv.org/abs/2010.09893
Let's Get Dirty: GAN Based Data Augmentation for Camera Lens Soiling Detection in Autonomous Driving
用于自动驾驶中广角鱼眼镜头污染检测的新型基于 GAN 的数据增强技术。
作者 | Michal Uricar, Ganesh Sistu, Hazem Rashed, Antonin Vobecky, Varun Ravi Kumar, Pavel Krizek, Fabian Burger, Senthil Yogamani
单位 | Independent Researcher;Valeo等
论文 | https://arxiv.org/abs/1912.02249

- END -
编辑:CV君
转载请联系本公众号授权

备注:gan

GAN交流群
更多最新GAN学习技术信息,
若已为CV君其他账号好友请直接私信。
OpenCV中文网
微信号 : iopencv
QQ群:805388940
微博/知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 