Python-pandas高级篇
数据规整化,合并数据集
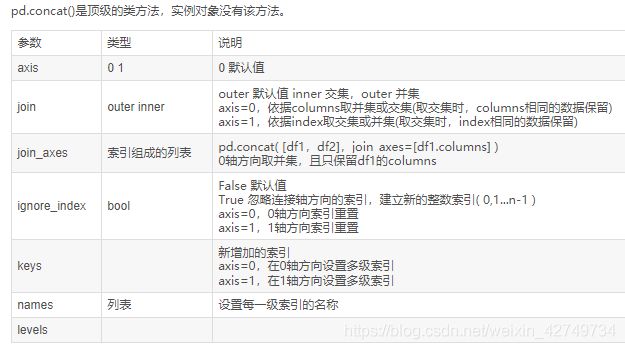
merge¶
- 左右连接
df1:
key data1
0 b 0
1 b 1
2 a 2
3 c 3
4 a 4
5 a 5
6 b 6
********************
df2:
key data2
0 a 0
1 b 1
2 d 2
- 默认情况下取两张表的交集(两张表里面都存在a和b,把所有ab相关的值都取出来,data1有3个,data2只有一个,与on='key’等同。
- df1跟df2前后顺序不影响结果
pd.merge(df1,df2)
out:
data1 key data2
0 0 b 1
1 1 b 1
2 6 b 1
3 2 a 0
4 4 a 0
5 5 a 0
pd.merge(df1,df2,on='key')
data1 key data2
0 0 b 1
1 1 b 1
2 6 b 1
3 2 a 0
4 4 a 0
5 5 a 0
- 加条件
data1 lkey
0 0 b
1 1 b
2 2 a
3 3 c
4 4 a
5 5 a
6 6 b
********************
data2 rkey
0 0 a
1 1 b
2 2 d
pd.merge(ddf1,ddf2,left_on='lkey',right_on='rkey')
data1 lkey data2 rkey
0 0 b 1 b
1 1 b 1 b
2 6 b 1 b
3 2 a 0 a
4 4 a 0 a
5 5 a 0 a
how :(left,right,outer,inner)
-
inner 默认值,只有共有的才显示
-
left/right 左/右连接,以左/右边的为标准,右/左边没有的 nan 填充
-
outer 左右的结合,只要有的都有,其他 nan 填充,与 inner 相反
-
left和right:两个不同的DataFrame;
-
how:连接方式,有inner、left、right、outer,默认为inner;
-
on:指的是用于连接的列索引名称,必须存在于左右两个DataFrame中,如果没有指定且其他参数也没有指定,则以两个DataFrame列名交集作为连接键;
-
left_on:左侧DataFrame中用于连接键的列名,这个参数左右列名不同但代表的含义相同时非常的有用;
-
right_on:右侧DataFrame中用于连接键的列名;
-
left_index:使用左侧DataFrame中的行索引作为连接键;
-
right_index:使用右侧DataFrame中的行索引作为连接键;
-
sort:默认为True,将合并的数据进行排序,设置为False可以提高性能;
-
suffixes:字符串值组成的元组,用于指定当左右DataFrame存在相同列名时在列名后面附加的后缀名称,默认为(’_x’, ‘_y’);
-
copy:默认为True,总是将数据复制到数据结构中,设置为False可以提高性能;
-
indicator:显示合并数据中数据的来源情况
# 以左边为准
pd.merge(df1,df2,on='key',how='left')
data1 key data2
0 0 b 1.0
1 1 b 1.0
2 2 a 0.0
3 3 c NaN
4 4 a 0.0
5 5 a 0.0
6 6 b 1.0
- 多个健
1 key2 lval
0 foo one 1
1 foo two 2
2 bar one 3
***************************************
key1 key2 lval
0 foo one 4
1 foo one 5
2 bar one 6
3 bar two 7
pd.merge(left,right,on=['key1','key2'],how='outer')
out:
key1 key2 lval_x lval_y
0 foo one 1.0 4.0
1 foo one 1.0 5.0
2 foo two 2.0 NaN
3 bar one 3.0 6.0
4 bar two NaN 7.0
pd.merge(left,right,on=['key1','key2'],how='inner')
out:
key1 key2 lval_x lval_y
0 foo one 1 4
1 foo one 1 5
2 bar one 3 6
concat
- 上下连接
s1=Series([0,1],index=['a','b'])
s2=Series([2,3,4],index=['c','d','e'])
s3=Series([5,6],index=['f','g'])
print(s1)
print(s2)
print(s3)
out:
a 0
b 1
dtype: int64
c 2
d 3
e 4
dtype: int64
f 5
g 6
dtype: int64
# 上下连接
val=pd.concat([s1,s2,s3])
out:
a 0
b 1
c 2
d 3
e 4
f 5
g 6
dtype: int64
# 左右连接
val=pd.concat([s1,s2,s3],axis=1)
out:
0 1 2
a 0.0 NaN NaN
b 1.0 NaN NaN
c NaN 2.0 NaN
d NaN 3.0 NaN
e NaN 4.0 NaN
f NaN NaN 5.0
g NaN NaN 6.0
- 加参数
s1:
a 0
b 1
s4:
a 0
b 5
f 5
g 6
dtype: int64
pd.concat([s1,s4],axis=1,join='inner')
out:
0 1
a 0 0
b 1 5
result=pd.concat([s1,s2,s3],keys=['one','two','three'])
result
out:
one a 0
b 1
two c 2
d 3
e 4
three f 5
g 6
dtype: int64
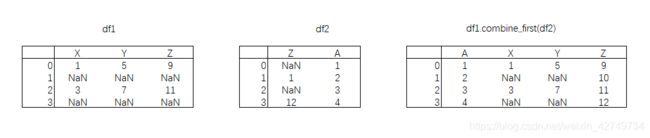
- Combin_first :合并重叠数据
-
用b填充a,以a为准,a中有的值保留,没有的用b来代替
a:
f NaN
e 2.5
d NaN
c 1.0
b 4.5
a NaN
dtype: float64
b:
f 0
e 1
d 2
c 3
b 4
a 5
dtype: int32
# 用b填充a,a中有的值保留,没有的用b来代替
a.combine_first(b)
out:
f 0.0
e 2.5
d 2.0
c 1.0
b 4.5
a 5.0
dtype: float64
对DataFrame一样的
重塑与轴向选择
- stack 将列旋转为行
- unstack 将行旋转为列
data=DataFrame(np.arange(6).reshape(2,3),index=pd.Index(['sh','bj'],name='city'),columns=pd.Index(['one','two','three'],name='number'))
number one two three
city
sh 0 1 2
bj 3 4 5
result=data.stack()
out:
city number
sh one 0
two 1
three 2
bj one 3
two 4
three 5
dtype: int32
# 还原
result.unstack()
out:
number one two three
city
sh 0 1 2
bj 3 4 5
# 指定旋转列
result.unstack('city')
out:
city sh bj
number
one 0 3
two 1 4
three 2 5
df1:
side left right
city number
sh one 0 5
two 1 6
three 2 7
bj one 3 8
two 4 9
three 5 10
df.unstack('city').stack('side')
out:
city bj sh
number side
one left 3 0
right 8 5
two left 4 1
right 9 6
three left 5 2
right 10 7
数据转换
清除重复数据(duplicate)
data:
k1 k2
0 one 1
1 one 1
2 one 2
3 two 3
4 two 3
5 two 4
6 two 4
# 找出重复值
data.duplicated()
out:
0 False
1 True
2 False
3 False
4 True
5 False
6 True
dtype: bool
# 删除重复值
data.drop_duplicates()
out:
k1 k2
0 one 1
2 one 2
3 two 3
5 two 4
# 条件删除,K1列的在、重复值都删除,保留第一行数据
data.drop_duplicates('k1')
out:
k1 k2
0 one 1
3 two 3
# 两条件用[]
data.drop_duplicates(['k1','k2'])
out:
k1 k2
0 one 1
2 one 2
3 two 3
5 two 4
# 保留第一个,last最后一个
data.drop_duplicates(['k1','k2'],keep='first') # 保留第一个,last最后一个
利用函数和映射进行转换
data:
food unit
0 A 2
1 b 4
2 c 6
3 D 8
meat_to_ainmal={
'a':'pig','b':'dog','c':'cow','d':'cat'}
# 全部转成小写(因为在food列存在大小写,在新增一列的字典里全是小写,所以要先转成小写,再添加。结果不改变food列值。
# 方法一
data['animal']=data['food'].map(str.lower).map(meat_to_ainmal)
#data['animal']=data['food'].map(lambda x:meat_to_animal[x.lower()])
data
out:
food unit animal
0 A 2 pig
1 b 4 dog
2 c 6 cow
3 D 8 cat
def trans(x):
return meat_to_ainmal[x.lower()]
data['animal']=data['food'].map(trans)
data
替换值replace
data:
0 1
1 -999
2 100
3 -999
4 -1000
dtype: int64
***************************************************
result=data.replace(-999,NA)
out:
0 1.0
1 NaN
2 100.0
3 NaN
4 -1000.0
dtype: float64
**************************************************
data.replace({
-999:NA,100:250})
out:
0 1.0
1 NaN
2 250.0
3 NaN
4 -1000.0
dtype: float64
拆分、分箱技术
cut
score_list=np.random.randint(25,100,size=20)
out:
array([85, 33, 80, 58, 27, 71, 83, 73, 51, 25, 55, 31, 34, 63, 61, 40, 87,
67, 50, 81])
# 定义一个分类的区间标准(分成四组:(0-59],(59-70],(70-80],(80-100])
bins=[0,59,70,80,100]
# 分箱处理
score_cat=pd.cut(score_list,bins)
# 分别位于哪个组的索引
score_cat.codes
array([3, 0, 2, 0, 0, 2, 3, 2, 0, 0, 0, 0, 0, 1, 1, 0, 3, 1, 0, 3],
dtype=int8)
# 统计出各个阶段的人数
pd.value_counts(score_cat)
(0, 59] 10
(80, 100] 4
(70, 80] 3
(59, 70] 3
dtype: int64
# 给每个区间命名
group_names=['D','C','B','A']
a=pd.cut(score_list,bins,labels=group_names)
pd.value_counts(a)
D 10
A 4
B 3
C 3
dtype: int64
# 对于DataFrame处理是一样的
df=DataFrame()
df['score']=score_list
df['student']=[pd.util.testing.rands(3) for i in range(20)] # 随机生成3个字符组成姓名
df['Categories']=pd.cut(df['score'],bins,labels=['D','C','B','A']) # 添加成绩等级
df.head()
score student Categories
0 85 Wg6 A
1 33 rsD D
2 80 VFH B
3 58 2q2 D
4 27 hXZ D
qcut
- qucut:默认情况下对个数进行几等分
- cut:默认情况下按照数值进行几等分
data=np.random.rand(1000)
# 用qcut进行4等分,结果是每个等级各250个
c1=pd.qcut(data,4)
c1
[(0.245, 0.503], (0.245, 0.503], (0.747, 0.999], (0.503, 0.747], (0.00098, 0.245], ..., (0.503, 0.747], (0.747, 0.999], (0.245, 0.503], (0.503, 0.747], (0.747, 0.999]]
Length: 1000
Categories (4, interval[float64]): [(0.00098, 0.245] < (0.245, 0.503] < (0.503, 0.747] < (0.747, 0.999]]
# 用cut进行4等分,结果是按 [(-0.000524, 0.25] < (0.25, 0.499] < (0.499, 0.749] < (0.749, 0.998]]分类
c2=pd.cut(data,4)
c2
[(0.25, 0.499], (0.749, 0.998], (0.25, 0.499], (-0.000524, 0.25], (0.499, 0.749], ..., (0.499, 0.749], (0.749, 0.998], (0.25, 0.499], (-0.000524, 0.25], (0.749, 0.998]]
Length: 1000
Categories (4, interval[float64]): [(-0.000524, 0.25] < (0.25, 0.499] < (0.499, 0.749] < (0.749, 0.998]]
# 比较两种方法的结果统计
print(pd.value_counts(c1))
print(pd.value_counts(c2))
(0.747, 0.999] 250
(0.503, 0.747] 250
(0.245, 0.503] 250
(0.00098, 0.245] 250
dtype: int64
(0.499, 0.749] 278
(-0.000524, 0.25] 261
(0.25, 0.499] 233
(0.749, 0.998] 228
dtype: int64
- 自定义分组与cut一样
result=pd.qcut(data,[0,0.1,0.5,0.9,1])
pd.value_counts(result)
(0.494, 0.907] 400
(0.0881, 0.494] 400
(0.907, 0.999] 100
(-5.999999999999929e-06, 0.0881] 100
dtype: int64
# 分组的结果四舍五入
result=pd.cut(data,[0,0.1,0.5,0.9,1])
pd.value_counts(result)
(0.1, 0.5] 392
(0.5, 0.9] 385
(0.0, 0.1] 114
(0.9, 1.0] 109
dtype: int64
检查和过滤异常值
data=DataFrame(np.random.randn(1000,4))
data.head()
0 1 2 3
0 -0.037801 -0.114125 -3.176546 -1.429600
1 -0.661482 0.463248 0.484711 0.472703
2 0.623268 0.643326 -1.104866 -0.776211
3 -1.289036 0.697960 0.676729 0.129446
4 1.737327 -0.023371 0.642303 -1.484452
# 描述统计
data.describe()
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean -0.052211 0.024592 -0.034262 -0.019984
std 0.985512 0.981705 1.038781 1.001963
min -3.168635 -3.914274 -3.311537 -3.790449
25% -0.723203 -0.627250 -0.744890 -0.672721
50% -0.056612 0.038724 0.000597 -0.025788
75% 0.623995 0.643587 0.658399 0.628468
max 3.364015 3.201296 2.941032 3.635790
# 筛选绝对值>3的
col=data[3]
col[np.abs(col)>3]
366 3.635790
624 3.072170
634 -3.790449
Name: 3, dtype: float64
# 全部绝对值>1
data[(np.abs(data)>3).any(1)]
0 1 2 3
0 -0.037801 -0.114125 -3.176546 -1.429600
85 0.729516 -0.714845 -3.181780 0.880925
191 0.745457 3.201296 -1.388863 -0.129746
265 -1.945317 -0.967863 -3.174635 -0.942325
360 -3.168635 1.322225 0.857038 0.785034
363 -0.692622 -3.452052 1.519987 2.441279
366 1.407668 -0.913443 0.405089 3.635790
414 1.441370 -0.053313 -3.134825 0.917022
425 0.558018 3.176739 -1.525225 -0.044710
439 -0.947407 3.068985 0.187254 -1.607603
445 -0.248250 -0.528560 -3.265440 0.916095
493 3.364015 0.086711 -2.107224 0.023489
533 1.243749 -0.178979 -3.311537 0.989587
612 0.365397 -3.914274 1.112423 0.152362
624 1.343073 0.644371 0.214362 3.072170
634 -1.771520 -1.624118 1.269436 -3.790449
694 -0.623029 0.292227 -3.235813 -0.395802
data[np.abs(data)>3]=np.sign(data)*3
data.describe()
0 1 2 3
count 1000.000000 1000.000000 1000.000000 1000.000000
mean -0.052406 0.025511 -0.032781 -0.019902
std 0.983795 0.975546 1.034377 0.996945
min -3.000000 -3.000000 -3.000000 -3.000000
25% -0.723203 -0.627250 -0.744890 -0.672721
50% -0.056612 0.038724 0.000597 -0.025788
75% 0.623995 0.643587 0.658399 0.628468
max 3.000000 3.000000 2.941032 3.000000
pandas读取数据
# 导入这个网站
import webbrowser
link='http://pandas.pydata.org/pandas-docs/version/0.20/io.html'
webbrowser.open(link)
# 读取网站表格
df2=pd.read_clipboard()
df2
以下这张表是用上面代码下载下来的,这是关于不同文件的读,存方法。
| Format Type | Data Description | Reader | Writer | |
|---|---|---|---|---|
| 0 | text | CSV | read_csv | to_csv |
| 1 | text | JSON | read_json | to_json |
| 2 | text | HTML | read_html | to_html |
| 3 | text | Local clipboard | read_clipboard | to_clipboard |
| 4 | binary | MS Excel | read_excel | to_excel |
| 5 | binary | HDF5 Format | read_hdf | to_hdf |
| 6 | binary | Feather Format | read_feather | to_feather |
| 7 | binary | Msgpack | read_msgpack | to_msgpack |
| 8 | binary | Stata | read_stata | to_stata |
| 9 | binary | SAS | read_sas | |
| 10 | binary | Python Pickle Format | read_pickle | to_pickle |
| 11 | SQL | SQL | read_sql | to_sql |
| 12 | SQL | Google Big Query | read_gbq | to_gbq |
# df1=pd.read_clipboard() #读取粘贴板上的内容
# df1.to_csv(sys.stdout,sep='|') # 显示出来
df2.to_csv('./df2.csv',index=False) # 不保存index
df3=pd.read_csv('./df2.csv') # 读取
df3
Format Type Data Description Reader Writer
0 text CSV read_csv to_csv
1 text JSON read_json to_json
2 text HTML read_html to_html
3 text Local clipboard read_clipboard to_clipboard
4 binary MS Excel read_excel to_excel
5 binary HDF5 Format read_hdf to_hdf
6 binary Feather Format read_feather to_feather
7 binary Msgpack read_msgpack to_msgpack
8 binary Stata read_stata to_stata
9 binary SAS read_sas
10 binary Python Pickle Format read_pickle to_pickle
11 SQL SQL read_sql to_sql
12 SQL Google Big Query read_gbq to_gbq
csv读取参数
- pd.read_csv(’/csv.csv’,sep=’,’,header=None,name=[‘a’,‘b’,‘c’])
- sep=分隔符
- header=
- name=表头
- index_col=‘a’ 以a列为索引
不规则的分隔符处理
- 正则表达式sep=’\s+’(针对一行,也是列间)
- skiprows=[1,4] 跳行(行之间存在不规则)
缺失值读取
- na_values=[‘null’]
- 多数可以用字典指定相对应的填充值,再na_values=dict
- na_rep=‘null’
read_csv/read_table 函数参数
| 参数 | 说明 |
|---|---|
| path | 表示文件系统位置、URL、文件型对象的字符串 |
| sep或delimlter | 用于对行中各字段进行拆分的字符序列或正则表达式 |
| header | 用作列名的行号。默认为0(第一行),如果没有header行就应该设置为None |
| index_col | 用作行索引的列编号或列名.可以是单个名称/数字或由多个名称/数字 组成的列表(层次化索引) |
| names | 用于结果的列名列表,结合header=None |
| skiprows | 需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0 幵始) |
| na_values | 一组用于替换NA的值 |
| comment | 用于将注释信息从行尾拆分出去的字符(一个或多个) |
| parse_dates | 尝试将数据解析为曰期,默认为False,如果为True,则尝试解析所有列,此外,还可以指定需要解析的一组列号或列名,如果列表的元素为列表或元组,就会将多个列组合到一起再进行曰期解析工作(例 如.曰期/时间分別位于两个列中) |
| keep_date_col | 如果连接多列解析曰期,则保持参与连接的列,默认为False |
| converters | 由列号/列名跟函数之间的映射关系组成的字典,例如,{‘foo’:f}会对 foo列的所有值应用函数f |
| dayfirst | 当解析有歧义的曰期时,将其看做国际格式(例如,7/6/2012 —June 7,2012) 。 馱认为False |
| date_parser | 用于解析曰期的函数 |
| nows | 需要读取的行数(从文件开始算起) |
| iterator | 返回一个TextParser以便逐块读取文件 |
| chunksize | 文件块的大小(用于迭代) |
| skip_footer | 需要忽略的行数(从文件末尾处算起) |
| verbose | 打印各种解析器输出信息,比如“非数值列中缺失值的数量"等 |
| encoding | 用于Unicode的文本编码格式。例如,“utf-8”表示用UTF-8编码的文本 |
| squeeze | 如果数据经解析后仅含一列,則返回Series |
| thousandas | 千分位分隔符,如",“或”." |
数据库的读取
import pandas as pd
from pandas import Series,DataFrame
import pymysql
conn=pymysql.connect(host='localhost',user='root',port=3306,password='1234',db='db',charset='utf8')
cur=conn.cursor()
sql="select * from doubanmovie"
df = pd.read_sql(sql,conn,index_col="ID")
df
name info rating num quote img_url
ID
cur.close
cur.close
<bound method Cursor.close of <pymysql.cursors.Cursor object at 0x000001E1A68F6320>>
聚合与分组计算
分组技术-GroupBy
- groups每个分组对应的位置
- size每个分组的大小(计数)
- 分组的最大值
- get_group分出北京单独一组
df=pd.read_csv(u'temp.csv')
df.head()
date tempertural city wind
0 2017-10-01 33 BJ 2
1 2017-10-02 36 BJ 3
2 2017-10-03 31 SH 4
3 2017-10-04 29 GZ 3
4 2017-10-05 30 SH 1
g=df.groupby(['city']) #根据城市分组
# groups每个分组对应的位置
print(g.groups)
# size每个分组的大小(计数)
print(g.size())
# 分组的最大值
print(g.max())
{
'BJ': Int64Index([0, 1, 6, 9, 11, 13, 14, 17, 22, 23, 25, 26, 27], dtype='int64'), 'GZ': Int64Index([3, 7, 8, 10, 15, 18, 20, 21, 24, 30], dtype='int64'), 'SH': Int64Index([2, 4, 5, 12, 16, 19, 28, 29], dtype='int64')}
*********************************************************************************************
city
BJ 13
GZ 10
SH 8
dtype: int64
*********************************************************************************************
date tempertural wind
city
BJ 2017-10-28 36 5
GZ 2017-10-31 32 6
SH 2017-10-30 33 5
# 分出北京单独一组get_group
bj=g.get_group('BJ')
bj.head()
date tempertural wind
0 2017-10-01 33 2
1 2017-10-02 36 3
6 2017-10-07 30 5
9 2017-10-10 32 5
11 2017-10-12 0 4
key1 key2 data1 data2
0 a one 0.668158 0.931483
1 a two 0.775910 0.653552
2 b one 0.528713 0.291508
3 b two 0.936786 0.173052
4 a one 0.210364 0.049781
# 根据key1,key2,进行分组,求平均值(三种写法)
grouped=df['data1'].groupby([df['key1'],df['key2']]).mean()
key1 key2
a one 0.439261
two 0.775910
b one 0.528713
two 0.936786
Name: data1, dtype: float64
df.groupby([df['key1'],df['key2']])[['data1']].mean()
data1
key1 key2
a one 0.439261
two 0.775910
b one 0.528713
two 0.936786
df.groupby(['key1','key2'])[['data1']].mean()
data1
key1 key2
a one 0.439261
two 0.775910
b one 0.528713
two 0.936786
# 没有指定哪列进行求平均值,默认全部
means=df.groupby(['key1','key2']).mean()
data1 data2
key1 key2
a one 0.301643 0.336847
two 0.135209 0.829968
b one 0.947798 0.606188
two 0.766954 0.107040
# 计数
df.groupby(['key1','key2']).size()
key1 key2
a one 2
two 1
b one 1
two 1
dtype: int64
# 分组并命名
for name,data in df.groupby('key1'):
print(name)
print(data)
a
data1 data2 key1 key2
0 0.068692 0.236280 a one
1 0.697486 0.469018 a two
4 0.868530 0.086073 a one
------------------------------------
b
data1 data2 key1 key2
2 0.941957 0.409646 b one
3 0.466520 0.521027 b two
pieces=dict(list(df.groupby('key1')))
# pieces
pieces['a']
data1 data2 key1 key2
0 0.540163 0.305852 a one
1 0.625073 0.987608 a two
4 0.629300 0.715550 a one
# 查看数据类型
df.dtypes
data1 float64
data2 float64
key1 object
key2 object
dtype: object
gr=df.groupby(df.dtypes,axis=1)
dict(list(gr))
{
dtype('float64'): data1 data2
0 0.582936 0.434599
1 0.135209 0.829968
2 0.947798 0.606188
3 0.766954 0.107040
4 0.020350 0.239096, dtype('O'): key1 key2
0 a one
1 a two
2 b one
3 b two
4 a one}
- as_index=False显示序列号
price
books
bk1 39
bk2 31
bk3 17
df.groupby('books',as_index=True).sum()
price
books
bk1 39
bk2 31
bk3 17
df.groupby('books',as_index=False).sum()
books price
0 bk1 39
1 bk2 31
2 bk3 17
通过字典、Series 分组
a b c d e
AA 0.913765 0.084771 0.498867 0.769994 0.904656
BB 0.359333 0.563282 0.103435 0.085575 0.677916
CC 0.359957 0.313697 0.599141 0.231513 0.108465
DD 0.469248 0.527980 0.712335 0.926182 0.034827
EE 0.299568 0.343068 0.489591 0.630986 0.664362
# 根据字典
mapping={
'a':'red','b':'red','c':'blue','d':'blue','e':'red'}
people.groupby(mapping,axis=1).sum()
out:
blue red
AA 1.268862 1.903192
BB 0.189010 1.600531
CC 0.830654 0.782119
DD 1.638517 1.032055
EE 1.120578 1.306998
# 根据series
# 根据字典创建一个series
map_series=Series(mapping)
map_series
a red
b red
c blue
d blue
e red
dtype: object
people.groupby(map_series,axis=1).count()
out:
blue red
AA 2 3
BB 2 3
CC 2 3
DD 2 3
EE 2 3
数据聚合
pandas常用的聚合函数
| 函数 | 说明 |
|---|---|
| count | 分组中非NA值的数量 |
| sum | 非NA值的和 |
| mean | 非NA值的平均值 |
| median | 非NA值的中位数 |
| std、var | 无偏(分母为n-1)标准差、方差 |
| max、min | 非NA值的最大值、最小值 |
| prod | 非NA值的积 |
| first、last | 第一个和最后一个非NA值 |
自定义函数agg传入函数
df_obj5
data1 data2 key1 key2
0 5 8 a one
1 8 5 b two
2 9 1 a one
3 3 7 b three
4 3 2 a two
5 9 1 b two
6 2 2 a one
7 3 1 a three
def peak_range(df):
return df.max()-df.min()
df_obj5.groupby(['key1','key2']).agg(peak_range)
data1 data2
key1 key2
a one 7 7
three 0 0
two 0 0
b three 0 0
two 1 4
# 传内置函数
df_obj5.groupby('key1').agg(['mean','std','count',peak_range]).round(2)
data1 data2
mean std count peak_range mean std count peak_range
key1
a 5.00 3.39 5 8 2.40 2.19 5 5
b 3.33 0.58 3 1 5.67 2.52 3 5
df_obj5.groupby('key1').agg([('均值','mean'),('标准差','std'),('数量','count'),('范围',peak_range)]).round(2)
data1 data2
均值 标准差 数量 范围 均值 标准差 数量 范围
key1
a 5.00 3.39 5 8 2.40 2.19 5 5
b 3.33 0.58 3 1 5.67 2.52 3 5
# 传入字典对data1、data2分别使用不同函数聚合
dict2={
'data1':'mean','data2':'sum'}
df_obj5.groupby('key1').agg(dict2)
data1 data2
key1
a 5.000000 12
b 3.333333 17
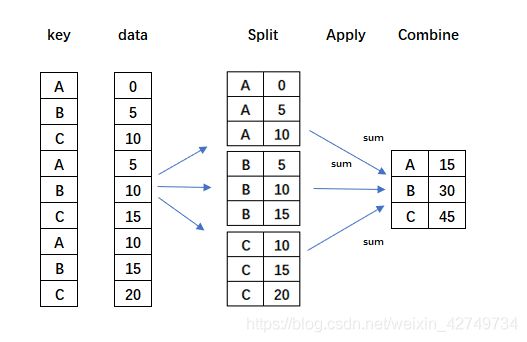
apply传入函数
data:
a b c d e sum
AA 0.550665 0.041065 0.890058 0.301983 0.583259 2.367030
BB 0.202899 0.023876 0.130807 0.371706 0.841696 1.570984
CC 0.667555 0.715283 0.457599 0.961007 0.214447 3.015890
DD 0.122853 0.593505 0.533650 0.621203 0.148557 2.019769
EE 0.688667 0.592045 0.606912 0.377382 0.193057 2.458063
data['on']=['Y','Y','N','Y','N']
def top(df,n=5,column='sum'):
return df.sort_values(by=column,ascending=False)[:n]
top(data,n=3)
a b c d e sum on
CC 0.667555 0.715283 0.457599 0.961007 0.214447 3.015890 N
EE 0.688667 0.592045 0.606912 0.377382 0.193057 2.458063 N
AA 0.550665 0.041065 0.890058 0.301983 0.583259 2.367030 Y
data.groupby('on').apply(top)
a b c d e sum on
on
N CC 0.667555 0.715283 0.457599 0.961007 0.214447 3.015890 N
EE 0.688667 0.592045 0.606912 0.377382 0.193057 2.458063 N
Y AA 0.550665 0.041065 0.890058 0.301983 0.583259 2.367030 Y
DD 0.122853 0.593505 0.533650 0.621203 0.148557 2.019769 Y
BB 0.202899 0.023876 0.130807 0.371706 0.841696 1.570984 Y
agg与apply的区别
https://blog.csdn.net/fanfanyuzhui/article/details/78503608
相同点:
都能针对Dataframe的特征的计算,常与groupby()方法连用
不同点:
- agg():
调用时要指定字段:df[‘AA’],apply默认传入整个Dataframe
- apply():
参数可以是自定义函数,包括简单的求和函数以及复制的特征间的差值函数等。apply不能直接使用python的内置函数,比如sum、max、min。
- transform():
参数不能是自定义的特征交互函数,因为transform是针对每一元素(即每一列特征操作)进行计算。使用transform要注意:
它只能对每一列进行计算,所以在groupby之后,transform之前是要指定操作的列,这点与apply有很大的不同
由于是对每一列进行计算,所以方法通用性性比apply就局限了很多,例如,只能求列的最大值,最小值,均值,方差,分箱等操作。
处理效率上:
agg()函数+内置函数是计算速度最快的,其次是transform()+内置方法。
agg()或者apply()+自定义函数的处理速度差不多,而这里特别要注意transform()+自定义函数计算速度是最慢的,尽量避免使用。
分位数和桶分析
# 先进行四分位
df=DataFrame({
'data1':np.random.rand(1000),'data2':np.random.rand(1000)})
quartiles=pd.cut(df.data1,4)
quartiles[:10]
0 (0.749, 0.999]
1 (0.25, 0.499]
2 (-0.000922, 0.25]
3 (0.749, 0.999]
4 (0.25, 0.499]
5 (0.499, 0.749]
6 (0.499, 0.749]
7 (-0.000922, 0.25]
8 (0.25, 0.499]
9 (0.749, 0.999]
Name: data1, dtype: category
Categories (4, interval[float64]): [(-0.000922, 0.25] < (0.25, 0.499] < (0.499, 0.749] < (0.749, 0.999]]
# 定义一个函数
def get_stats(group):
return {
'min':group.min(),'max':group.max(),'count':group.count(),'mean':group.mean()}
grouped=df.data2.groupby(quartiles)
grouped.apply(get_stats).unstack()
out:
count max mean min
data1
(-0.000922, 0.25] 257.0 0.999352 0.506744 0.010041
(0.25, 0.499] 246.0 0.995052 0.525825 0.010561
(0.499, 0.749] 239.0 0.999515 0.494211 0.000945
(0.749, 0.999] 258.0 0.999476 0.503396 0.001738
分组加权平均数
df=DataFrame({
'category':['a','a','a','b','b','b'],'data':np.random.rand(6),'weight':np.random.rand(6)})
df
category data weight
0 a 0.857748 0.483854
1 a 0.780560 0.470261
2 a 0.107323 0.554079
3 b 0.159418 0.591490
4 b 0.775190 0.800363
5 b 0.568241 0.896928
grouped=df.groupby('category')
get_vavg=lambda g:np.average(g['data'],weights=g['weight'])
grouped.apply(get_vavg)
category
a 0.557990
b 0.534957
dtype: float64
透视表
两种方法一样
df.pivot_table(index=['day','smoker'])
df.groupby(['day','smoker']).mean()
pivot_table的参数说明
pivo_table(data, values=None,
index = None,
columns = None,
aggfunc = 'mean',
fill_values = None,
margins = False,
dropna = True,
margind_name = 'All')
| 函数名 | 说明 |
|---|---|
| values | 待聚合的列的名称。默认聚合所有数值列 |
| index | 用于分组的列名或其他分组键,出现在结果透视表的行 |
| columns | 用于分组的列名或其他分组键,出现在结果透视表的列 |
| aggfunc | 聚合函数或函数列表.默认为mean。可以是任何对groupby有效的函数 |
| fill_values | 用于替换结果表中的缺失值 |
| dropna | 如果为True,不添加条目都为NA的列 |
| margins | 添加行/列小计和总计,默认为False |
| margins_name | 默认行汇总和列汇总的名称为All |
透视表
df1:
total_bill tip smoker day time size tip_pct
0 16.99 1.01 No Sun Dinner 2 0.059447
1 10.34 1.66 No Sun Dinner 3 0.160542
2 21.01 3.50 No Sun Dinner 3 0.166587
3 23.68 3.31 No Sun Dinner 2 0.139780
4 24.59 3.61 No Sun Dinner 4 0.146808
df1.pivot_table(index=['day','smoker'])
size tip tip_pct total_bill
day smoker
Fri No 2.250000 2.812500 0.151650 18.420000
Yes 2.066667 2.714000 0.174783 16.813333
Sat No 2.555556 3.102889 0.158048 19.661778
Yes 2.476190 2.875476 0.147906 21.276667
Sun No 2.929825 3.167895 0.160113 20.506667
Yes 2.578947 3.516842 0.187250 24.120000
Thur No 2.488889 2.673778 0.160298 17.113111
Yes 2.352941 3.030000 0.163863 19.190588
df1.pivot_table(['tip_pct','size'],index=['time','day'],columns='smoker')
size tip_pct
smoker No Yes No Yes
time day
Dinner Fri 2.000000 2.222222 0.139622 0.165347
Sat 2.555556 2.476190 0.158048 0.147906
Sun 2.929825 2.578947 0.160113 0.187250
Thur 2.000000 NaN 0.159744 NaN
Lunch Fri 3.000000 1.833333 0.187735 0.188937
Thur 2.500000 2.352941 0.160311 0.163863
df1.pivot_table(['tip_pct','size'],index=['time','day'],columns='smoker',margins=True)
size tip_pct
smoker No Yes All No Yes All
time day
Dinner Fri 2.000000 2.222222 2.166667 0.139622 0.165347 0.158916
Sat 2.555556 2.476190 2.517241 0.158048 0.147906 0.153152
Sun 2.929825 2.578947 2.842105 0.160113 0.187250 0.166897
Thur 2.000000 NaN 2.000000 0.159744 NaN 0.159744
Lunch Fri 3.000000 1.833333 2.000000 0.187735 0.188937 0.188765
Thur 2.500000 2.352941 2.459016 0.160311 0.163863 0.161301
All 2.668874 2.408602 2.569672 0.159328 0.163196 0.160803
df1.pivot_table('tip_pct',index=['time','smoker'],columns='day',aggfunc=len,margins=True)
day Fri Sat Sun Thur All
time smoker
Dinner No 3.0 45.0 57.0 1.0 106.0
Yes 9.0 42.0 19.0 NaN 70.0
Lunch No 1.0 NaN NaN 44.0 45.0
Yes 6.0 NaN NaN 17.0 23.0
All 19.0 87.0 76.0 62.0 244.0
df1.pivot_table('tip_pct',index=['time','smoker'],columns='day',aggfunc='mean',margins=True,fill_value=0)
day Fri Sat Sun Thur All
time smoker
Dinner No 0.139622 0.158048 0.160113 0.159744 0.158653
Yes 0.165347 0.147906 0.187250 0.000000 0.160828
Lunch No 0.187735 0.000000 0.000000 0.160311 0.160920
Yes 0.188937 0.000000 0.000000 0.163863 0.170404
All 0.169913 0.153152 0.166897 0.161276 0.160803
jicha=lambda df:df.max()-df.min()
df1.pivot_table('tip_pct',index=['time','smoker'],columns='day',aggfunc=jicha,margins=True,fill_value=0)
day Fri Sat Sun Thur All
time smoker
Dinner No 0.035239 0.235193 0.193226 0.00000 0.235193
Yes 0.159925 0.290095 0.644685 0.00000 0.674707
Lunch No 0.000000 0.000000 0.000000 0.19335 0.193350
Yes 0.141580 0.000000 0.000000 0.15124 0.169300
All 0.159925 0.290095 0.650898 0.19335 0.674707
应用groupby实现透视
df1:
total_bill tip smoker day time size tip_pct
0 16.99 1.01 No Sun Dinner 2 0.059447
1 10.34 1.66 No Sun Dinner 3 0.160542
2 21.01 3.50 No Sun Dinner 3 0.166587
3 23.68 3.31 No Sun Dinner 2 0.139780
4 24.59 3.61 No Sun Dinner 4 0.146808
def aa(df,n=5,cols='tip_pct'):
return df[cols].sort_values()[-n:]
aa(df1)
183 0.280535
232 0.291990
67 0.325733
178 0.416667
172 0.710345
Name: tip_pct, dtype: float64
def aa(df,n=5,cols='tip_pct'):
return df.sort_values(by=cols)[-n:]
aa(df1)
total_bill tip smoker day time size tip_pct
183 23.17 6.50 Yes Sun Dinner 4 0.280535
232 11.61 3.39 No Sat Dinner 2 0.291990
67 3.07 1.00 Yes Sat Dinner 1 0.325733
178 9.60 4.00 Yes Sun Dinner 2 0.416667
172 7.25 5.15 Yes Sun Dinner 2 0.710345
df1.groupby('smoker').apply(aa)
total_bill tip smoker day time size tip_pct
smoker
No 88 24.71 5.85 No Thur Lunch 2 0.236746
185 20.69 5.00 No Sun Dinner 5 0.241663
51 10.29 2.60 No Sun Dinner 2 0.252672
149 7.51 2.00 No Thur Lunch 2 0.266312
232 11.61 3.39 No Sat Dinner 2 0.291990
Yes 109 14.31 4.00 Yes Sat Dinner 2 0.279525
183 23.17 6.50 Yes Sun Dinner 4 0.280535
67 3.07 1.00 Yes Sat Dinner 1 0.325733
178 9.60 4.00 Yes Sun Dinner 2 0.416667
172 7.25 5.15 Yes Sun Dinner 2 0.710345
df1.groupby(['smoker','day']).apply(aa,n=1,cols='total_bill')
total_bill tip smoker day time size tip_pct
smoker day
No Fri 94 22.75 3.25 No Fri Dinner 2 0.142857
Sat 212 48.33 9.00 No Sat Dinner 4 0.186220
Sun 156 48.17 5.00 No Sun Dinner 6 0.103799
Thur 142 41.19 5.00 No Thur Lunch 5 0.121389
Yes Fri 95 40.17 4.73 Yes Fri Dinner 4 0.117750
Sat 170 50.81 10.00 Yes Sat Dinner 3 0.196812
Sun 182 45.35 3.50 Yes Sun Dinner 3 0.077178
Thur 197 43.11 5.00 Yes Thur Lunch 4 0.115982
df1.groupby(['smoker','day'],group_keys=False).apply(aa,n=1,cols='total_bill')
total_bill tip smoker day time size tip_pct
94 22.75 3.25 No Fri Dinner 2 0.142857
212 48.33 9.00 No Sat Dinner 4 0.186220
156 48.17 5.00 No Sun Dinner 6 0.103799
142 41.19 5.00 No Thur Lunch 5 0.121389
95 40.17 4.73 Yes Fri Dinner 4 0.117750
170 50.81 10.00 Yes Sat Dinner 3 0.196812
182 45.35 3.50 Yes Sun Dinner 3 0.077178
197 43.11 5.00 Yes Thur Lunch 4 0.115982