SQL批量新增数据(后续)
今天大年初七,新的一年的打工生活又开始了,先祝大家工作顺利!学业进步!

今天主要是处理当初遗留问题的一篇博客
可查看博客 : SQL批量新增数据 了解前因 ~~
在上一次的批量中,在数据量较大的时候,会导致insert非常慢,出现假死状态等,具体可看上边连接
对于这个问题,在当初出现后不久就已经有解决方案了,但是一直没有合适的时间进行整理
问题原因:I/O
简单说可以把insert作为守门人开合一扇门,数据作为一个人,我们原方法做的就是进一个人,就开一次门,然后在开合的时候,那个开门的人就会累
我们也可以拿核算检测做类比:最开始的时候我们都是一人一次的检查,每个人都需要一份试剂,这在早期也是很慢的,假如是一个人一直做,那就会存在效率变低,所以要轮班保证效率,但是我们执行SQL的时候,是没有可以轮班的,等于是一个人在把百万人的核算检测做了(一次处理多笔)。后边技术提升了,我们可以把检测结果这条路,做成10人合到一个试剂检查,等于提高了10倍的效率,再者,我们不止一个人,我们有众多的医护人员,志愿者等,又加快了获取数据了效率(多线程)
由上结论,我们在SQL上,今天使用的方案1使用的就是一次处理多笔这步流程(多线程得使用程序)
因目前技术有限,这也就只是方案1,后续或许会有更好的方法,也会更新进来,或者添加链接
进入方案1的正题:
1、新建数据库表
--BatchAddData_20210218
--新加一个表,用来测试本次的批量新增数据
if NOT exists (select * from dbo.sysobjects where id = object_id(N'[dbo].[BatchAddData_20210218]') and OBJECTPROPERTY(id, N'IsUserTable') = 1)
BEGIN
CREATE TABLE [dbo].[BatchAddData_20210218](
[ID] [int] IDENTITY(1,1) NOT NULL, --主键ID
[CreationTime] [datetime] NULL,--创建时间
[Remark][nvarchar](MAX) NULL --备注
)
END
GO
--select *from BatchAddData_202102182、先使用原方法做 测试
--批量数据
--循环添加数据
declare @i int --声明一个变量
set @i=1 --给变量赋值(初始化)
while @i<10 --循环插入
begin
insert into BatchAddData_20210218 (CreationTime,Remark)
values ( GETDATE(),'SQL批量新增[20200218]-第一轮');
set @i=@i+1
end
GO2.1 结果
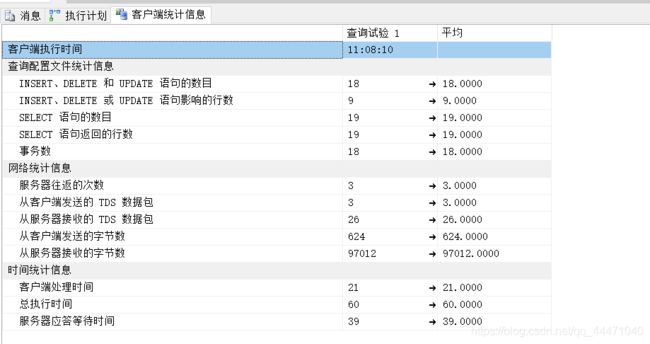
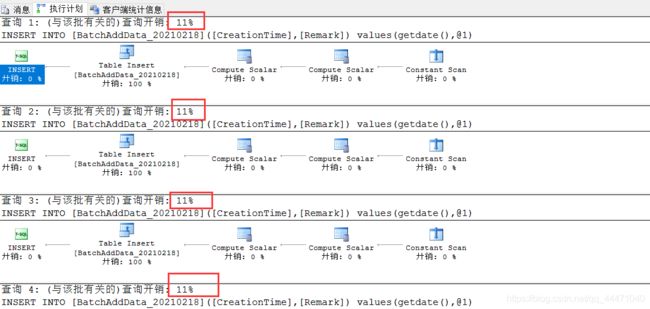
由图可见,数据较少的时候,执行还是非常的顺利的。
一百、一千、一万...百万的我就不在这 测试来了
3、使用新方法,上边是10条数据,那我把他分成2*5,也就是执行两个insert即可
--批量数据
--循环添加数据
declare @i int --声明一个变量
set @i=1 --给变量赋值(初始化)
while @i<=2 --循环插入
begin
insert into BatchAddData_20210218 (CreationTime,Remark)
values ( GETDATE(),'SQL批量新增[20200218]-第二轮:2*5')
,( GETDATE(),'SQL批量新增[20200218]-第二轮:2*5')
,( GETDATE(),'SQL批量新增[20200218]-第二轮:2*5')
,( GETDATE(),'SQL批量新增[20200218]-第二轮:2*5')
,( GETDATE(),'SQL批量新增[20200218]-第二轮:2*5')
;
set @i=@i+1
end
GO3.1 结果
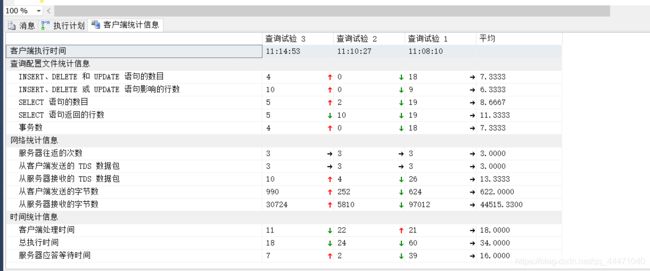

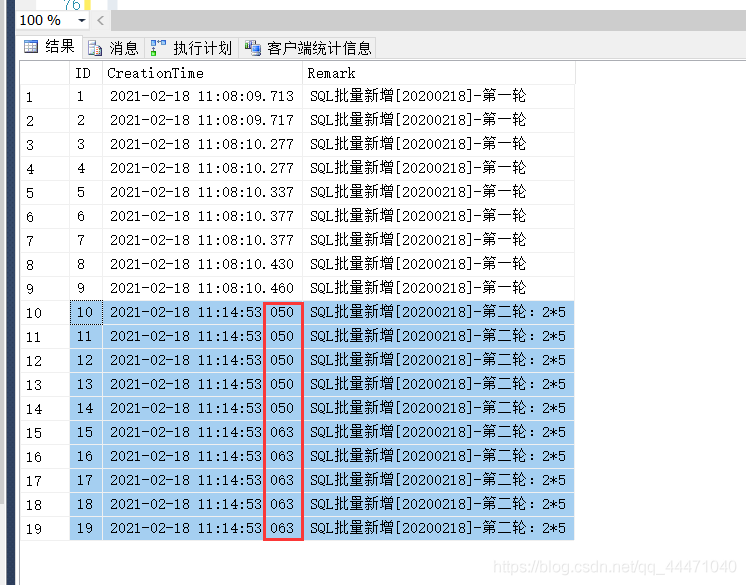
从上图图3可以直观的看到,10条数据在毫秒内就处理完成了,图1的总执行时间也缩小了近5倍。
4、思考
4.1 假如新方法这么好用,那我不是可以一次就把10条insert 了?答案肯定是可以的,但是假如又回到百万数据呢,又该如何?
5 处理百万数据
5.1 拆分 100*1000 或者 1000*1000,在处理SQL的时候,我们不可能把数据写的太死,这里至少在循环SQL时的SQL拼接得处理
5.2 测试1000
--批量数据(1000)
--循环添加数据
declare @i int --声明一个变量
set @i=1 --给变量赋值(初始化)
declare @j int --声明一个变量
set @j=1 --给变量赋值(初始化)
declare @execSQL nvarchar(max) --拼接SQL
--set @execSQL ='insert into BatchAddData_20210218 (CreationTime,Remark)' --给变量赋值(初始化)
while @i<=10 --循环插入
begin
--放入外循环
set @execSQL ='insert into BatchAddData_20210218 (CreationTime,Remark)' --给变量赋值(初始化)
--------------内循环:拼接SQL ---------------------------------------
while @j<=10 --循环插入
begin
if(@j=1)
begin
set @execSQL +='values ( GETDATE(),''SQL批量新增[20200218]-第三轮:100*100'')'
set @j=@j+1
end
if(@j!=1)
begin
set @execSQL +=', ( GETDATE(),''SQL批量新增[20200218]-第三轮:100*100'')'
set @j=@j+1
end
end
---------------------------------------------------------------------
--print @execSQL
EXEC ( @execSQL ) --执行拼接好的SQL
set @execSQL = '' --清除(可无)
set @j= 1;
set @i=@i+1
end
GO
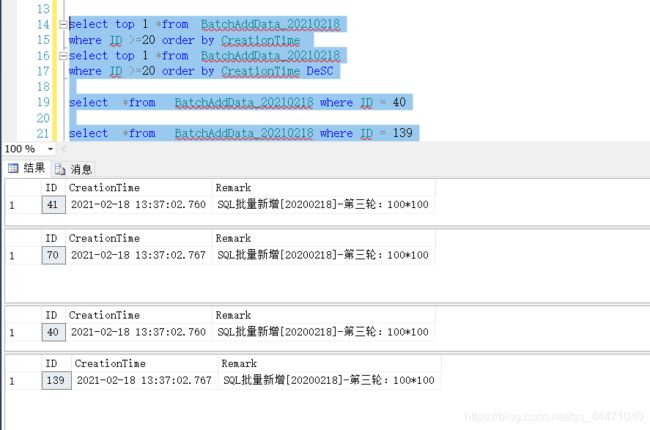
5.2.1 结果 从结果看,第二和第四的时间一致,还是存在有误的可能性

5.3 优化
5.3.1 重新写批量SQL(为了效果)
--批量数据(1000)
--循环添加数据
declare @i int --声明一个变量
set @i=1 --给变量赋值(初始化)
declare @j int --声明一个变量
set @j=1 --给变量赋值(初始化)
declare @sum int --声明一个变量
set @sum=1 --给变量赋值(初始化)
declare @execSQL nvarchar(max) --拼接SQL
--set @execSQL ='insert into BatchAddData_20210218 (CreationTime,Remark)' --给变量赋值(初始化)
while @i<=10 --循环插入
begin
--放入外循环
set @execSQL ='insert into BatchAddData_20210218 (CreationTime,Remark)' --给变量赋值(初始化)
--------------内循环:拼接SQL ---------------------------------------
while @j<=10 --循环插入
begin
if(@j=1)
begin
set @execSQL +=' values ( GETDATE(),'''+CONVERT(nvarchar(max),@sum)+'''+''第4轮,10*10'')'
set @j=@j+1
set @sum = @sum +1;
end
if(@j!=1)
begin
set @execSQL +=', ( GETDATE(),'''+CONVERT(nvarchar(max),@sum)+'''+''第4轮,10*10'')'
set @j=@j+1
set @sum = @sum +1;
end
--set @sum = @sum +1;
end
---------------------------------------------------------------------
--print @execSQL
EXEC ( @execSQL ) --执行拼接好的SQL
set @execSQL = '' --清除(可无)
set @j= 1;
set @i=@i+1
end
GO
5.3.2 结果 :效果还是相对可以,那么,我们就开始测试百万数据情况
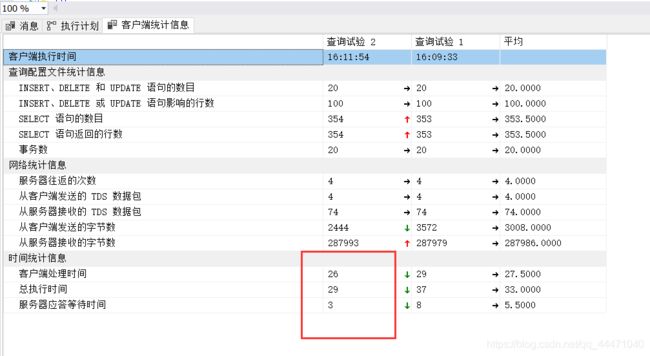

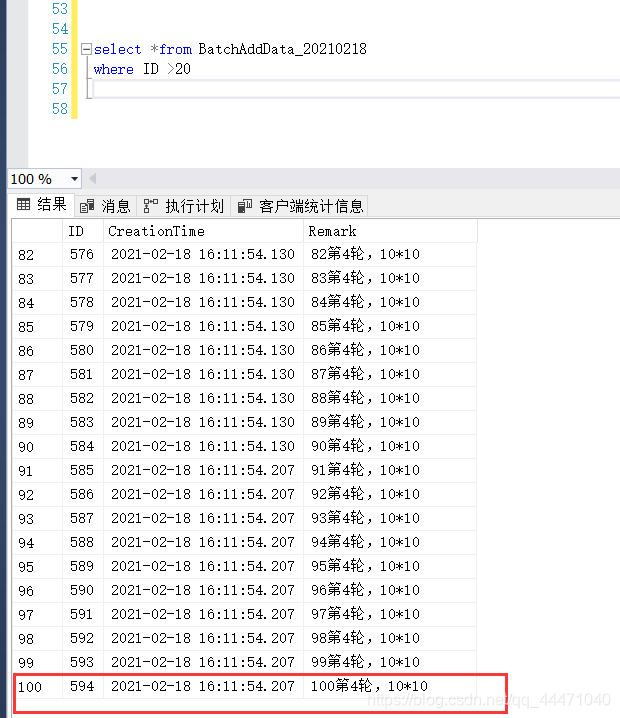
6、百万数据 测试
方案1 : 100*10000 ,失败,内循环超过1000
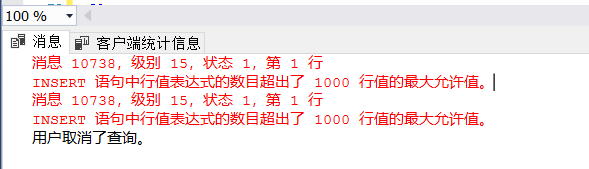
方案2 : 1000*1000 可行,但是数据库还是有点卡顿,最后一段时间是7秒刷新一次,一次外循环的时间
同样的,外循环处理数据达到一定量的时候,他也会变慢,从开始的1秒跳,到最后的7秒跳
但是数据量较大,还是没有等待全部执行(目前是10分钟33秒,113000笔数据,insert了11.3%的数据)
1%的占比应该是不可能的,可能是SQL Server 数据库最小单位就是1%吧。
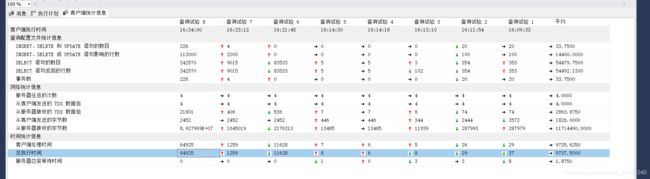

方案3 : 10000*100
在处理别的,没把握好时间,(目前是12分钟27秒,27400笔数据,insert了27.4%的数据)
相比于方案2,多使用了2分钟,但是数据量却是比方案2多了一倍多的数据量,物极必满,最大量1000的还是只最为最大使用,并不是最高效率的情况
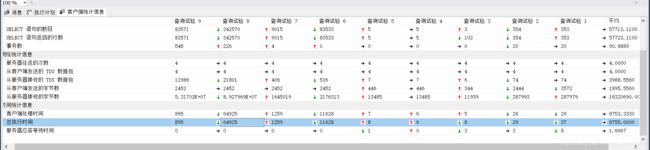
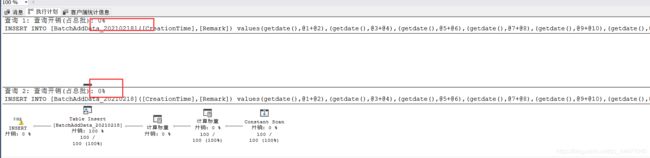
方案4 :由上述的出,我们内循环的值还可以在100 - 1000内取值,像200,500,等,都可再测试,我这也就不再测试了
总的来说,还是没有达到我理想的速度,还有待提高。
同时,这个还可以做成存储过程,直接调用,也没啥参数。
拓展:
1、这里的数据还是限制于数据库,假如使用程序的话,使用多线程,开5-8-10个,速度理论提升了5-8-10倍,但是同样的高频率的IO,是否又是假死呢?
2、假如数据不是整数,是其他数,该如何?比如1234条数据?123456条数据?
3、是否存在一个已知总数,得出最优内外循环值的可能性?
....
我是一个人三座城
一个人生活在三座城市,过去、现在、将来.
期待你的关注!