python+tensorflow2.x+opencv搭建真实场景下的手写数字识别
python+tensorflow2.x+opencv搭建真实场景下的手写数字识别
- 初步成果
- 第一步训练手写数字模型
-
- 引入需要的库文件
- 读取数据
- 看一下数据什么样
- 数据归一化
- 搭建模型
- 固化模型
- 训练模型
- 看一下我们的训练成果
- 用模型预测一个数据
- 保存模型
- opencv计算机视觉部分
-
- 先引入必须的库文件
- 必要的全局变量
- 写一个函数用来查看图片
- 读取图片
- 改变图片大小
- 灰度化处理
- 边缘检测
- 闭运算
- 在图片外围加上边框
- 获取边框
- 最后一步,识别加标注
- 全部程序
-
- 模型训练代码
- 视觉部分代码
初步成果
大概的正确率在百分之90左右,但模型训练过程没有做任何数据增强,所以模型仍可进一步加强

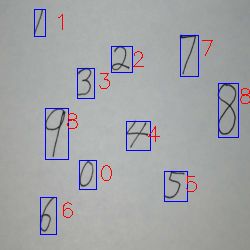
第一步训练手写数字模型
引入需要的库文件
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import tensorflow as tf
from tensorflow import keras
在这里numpy和pandas是在对数据处理时用到的库文件
matplotlib 是python里非常有名的画图库
tensorflow是我们要训练模型的主要框架
keras是tf的官方前端,这样可以减少我们写的代码,让逻辑更加清晰
读取数据
数据这里我们先用的官方MNIST数据进行训练
在tensorflow keras里直接定义了这个数据集的下载路径,我们直接调用方法从网站上下载下来就可以
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()#在这里我们调用这个方法后直接就可以把数据集分成训练集和测试集,
x_train = x_train.reshape(-1,28,28,1)#在这里因为下面要通入模型时需要图片数据是四维数据,这里就把数据转成四维,最后的一是指图片通道数,因为我们的图片本来就是只有一个通道(RGB有三个通道)所以直接写成一
x_test = x_test.reshape(-1,28,28,1)
print(x_train.shape)#在这里读取各个数据集类型的形状,查看一下有没有问题
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
"""
(60000, 28, 28, 1)
(60000,)
(10000, 28, 28, 1)
(10000,)
"""
这里看出来训练集有六万张图片(每张图片28×28×1)
训练集标签有60000个每个都是0维(点嘛,一个数据就是零维)
测试集有一万张图片
测试集标签也有一万个
看一下数据什么样
def show_single_image(img_arr):#这里定义了一个函数用来查看图片
img_arr = img_arr.reshape(28,28)#把输入进来的数据都变成28×28的这样才能展示数据
plt.imshow(img_arr,cmap = "binary")#显示图片,具体的话可以看我matplotlib的教程
plt.show()
show_single_image(x_train[0])#这里我们输入的训练集的第一张图片,可以通过中括号里的数字看其他不同的数据

数据归一化
x_train = x_train/255.
x_test = x_test/255.
把数据都变成0-1的范围这样方便训练,提高收敛速度
搭建模型
model = keras.models.Sequential() #先生成一个模型框架
model.add(keras.layers.Conv2D(filters = 128,#在这里定义了一个卷积核的数量
kernel_size = 3,
padding = 'same',#这里选择模式是same也就是说卷积层不会改变模型大小
activation = 'selu',#激活函数选择selu这是一个自带归一化的激活函数
input_shape = (28,28,1)#这里设置输入数据大小
))
model.add(keras.layers.SeparableConv2D(filters = 128,
kernel_size = 3,
padding = 'same',
activation = 'selu',
))
model.add(keras.layers.MaxPool2D(pool_size = 2))#池化层在这里我们只规定了池化层核心的大小
model.add(keras.layers.SeparableConv2D(filters = 256,
kernel_size = 3,
padding = 'same',
activation = 'selu',
))
model.add(keras.layers.SeparableConv2D(filters = 256,
kernel_size = 3,
padding = 'same',
activation = 'selu',
))
model.add(keras.layers.MaxPool2D(pool_size = 2))
model.add(keras.layers.SeparableConv2D(filters = 512,
kernel_size = 3,
padding = 'same',
activation = 'selu',
))
model.add(keras.layers.SeparableConv2D(filters = 512,
kernel_size = 3,
padding = 'same',
activation = 'selu',
))
model.add(keras.layers.MaxPool2D(pool_size = 2))
model.add(keras.layers.Flatten())#在上几个层次中我们输出的数据仍然是三维的,在这里要把数据展平变成一维
model.add(keras.layers.Dense(128,activation = 'selu'))#全连接没什么可多说的,具体参照多层感知机模型
model.add(keras.layers.Dense(10,activation = 'softmax'))#softmax将输入数值变成概率的模式
固化模型
model.compile(optimizer='adam',#求解模型的方法
loss='sparse_categorical_crossentropy',#损失函数
metrics=['accuracy'])#评判模型的方法
训练模型
history = model.fit(#history用来接收训练过程中的训练过程参数
x_train, y_train,# 训练集的数据和标签
epochs = 5, #训练5遍
validation_data = (x_test,y_test) )#实时展示模型训练情况
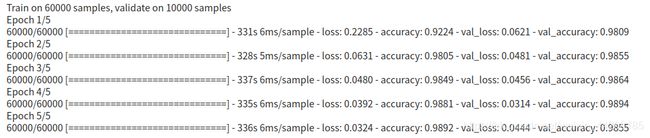
看一下我们的训练成果
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid(True)#画网格
plt.gca().set_ylim(0,1.5)
plt.show()
plot_learning_curves(history)#(输入训练时的返回值)
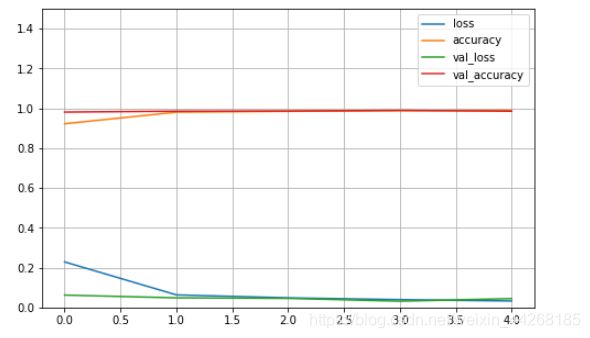
用模型预测一个数据
def predict_data(test_data):#定义一个函数
pred = model.predict(test_data.reshape(-1,28,28,1))#先把数据转化成之前我们训练集数据一样的通入方式
return np.argmax(pred)#返回输出神经元中最大值的索引
show_single_image(x_test[0])
print("模型的预测结果是:",predict_data(x_test[0]))
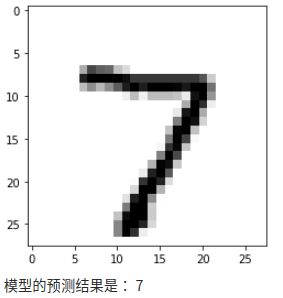
保存模型
model.save('my_model.h5')
好啦现在我们就有了作为识别的手写数字识别分类器的模型
opencv计算机视觉部分
先引入必须的库文件
import tensorflow as tf
from tensorflow import keras
import cv2
import numpy as np
import matplotlib.pyplot as plt
必要的全局变量
font = cv2.FONT_HERSHEY_SIMPLEX#我们设置写数字的字体
model =keras.models.load_model('my_model.h5') #读取之前训练好的数据模型
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(3,3))#
image_path = "z.png"#在这里写入图片路径
写一个函数用来查看图片
def look_image(data):
plt.figure()#重新显示一张图图片在一个独立窗口
data = cv2.cvtColor(data, cv2.COLOR_BGR2RGB)#因为opencv是bgr模式所以转换成rgb模式,使用cv的显示图片方法也可以,不过有的系统可能不支持为了兼容性我们采用这种方法,真实部署里可能压根不需要显示图片
plt.imshow(data)#显示图片
读取图片
image = cv2.imread(image_path)#读取图片
look_image(image)#显示图片

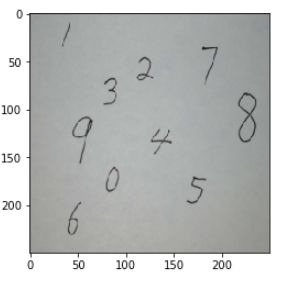
改变图片大小
可以看到图片大小是1000多×1000多,这里数据太大了
我们把它压缩到250×250
这样不仅数据量小了,而且小的点状噪声也被去除了
image_ = cv2.resize(image, (250,250), interpolation = cv2.INTER_AREA)#在这里用了image_接收变量,因为后面还要用到这个数据
look_image(image_)#显示图片
灰度化处理
image = cv2.cvtColor(image_, cv2.COLOR_BGR2GRAY)#灰度化处理

在这里可能看不出什么,但图片通道数变成了1
边缘检测
img_w = cv2.Sobel(image,cv2.CV_16S,0,1)#Sobel滤波,边缘检测(横)
img_h = cv2.Sobel(image,cv2.CV_16S,1,0)#Sobel滤波,边缘检测(竖)这里我试过横竖边缘一起提取效果不太好
img_w = cv2.convertScaleAbs(img_w)
_, img_w = cv2.threshold(img_w,0,255,cv2.THRESH_OTSU|cv2.THRESH_BINARY)#二值化数据
look_image(img_w)
img_h = cv2.convertScaleAbs(img_h)
_, img_h = cv2.threshold(img_h,0,255,cv2.THRESH_OTSU|cv2.THRESH_BINARY)
look_image(img_h)
image = img_w + img_h#把两个边缘检测结果进行整合,免得出现数字断头现象
look_image(image)

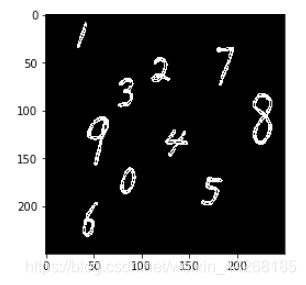
闭运算
在前面的图片里可以看到数字中间有小的洞洞,这会影响我们之后的模型判断所以这里用闭运算去除这些
image = cv2.morphologyEx(image,cv2.MORPH_CLOSE,kernel)#这里的kernel是之前定义的
look_image(image)

在图片外围加上边框
后面获取的边框是紧贴着数字的,但训练集不是这样,所以我们要手动扩大边框,为了防止数字本就出现在边缘的情况所以给图片加个框
#在这里就是创建几个numpy数组把它和数据进行合并
temp_data = np.zeros((250,10))
image = np.concatenate((temp_data,image,temp_data),axis = 1)
temp_data = np.zeros((10,270))
image = np.concatenate((temp_data,image,temp_data),axis = 0)
image = cv2.convertScaleAbs(image)
look_image(image)
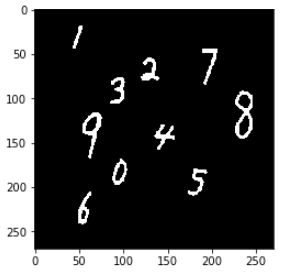
获取边框
contours, hierarchy = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
最后一步,识别加标注
for _ in contours:#对边框进行便利
x,y,w,h = cv2.boundingRect(_)#获取边框的坐标和长宽
if w*h < 100:#定义一下面积,太小的边框直接舍弃
continue
img_model = image[y-10:y+h+10,x-10:x+w+10]#手动扩大边框并截取
img_model = cv2.resize(img_model, (28,28), interpolation = cv2.INTER_AREA)#将截取到的数字改变大小(28×28)因为我们训练的时候图片大小就是28×28
img_model = img_model/255#数据归一化
predict = model.predict(img_model.reshape(-1,28,28,1))#用神经网络进行判断
if np.max(predict) > 0.5:#只显示置信率百分之50以上的数据
data_predict = str(np.argmax(predict))#将得到的神经网络输出最大的索引转换成字符串(后面写必须要字符串形式)
image_z = cv2.rectangle(image_,(x-10,y-10),(x + w-10,y + h-10),(255,0,0),1)#画框
image_z = cv2.putText(image_z,data_predict , (x+10, y+10), font, 0.7, (0, 0, 255), 1)#写文字
look_image(image_z)#显示图片
save = cv2.imwrite( "image_predict.png",image_z)#保存图片
好到此就全都结束了
全部程序
模型训练代码
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
import pandas as pd
from tensorflow import keras
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.reshape(-1,28,28,1)
x_test = x_test.reshape(-1,28,28,1)
print(x_train.shape)
print(y_train.shape)
print(x_test.shape)
print(y_test.shape)
def show_single_image(img_arr):
img_arr = img_arr.reshape(28,28)
plt.imshow(img_arr,cmap = "binary")
plt.show()
x = 0
show_single_image(x_train[x])
x_train = x_train/255.
x_test = x_test/255.
model = keras.models.Sequential() #先生成一个模型框架
model.add(keras.layers.Conv2D(filters = 128,
kernel_size = 3,
padding = 'same',
activation = 'selu',
input_shape = (28,28,1)
))
model.add(keras.layers.SeparableConv2D(filters = 128,
kernel_size = 3,
padding = 'same',
activation = 'selu',
))
model.add(keras.layers.MaxPool2D(pool_size = 2))
model.add(keras.layers.SeparableConv2D(filters = 256,
kernel_size = 3,
padding = 'same',
activation = 'selu',
))
model.add(keras.layers.SeparableConv2D(filters = 256,
kernel_size = 3,
padding = 'same',
activation = 'selu',
))
model.add(keras.layers.MaxPool2D(pool_size = 2))
model.add(keras.layers.SeparableConv2D(filters = 512,
kernel_size = 3,
padding = 'same',
activation = 'selu',
))
model.add(keras.layers.SeparableConv2D(filters = 512,
kernel_size = 3,
padding = 'same',
activation = 'selu',
))
model.add(keras.layers.MaxPool2D(pool_size = 2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128,activation = 'selu'))
model.add(keras.layers.Dense(10,activation = 'softmax'))
model.compile(optimizer='adam',#求解模型的方法
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
history = model.fit(x_train, y_train,epochs = 5, #history用来接收训练过程中的一些参数数值 #训练的参数#训练5遍
validation_data = (x_test,y_test) )#实时展示模型训练情况
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1.5)
plt.show()
plot_learning_curves(history)#(输入训练时的返回值)
def predict_data(test_data):
pred = model.predict(test_data.reshape(-1,28,28,1))
return np.argmax(pred)
show_single_image(x_test[0])
print("模型的预测结果是:",predict_data(x_test[0]))
model.save('my_model.h5')
视觉部分代码
import tensorflow as tf
from tensorflow import keras
import cv2
import numpy as np
import matplotlib.pyplot as plt
font = cv2.FONT_HERSHEY_SIMPLEX
model =keras.models.load_model('my_model.h5') #读取网络
kernel = cv2.getStructuringElement(cv2.MORPH_RECT,(3,3))
image_path = "z.png"#在这里写入图片路径
def look_image(data):
plt.figure()
data = cv2.cvtColor(data, cv2.COLOR_BGR2RGB)
plt.imshow(data)
image = cv2.imread(image_path)#读取图片
image_ = cv2.resize(image, (250,250), interpolation = cv2.INTER_AREA)
image = cv2.cvtColor(image_, cv2.COLOR_BGR2GRAY)#灰度化处理
img_w = cv2.Sobel(image,cv2.CV_16S,0,1)#Sobel滤波,边缘检测
img_h = cv2.Sobel(image,cv2.CV_16S,1,0)#Sobel滤波,边缘检测
img_w = cv2.convertScaleAbs(img_w)
_, img_w = cv2.threshold(img_w,0,255,cv2.THRESH_OTSU|cv2.THRESH_BINARY)
img_h = cv2.convertScaleAbs(img_h)
_, img_h = cv2.threshold(img_h,0,255,cv2.THRESH_OTSU|cv2.THRESH_BINARY)
image = img_w + img_h
image = cv2.morphologyEx(image,cv2.MORPH_CLOSE,kernel)
temp_data = np.zeros((250,10))
image = np.concatenate((temp_data,image,temp_data),axis = 1)
temp_data = np.zeros((10,270))
image = np.concatenate((temp_data,image,temp_data),axis = 0)
image = cv2.convertScaleAbs(image)
contours, hierarchy = cv2.findContours(image, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
for _ in contours:
x,y,w,h = cv2.boundingRect(_)
if w*h < 100:
continue
img_model = image[y-10:y+h+10,x-10:x+w+10]
img_model = cv2.resize(img_model, (28,28), interpolation = cv2.INTER_AREA)
img_model = img_model/255
predict = model.predict(img_model.reshape(-1,28,28,1))
if np.max(predict) > 0.5:
data_predict = str(np.argmax(predict))
image_z = cv2.rectangle(image_,(x-10,y-10),(x + w-10,y + h-10),(255,0,0),1)
image_z = cv2.putText(image_z,data_predict , (x+10, y+10), font, 0.7, (0, 0, 255), 1)
look_image(image_z)
save = cv2.imwrite( "image_predict2.png",image_z)