机器学习实战-聚类分析KMEANS算法-25
KMEANS算法-NBA球队实力聚类分析
from sklearn.cluster import KMeans
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
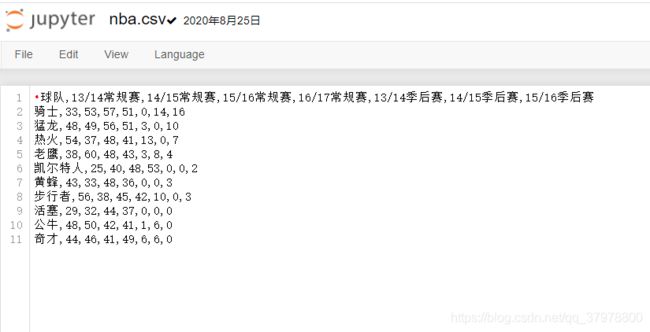
data = pd.read_csv('nba.csv')
data.head()
minmax_scaler = MinMaxScaler()
# 标准化数据
X = minmax_scaler.fit_transform(data.iloc[:,1:])
X[:5]

# 肘部法则
loss = []
for i in range(2,10):
model = KMeans(n_clusters=i).fit(X)
loss.append(model.inertia_)
plt.plot(range(2,10),loss)
plt.xlabel('k')
plt.ylabel('loss')
plt.show()
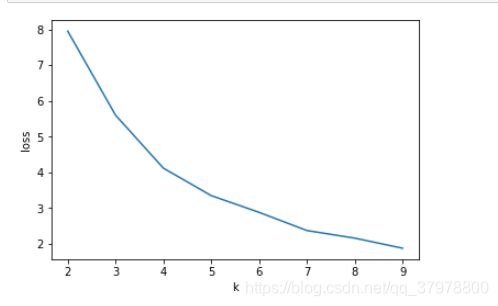
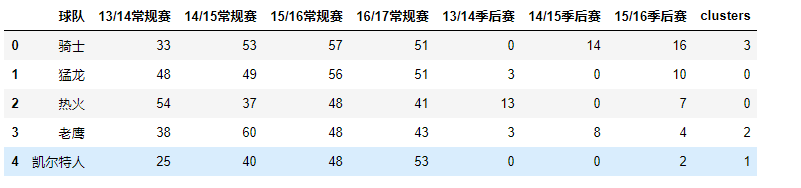
k = 4
model = KMeans(n_clusters=k).fit(X)
# 将标签整合到原始数据上
data['clusters'] = model.labels_
data.head()
for i in range(k):
print('clusters:',i)
label_data = data[data['clusters'] == i].iloc[:,0]
print(label_data.values)

KMEANS算法-广告效果聚类分析
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# 显示中文
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 载入数据,空格为间隔
df = pd.read_csv('ad_performance.txt', delimiter='\t')
# 数据概观
df.tail(5)

df.isnull().sum()

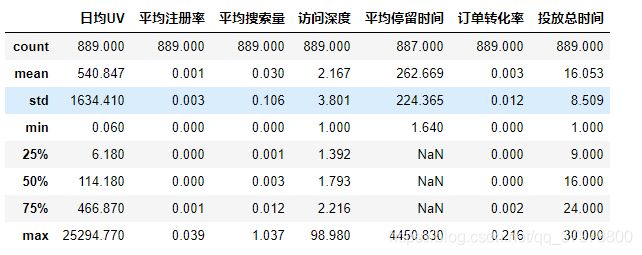
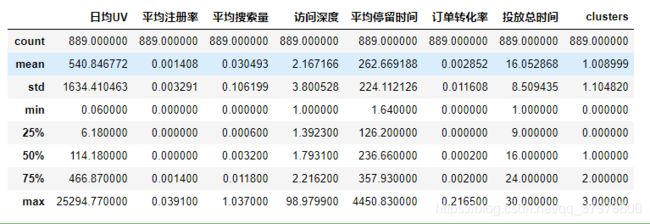
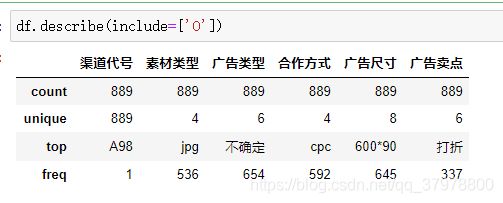
df.describe().round(3)
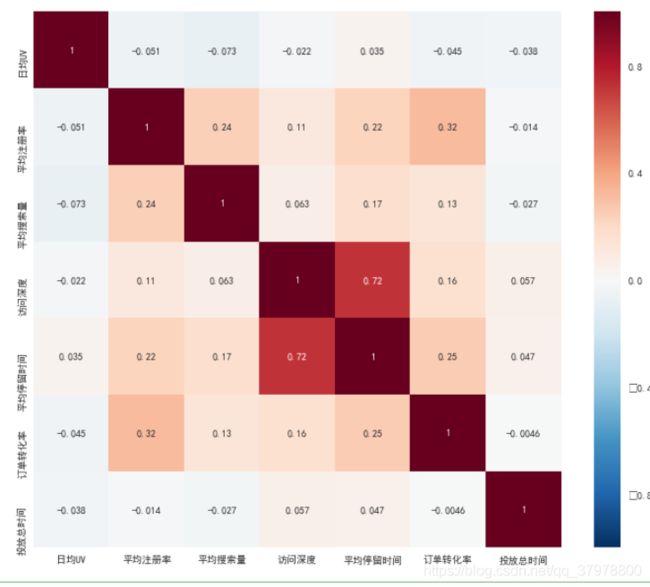
plt.figure(figsize=(12,10))
# 画热力图,数值为两个变量之间的相关系数
p=sns.heatmap(df.corr(), annot=True)
plt.show()
# 使用平均值替换缺失值
df['平均停留时间'] = df['平均停留时间'].fillna(df['平均停留时间'].mean())
# 字符串分类转整数分类
conver_cols = ['素材类型', '广告类型', '合作方式', '广告尺寸', '广告卖点']
# 用get_dummies进行one hot编码
dummy_df = pd.get_dummies(df[conver_cols])
# 清除原来的特征
df2 = df.drop(conver_cols, axis=1)
# 当axis = 1的时候,concat就是行对齐,然后将不同列名称的两张表合并
df2 = pd.concat([df2, dummy_df], axis=1)
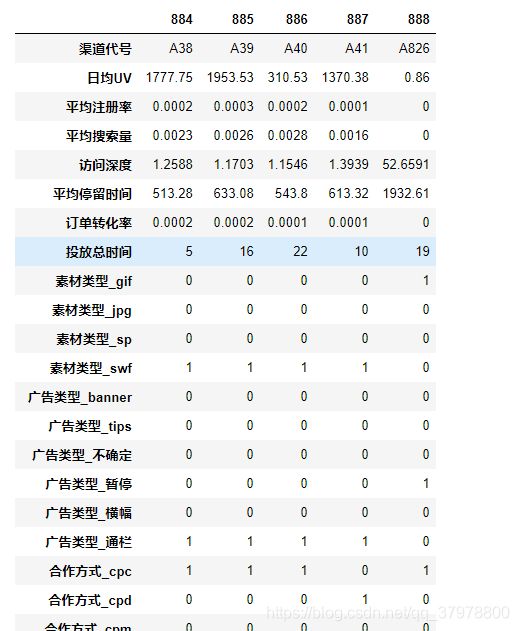
df2.tail().T
# 获取数值特征转换成矩阵
scale_matrix = df2.iloc[:, 1:8]
# 建立MinMaxScaler模型对象
minmax_scaler = MinMaxScaler()
# 标准化数据
df2.iloc[:, 1:8] = minmax_scaler.fit_transform(scale_matrix)
X = np.array(df2.iloc[:,1:])
# 肘部法则
loss = []
for i in range(2,10):
model = KMeans(n_clusters=i).fit(X)
loss.append(model.inertia_)
plt.plot(range(2,10),loss)
plt.xlabel('k')
plt.ylabel('loss')
plt.show()
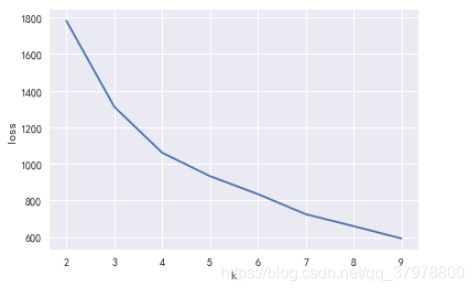
k = 4
model = KMeans(n_clusters=k).fit(X)
# 将最优情况的标签整合到原始数据上
df['clusters'] = model.labels_
# 每个聚类的样本量
cluster_count = pd.DataFrame(df.clusters.value_counts()).rename(columns={
'clusters': 'counts'})
# 获取样本占比
cluster_count['percentage'] = (cluster_count['counts']/cluster_count['counts'].sum()).round(2)
cluster_count.head()

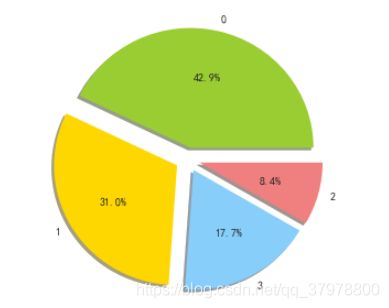
# 设置颜色
colors='yellowgreen','gold','lightskyblue','lightcoral'
# 设置分离
explode=0.1,0.1,0.1,0.1
# 设置画幅
plt.figure(figsize=(5, 5))
# 作图
plt.pie(cluster_count.counts,explode=explode,labels=cluster_count.index,colors=colors,autopct='%1.1f%%',shadow=True)
plt.show()
df.describe()
# 空列表,用于存储最终合并后的所有特征信息
cluster_features = []
# 读取每个类索引
for line in range(k):
# 获得特定类的数据
label_data = df[df['clusters'] == line]
# 获得数值型数据特征
part1_data = label_data.iloc[:, 1:8]
# 得到数值型特征的描述性统计信息
part1_desc = part1_data.describe().round(3)
# 得到数值型特征的均值
merge_data1 = part1_desc.iloc[1, :]
# 获得字符串型数据特征
part2_data = label_data.iloc[:, 8:-1]
# 获得字符串型数据特征的描述性统计信息
part2_desc = part2_data.describe(include='all')
# 获得字符串型数据特征的最频繁值
merge_data2 = part2_desc.iloc[2, :]
# 将数值型和字符串型典型特征沿行合并
merge_line = pd.concat((merge_data1, merge_data2), axis=0)
# 将每个类别下的数据特征追加到列表
cluster_features.append(merge_line)
# 将列表转化为矩阵
cluster_pd = pd.DataFrame(cluster_features)
# 将信息合并
all_cluster_set = cluster_count.join(cluster_pd).sort_index().T
all_cluster_set
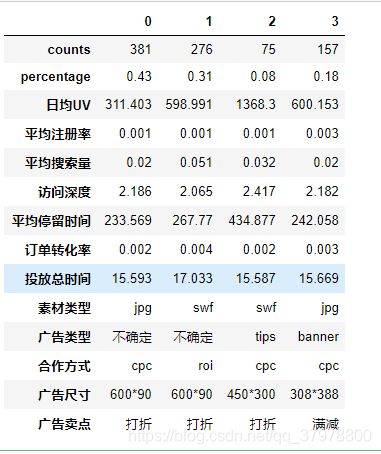
聚类0:各方面的特征都不明显,换句话说就是效果比较平庸,没有明显的优势或短板。但这些“中庸”的广告媒体却构成了整个广告的主体。因此需要业务部门重点考虑其投放的实际价值。
聚类1:这类广告媒体在访问深度、平均停留时间、订单转化率以及平均搜索量等流量质量的特征上的表现较好,除了注册转化率较低外,该类渠道各方面比较均衡。更重要的是该类媒体的数量占据了31%的数量,因此是一类规模较大且综合效果较好的媒体。聚类1的广告渠道的短板是日均UV和平均注册率,因此该类媒体无法为企业带来大量的流量以及新用户。不过这类广告订单转化率高适合有关订单转化的提升。
聚类2:这类广告媒体渠道效果很好,特别是日均UV和用户停留时间表现很好,但综合其只占8%的媒体数量,由于实例比较少,不排除是因为个例导致效果扩大,可以合理增加此类渠道投放,继续深入测试其真实效果。
聚类3:这类渠道其日均UV还不错,平均注册率非常突出,证明这是一类“引流”+“拉新”的渠道,适合在大规模的广告宣传和引流时使用。