python 大作业_Python 程序设计结业考核大作业
《Python 程序设计》结业考核大作业
2020 年春季学期 大数据 2018 级
分类和预测要求如下:
- 利用算法实现人脸识别的功能,最后显示某人的预测名字与真实名字
- 数据集按照比例切分为训练集和测试集,报告中给出你的划分比例
- 评估预测模型的优劣:显示主要分类(必有) 指标 precision\recall\f1-score\support (其他指标可自行添加)
- 用可视化包或库(如, matplotlib )显示预测实验的结果,如图所示:
 UTOOLS1590802589092.png
UTOOLS1590802589092.png
- 撰写总结报告, 包含代码基本注释、实验流程,简短总结。
代码注释
下载数据(如果尚未存储在磁盘上)并将其作为numpy数组加载
lfw_people = fetch_lfw_people(min_faces_per_person=70, resize=0.4)
获取图像数组形状属性(用于绘制)
n_samples, h, w = lfw_people.images.shape
对于机器学习,我们直接使用这2个数据(因为相对像素位置信息被该模型忽略 )
X = lfw_people.data
n_features = X.shape[1]
要预测的标签是该人对应的id
y = lfw_people.target
target_names = lfw_people.target_names
总共需要预测的人数(类别数)
n_classes = target_names.shape[0]
划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=32)
计算人脸数据集(作为未标记数据集)上的PCA(特征脸):主成分分析PCA降维 保留150个成分
n_components = 150
pca = PCA(n_components=n_components, svd_solver='randomized',
whiten=True).fit(X_train)
降维后的特征脸
eigenfaces = pca.components_.reshape((n_components, h, w))
对划分后的训练集测试集进行相同处理
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
训练SVM分类模型、超参设定、定义调参器,并设置5折交叉验证 传入SVC
param_grid = {
'C': [1e3, 5e3, 1e4, 5e4, 1e5],
'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }
clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'),
param_grid, cv=5)
clf = clf.fit(X_train_pca, y_train)
使用测试集对模型的质量进行定量评估
y_pred = clf.predict(X_test_pca)
print(classification_report(y_test, y_pred, target_names=target_names))
print(confusion_matrix(y_test, y_pred, labels=range(n_classes)))
使用matplotlib对预测进行定性(可视化)评估
def plot_gallery(images, titles, h, w, n_row=3, n_col=4):
"""辅助功能以绘制肖像画廊"""
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(n_row * n_col):
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=12)
plt.xticks(())
plt.yticks(())
def title(y_pred, y_test, target_names, i):
"""绘制人名标签 """
pred_name = target_names[y_pred[i]].rsplit(' ', 1)[-1]
true_name = target_names[y_test[i]].rsplit(' ', 1)[-1]
return 'predicted: %s\ntrue: %s' % (pred_name, true_name)
在一部分测试集上绘制预测结果
prediction_titles = [title(y_pred, y_test, target_names, i)
for i in range(y_pred.shape[0])]
plot_gallery(X_test, prediction_titles, h, w)
绘制降维后得到特征脸图像
eigenface_titles = ["eigenface %d" % i for i in range(eigenfaces.shape[0])]
plot_gallery(eigenfaces, eigenface_titles, h, w)
plt.show()
实验流程
数据降维
PCA 的核心步骤(假如原始数据集为矩阵 M, M 中每一行代表一个样本,每一列代表一个特征)
- (零均值化):求每一列的平均值,然后该列上的所有数都减去这个均值
- 求该矩阵的协方差矩阵
- 求特征值、特征矩阵
- 保留主要成分(即比较大的前 n 个特征)
本次实验中,使用 PCA 将特征值降为 150 个。即设置 PCA 最关键的参数 n_components=150
分类算法
支持向量机(Support Vector Machines, 简称SVM)是一种二类分类模型.
划分超平面为:
其优化目标函数为: ($ 为拉格朗日乘子)
其中 为将 映射到高维度的特征向量, 为核函数(Kernel Function), 用于线性不可分的情况, 常见核函数有:
| Name | Expression |
|---|---|
| 线性核函数 | |
| 高斯(RBF)核函数 | $K(x_i, x_j) = exp(-\frac{ |
| ... | ... |
本实验中利用SVM训练 One-VS-One Multiclass SVM 模型, 对前面PCA降维得到的数据进行分类.
总体思路
获取图像得height和width方便后续plot输出。然后对数据特征进行提取,本次实验只用到图像像素信息。通过target属性得到人名信息,并提取对应类别n_classes。
使用train_test_split方法对数据集进行划分。划分完成后使用sklearn.decomposition进行主要成分分析,这里选用得是PCA降维方法。保留150个特征用于绘制特征脸。测试集与训练集相同处理。通过sklearn.svm中得SVC分类器作为识别模型,设定超差'C': [1e3, 5e3, 1e4, 5e4, 1e5],'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }。使用GridSearchCV进行调参,并同时进行5折交叉验证。
使用classification_report评估器对模型进行评估包括precision、recall、f1-score等评估指标。之后使用matplotlib对结果进行可视化展示
 大作业2.png
大作业2.png
通过sklearn.datasets导入数据集。lfw数据集其结果如图:
简短总结
按要求绘制得图像:
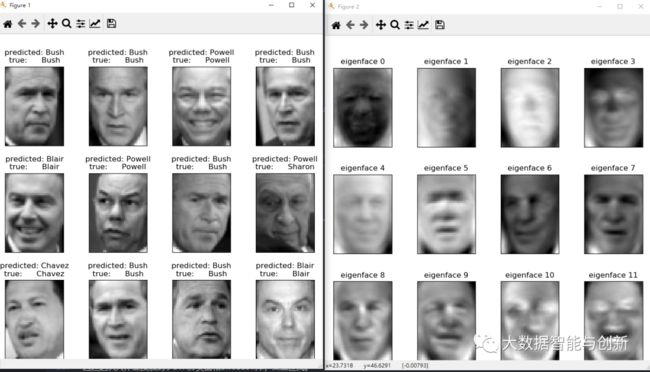 UTOOLS1590808565420.png
UTOOLS1590808565420.png
评估指标输出:
| person | precision | recall | f1-score | support |
|---|---|---|---|---|
| Ariel Sharon | 0.67 | 0.92 | 0.77 | 13 |
| Colin Powell | 0.75 | 0.78 | 0.76 | 60 |
| Donald Rumsfeld | 0.78 | 0.67 | 0.72 | 27 |
| George W Bush | 0.86 | 0.86 | 0.86 | 146 |
| Gerhard Schroeder | 0.76 | 0.76 | 0.76 | 25 |
| Hugo Chavez | 0.67 | 0.67 | 0.67 | 15 |
| Tony Blair | 0.81 | 0.69 | 0.75 | 36 |
| avg / total | 0.80 | 0.80 | 0.80 | 322 |
总结:
通过这次大作业接触到了SVM分类器和sklearn库,受益匪浅,让作为掉包崽的我又学到了。
sklearn.model_selection.train_test_split(*arrays, options)
*arrays: 可以是lists, np.array,scipy-sparse matrices 或者pd.dataframe(很全有没有) 下面就是option里的内容
test_size: float 代表比例必须是[0,1]之间,代表测试集占总数据集的比例。也可以是int 代表测试集的实际数量。如果给的是None, 所有的集合都是训练集。默认为0.25。但是朋友们注意了在版本0.21之后,只有在train_size(下面会说明这个参数) 不确定的情况下是0.25,不然的话会用全部的集合当成训练集。
train_size:和上面的参数一样,只是这里设置的是训练集的比例或者数量
random_state: 个人理解是随机数种子,必须是int或则None, 指定相同的随机数种子可以确保每次划分的口径一致
shuffle:是否重新洗牌,这个参数很有意思,默认为True,在这个情况下,你上面定义的随机数种子才会有用。随机的打乱数据排列, 然后选择。当用False的时候,就是按照数据输入的顺序划分。开头是训练集,末尾是测试集。如果shuffle=False,参数stratify必须是None
stratify: 时候按照一定的比例抽取样本,这个参数很神奇。默认的情况是None, 给值得时候是也很神奇,给的是一个标签序列。比如说,你将原数据集的y标签给入超参。那么随机抽取的样本是按照y标签内样本分布抽取的
classsklearn.model_selection.GridSearchCV(estimator,param_grid, scoring=None, fit_params=None, n_jobs=1, iid=True, refit=True,cv=None, verbose=0, pre_dispatch='2*n_jobs', error_score='raise',return_train_score=True) 常用参数解读
estimator:所使用的分类器,如estimator=RandomForestClassifier(min_samples_split=100,min_samples_leaf=20,max_depth=8,max_features='sqrt',random_state=10), 并且传入除需要确定最佳的参数之外的其他参数。每一个分类器都需要一个scoring参数,或者score方法。
param_grid:值为字典或者列表,即需要最优化的参数的取值,param_grid =param_test1,param_test1 = {'n_estimators':range(10,71,10)}。
scoring :准确度评价标准,默认None,这时需要使用score函数;或者如scoring='roc_auc',根据所选模型不同,评价准则不同。字符串(函数名),或是可调用对象,需要其函数签名形如:scorer(estimator, X, y);如果是None,则使用estimator的误差估计函数。
cv :交叉验证参数,默认None,使用三折交叉验证。指定fold数量,默认为3,也可以是yield训练/测试数据的生成器。
refit :默认为True,程序将会以交叉验证训练集得到的最佳参数,重新对所有可用的训练集与开发集进行,作为最终用于性能评估的最佳模型参数。即在搜索参数结束后,用最佳参数结果再次fit一遍全部数据集。
iid:默认True,为True时,默认为各个样本fold概率分布一致,误差估计为所有样本之和,而非各个fold的平均。
verbose:日志冗长度,int:冗长度,0:不输出训练过程,1:偶尔输出,1:对每个子模型都输出。
n_jobs: 并行数,int:个数,-1:跟CPU核数一致, 1:默认值。
pre_dispatch:指定总共分发的并行任务数。当n_jobs大于1时,数据将在每个运行点进行复制,这可能导致OOM,而设置pre_dispatch参数,则可以预先划分总共的job数量,使数据最多被复制pre_dispatch次
sklearn.decomposition.PCA的主要参数
n_components:这个参数可以帮我们指定希望PCA降维后的特征维度数目。最常用的做法是直接指定降维到的维度数目,此时n_components是一个大于等于1的整数。当然,也可以指定主成分的方差和所占的最小比例阈值,让PCA类自己去根据样本特征方差来决定降维到的维度数,此时n_components是一个(0,1]之间的数。当然,还可以将参数设置为"mle", 此时PCA类会用MLE算法根据特征的方差分布情况自己去选择一定数量的主成分特征来降维。我们也可以用默认值,即不输入n_components,此时n_components=min(样本数,特征数)。
whiten :判断是否进行白化。所谓白化,就是对降维后的数据的每个特征进行归一化,让方差都为1.对于PCA降维本身来说,一般不需要白化。如果你PCA降维后有后续的数据处理动作,可以考虑白化。默认值是False,即不进行白化。
svd_solver:即指定奇异值分解SVD的方法,由于特征分解是奇异值分解SVD的一个特例,一般的PCA库都是基于SVD实现的。有4个可以选择的值:{‘auto’, ‘full’, ‘arpack’, ‘randomized’}。randomized一般适用于数据量大,数据维度多同时主成分数目比例又较低的PCA降维,它使用了一些加快SVD的随机算法。full则是传统意义上的SVD,使用了scipy库对应的实现。arpack和randomized的适用场景类似,区别是randomized使用的是scikit-learn自己的SVD实现,而arpack直接使用了scipy库的sparse SVD实现。默认是auto,即PCA类会自己去在前面讲到的三种算法里面去权衡,选择一个合适的SVD算法来降维。一般来说,使用默认值就够了。
sklearn.svm.SVC(C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, shrinking=True, probability=False,tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=None,random_state=None)
C:C-SVC的惩罚参数C?默认值是1.0C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强。
kernel :核函数,默认是rbf,可以是‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’
0 – 线性:u'v 1 – 多项式:(gamma*u'v + coef0)^degree 2 – RBF函数:exp(-gamma|u-v|^2) 3 –sigmoid:tanh(gammau'*v + coef0)
degree :多项式poly函数的维度,默认是3,选择其他核函数时会被忽略。
gamma : ‘rbf’,‘poly’ 和‘sigmoid’的核函数参数。默认是’auto’,则会选择1/n_features
coef0 :核函数的常数项。对于‘poly’和 ‘sigmoid’有用。
probability :是否采用概率估计?.默认为False
shrinking :是否采用shrinking heuristic方法,默认为true
tol :停止训练的误差值大小,默认为1e-3
cache_size :核函数cache缓存大小,默认为200
class_weight :类别的权重,字典形式传递。设置第几类的参数C为weight*C(C-SVC中的C)
verbose :允许冗余输出?
max_iter :最大迭代次数。-1为无限制。
decision_function_shape :‘ovo’, ‘ovr’ or None, default=None3
random_state :数据洗牌时的种子值,int值
参考
- https://www.jianshu.com/p/c86f167c019d
- http://scikit-learn.org/stable/modules/generated/sklearn.datasets.fetch_lfw_people.html