Redis面试题集
Redis 面试题集
- Redis 面试题集
-
- 1. Redis为什么是单线程的?
- 2. Redis 支持的数据类型有哪些?
- 3. Redis的缓存穿透、缓存崩溃、缓存击穿的理解?
- 4. Redis 持久化的几种方式?
- 5. Redis中如何保证缓存数据和数据库数据的一致性?
- 6.Redis的分布式锁如何实现,有什么优缺点?
- 7. Jedis和Redisson 的优缺点?
- 8.Redis的数据淘汰策略
- 9.Redis 和 Memecache 有什么区别?
- 10. Redis的内存优化
- 11. Redis如何进行大数据量更新缓存?
Redis 面试题集
1. Redis为什么是单线程的?
1、完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1);
2、数据结构简单,对数据操作也简单,Redis中的数据结构是专门进行设计的;
3、采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
4、使用多路I/O复用模型,非阻塞IO;
多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈,主要由以上几点造就了 Redis 具有很高的吞吐量。
5、使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,Redis直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
Redis为什么这么快:因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。
2. Redis 支持的数据类型有哪些?
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合)
各个数据类型应用场景:
| 类型 | 简介 | 特性 | 场景 |
|---|---|---|---|
| String(字符串) | 二进制安全 | 可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512M | — |
| Hash(字典) | 键值对集合,即编程语言中的Map类型 | 适合存储对象,并且可以像数据库中update一个属性一样只修改某一项属性值(Memcached中需要取出整个字符串反序列化成对象修改完再序列化存回去) | 存储、读取、修改用户属性 |
| List(列表) | 链表(双向链表) | 增删快,提供了操作某一段元素的API | 1,最新消息排行等功能(比如朋友圈的时间线) 2,消息队列 |
| Set(集合) | 哈希表实现,元素不重复 | 1、添加、删除,查找的复杂度都是O(1) 2、为集合提供了求交集、并集、差集等操作 | 1、共同好友 2、利用唯一性,统计访问网站的所有独立ip 3、好友推荐时,根据tag求交集,大于某个阈值就可以推荐 |
| Sorted Set(有序集合) | 将Set中的元素增加一个权重参数score,元素按score有序排列 | 数据插入集合时,已经进行天然排序 | 1、排行榜 2、带权重的消息队列 |
-
String:
string 是 redis 最基本的类型,你可以理解成与 Memcached 一模一样的类型,一个 key 对应一个 value。
string 类型是二进制安全的。意思是 redis 的 string 可以包含任何数据。比如jpg图片或者序列化的对象。
string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512MB。redis 127.0.0.1:6379> SET runoob "菜鸟教程" OK redis 127.0.0.1:6379> GET runoob "菜鸟教程"在以上实例中我们使用了 Redis 的 SET 和 GET 命令。键为 runoob,对应的值为 菜鸟教程。
-
Hash(哈希):
Redis hash 是一个键值(key=>value)对集合。
Redis hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象。
redis 127.0.0.1:6379> DEL runoob
redis 127.0.0.1:6379> HMSET runoob field1 “Hello” field2 “World”
“OK”
redis 127.0.0.1:6379> HGET runoob field1
“Hello”
redis 127.0.0.1:6379> HGET runoob field2
“World”
实例中我们使用了 Redis HMSET, HGET 命令,HMSET 设置了两个 field=>value 对, HGET 获取对应 field 对应的 value。每个 hash 可以存储 232 -1 键值对(40多亿)。
redis 127.0.0.1:6379> DEL runoob
redis 127.0.0.1:6379> HMSET runoob field1 "Hello" field2 "World"
"OK"
redis 127.0.0.1:6379> HGET runoob field1
"Hello"
redis 127.0.0.1:6379> HGET runoob field2
"World"
-
List(列表)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。redis 127.0.0.1:6379> DEL runoob redis 127.0.0.1:6379> lpush runoob redis (integer) 1 redis 127.0.0.1:6379> lpush runoob mongodb (integer) 2 redis 127.0.0.1:6379> lpush runoob rabitmq (integer) 3 redis 127.0.0.1:6379> lrange runoob 0 10 1) "rabitmq" 2) "mongodb" 3) "redis" redis 127.0.0.1:6379>
列表最多可存储 232 - 1 元素 (4294967295, 每个列表可存储40多亿)。
-
Set(集合)
Redis 的 Set 是 string 类型的无序集合。
集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
sadd 命令
添加一个 string 元素到 key 对应的 set 集合中,成功返回 1,如果元素已经在集合中返回 0。sadd key member
实例:
redis 127.0.0.1:6379> DEL runoob redis 127.0.0.1:6379> sadd runoob redis (integer) 1 redis 127.0.0.1:6379> sadd runoob mongodb (integer) 1 redis 127.0.0.1:6379> sadd runoob rabitmq (integer) 1 redis 127.0.0.1:6379> sadd runoob rabitmq (integer) 0 redis 127.0.0.1:6379> smembers runoob 1) "redis" 2) "rabitmq" 3) "mongodb"以上实例中 rabitmq 添加了两次,但根据集合内元素的唯一性,第二次插入的元素将被忽略。
集合中最大的成员数为 232 - 1(4294967295, 每个集合可存储40多亿个成员)。 -
zset(sorted set:有序集合)
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
不同的是每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
zadd 命令
添加元素到集合,元素在集合中存在则更新对应scorezadd key score member
实例:
redis 127.0.0.1:6379> DEL runoob redis 127.0.0.1:6379> zadd runoob 0 redis (integer) 1 redis 127.0.0.1:6379> zadd runoob 0 mongodb (integer) 1 redis 127.0.0.1:6379> zadd runoob 0 rabitmq (integer) 1 redis 127.0.0.1:6379> zadd runoob 0 rabitmq (integer) 0 redis 127.0.0.1:6379> > ZRANGEBYSCORE runoob 0 1000 1) "mongodb" 2) "rabitmq" 3) "redis"
3. Redis的缓存穿透、缓存崩溃、缓存击穿的理解?
-
缓存穿透:是指查询一个数据库一定不存在的数据。
正常的使用缓存流程大致是,数据查询先进行缓存查询,如果key不存在或 者key已经过期,再对数据库进行查询,并把查询到的对象,放进缓存。如果数据库查询对象为空,则不放进缓存。
发生场景:
如果传入的参数为-1,会是怎么样?这个-1,就是一定不存在的对象。就会每次都去查询数据库,而每次查询都是空,每次又都不会进行缓存。假如有恶意攻击,就可以利用这个漏洞,对数据库造成压力,甚至压垮数据库。即便是采用UUID,也是很容易找到一个不存在的KEY,进行攻击。 -
缓存击穿: 是指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
发生场景:某一个商品爆款的时候会导致这种情况的产生。
解决方案:- 设置缓存永不过期(或者过期时间比较大)。
- 设置双重缓存备份A和B,当A缓存失效时,使用B缓存。
-
缓存雪崩:缓存在同一时间内大量键过期(失效),接着来的一大波请求瞬间都落在了数据库中导致连接异常。
解决方案:
- 也是像解决缓存穿透一样加锁排队;
- 建立备份缓存,缓存A和缓存B,A设置超时时间,B不设值超时时间,先从A读缓存,A没有读B,并且更新A缓存和B缓存;
- 设置缓存超时时间的时候加上一个随机的时间长度,比如这个缓存key的超时时间是固定的5分钟加上随机的2分钟,酱紫可从一定程度上避免雪崩问题;
参考链接:
- https://blog.csdn.net/fanrenxiang/article/details/80542580
- https://baijiahao.baidu.com/s?id=1619572269435584821&wfr=spider&for=pc
4. Redis 持久化的几种方式?
持久化方式主要分为RDB和AOF两种方式。
- RDB:RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储。
- AOF: AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到详细的操作记录。
参考资料: Redis持久化方式详解
5. Redis中如何保证缓存数据和数据库数据的一致性?
缓存应用和数据库在更新时经常会出现不一致的问题,采用哪种策略,值得去思考。
从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存
目前最优的解决方案:使用延时双删策略
策略流程如下图所示:
(1)更新数据库数据
(2)数据库会将操作信息写入binlog日志当中
(3)订阅程序提取出所需要的数据以及key
(4)另起一段非业务代码,获得该信息
(5)尝试删除缓存操作,发现删除失败
(6)将这些信息发送至消息队列
(7)重新从消息队列中获得该数据,重试操作。
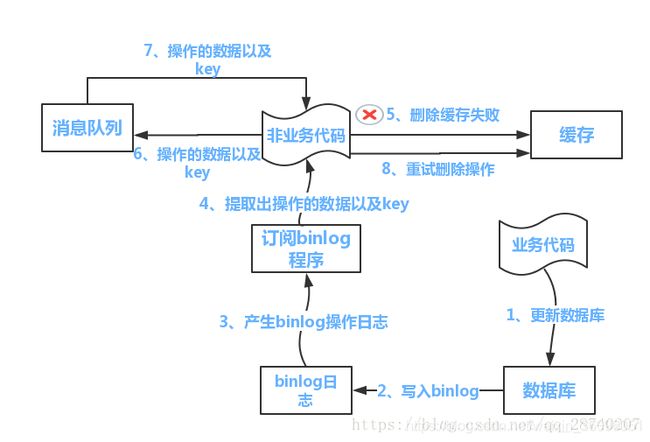
参考资料:Redis缓存和数据库一致性问题
6.Redis的分布式锁如何实现,有什么优缺点?
-
分布式锁需要解决的问题
互斥性:任意时刻只能有一个客户端拥有锁,不能同时多个客户端获取
安全性:锁只能被持有该锁的用户删除,而不能被其他用户删除
死锁:获取锁的客户端因为某些原因而宕机,而未能释放锁,其他客户端无法获取此锁,需要有机制来避免该类问题的发生
容错:当部分节点宕机,客户端仍能获取锁或者释放锁。 -
如何通过Redis实现分布式锁:(非完善方法)
SETNX key value :如果key不存在,则创建并赋值
时间复杂度: 0(1)
返回值:设置成功,返回1;设置失败,返回0。
但是此时我们获取的key是长期有效的,所以我们应该如何解决长期有效的问题呢?如何解决SETNX长期有效的问题?
EXPIRE key seconds
设置key的生存时间,当key过期时(生存时间为0) ,会被自动删除
缺点:原子性得不到满足//该程序存在危险,如果执行到第二行就崩溃了,则此时key会被一直占用而无法被释放 RedisService redisService = SpringUtils.getBean(Redi sService.class); long status = redisService.setnx(key, "1"); if(status == 1) { redisService.expire(key, expire); //执行独占资源逻辑 doOcuppiedWork(); } -
如何通过Redis实现分布式锁:(正确方式)
SET key value [EX seconds] [PX milliseconds] [NX|XX]EX second :设置键的过期时间为second秒
PX millisecond :设置键的过期时间为millisecond毫秒
NX :只在键不存在时,才对键进行设置操作
XX:只在键已经存在时,才对键进行设置操作
SET操作成功完成时,返回OK ,否则返回nilRedisService redisService = SpringUtils.getBean(RedisService.class); . String result = redisService.set(lockKey, requestId, SET_IF_NOT_EXIST, SET_WITH_EXPIRE_TIME, expireTime); if ("OK".equals(result)) { //执行独占资源逻辑 doOcuppiedWork(); } -
大量的key同时过期的注意事项
集中过期,由于清除大量的key很耗时,会出现短暂的卡顿现象
解放方案:在设置key的过期时间的时候,给每个key加上随机值
特殊场景1:超时后使用del 导致误删其他线程的锁
又是一个极端场景,假如某线程成功得到了锁,并且设置的超时时间是30秒。
如果某些原因导致线程B执行的很慢很慢,过了30秒都没执行完,这时候锁过期自动释放,线程B得到了锁。
随后,线程A执行完了任务,线程A接着执行del指令来释放锁。但这时候线程B还没执行完,线程A实际上删除的是线程B加的锁。
怎么避免这种情况呢?可以在del释放锁之前做一个判断,验证当前的锁是不是自己加的锁。
至于具体的实现,可以在加锁的时候把当前的线程ID当做value,并在删除之前验证key对应的value是不是自己线程的ID。
,if判断和释放锁是两个独立操作,不是原子性。
我们都是追求极致的程序员,所以这一块要用Lua脚本来实现:
String luaScript = 'if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end';
redisClient.eval(luaScript , Collections.singletonList(key), Collections.singletonList(threadId));
这样一来,验证和删除过程就是原子操作了。
特殊场景2: 出现并发的可能性
还是刚才的场景1,虽然我们避免了线程A误删掉key的情况,但是同一时间有A,B两个线程在访问代码块,仍然是不完美的。
怎么办呢?我们可以让获得锁的线程开启一个守护线程,用来给快要过期的锁“续航”。
当过去了29秒,线程A还没执行完,这时候守护线程会执行expire指令,为这把锁“续命”20秒。守护线程从第29秒开始执行,每20秒执行一次。
当线程A执行完任务,会显式关掉守护线程。
另一种情况,如果节点1 忽然断电,由于线程A和守护线程在同一个进程,守护线程也会停下。这把锁到了超时的时候,没人给它续命,也就自动释放了。
Redisson 实现分布式锁(建议使用):
redisson所有指令都通过lua脚本执行,redis支持lua脚本原子性执行
redisson设置一个key的默认过期时间为30s,如果某个客户端持有一个锁超过了30s怎么办?
redisson中有一个watchdog的概念,翻译过来就是看门狗,它会在你获取锁之后,每隔10秒帮你把key的超时时间设为30s
这样的话,就算一直持有锁也不会出现key过期了,其他线程获取到锁的问题了。
redisson的“看门狗”逻辑保证了没有死锁发生。
(如果机器宕机了,看门狗也就没了。此时就不会延长key的过期时间,到了30s之后就会自动过期了,其他线程可以获取到锁)
看门狗的作用类似上述场景2中的守护线程
7. Jedis和Redisson 的优缺点?
Redisson:
优点:
- Redisson实现了分布式和可扩展的Java数据结构。支持的数据结构有:List, Set, Map, Queue, SortedSet, ConcureentMap, Lock, AtomicLong, CountDownLatch。并且是线程安全的,底层使用Netty 4实现网络通信。
- 封装了redis的分布式锁的实现,使用者只需要调用即可。
缺点:功能较为简单,不支持字符串操作,不支持排序、事务‘管道、分区等Redis特性。
Jedis: 与上述相反。
8.Redis的数据淘汰策略
如果对淘汰策略不熟悉,可参考: Redis淘汰策略
当前版本,Redis 3.0 支持的策略包括:
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用 的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数 据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据 淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据
如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
您需要根据系统的特征, 来选择合适的驱逐策略。 当然, 在运行过程中也可以通过命令动态设置驱逐策略, 并通过 INFO 命令监控缓存的 miss 和 hit, 来进行调优。
一般来说:
如果分为热数据与冷数据, 推荐使用 allkeys-lru 策略。 也就是, 其中一部分key经常被读写. 如果不确定具体的业务特征, 那么 allkeys-lru 是一个很好的选择。
如果需要循环读写所有的key, 或者各个key的访问频率差不多, 可以使用 allkeys-random 策略, 即读写所有元素的概率差不多。
假如要让 Redis 根据 TTL 来筛选需要删除的key, 请使用 volatile-ttl 策略。
volatile-lru 和 volatile-random 策略主要应用场景是: 既有缓存,又有持久key的实例中。 一般来说, 像这类场景, 应该使用两个单独的 Redis 实例。
值得一提的是, 设置 expire 会消耗额外的内存, 所以使用 allkeys-lru 策略, 可以更高效地利用内存, 因为这样就可以不再设置过期时间了。
9.Redis 和 Memecache 有什么区别?
- Redis和Memcache都是将数据存放在内存中,都是内存数据库。不过memcache还可用于缓存其他东西,例如图片、视频等等。
- Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,hash等数据结构的存储。
- 虚拟内存–Redis当物理内存用完时,可以将一些很久没用到的value 交换到磁盘
- 过期策略–memcache在set时就指定,例如set key1 0 0 8,即永不过期。Redis可以通过例如expire 设定,例如expire name 10
- 分布式–设定memcache集群,利用magent做一主多从;redis可以做一主多从。都可以一主一从
- 存储数据安全–memcache挂掉后,数据没了;redis可以定期保存到磁盘(持久化)
- 灾难恢复–memcache挂掉后,数据不可恢复; redis数据丢失后可以通过aof恢复
- Redis支持数据的备份,即master-slave模式的数据备份。
10. Redis的内存优化
- 关闭 Redis 的虚拟内存[VM]功能,即 redis.conf 中 vm-enabled = no
- 设置 redis.conf 中 maxmemory ,用于告知 Redis 当使用了多少物理内存后拒绝继续写入的请求,可防止 Redis 性能降低甚至崩溃
- 可为指定的数据类型设置内存使用规则,从而提高对应数据类型的内存使用效率
- Hash 在 redis.conf 中有以下两个属性,任意一个超出设定值,则会使用 HashMap 存值
- hash-max-zipmap-entires 64 表示当 value 中的 map 数量在 64 个以下时,实际使用 zipmap 存储值
- hash-max-zipmap-value 512 表示当 value 中的 map 每个成员值长度小于 512 字节时,实际使用 zipmap 存储值
- List 在 redis.conf 中也有以下两个属性
- list-max-ziplist-entires 64
- list-max-ziplist-value 512
- Hash 在 redis.conf 中有以下两个属性,任意一个超出设定值,则会使用 HashMap 存值
- 在 Redis 的源代码中有一行宏定义 REDIS-SHARED-INTEGERS = 10000 ,修改该值可以改变 Redis 存储数值类型的内存开销
更多方案,参考资料:Redis内存进阶优化
11. Redis如何进行大数据量更新缓存?
Reids是一个cs模式的Tcp服务,类似于http的请求。 当客户端发送一个请求时,服务器处理之后会将结果通过响应报文返回给客户端 。
那么当需要发送多个请求时,难道每次都要等待请求响应,再发送下一个请求吗?
当然不是,这里就可以采用Redis的管道技术(pipeline)。
举个例子,如果说jedis是:request response,request response,…;
那么pipeline则是:request request… response response的方式。
参考资料:使用Redis的管道(Pipeline)进行批量操作