【Grasshopper基础8】电池的序列化与反序列化 Serilization of Grasshopper Component
这篇文章的内容是介绍GH_Component中另外一对可以被 override 的函数:
- Read
- Write
当我们在自己的电池中直接 override 时,Visual Studio会帮我们添加基类实现:
public override bool Read(GH_IReader reader)
{
return base.Read(reader);
}
public override bool Write(GH_IWriter writer)
{
return base.Write(writer);
}
这一对函数是用来进行序列化电池数据的。它们的最主要的应用场景是将某些属于电池的状态数据 存储 在电池所在的 .gh 文件中。
举个例子:Grasshopper中有许多电池是具备多个形态的,比如 Cross Reference 电池,它的不同工作模式可以使得两个列表对象以不同的方式匹配到一起:
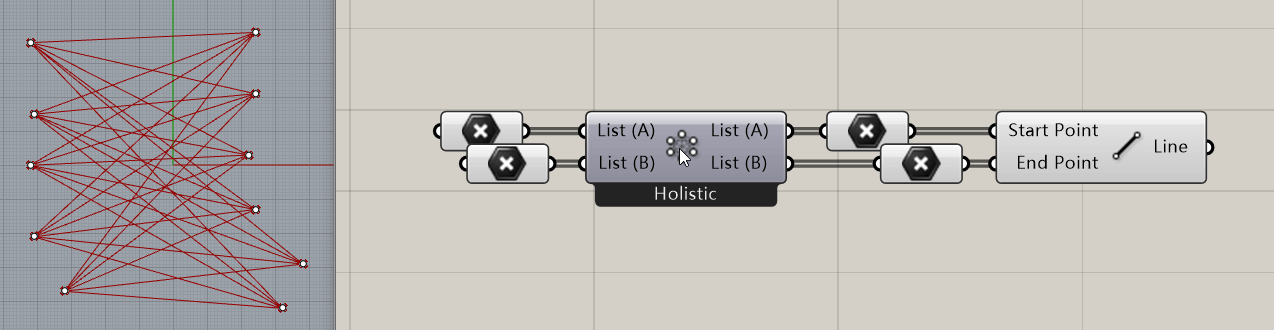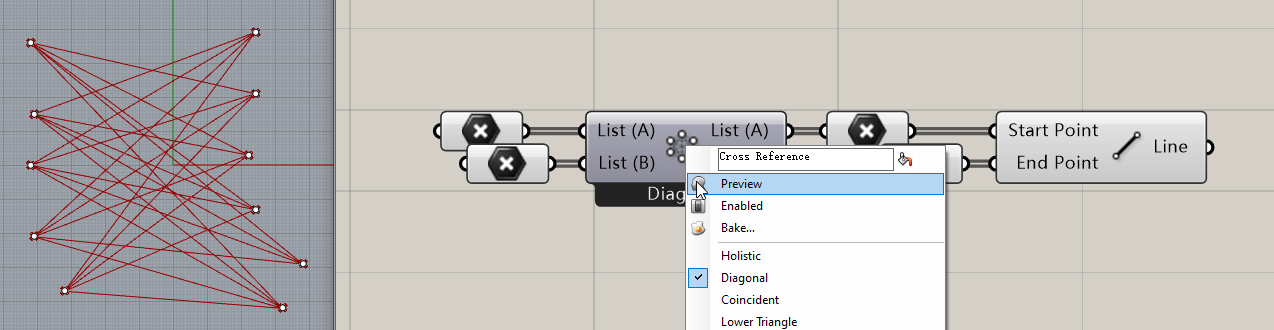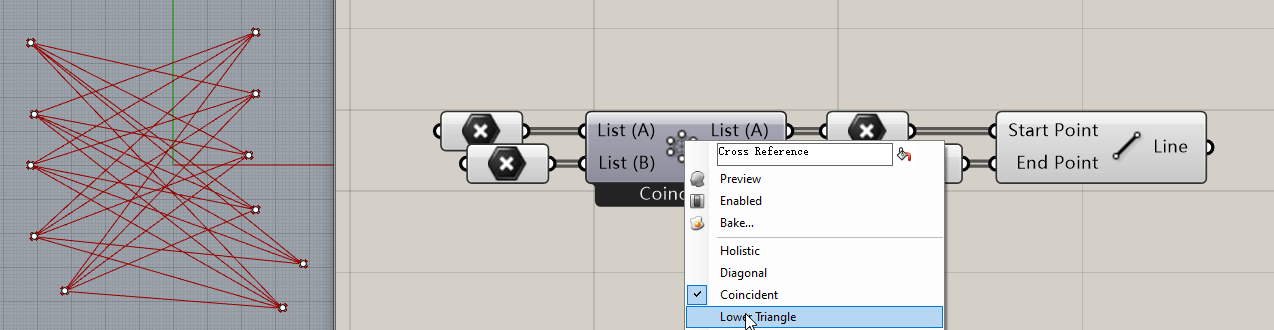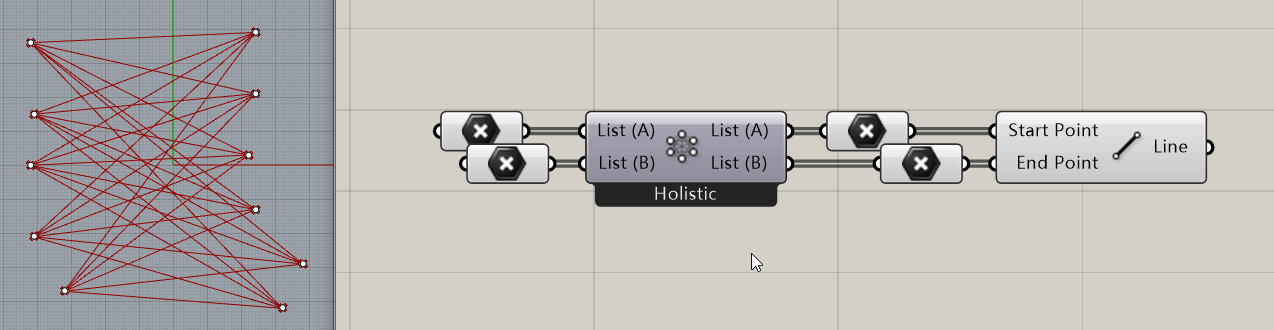
那么问题就来了,Grasshopper是如何实现打开一个 .gh 文件时让这个电池还保持它上次在文件关闭时的电池形态呢?进一步的,GH在文件保存时是怎么知道这个电池处于什么状态下呢?
这里就需要使用到这一对函数了。在Grasshopper打开文件时,会调用电池的Read函数,读取 .gh 文件中属于该电池的数据内容;Write函数正好相反,是在每次 .gh 文件保存时,将属于电池的数据写入到 .gh 文件的数据内容存储区。
电池的序列化
所有的电池其本质上都是一个自定义类,其继承自GH_Component。但所有程序都是在内存中运行的,因此,我们在GH画布上创作的电池其本质都是 在内存中 创造/销毁数据。当我们的自定义电池被拖入GH画布上时,一个自定义电池类的实例就会在内存中被创建;我们在GH画布上删除一个电池时,一个自定义电池类的实例就会在内存中被销毁。
当 .gh 文件被保存时,这些内存中的电池实例就会被“序列化”至硬盘上。 .gh 文件被打开的时候,Grasshopper就会“反序列化”将硬盘上的内容读取到内存中。

但是,我们都知道,硬盘上只能存储0和1。那一堆0和1是怎么变成我们的自定义类的,我们自定义类又是如何变成0和1?这就需要我们定义“序列化规则”。
自定义电池类的基类GH_Component已经由GH的开发者实现了一套默认的序列化规则,放在这一对函数Read和Write中来帮助我们实现电池的序列化和反序列化,因此电池中的基础数据就可以被正确地存盘和读取,包括并不限于:
- 电池的名字(Name)
- 电池的描述(Description)
- 电池是否打开预览(Preview)
- 电池是否处于激活状态(Active)
- ……
因此,即便自定义电池中不重写Read和Write,也能对自定义电池的基本状态实现序列化和反序列化。但是如果自定义电池里出现了一个GH_Component中不包含的属性,那么其默认的序列化规则就无法将它写入 .gh 文件中了,自然也没办法从 .gh 读取该属性了。
让我们来看下面的例子:
这是一个可以把每次输入的文字不断拼接的电池,还附带了一个重置按钮。
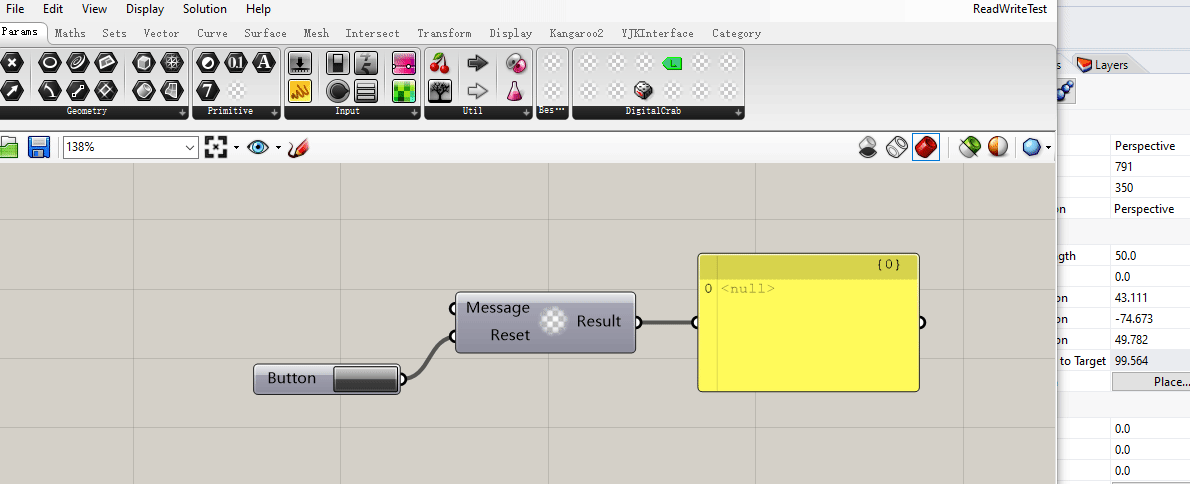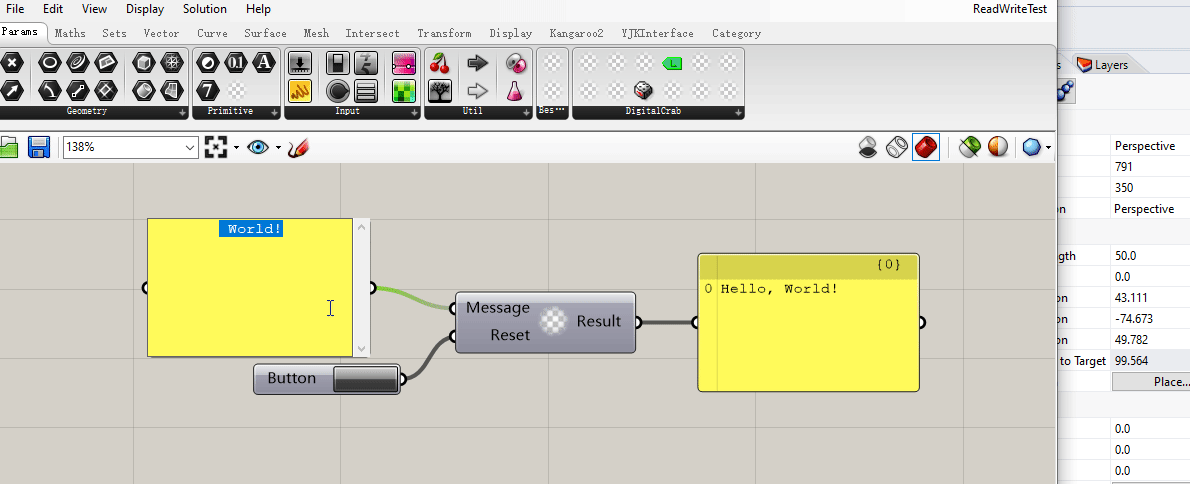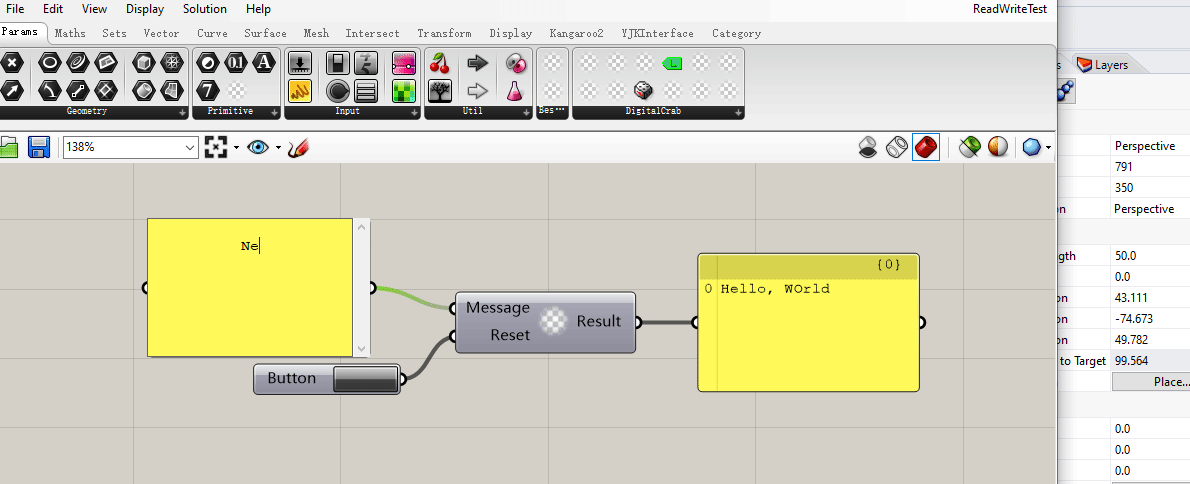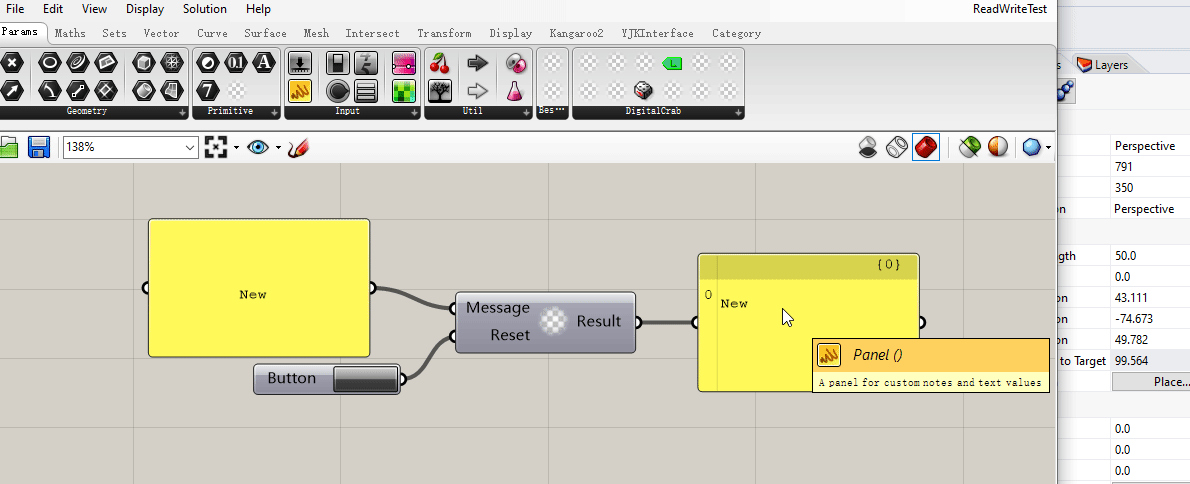
可以看到这个电池在这个 gh 文件保存关闭再打开之后,原来存储在 myMessage 属性中的字符串值没能够成功存储。(电池输出端的 “Hello, World” 在关闭文件再次打开时消失了。)
这种情况下,在与其它人分享交流 .gh 文件的时候会变得十分不方便,因为别人再打开 .gh 文件时,电池的“状态”与它在被保存的时候的状态是不一致的。
gif中电池关键代码如下
public class ReadAndWrite : GH_Component
{
// 其他电池的函数省略,比如Guid, 构造函数等
string myMessage = ""; // 自定义电池的额外属性,用于存储字符串。
protected override void RegisterInputParams(GH_Component.GH_InputParamManager pManager)
{
pManager.AddTextParameter("Message", "M", "", GH_ParamAccess.item);
Params.Input[0].Optional = true;
pManager.AddBooleanParameter("Reset", "R", "", GH_ParamAccess.item, false);
}
protected override void RegisterOutputParams(GH_Component.GH_OutputParamManager pManager)
{
pManager.AddTextParameter("Result", "S", "", GH_ParamAccess.item);
}
protected override void SolveInstance(IGH_DataAccess DA)
{
bool resetBtn = false;
if (!DA.GetData(1, ref resetBtn)) return;
if (resetBtn)
{
myMessage = string.Empty;
return;
}
string msg = string.Empty;
if (!DA.GetData(0, ref msg)) return;
if (!string.IsNullOrWhiteSpace(msg)) myMessage += msg;
DA.SetData(0, myMessage);
}
}
重写Read()和Write()
要把自定义电池的属性(状态)存储在 .gh 文件中,就需要重写其默认的 Read 和 Write 方法 —— Write用来实现序列化,Read用来实现反序列化。
在重写的函数体内,使用传入的参数 writer 和 reader 分别来进行数据的存储和读取。这里可以存储常用的简单数据类型,包括 Boolean、Byte、Int、Double、String 等,也可以储存一些特定的Grasshopper特有的数据类型,比如Interval、Plane等。对应的序列化和反序列化操作需要调用的函数分别是以Set开头的和Get开头的函数。比如对于整形数据,对应的序列化和反序列化操作函数分别是 writer.SetInt32 和 reader.GetInt32。
要实现对于上一节介绍的 myMessage 属性的序列化/反序列化操作,就需要使用到字符串的序列化。下面是其代码的例子。
public override bool Write(GH_IWriter writer)
{
// 将变量myMessage的内容存入至gh文件的数据表中,并且给这个内容起名叫 "MyMessage"
// 名字会在反序列化时用到,从数据表中取出时需要通过名字来获取
writer.SetString("MyMessage", myMessage);
return base.Write(writer);
}
public override bool Read(GH_IReader reader)
{
// 一定要先确定数据表中有没有存在这个名字的项,否则会报I/O错误
if (reader.ItemExists("MyMessage"))
// 从gh文件数据表中获取名为MyMessage的数据,并转为string,存入变量中
myMessage = reader.GetString("MyMessage");
return base.Read(reader);
}

可以看到,在重写了这两个函数后,自定义电池已经可以“记住”自己在 .gh 文件被保存时的状态,并且在其被打开时再次恢复上次被保存的状态了。
Read()和Write()在什么时候被GH调用
Read仅仅会在 .gh 文件被打开时调用。当一个 .gh 文件被打开时,Grasshopper会使用反序列化规则在内存中挨个创建电池:先会按照 默认构造函数 创建电池的实例,然后调用 Read 函数,其内部需要包含给其他并不存在于默认构造函数中的属性 赋值。上例中的
myMessage = reader.GetString("MyMessage");
就是给 myMessage 这个不存在于默认构造函数中的属性进行赋值。这样以来,当序列化完成之后,电池的各个自定义属性的值就会回到 .gh 文件被保存时的状态。Read函数是自定义电池类实例创建完成之后调用的。
对应的,Write函数会在每次 .gh 文件保存时被调用,用于存储自定义电池的各个属性(状态)。一个属性只有在被保存了之后,才能被成功读取,否则就会在Grasshopper打开文件时报I/O错误。大家可以尝试将上例中的 if (reader.ItemExists(...)) 判断语句拿掉,并且试图读取一个压根不存在的名字对应的值,看看在文件打开时会出现什么样的错误吧。(没错就是下面这个框)

总之,.gh 文件就好似一个数据库,而 Read 和 Write 这两个函数就是电池与这个数据库之间沟通的桥梁。通过它们俩,内存中的电池实例中的数据才能被永久化地存储于 .gh 文件中。
本次关于电池的序列化与反序列化内容就介绍到这里,其中有未详尽之处,欢迎大家留言交流。