简介: 随着大数据的爆发,图数据的应用规模不断增长,现有的图计算系统仍然存在一定的局限。阿里巴巴拥有全球最大的商品知识图谱,在丰富的图场景和真实应用的驱动下,阿里巴巴达摩院智能计算实验室研发并开源了全球首个一站式超大规模分布式图计算平台GraphScope,并入选中国科学技术协会“科创中国”平台。本文详解图计算的原理和应用及GraphScope的架构设计。

一、 什么是图计算
图数据对一组对象(顶点)及其关系(边)进行建模,可以直观、自然地表示现实世界中各种实体对象以及它们之间的关系。在大数据场景下,社交网络、交易数据、知识图谱、交通和通信网络、供应链和物流规划等都是典型的以图建模的例子。图 1 显示了阿里巴巴在电商场景下的图数据,其中有各种类型的顶点(消费者、卖家、物品和设备)和边(表示了购买、查看、评论等关系)。此外,每个顶点还有丰富的属性信息相关联。
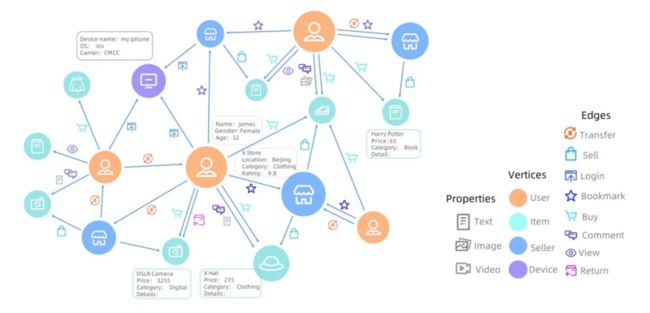 图 1:阿里巴巴电商场景图数据示例
图 1:阿里巴巴电商场景图数据示例
实际场景中的这种图数据通常包含数十亿个顶点和数万亿条边。除了规模大之外,这个图的持续更新速度也非常快,每秒可能有近百万的更新。随着近年来图数据应用规模的不断增长,探索图数据内部关系以及在图数据上的计算受到了越来越多的关注。根据图计算的不同目标,大致可以分为交互查询、图分析和基于图的机器学习三类任务。
1、 图的交互查询
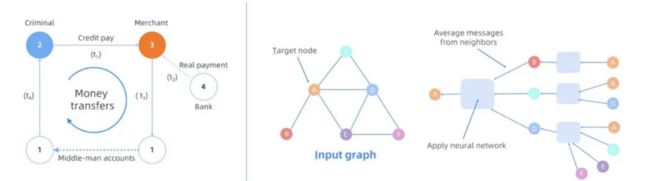 图 2:左,金融反欺诈示例;右,图学习示例。
图 2:左,金融反欺诈示例;右,图学习示例。
在图计算的应用中,业务通常需要以探索的方式来查看图数据,以进行一些问题的及时定位和分析某个深入的信息,如图 2 (左)中的(简化)图模型可被用于金融反欺诈(信用卡非法套现)检测。通过使用伪造的标识符,“犯罪分子”可以从银行获得短期信用(顶点 4)。他尝试通过商家(顶点3)的帮助,以虚假购买( 边 2->3)来兑现货币。一旦从银行(顶点4)收到付款(边 4->3),商家再通过其名下的多个帐户将钱(通过边 3->1 和 1->2)退还给“犯罪分子”。这种模式最终形成一个图上的闭环(2->3->1...->2)。真实场景中,图数据在线上的规模可能包含数十亿个顶点(例如,用户)和数千亿至万亿条边(例如,支付交易),并且整个欺诈过程可能涉及到许多实体之间包含各种约束的动态交易链,因此需要复杂的实时交互分析才能很好的识别。
2、 图分析
关于图分析计算的研究已经持续了数十年,产生了很多图分析的算法。典型的图分析算法包括经典图算法(例如,PageRank、最短路径和最大流),社区检测算法(例如,最大团/clique、联通量计算、Louvain 和标签传播),图挖掘算法(例如,频繁集挖掘和图的模式匹配)。由于图分析算法的多样性和分布式计算的复杂性,分布式图分析算法往往需要遵循一定的编程模型。当前的编程模型有点中心模型“Think-like-vertex”,基于矩阵的模型和基于子图的模型等。在这些模型下,涌现出各种图分析系统,如 Apache Giraph、Pregel、PowerGraph、Spark GraphX、GRAPE 等。
3、 基于图的机器学习
经典的 Graph Embedding 技术,例如 Node2Vec 和 LINE,已在各种机器学习场景中广泛使用。近年来提出的图神经网络(GNN),更是将图中的结构和属性信息与深度学习中的特征相结合。GNN 可以为图中的任何图结构(例如,顶点,边或整个图)学习低维表征,并且生成的表征可以被许多下游图相关的机器学习任务进行分类、链路预测、聚类等。图学习技术已被证明在许多与图相关的任务上具有令人信服的性能。与传统的机器学习任务不同,图学习任务涉及图和神经网络的相关操作(见图 2 右),图中的每个顶点都使用与图相关的操作来选择其邻居,并将其邻居的特征与神经网络操作进行聚合。
二 、图计算:下一代人工智能的基石
不仅仅是阿里巴巴,近年来图数据和计算技术一直是学术界和工业界的热点。特别是,在过去的十年中,图计算系统的性能已提高了 10~100 倍,并且系统仍在变得越来越高效,这使得通过图计算来加速AI和大数据任务成为了可能。实际上,由于图能十分自然地表达各种复杂类型的数据,并且可以为常见的机器学习模型提供抽象。与密集张量相比,图能提供更丰富的语义和更全面的优化功能。此外,图是稀疏高维数据的自然表达,并且图卷积网络(GCN)和图神经网络(GNN)中越来越多的研究证明,图计算是对机器学习的有效补充,在结果的可解释性、深层次推理因果等方面将扮演越来越重要的作用。
 图 3:图计算在AI各个领域具有广阔的应用前景
图 3:图计算在AI各个领域具有广阔的应用前景
可以预见,图计算将在下一代人工智能的各种应用中发挥重要作用,包括反欺诈,智能物流,城市大脑,生物信息学,公共安全,公共卫生,城市规划,反洗钱,基础设施,推荐系统,金融技术和供应链等领域。
三 、图计算现状
经过这些年的发展,已有针对各种图计算需求的多种系统和工具。例如在交互查询方面,有图数据库Neo4j、ArangoDB和OrientDB等、也有分布式系统和服务JanusGraph、Amazon Neptune和Azure Cosmos DB等;在图分析方面,有 Pregel、Apache Giraph、Spark GraphX、PowerGraph 等系统;在图学习上有 DGL、pytorch geometric 等。尽管如此,面对丰富的图数据和多样化的图场景,有效利用图计算增强业务效果依然面临着巨大的挑战:
- 现实生活中的图计算场景多样,且通常非常复杂,涉及到多种类型的图计算。现有的系统主要是为特定类型的图计算任务设计的。因此,用户必须将复杂的任务分解为涉及许多系统的多个作业。在系统之间可能会产生大量例如集成、IO、格式转换、网络和存储方面的额外开销。
- 难以开发大型图计算的应用。为了开发图计算的应用,用户通常使用简单易用的工具(例如 Python 中的 NetworkX 和 TinkerPop)在一台机器上从小规模图数据开始。但是,对于普通用户而言,扩展其单机解决方案到并行环境处理大规模图是极其困难的。现有的用于大规模图的分布式系统通常遵循不同的编程模型,并且缺乏单机库(例如 NetworkX)中丰富的即用算法/插件库。这使得分布式图计算的门槛过高。
- 处理大图的规模和效率仍然有限。例如,由于游历模式的高度复杂性,现有的交互式图查询系统无法并行执行 Gremlin 查询。对于图分析系统,传统的点中心编程模型使图级别的现有优化技术不再可用。此外,许多现有系统也基本未在编译器级别上做过优化。
下面我们通过一个具体的示例看看现有系统的局限性。
1 示例:论文分类预测
数据集 ogbn-mag 是一个来自于微软学术的数据集。数据中包含四种类型的点,分别表示论文、作者、机构、研究领域;在这些点之间有表示关系的四种边:分别是作者“撰写”了论文,论文“引用”了另一篇论文,作者“隶属于”某个机构,和论文“属于”某个研究领域。这个数据很自然的可以用图来建模。
一个用户期望在这个图上对 2014-2020 年间发表的“论文”做一个分类任务,期望能根据论文在数据图中的结构属性、自身的主题特征、以及 kcore、三角计数 triangle-counting 等团聚度的衡量参数,将其归类并预测文章的主题类别。实际上,这是一个十分常见和有意义的任务,这个预测由于考虑了论文的引用关系和论文的主题,可以帮助研究人员更好的发现领域内的潜在合作和研究热点。
让我们分解一下这个计算任务:首先我们需要对论文及其相关的点边做一个根据年份的筛选,再需要在这个图上计算 kcore、triangle-counting 等全图计算,最后将这两个参数和图上的原始特征一起,放入一个机器学习框架进行分类训练和预测。我们发现当前已有的系统并不能很好的端到端解决这个问题,我们只能通过将多个系统组织成一个 pipeline 的形式运行:
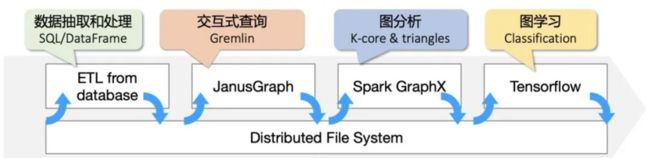 图 4:论文分类预测多系统组成的工作流
图 4:论文分类预测多系统组成的工作流
这个任务看起来是解决了,实际上这样流水线的方案背后隐藏着许多问题。例如多个系统之间互相独立和割裂,中间数据频繁落盘进行系统间的数据传递;图分析的程序不是声明性语言,没有固定范式;图的规模影响机器学习框架的效率等等。这些都是我们在现实图计算场景中常遇到的问题,总结一下可以概括为以下三点:
- 图计算问题十分复杂,计算模式多样,解决方案碎片化。
- 图计算学习难度强,成本大,门槛高。
- 图的规模和数据量大,计算复杂,效率低。
为了解决以上的问题,我们设计并研发了一站式开源图计算系统:GraphScope。
四 、GraphScope 是什么
GraphScope 是阿里巴巴达摩院智能计算实验室研发并开源的一站式图计算平台。依托于阿里海量数据和丰富场景,与达摩院的高水平研究,GraphScope 致力于针对实际生产中图计算的上述挑战,提供一站式高效的解决方案。
GraphScope 提供 Python 客户端,能十分方便的对接上下游工作流,具有一站式、开发便捷、性能极致等特点。它具有高效的跨引擎内存管理,在业界首次支持 Gremlin 分布式编译优化,同时支持算法的自动并行化和支持自动增量化处理动态图更新,提供了企业级场景的极致性能。在阿里巴巴内部和外部的应用中,GraphScope 已经证明在多个关键互联网领域(如风控,电商推荐,广告,网络安全,知识图谱等)实现重要的业务新价值。
GraphScope 集合了达摩院的多项学术研究成果,其中的核心技术曾获得数据库领域顶级学术会议 SIGMOD2017 最佳论文奖、VLDB2017 最佳演示奖、VLDB2020 最佳论文提名奖、世界人工智能创新大赛SAIL奖。GraphScope 的交互查询引擎的论文也已被 NSDI 2021 录用,即将发表。还有其它围绕 GraphScope 的十多项研究成果发表在领域顶级的学术会议或期刊上,如 TODS、SIGMOD、VLDB、KDD 等。
1、 架构介绍
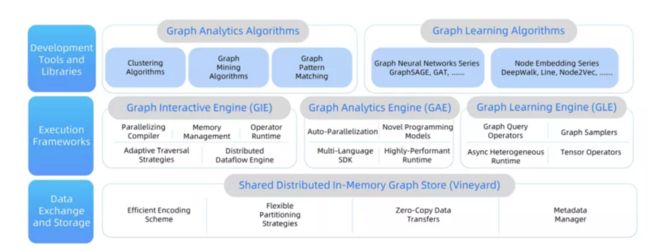 图 5:GraphScope 系统架构图
图 5:GraphScope 系统架构图
GraphScope 的底层是一个分布式内存数据管理系统 vineyard[1]。vineyard 也是我们开源的一个项目,它提供了高效和丰富的 IO 接口负责与更底层的文件系统交互,它提供了高效和高层次的数据抽象(包括但不限于图,tensor,vector 等),支持管理数据的分区、元数据等,可以为上层应用提供本机零拷贝的数据读取。正是这一点支持了 GraphScope 的一站式能力:在跨引擎之间,图数据按分区的形式存在于 vineyard,由 vineyard 统一管理。
中间是引擎层,分别由交互式查询引擎 GIE,图分析引擎 GAE,和图学习引擎 GLE 组成,我们将在后续的章节中详细介绍。
最上层是开发工具和算法库。GraphScope 提供了各类常用的分析算法,包括连通性计算类、社区发现类和 PageRank、中心度等数值计算类的算法,后续会不断扩展算法包,在超大规模图上提供与 NetworkX 算法库兼容的分析能力。此外也提供了丰富的图学习算法包,内置支持 GraphSage、DeepWalk、LINE、Node2Vec 等算法。
2、 重解问题:论文分类预测
有了一站式计算平台 GraphScope,我们可以用一种更简单的方式解决前面示例中的问题。
GraphScope 提供 Python客户端, 让数据科学家可以在自己熟悉的环境中完成所有图计算相关的工作。打开 Python 后,我们首先需要建立一个 GraphScope 会话。
import graphscope
from graphscope.dataset.ogbn_mag import load_ogbn_mag
sess = graphscope.sesson()
g = load_ogbn_mag(sess, "/testingdata/ogbn_mag/")在上面的代码中,我们建立了一个 GraphScope 的 session,并载入了图数据。
GraphScope 面向云原生设计,一个 session 的背后对应了一组 k8s 的资源,该session 负责这个会话中所有资源的申请和管理。具体来说,在用户这行代码的背后,session首先会请求一个后端总入口 Coordinator 的 pod。Coordinator 负责跟 Python 客户端的所有通信,在完成自身的初始化后,它会拉起一组引擎 pod。这组 pod 中每一个 pod 都有一个 vineyard 实例,共同组成一个分布式内存管理层;同时,每一个 pod 中都有 GIE、GAE、GLE 三个引擎,它们的启停状态由 Coordinator 在后续按需管理。当这组 pod 拉起并与 Coordinator 建立稳定连接、完成健康检查后,Coordinator 会返回状态到客户端,告诉用户,session 已拉起成功,资源就绪可以开始载图或计算了。
interactive = sess.gremlin(g)
# count the number of papers two authors (with id 2 and 4307) have co-authored
papers = interactive.execute("g.V().has('author', 'id', 2).out('writes').where(__.in('writes').has('id', 4307)).count()").one()首先我们在图 g 上建立了一个交互式查询对象 interactive。这个对象在引擎 pod 中拉起了一组交互式查询引擎 GIE。接着下面是一个标准的 Gremlin 查询语句,用户想在这个数据中查看两个具体作者的合作论文。这个 Gremlin 语句会发送给 GIE 引擎进行拆解和执行。
GIE 引擎由并行化 Compiler、内存和调度管理、Operator 运行时、自适应的游历策略和分布式 Dataflow 引擎等核心组件组成。在收到交互式查询的语句后,该语句首先会被 Compiler 拆分,编译成多个运行算子。这些算子再以分布式数据流的模型被驱动和执行,在这个过程中,每一个持有分区数据的计算节点都跑一份该数据流的拷贝,并行处理本分区的数据,并在过程中按需进行数据交换,从而并行化的执行 Gremlin 查询。
Gremlin 复杂的语法下,游历策略至关重要并影响着查询的并行度,它的选择直接影响着资源的占用和查询的性能。只靠简单的 BFS 或是 DFS 在现实中并不能满足需求。最优的游历策略往往需要根据具体的数据和查询动态调整和选择。GIE 引擎提供了自适应的游历策略配置,根据查询数据、拆解的 Op 和 Cost 模型选择游历策略,以达到算子执行的高效性。
# extract a subgraph of publication within a time range
sub_graph = interactive.subgraph("g.V().has('year', inside(2014, 2020)).outE('cites')")
# project the projected graph to simple graph.
simple_g = sub_graph.project_to_simple(v_label="paper", e_label="cites")
ret1 = graphscope.k_core(simple_g, k=5)
ret2 = graphscope.triangles(simple_g)
# add the results as new columns to the citation graph
sub_graph = sub_graph.add_column(ret1, {"kcore": "r"})
sub_graph = sub_graph.add_column(ret2, {"tc": "r"})在通过一系列单点查看的交互式查询后,用户通过以上语句开始做图分析任务。
首先它通过一个 subgraph 的操作子从原图中根据筛选条件抽取了一个子图。这个操作子的背后,是交互式引擎 GIE 执行了一个查询,再将结果图写入了 vineyard。
然后用户在这个新图上抽取了 label 为论文的点和他们之间关系为引用(cites)的边,产出了一张同构图,并在上面调用了 GAE 的内置算法 k-core 和三角计数 triangles 在全图做了分析型计算。产出结果后,这两个结果被作为点上的属性加回了原图。这里,借助于 vineyard 元数据管理和高层数据抽象,新的 sub_graph 是通过原图上新增一列的变换来生成的,不需要重建整张图的全部数据。
GAE 引擎核心继承了曾获得 SIGMOD2017 最佳论文奖的 GRAPE 系统[2]。它由高性能运行时、自动并行化组件、多语言支持的 SDK 等组件组成。上面的例子用到了 GAE 自带的算法,此外,GAE 也支持用户十分简单的编写自己的算法并在其上即插即用。用户以基于子图编程的 PIE 模型编写算法,或者重用已有图算法,而不用考虑分布式细节,由 GAE 来做自动并行化,大幅降低了分布式图计算对用户的高门槛。目前,GAE 支持用户通过C++、Python(后续将支持 Java)等多语言编写自己的算法逻辑,即插即用在分布式环境。GAE 的高性能运行时基于 MPI,对通讯、数据排布,硬件特征做了十分细致的优化,以达到极致性能。
# define the features for learning
paper_features = []
for i in range(128):
paper_features.append("feat_" + str(i))
paper_features.append("kcore")
paper_features.append("tc")
# launch a learning engine.
lg = sess.learning(sub_graph, nodes=[("paper", paper_features)],
edges=[("paper", "cites", "paper")],
gen_labels=[
("train", "paper", 100, (1, 75)),
("val", "paper", 100, (75, 85)),
("test", "paper", 100, (85, 100))
]) 接下来我们开始用图学习引擎为论文分类。首先我们配置将数据中论文类节点的 128 维特征以及我们在上一步中计算出的 kcore 和 triangles 两个属性共同作为训练特征。然后我们从 session 中拉起图学习引擎 GIE。在拉起 GIE中 图 lg 时,我们配置了图数据,特征属性,指定了哪一类的边,以及将点集划分为了训练集、验证集和测试集。
from graphscope.learning.examples import GCN
from graphscope.learning.graphlearn.python.model.tf.trainer import LocalTFTrainer
from graphscope.learning.graphlearn.python.model.tf.optimizer import get_tf_optimizer
# supervised GCN.
def train_and_test(config, graph):
def model_fn():
return GCN(graph, config["class_num"], ...)
trainer = LocalTFTrainer(model_fn,
epoch=config["epoch"]...)
trainer.train_and_evaluate()
config = {...}
train_and_test(config, lg)然后我们通过上面的代码选用模型以及做一些训练相关的参数配置就可以十分便捷的用 GLE 开始做图分类任务。
GLE 引擎包含 Graph 与 Tensor 两部分,分别由各种 Operator 构成。Graph 部分涉及图数据与深度学习的对接,如按 Batch 迭代、采样和负采样等,支持同构图和异构图。Tensor 部分则由各类深度学习算子构成。在计算模块中,图学习任务被拆解成一个个算子,算子再被运行时分布式的执行。为了进一步优化采样性能,GLE 将缓存远程邻居、经常访问的点、属性索引等,以加快每个分区中顶点及其属性的查找。GLE 采用支持异构硬件的异步执行引擎,这使 GLE 可以有效地重叠大量并发操作,例如 I/O、采样和张量计算。GLE 将异构计算硬件抽象为资源池(例如 CPU 线程池和 GPU 流池),并协作调度细粒度的并发任务。
五 、性能
GraphScope 不仅在易用性上一站式的解决了图计算问题,在性能上也达到极致,满足了企业级需求。我们使用 LDBC Benchmark 对 GraphScope 的性能进行了评估和对比测试。
如图 6 所示,在交互式查询测试 LDBC SNB Benchmark上,单节点部署的 GraphScope 与开源系统 JanusGraph 相比,多数查询快一个数量级以上;在分布式部署下,GraphScope 的交互式查询基本能达到线性加速的扩展性。
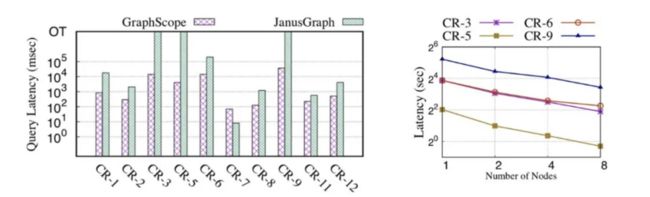 图 6:GraphScope 交互式查询性能
图 6:GraphScope 交互式查询性能
在图分析测试 LDBC GraphAnalytics Benchmark 上,GraphScope 与 PowerGraph 以及其他最新系统比较,几乎在所有算法和数据集的组合中居于领先水平。在某些算法和数据集上,跟其他平台比较最低也有五倍的性能优势。局部数据见下图。
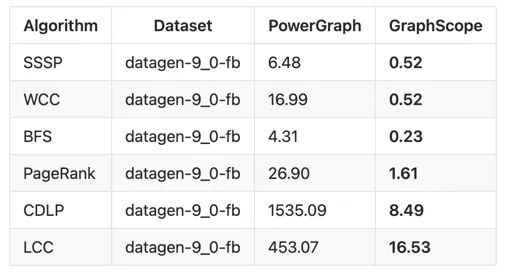 图 7:GraphScope 图分析性能
图 7:GraphScope 图分析性能
关于实验的设定、重现和完整的性能比较可以参见交互式查询性能[3]和图分析性能[4]。
六 、拥抱开源
GraphScope 的白皮书、代码已经在 github.com/alibaba/graphscope 开源[5],项目遵守 Apache License 2.0。欢迎大家 star、试用,参与到图计算中来。也欢迎大家贡献代码,一起打造业界最好的图计算系统。我们的目标是持续更新该项目,不断提升功能的完整性和系统的稳定性。
作者:开发者小助手_LS
原文链接
本文为阿里云原创内容,未经允许不得转载