txt文本读写,以及txt文件批量转换为xlsx文件
在处理数据过程中,发现需要重复处理txt文本数据,并将txt数据转换为xlsx数据进行计算,思考是不是能使用python来让工作量变少,从而节约时间,提高效率。
模块主要用的是os和openpyxl模块。
import os
import openpyxl
一、txt文件的读写
1.载入路径(txtPath),因为是批量处理txt文件,因此使用os模块遍历所有文件(txtLists)。
txtPath = 'C:/Users/飞翔的小猪/Desktop/2_2017_Aerosol_Optical_Depth_550_Land_resample01_ASCII/'
txtPath = txtPath.encode('utf-8')
txtType = 'txt'
txtLists = os.listdir(txtPath) #列出文件夹下所有的目录与文件
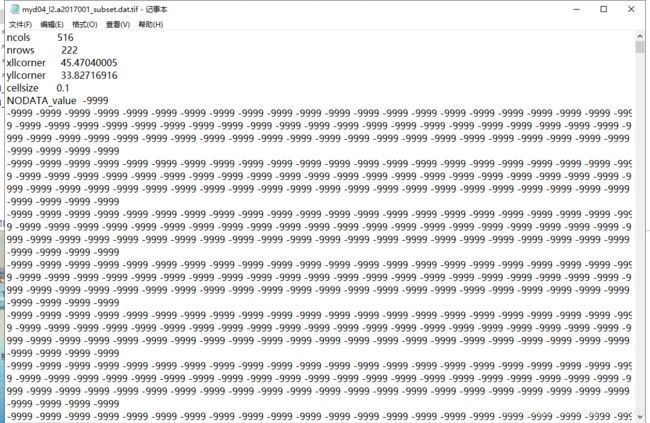
2.因为txt文本中存在大量无用且重复的数据,首先需要做的就是将他们删除。
for txt in txtLists:
f = open(txtPath+txt,encoding='utf-8') # 返回一个文件对象
lines = f.readlines() # 读取全部内容 ,并以列表方式返回
print(txt)
fp = open('C:/Users/飞翔的小猪/Desktop/09/a.txt','w') #打开你要写得文件pp2.txt
for s in lines: #将前六行的数据替换成空值,同时将所有-9999替换成换行
if 'ncols' in s:
fp.write(s.replace('ncols','').replace('515',''))
elif 'nrows' in s:
fp.write(s.replace('nrows','').replace('220',''))
elif 'xllcorner' in s:
fp.write(s.replace('xllcorner','').replace('45.',''))
elif 'yllcorner' in s:
fp.write(s.replace('yllcorner','').replace('33.',''))
elif 'cellsize' in s:
fp.write(s.replace('cellsize','').replace('0.1',''))
elif 'NODATA_value' in s:
fp.write(s.replace('NODATA_value','').replace('-9999',''))
else:
fp.write(s.replace('-9999','\n'))
# replace是替换,write是写入
fp.close() # 关闭文件
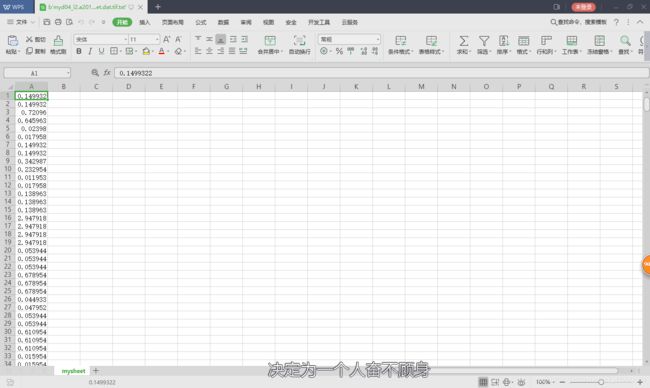
3.因为我们想要把所有的数据存储为xlsx格式,并最终以一列显示,而在将上面多余的数值替换成空值之后,会存在众多的空单元格,我们使用replace()进行替换,所有的数据就变成一列的数据了。
fppp= open('C:/Users/飞翔的小猪/Desktop/09/aa.txt').readlines()
dff=open('C:/Users/飞翔的小猪/Desktop/09/aaa.txt','w')
for sss in fppp: #将数据与数据之间的空行转换成换行符
dff.write(sss.replace(' ','\n'))
dff.close()
二、txt文件转换为xlsx文件
xlrd模块、xlwt模块和openpyxl模块都可以处理excel的读写,不过前两个只能处理excel2003版的,而openpyxl则可以处理excel2007版本以上的。在前期处理过程中使用的xlrd模块和xlwt模块,后面因为数据量太大改为openpyxl模块。
xlrd模块和xlwt模块
pen = open("C:/Users/飞翔的小猪/Desktop/09/aaaa.txt", 'r')
lines = pen.readlines()
# 新建一个excel文件
file = xlwt.Workbook(encoding='utf-8', style_compression=0)
# 新建一个sheet
sheet = file.add_sheet('data')
i = 0
for line in lines:
sheet.write(i, 0, line)
i = i + 1
file.save('C:/Users/飞翔的小猪/Desktop/09/3_5_2009_Aerosol_Optical_Depth_550_Land_openshrubmask01ASCII/'+str(txt)+'.xls')
openpyxl模块
fopen = open("C:/Users/飞翔的小猪/Desktop/09/aaaa.txt", 'r')
lines = fopen.readlines()
# 新建一个excel文件
file=openpyxl.Workbook()
worksheet = file.active
worksheet.title="mysheet"
i = 1
for line in lines:
line = line.strip('\n')#数据会存在多余的空格
#line = line.split(',')
worksheet.cell(i, 1,float(str( line)))
i = i + 1
file.save('C:/Users/飞翔的小猪/Desktop/09/'+str(txt)+'.xlsx')
放张初始图和成果图!!!