数据分析-pandas总结笔记

一、Pandas简介
在Python中,pandas是基于NumPy数组构建的,使数据预处理、清洗、分析工作变得更快更简单。pandas是专门为处理表格和混杂数据设计的,而NumPy更适合处理统一的数值数组数据。
Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
pandas有两个主要数据结构:Series和DataFrame。
二、Series对象
Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成,即index和values两部分,可以通过索引的方式选取Series中的单个或一组值。
import pandas as pd
# 通过传递一个list对象来创建一个Series
sel = pd.Series(data = [1,2,3,4], index = list('abcd'))
print(sel)
# 获取内容
print('获取内容:',sel.values)
# 获取索引
print('获取索引:',sel.index)
# 获取索引和值对
print('获取索引和值对:',list(sel.iteritems()))
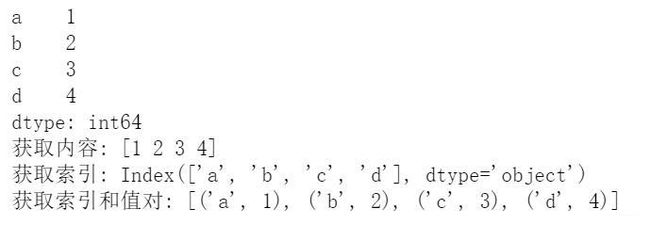
三、DataFrame对象
DataFrame是一种二维的数据结构,非常接近于电子表格或者类似 mysql 数据库的形式。它的竖行称之为 columns,横行跟前面的 Series 一样,称之为 index,也就是说可以通过 columns 和 index 来确定一个主句的位置。
1.创建DataFrame对象
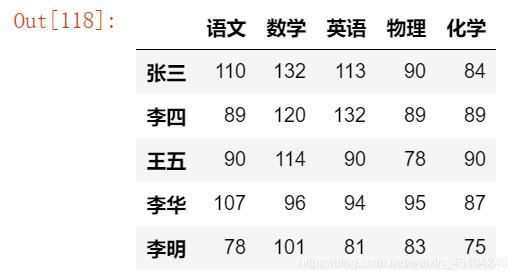
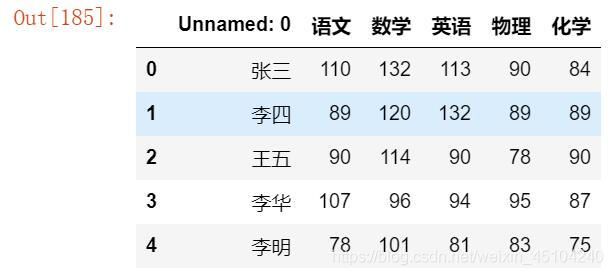
data = {
'语文':[110,89,90,107,78],
'数学': [132,120,114,96,101],
'英语':[113,132,90,94,81],
'物理':[90,89,78,95,83],
'化学':[84,89,90,87,75]}
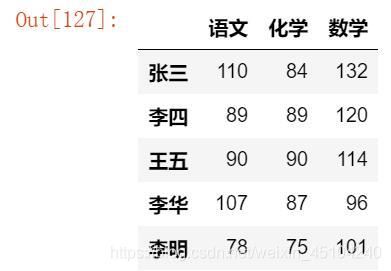
df = pd.DataFrame(data,index=['张三', '李四', '王五', '李华', '李明'])
df
2.查看DataFrame对象
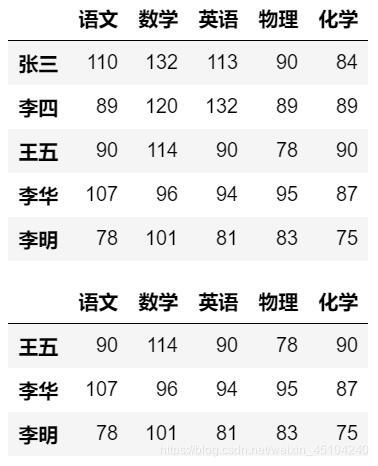
查看DataFrame中头部和尾部:
#1.查看DataFrame中头部行
display(df.head())
#2.查看DataFrame尾部的行
display(df.tail(3))
查看不同列的数据类型:
#查看不同列的数据类型
df.dtypes

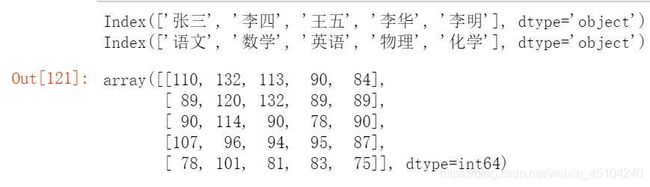
显示索引、列和底层的numpy数据:
print(df.index)
print(df.columns)
df.values
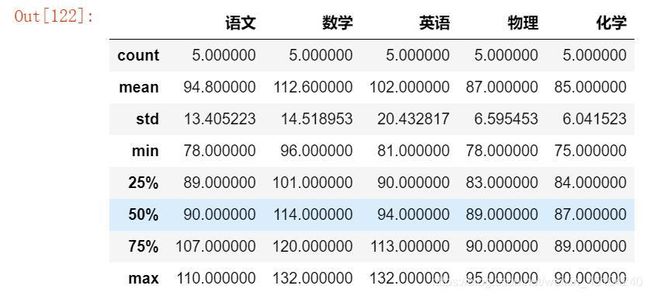
数据的快速统计汇总:
# describe()函数对于数据的快速统计汇总,
# 统计每个索引的数据量、最小值、最大值等
df.describe()
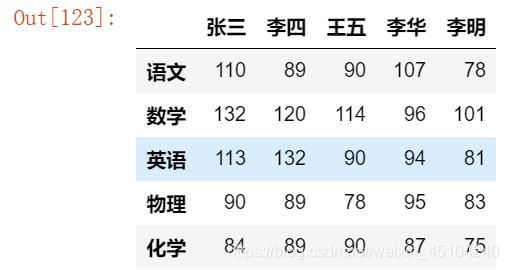
对数据的转置:
df.T
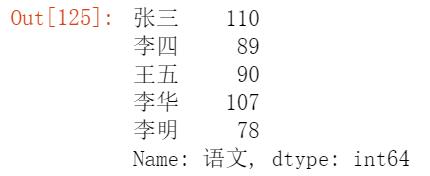
3.选择数据
选择一个单独的列,将会返回一个Series:
df['语文']
通过[]进行选择,将会对行进行切片:
df[2:4]
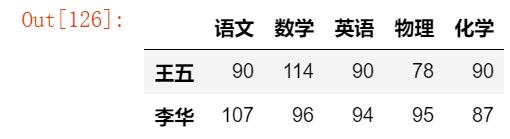
通过标签进行选择数据:
df.loc[:,['语文','化学','数学']] #提取-'语文','化学','数学'三列的数据
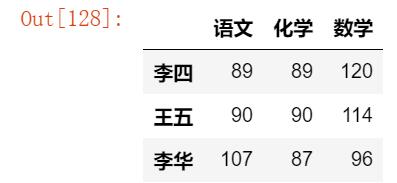
截取行并对列进行切片:
df.loc['李四':'李华',['语文','化学','数学']]
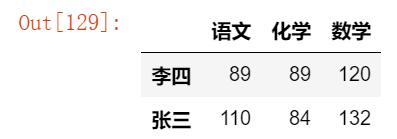
截取指定行和指定列:
df.loc[['李四','张三'],['语文','化学','数学']]
通过位置选择:
# 通过传递数值进行位置选择(选择的是行)
df.iloc[3]
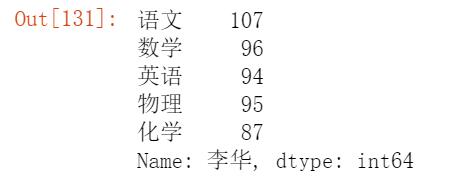
通过数值进行切片:
df.iloc[3:4,3:4] #对第3行,第3列的数据切片截取

通过指定一个位置进行选择数据:
df.iloc[[1,2,4],[0,2]] #选取表中位置 第1,2,4行,语文和英语列的数据

布尔索引:
#通过条件进行判断,并返回相应布尔值
df['语文']>90
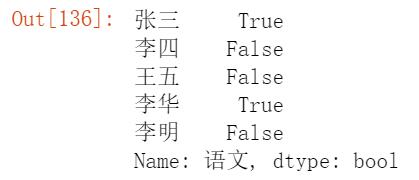
4.缺省值处理
在pandas中,使用np.nan来代替缺失值,这些值将默认不会包含在计算中
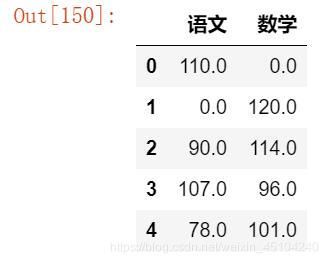
data = {
'语文': [110,np.nan,90,107,78], '数学': [np.nan,120,114,96,101]}
df = pd.DataFrame(data)
df

去掉包含缺省值的行
df.dropna(how='any')

对数据进行布尔填充
#对数据进行布尔填充(将全部数据进行替换成布尔值)
pd.isnull(df)

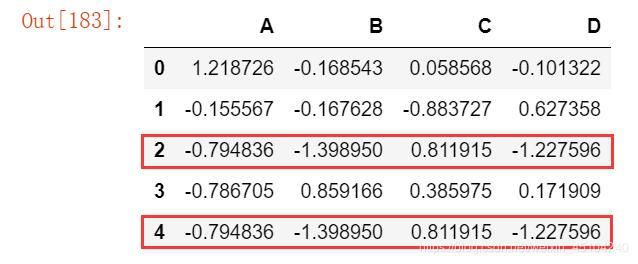
5.合并
df = pd.DataFrame(np.random.randn(4,4),columns=list('ABCD'))
print(df)
s = df.iloc[2] #将第3行的数据append到最后一行
df.append(s,ignore_index=True)
导入和保存数据
# 写入csv文件
df.to_csv('data.csv')
# 从csv文件中读取
pd.read_csv('data.csv')
# 写入excel文件
df.to_excel('data.xlsx',sheet_name='Sheet1')
# 从excel文件中读取
pd.read_excel('data.xlsx','Sheet1')
# 写入HDF5存储
df.to_hdf('data.h5','df')
# 从HDF5存储中读取
pd.read_hdf('data.h5','df')
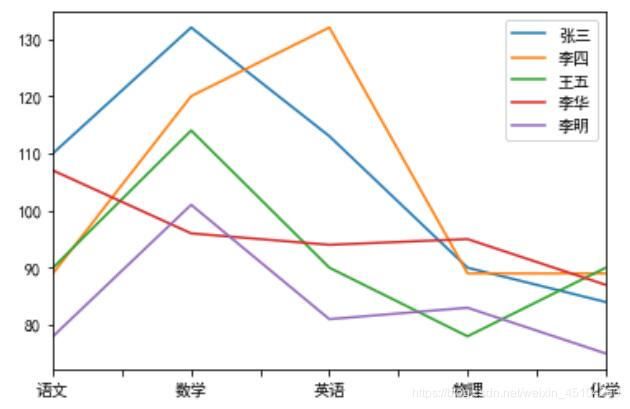
使用matplotlib生成数据分析图片并保存:
import matplotlib.pyplot as plt
#解决中文显示问题
from pylab import mpl
mpl.rcParams["font.sans-serif"] = ["SimHei"]
df.T.plot()
plt.savefig('./p2t.png')