正则表达式学习
- 正则表达式就用来是解决字符串搜索与替换问题的,可以用正则表达式引擎判断一个字符串是不是符合正则表达式引擎中的定义好的规则,并且规则往往是几个简单地字符表示的,看上去很简洁,只不过如果不会正则表达式的,看起来会更加难懂
- 正则表达式的作用核心是使用状态机的思想进行模式匹配
- 个人理解写好正则表达式只需要组合好 唯一匹配+重复匹配+规则关系即可
字符
精确匹配,也就是一模一样
System.out.println("t".matches("t")); // true System.out.println("t*".matches("t\\*")); // true 注意对于一般字符串 *不是特殊字符 在正则中*是特殊字符,因此要表达其本来的意思需要使用转义(此转义时正则中的转义,不是一般的转义字符),即\*,但是\*并非标准的转义字符,因此使用\字符与*字符拼接标识转义(此转义时正则中的转义,而不是一般字符串中的转义),而表达字符则需要\\ System.out.println("$".matches("\\$")); // true System.out.println("\t".matches("\t")); // false 正则匹配转义字符,源字符串解析不解析为转义 System.out.println("\t".matches("\\t")); // true正则从左到右匹配,在正则中用到了对于\的转义标识\字符串本身,这里匹配时把普通字符串中的转义字符视为两个字符,相当于精确匹配 System.out.println("\\t".matches("\\t")); // false System.out.println("\\t".matches("\\\\t")); // true 正则表达式中匹配转义,源字符串不匹配转义对于正常的字符串来说,除了普通字符和转义字符之外,特殊字符有如下几个
\作为转义字符的标识符,如果想不做为标识符使用,而是单独作为字符串本身使用,必须使用\\'单引号,Java的字符,js的字符串,都可以使用单引号标识,因此为了避免混淆使用\'标识单引号本身"双引号,多种语言的字符都使用双引号标识,为了避免混淆使用\"标识双引号字符本身
正则接受一般的转义字符,也接受正则自己引入的所谓的转义字符(提供正则功能)
对于正则引擎来说对于一般的转义字符,
\与后边的被转译字符视为一个字符(事实上也确实如此),而对于正则自己引入的转义字符,\与后边的被转译字符视为两个字符,只不过这种字符组合构成了转义的功能- 但是对于待匹配或替换处理的原始字符串不会把转义字符当做一个字符来处理,而是拆开处理
正则自己引入的字符
- 让特殊字符失去其本意的转义
System.out.println("t*".matches("t\\*")); - 提供特殊功能的转义
\w \d
- 让特殊字符失去其本意的转义
使用正则表达式引擎提供的特殊字符时务必注意不要与转义字符混淆
转义字符的作用是让一个特殊字符失去其本身的含义,而作为一个普通的字符,对于普通字符来说即使使其具有特殊的含义
特殊字符以及其本身含有的特殊含义包括:
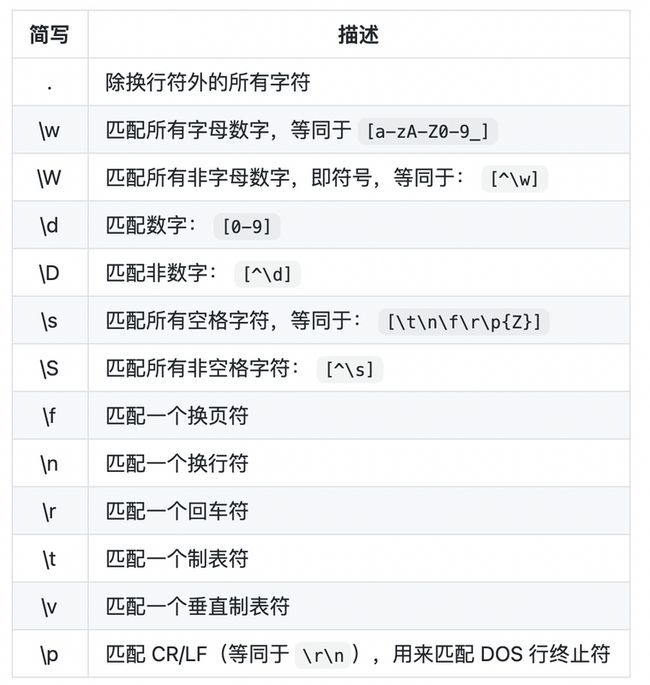
表示唯一匹配(匹配有限数量的字符)
- . 匹配一个并且必须是1个的除了换行符之外的任意字符
\d匹配一个数字\D除了数字之外的字符\w字母、数字、下划线\W除了字母、数字、下划线之外的字符\s空白字符(空格+制表符+换页符+换行符)\S除了空白字符之外的其他字符指定范围的匹配
[123]枚举匹配- 枚举匹配时需要注意,方括号内可以直接枚举特殊字符,包括* ?+ 等等而不需要做转义即可表示字符串本身
[n-m1-2A-b]指定范围匹配(范围的起始点与终止点都包含)(注意多范围之间无空格)使用^取非注意仅在范围匹配,也就是方括号内部使用^做取非
- 除了上述的特殊字符外,正则还提供了一些其他的特殊字符,部分特殊字符与普通的转义字符重复
重复匹配(匹配无限数量的字符)(通配符+集合区间)(重复匹配作为修饰符放在唯一匹配的字符后边)
- 星号
匹配任意多个符合规则的字符 - 加号
匹配至少一个 ?匹配0个或者1个{n}匹配n个{n,m}匹配至少n个,至多m个,m省略表示至少含义,n设置为0表示至多含义
- 星号
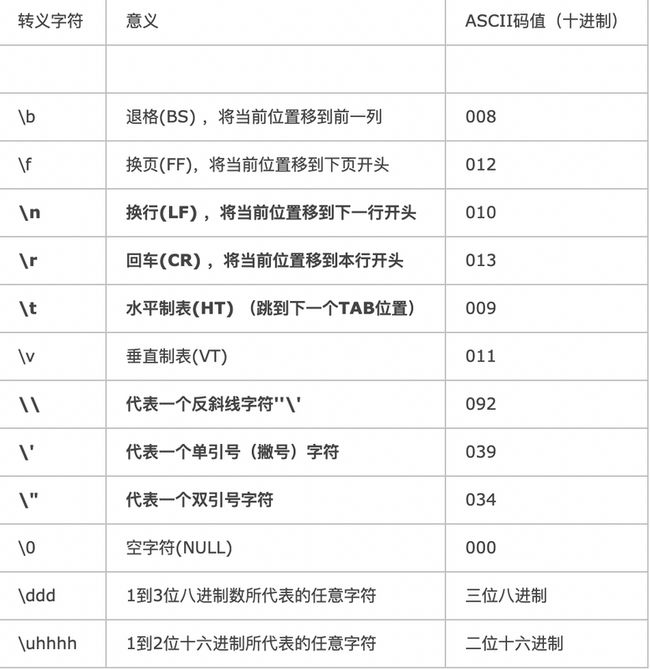
对于普通字符的转义
- 正则表达式中需要进行转义以表示字符本身的特殊字符
- *
- .
- ?
- +
- $
- ^
- 方括号
- 圆括号
- 大括号
- |
- \
规则
位置边界+正则模式
- 位置边界用来限制匹配的位置,通过限制匹配的位置筛选掉不符合条件的匹配
单词边界
\b字符边界(注意这个正则的特殊字符与普通转义字符中有重复,在正则中显然作为字符边界处理)- b是boundary的首字母。在正则引擎里它匹配的是能构成单词的字符(\w)和不能构成单词的字符(\W)中间的那个位置
\B标识非字符边界案例
String p = "The cat scattered his food all over the room."; System.out.println(p.replaceAll("\\bcat\\b", "*")); // The * scattered his food all over the room.- 注意正则的内置特殊字符的使用方式
- 注意replaceAll API的使用:直接返回更改后的新的String,而不是把新的String赋给原字符串变量引用变量
字符串边界
适用于多行匹配的模式下对于字符串的匹配
^标识字符串的开头是否使用
^边界符号的区别在于,是否是针对整个字符串的匹配"(T|t)he" => The car is parked in the garage. // 字符串中的两个the都会被选中 "^(T|t)he" => The car is parked in the garage. // 只有字符串首部的The被选中,因为筛选的是以The或者the开头的字符串
$标识字符串的结尾同样的,是否使用
$边界符号的区别在于,是否是针对整个字符串的匹配"(at\.)" => The fat cat. sat. on the mat. // cat. sat. mat.都被选中 "(at\.)$" => The fat cat. sat. on the mat. // 只有最后一个mat.被选中
字符串边界符号与正则模式的配合使用
在多行字符串的匹配中当只是用字符串边界符号时,仅仅能匹配第一行或最后一行,因为有换行符的存在所以只能匹配一行
String p1 = String.join("\n", "I am scq000.", "I am scq000."); // * // I am scq000. System.out.println(p1.replaceAll("^I am scq000\\.", "*")); // I am scq000. // * System.out.println(p1.replaceAll("I am scq000\\.$", "*")); // 多行无法匹配 // I am scq000. // I am scq000. System.out.println(p1.replaceAll("^I am scq000\\.$", "*"));多行匹配的引入
System.out.println(p1.replaceAll("(?m)^I am scq000\\.$", "*"));- 使用
(?m)引入多行模式
Pattern p = Pattern.compile("^I am scq000\\.$", Pattern.MULTILINE); Matcher m = p.matcher(p1); System.out.println(m.find());- 使用Pattern解析正则,引入正则模式
Pattern p1 = Pattern.compile("^.*b.*$"); //输出false,因为正则表达式中出现了^或$,默认只会匹配第一行,第二行的b匹配不到。 System.out.println(p1.matcher("a\nb").find()); Pattern p2 = Pattern.compile("^.*b.*$",Pattern.MULTILINE); //输出true,指定了Pattern.MULTILINE模式,就可以匹配多行了。 System.out.println(p2.matcher("a\nb").find());"/.at(.)?$/" => The fat cat sat on the mat. 只有mat匹配 "/.at(.)?$/gm" => The fat cat sat on the mat. fat sat mat都匹配- 使用
正则模式
m多行模式g全局模式 匹配全部的符合规则的而不只是第一个i忽略大小写指定模式的两种方式:
在正则表达式中指定
- 注意Java中使用正则表达式模式的方式
String p1 = String.join("\n", "I Am scq000.", "I am scq000."); // 结果为: // I Am scq000. // * // 可见第一行并未匹配 System.out.println(p1.replaceAll("I am scq000\\.", "*")); // 多行模式 大小写无关模式 // 结果为: // * // * // 可见全部都匹配 System.out.println(p1.replaceAll("(?mi)I am scq000\\.", "*"));- 在最开头使用
(?m)(?i)来标识正则模式,也可以使用组合模式(?mi) - 全局模式不能使用此方法指定,全局还是非全局更多的是通过API的方式,比如
replaceAllreplaceFirst
在API参数中指定
Pattern p1 = Pattern.compile("^.*b.*$"); //输出false,因为正则表达式中出现了^或$,默认只会匹配第一行,第二行的b匹配不到。 System.out.println(p1.matcher("a\nb").find()); Pattern p2 = Pattern.compile("^.*b.*$",Pattern.MULTILINE); //输出true,指定了Pattern.MULTILINE模式,就可以匹配多行了。 System.out.println(p2.matcher("a\nb").find());Pattern解析正则时除了提供了多行模式外,还提供了以下几种模式
DOTALL模式 用来解决正则表达式中的
.通配符不包含换行符带来的问题Pattern p1 = Pattern.compile("a.*b"); //输出false,默认点(.)没有匹配换行符 System.out.println(p1.matcher("a\nb").find()); Pattern p2 = Pattern.compile("a.*b", Pattern.DOTALL); //输出true,指定Pattern.DOTALL模式,可以匹配换行符。 System.out.println(p2.matcher("a\nb").find());- UNIX_LINES
- CASE_INSENSITIVE
- LITERAL
- UNICODE_CASE
- CANON_EQ
- UNICODE_CHARACTER_CLASS
同时使用多个模式的案例
Pattern p1 = Pattern.compile("^a.*b$"); //输出false System.out.println(p1.matcher("cc\na\nb").find()); Pattern p2 = Pattern.compile("^a.*b$", Pattern.DOTALL); //输出false,因为有^或&没有匹配到下一行 System.out.println(p2.matcher("cc\na\nb").find()); Pattern p3 = Pattern.compile("^a.*b$", Pattern.MULTILINE); //输出false,匹配到下一行,但.没有匹配换行符 System.out.println(p3.matcher("cc\na\nb").find()); //指定多个模式,中间用|隔开 Pattern p4 = Pattern.compile("^a.*b$", Pattern.DOTALL|Pattern.MULTILINE); //输出true System.out.println(p4.matcher("cc\na\nb").find());
- 以上各个模式的用途可查看源码注释,每一个模式都支持对应的正则表达式内嵌的标识方法,可以参考其注释
子表达式
- 使用小括号将表达式进行拆分,得到子正则表达的组合,更加灵活。
- 一个简单的例子:座机号码的区号-电话号的组合,匹配之后,想拆分出区号与电话号,可以使用split,substring等复杂的方法,但是比较麻烦,并且没有复用性,使用分组可以方便的进行拆分并得到其匹配的值
- 要想高效使用分组子表达式需要用到回溯引用
回溯引用
回溯引用是在分组的基础之上使用的,指的是模式的后边的部分引用前边部分的已经匹配了的子表达式,使用回溯表达式有以下两点好处
可以写出更加精简高效的正则
在正则表达式中直接使用回溯的语法是:
- 回溯引用的语法像
\1,\2,....,其中\1表示引用的第一个子表达式,\2表示引用的第二个子表达式,以此类推。而\0则表示整个表达式 - 案例:匹配字符串中的两个连续的相同的单词
Hello what what is the first thing, and I am am scq000.---\b(\w+)\s\1
- 回溯引用的语法像
可以使用正则抽取分组信息
Pattern类配合Matchr类
String regex20 = "([0-9]{3,4})-([1-9]{7,8})"; Pattern pattern = Pattern.compile(regex20); Matcher matcher = pattern.matcher("0312-2686815"); // 注意只有经过matches判断后的matcher才能进行分组提取,否则会报错No Match Fund if (matcher.matches()) { // 注意分组从1开始,序号为0的分组是字符串整体 // 区号 System.out.println(matcher.group(1)); // 电话号 System.out.println(matcher.group(2)); // 匹配的整体 System.out.println(matcher.group(0)); } else { System.out.println("不匹配"); } // 去掉区号 System.out.println("0312-2686815".replaceAll(regex20, "$2"));"str.matches"方法内部使用的也是Pattern与Matchr,每一次调用方法都创建一个新的Patterm对象和一个新的Matcher对象,推荐直接定义一个Pattern来复用,以提升性能- 使用回溯进行分组提取时,使用的特殊字符为
$1而不是\1,同样注意$0代表整体,$1才是第一个分组,以此类推
如果要拒绝子正则表达式被引用,则在子正则的前边加上
?:String regex20 = "(?:[0-9]{3,4})-([1-9]{7,8})"; // $0仍然是表示整体,$1由第二个子表达式补位,此时再引用$2 会报错No Group 2 System.out.println("0312-2686815".replaceAll(regex20, "$2"));由上边的非捕获正则
?:引出前向查找和后向查找(也可以称作零宽度断言)----相对来说说比较难以理解- 使用断言的说法更容易理解,因为其作用就在于对子表达式附加断言,从而为正则匹配添加筛选条件,所谓前后就是表征这个断言限制条件是作用在子表达式前还是后(关于后发的写法的记忆手段:从后指向前的箭头),所谓正负表征的就是逻辑上的是与否(正负在写法上的差别就是=与!的差别)
- 需要注意的是断言表达式本身不作为匹配的内容,只是作为断言的辅助说明
正先行断言
(?=regex)"(T|t)he(?=\sfat)" => The fat cat sat on the mat.匹配第一个The- 除断言之外的表达式可以匹配两个the,加入断言后只匹配第一个The,因为其后边是
fat
负先行断言
(?!regex)"(T|t)he(?!\sfat)" => The fat cat sat on the mat.匹配第二个the- 筛选出不满足断言的
正后发断言
(?<=regex)"(?<=(T|t)he\s)(fat|mat)" => The fat cat sat on the mat.匹配fat和mat- 断言条件的位置在子正则之前
负后发断言
(?"(? The cat sat on cat.匹配第二个cat
逻辑组合
- 在正则中,多个规则写在一起时,默认是与关系
|或关系[^]枚举或指定范围的匹配的取反!负先发断言,负后发断言
贪婪匹配与惰性匹配
- 默认是贪婪匹配,贪婪匹配会在从左到右的匹配中匹配尽可能多的字符
"/(.*at)/" => The fat cat sat on the mat.整个字符串全部匹配 - 贪婪匹配更改为惰性匹配使用
?即可:将?加在重复匹配的修饰符(*+?等)后边即可 案例
"/(.*?at)/" => The fat cat sat on the mat.at前边是任意数量的字符,惰性匹配就在这个任意数量的修饰符后加上?标识尽可能少匹配字符 因此只匹配The fat判断字符串数字末尾的0的个数
123000->"(\\d+)(0*)"->"123000" ""至少一个数字?我全都要123000->"(\\d+?)(0*)"->"123" "000"至少一个数字?那就给你1个吧!但是考虑到后边的只想要0,那就把0前边的都给你0000->"(\\d+?)(0*)"->"0" "000"至少一个数字,那就给你1个,其余的后边的正好都要!哈哈9999->"(\\d??)(9*)"->"" "9999"可有可无,正好后边都想要呢,那你就没了~