Redis Cluster 采用去中心化的路由方案,cluster 中的每个 node 都可以感知到完整路由表,为了能够正确地访问到数据,路由表的正确性保证至关重要。
在 cluster 节点数量一定的情况下,有两种情况可以导致路由的变化,即主从关系变更和 slot resharding。
同时,需要考虑 server 重启和 partition 恢复后如何去更新本地旧的路由信息。
本文将结合代码片段逐一分析。
主从关系变更
failover
执行 failover 后,首先在本地做变更,然后通过 gossip 信息传播,使得路由在 cluster 内打平。
本节点变更
不管是主动 failover 还是被动 failover,流程的最后一步都需要调用 clusterFailoverReplaceYourMaster 函数。
从代码可以看出,有以下 5 个步骤,
1)修改节点 flag 标识
/* 1) Turn this node into a master. */
clusterSetNodeAsMaster(myself); void clusterSetNodeAsMaster(clusterNode *n) {
if (nodeIsMaster(n)) return;
if (n->slaveof) {
clusterNodeRemoveSlave(n->slaveof,n);
if (n != myself) n->flags |= CLUSTER_NODE_MIGRATE_TO;
}
n->flags &= ~CLUSTER_NODE_SLAVE;
n->flags |= CLUSTER_NODE_MASTER;
n->slaveof = NULL;
/* Update config and state. */
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE);
}去掉 CLUSTER_NODE_SLAVE 标识,变更为 CLUSTER_NODE_MASTER,取消本地路由表中原有的主从关系。
2)接管 slot
/* 2) Claim all the slots assigned to our master. */
clusterNode *oldmaster = myself->slaveof;
for (j = 0; j < CLUSTER_SLOTS; j++) {
if (clusterNodeGetSlotBit(oldmaster,j)) {
clusterDelSlot(j);
clusterAddSlot(myself,j);
}
}将 oldmaster 负责的 slot 全部交给当前节点。
3)更新 cluster state 状态,并保存 config。
/* 3) Update state and save config. */
clusterUpdateState();
clusterSaveConfigOrDie(1);在保存配置前需要先执行clusterUpdateState 函数。
对于被动 failover 的情况,必然是当前节点先检测到了 node fail,那么对于配置了 cluster-require-full-coverage 参数的实例,需要将 cluster 状态更新为 CLUSTER_FAIL。
4)广播路由变更
/* 4) Pong all the other nodes so that they can update the state
* accordingly and detect that we switched to master role. */
clusterBroadcastPong(CLUSTER_BROADCAST_ALL);遍历本地路由表中所有认识的节点,发送 pong 消息,告知它们新的路由信息。
5)重置 mf 状态
/* 5) If there was a manual failover in progress, clear the state. */
resetManualFailover();注意:
如果,此时在该节点上执行 cluster nodes 命令,会看到该节点已经切换为 master,且携带 slot,而原来的 master 依然是 master,只是不再负责 slot。
路由打平
上一小结步骤 4)中发出的 pong 消息,会在 cluster 其他 node 引起路由更改。
为表述方便,做如下假设。
正常 cluster 中有以下关系:A1 为 slave,A 是 A1 的 master,负责 0-100 slot,路人节点 B。
那么,路由在 A/A1/B 三者之间打平,需要以下 5 个步骤。
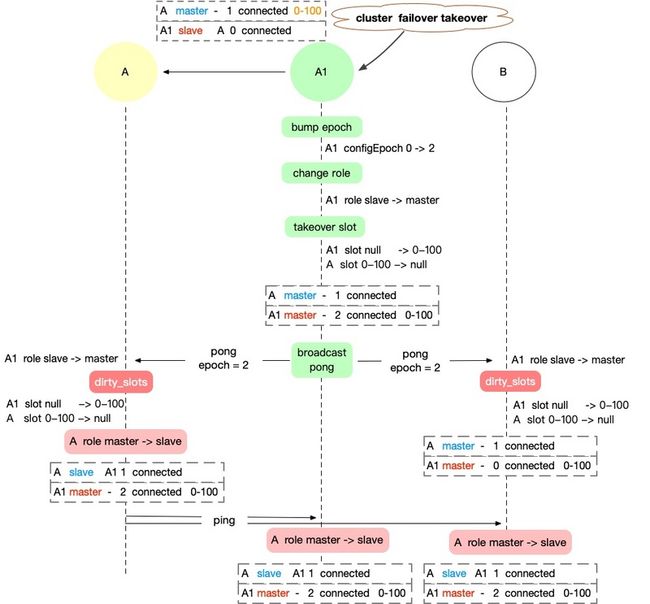
① 新主节点 A1 更新,A1(myself) role slave → master,接管 slot,此时 A 仍是 master ,但没有了 slots,广播 pong
② 原主节点 A 更新,A1 role slave → master,接管 slots,A(myself) role master → slave,抹掉 slots。A 路由更新完成。
③ 路人节点 B 更新,A1 role slave → master,[接管 slots],A 还是 master ,但不负责 slots。
④ 新主节点 A1 收到 A 的 ping,或者主动 ping A,A role master → slave。A1 路由更新完成。
⑤ 路人节点 B 同 ④ 逻辑 (等待额外的 pingpong)。路人 B 路由更新完成。
实际上,以上 5 个步骤中, ① 必然第一个执行, 由于网络的不可靠,③ 和 ⑤ 的发生顺序是不确定的。
如果 ③ 发生在 ⑤ 之前,那么路由打平逻辑如下图所示,
而如果 ③ 发生在 ⑤ 之后,那么路由打平逻辑将做如下变更,
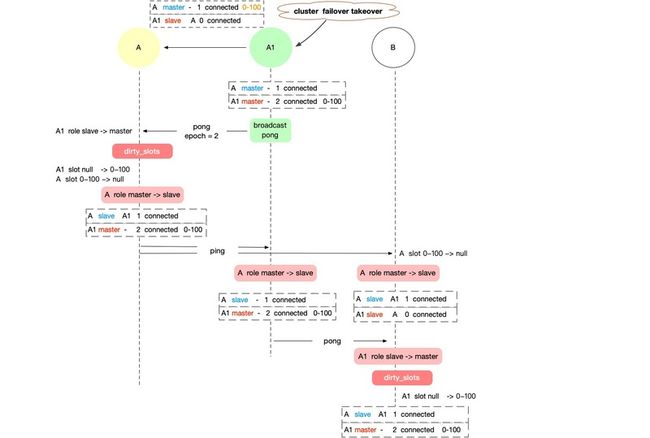
重点区别在路人节点 B 上对于 A/A1 的更新!
注意:
对于 node 信息的变更,一定要以“当事人”说的为准!
A1 对原 master 节点 A 的 role 信息变更一定发生在 A 自己的 role 变更之后!
A1 做 failover 后,只更改了自己的信息,不去改 A 的 role,至于 A 要怎么改,需要 A 发信息来同步。
replication
执行 CLUSTER REPLICATE 后,仅对本地路由表做了更改,路由打平需要依靠 ping-pong 消息实现。
else if (!strcasecmp(c->argv[1]->ptr,"replicate") && c->argc == 3) {
...
/* Set the master. */
clusterSetMaster(n);
clusterDoBeforeSleep(CLUSTER_TODO_UPDATE_STATE|CLUSTER_TODO_SAVE_CONFIG);
addReply(c,shared.ok);
}在某节点收到 ping 或者 pong 消息时,对 role 信息进行校验,核心逻辑如下,
int clusterProcessPacket(clusterLink *link) {
...
/* Check for role switch: slave -> master or master -> slave. */
if (sender) {
if (!memcmp(hdr->slaveof,
CLUSTER_NODE_NULL_NAME, sizeof(hdr->slaveof)))
{
/* sender claimed it is a master. */
clusterSetNodeAsMaster(sender);
} else {
/* sender claimed it is a slave. */
clusterNode *master = clusterLookupNode(hdr->slaveof);
...
/* Master node changed for this slave? */
if (master && sender->slaveof != master) {
if (sender->slaveof)
clusterNodeRemoveSlave(sender->slaveof,sender);
// 绑定新的主从关系
clusterNodeAddSlave(master,sender);
sender->slaveof = master;
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG);
}
}
}
...
}当检测到 sender 的 master 发生变化时,调用 clusterNodeRemoveSlave 函数,把它从原来的主从关系绑定中释放出来,绑定新的主从关系。
slot 变更
在 slot resharding 的过程中,会发生 slot ownership 的重新绑定,详细过程已经在之前的博客 《Redis 源码分析之数据迁移》中详细介绍过,这里只说明路由打平逻辑。
在 slot 迁移的最后一步,更改目标节点路由时,有以下逻辑,
else if (!strcasecmp(c->argv[1]->ptr,"setslot") && c->argc >= 4) {
...
else if (!strcasecmp(c->argv[3]->ptr,"node") && c->argc == 5) {
...
if (n == myself &&
server.cluster->importing_slots_from[slot])
{
if (clusterBumpConfigEpochWithoutConsensus() == C_OK) {}
server.cluster->importing_slots_from[slot] = NULL;
}
clusterDelSlot(slot);
clusterAddSlot(n,slot);
}
}在 clusterBumpConfigEpochWithoutConsensus 函数中,迁移目标节点要保证自己的 configEpoch 为 cluster 中最大。
其他节点在 ping-pong 消息处理中,通过 diff 对路由进行相应的变更,代码如下,
int clusterProcessPacket(clusterLink *link) {
...
clusterNode *sender_master = NULL; /* Sender or its master if slave. */
int dirty_slots = 0; /* Sender claimed slots don't match my view? */
if (sender) {
sender_master = nodeIsMaster(sender) ? sender : sender->slaveof;
if (sender_master) {
dirty_slots = memcmp(sender_master->slots,
hdr->myslots, sizeof(hdr->myslots)) != 0;
}
}
if (sender && nodeIsMaster(sender) && dirty_slots)
clusterUpdateSlotsConfigWith(sender,
senderConfigEpoch,hdr->myslots);
...
}以上代码可以看出,当某节点看到的 sender 负责的 slot,与 sender 提交的信息不一致时,调用 clusterUpdateSlotsConfigWith 函数进行路由矫正。
void clusterUpdateSlotsConfigWith(clusterNode *sender, uint64_t senderConfigEpoch, unsigned char *slots) {
...
if (server.cluster->slots[j] == NULL ||
server.cluster->slots[j]->configEpoch < senderConfigEpoch)
{
...
clusterDelSlot(j);
clusterAddSlot(sender,j);
...
}
...
}路由信息根据 configEpoch 更新,configEpoch 越大表明路由越新。
注意,该函数中有一个逻辑需要格外注意,关键代码如下,
clusterNode *curmaster, *newmaster = NULL;
curmaster = nodeIsMaster(myself) ? myself : myself->slaveof;
if (server.cluster->importing_slots_from[j]) continue;
if (server.cluster->slots[j] == NULL ||
server.cluster->slots[j]->configEpoch < senderConfigEpoch)
{
...
if (server.cluster->slots[j] == curmaster)
newmaster = sender;
}
...
if (newmaster && curmaster->numslots == 0) {
clusterSetMaster(sender);
}如果当前节点或当前节点的 master 失去某 slot 的所有权时,newmaster 会记录 slot 所有权被谁夺走了。如果全部被夺走了,那么就认对方为自己的 master。
有这样一种情况,假设现在集群路由关系如下,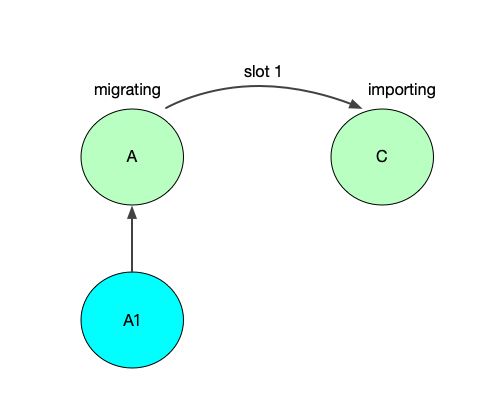
A 往 C 迁移最后一个 slot,正常步骤如下:
① 目的 C 执行 SETSLOT 命令,C 拥有 slot 1
② 源节点 A 执行 SETSLOT 命令,A 失去 slot 1
但是 ①② 不是原子操作,A 在执行 SETSLOT 命令之前,有可能会先收到 C 的 ping 或者 pong,按照上面代码分析的逻辑,A 就成了 C 的 slave,即 A1 slaveof A,A slaveof C。
过期修复
当 server 重启或 partition 恢复后,可能会因为本地路由信息过旧而搞乱整个 cluster 路由,在 Redis Cluster 中使用 CLUSTERMSG_TYPE_UPDATE 类型消息对此进行处理。代码大致如下,
int clusterProcessPacket(clusterLink *link) {
...
if (sender && dirty_slots) {
int j;
for (j = 0; j < CLUSTER_SLOTS; j++) {
if (bitmapTestBit(hdr->myslots,j)) {
if (server.cluster->slots[j] == sender ||
server.cluster->slots[j] == NULL) continue;
if (server.cluster->slots[j]->configEpoch > senderConfigEpoch)
{
clusterSendUpdate(sender->link, server.cluster->slots[j]);
break;
}
}
}
}
}如果本地看到的 slot j 的所有者信息比 sender 声明的要新,那么,通知它去做更新。
typedef struct {
uint64_t configEpoch; /* Config epoch of the specified instance. */
char nodename[CLUSTER_NAMELEN]; /* Name of the slots owner. */
unsigned char slots[CLUSTER_SLOTS/8]; /* Slots bitmap. */
} clusterMsgDataUpdate;CLUSTERMSG_TYPE_UPDATE 消息中会告诉对方,该 slot 应该属于谁。
在以上代码中,只是在检查到第一个 slot 信息出现 diff 时,发送 CLUSTERMSG_TYPE_UPDATE 消息,如果出现多个 slot 有不同的持有信息,那么需要多次信息交互。
以上便是 Redis Cluster 中路由更新的所有情况。