超详细的yolov3深度剖析+源码debug级讲解(一)
前言
大家好!很久不写CSDN了,今年一直在学习计算机视觉方向以及参加竞赛。在学习过程中有很多重要的框架,比如目标检测的yolov3,faster-rcnn,efficientdet;语义分割的unet,deeplabv3+,HRnet;backbone网络的resnest,res2net,efficientnet等等。
我在学习过程中找到了不少写的不错的资料,但是很多重点难点也被忽略了,而且很少有对于源码的完整分析。因此我想写一个系列,更为详细的讲解这些经典或者SOTA的框架。
我做这个系列的目的就是为了让大家只要肯坚持看完这一系列的博客,就会对yolov3的源码完全理解,话不多说,我们进入学习吧!
Part1. models.py文件里的模型创建
1.如何更方便的准备debug环境?
我们选取的源码是github上5.7k star的 pytorch implementation
项目源码地址
下面我们从models.py文件入手。在讲源码的过程中采用了debug模式,这样可以更为深入的分析整个tensor数据流的变化。默认的数据集是coco数据集,完整下载要十几G,但是作者也留下了一个小的入口,方面大家debug。
这个入口是一张图片,需要修改train.py文件里面的一行内容:
parser.add_argument("--data_config", type=str, default="config/custom.data", help="path to data config file")
也就是把coco数据集改为custom数据集,custom数据集里只包含一张图片,对应的GT labels里面只包含一个target。为了看清楚target的变换,我们再多加一个target,只需修改一下custom/labels里面的train.txt。
D:\pyprojects\object-detection-code-debug\PyTorch-YOLOv3\data\custom\labels
我多加了一个target,所以改成了:

同时大家也可能看到里面的数值是5列,分别对应了target的class,x, y中心坐标, target高宽h, w,注意这里都是对应于原图进行的归一化。
修改完之后就可以跑train.py了。我们在models.py里面增加debug断点,便于分析源码,观察数据变化。
2.parse_model_config()函数是如何加载配置文件的?
首先最外层是models.py里面的Darknet Class。重点的代码是下面这段:
class Darknet(nn.Module):
"""YOLOv3 object detection model"""
def __init__(self, config_path, img_size=416):
super(Darknet, self).__init__()
self.module_defs = parse_model_config(config_path) # 得到list[dict()]类型的model配置信息表
self.hyperparams, self.module_list = create_modules(self.module_defs)
self.yolo_layers = [layer[0] for layer in self.module_list if isinstance(layer[0], YOLOLayer)]
self.img_size = img_size
self.seen = 0
self.header_info = np.array([0, 0, 0, self.seen, 0], dtype=np.int32)
def forward(self, x, targets=None):
img_dim = x.shape[2] # 图像的尺寸
loss = 0
layer_outputs, yolo_outputs = [], []
for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):
if module_def["type"] in ["convolutional", "upsample", "maxpool"]:
x = module(x)
elif module_def["type"] == "route":
# torch.cat 对单个tensor相当于保持原样
x = torch.cat([layer_outputs[int(layer_i)] for layer_i in module_def["layers"].split(",")], 1)
elif module_def["type"] == "shortcut":
layer_i = int(module_def["from"])
x = layer_outputs[-1] + layer_outputs[layer_i]
elif module_def["type"] == "yolo":
x, layer_loss = module[0](x, targets, img_dim)
loss += layer_loss
yolo_outputs.append(x)
layer_outputs.append(x)
yolo_outputs = to_cpu(torch.cat(yolo_outputs, 1))
return yolo_outputs if targets is None else (loss, yolo_outputs)
我们从init函数看起,首先是:
self.module_defs = parse_model_config(config_path)
这句调用了parse_model_config函数,那我们首先看一下这个函数:
def parse_model_config(path):
"""通过cfg文件加载yolov3的配置,并存储到list[dict()]的结构中
每一层以“[”作为标记的开始
"""
file = open(path, 'r', encoding="utf-8")
lines = file.read().split('\n')
lines = [x for x in lines if x and not x.startswith('#')]
lines = [x.rstrip().lstrip() for x in lines] # get rid of fringe whitespaces
module_defs = []
for line in lines:
if line.startswith('['): # This marks the start of a new block
module_defs.append({
})
module_defs[-1]['type'] = line[1:-1].rstrip()
# 初始化batch-normal参数 配置文件里还是加载为1
if module_defs[-1]['type'] == 'convolutional':
module_defs[-1]['batch_normalize'] = 0
else:
key, value = line.split("=")
value = value.strip()
module_defs[-1][key.rstrip()] = value.strip()
return module_defs
这个函数的作用很明显,就是加载配置文件,然后把配置文件里面的模型结构解析出来。配置文件的形式大家在项目里也是可以找到的,结尾是cfg的文件。
打开yolov3.cfg,再结合刚才的源码,很容易知道每个[]代表一个module的开始,每个module以一个dict()的形式去存放相关的参数,仔细观察cfg配置文件可以知晓module分为以下几类:
[net]
# Training
batch=16
subdivisions=1
width=416
...
[net]:模型的参数以及一些可配置的学习策略参数
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[convolution]:卷积层,参数指定了常见的有卷积核的kernel size、padding、stride之类的。以及是否跟随BN层,是否跟随激活层。可以注意到默认的激活函数是leaky-relu。
[shortcut]
from=-3
activation=linear
[shortcut]:这个对应的是残差结构,from=-3指代的是从当前结果和哪个层的输出进行残差结构。-3就是从当前的结果回溯三层的输出。
[yolo]
mask = 6,7,8
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
[yolo]:yolo对应的是一个模型的最终输出,因为yolov3采用的类似FPN结构的输出,所以有3个yolo layer。
[route]
layers = -4
[route]:层指代的来自不同层的特征融合。是tensor在channel维度的叠加。因为存在FPN结构,所以yolov3 在多个地方进行了上采样+特征融合。
[upsample]
stride=2
[unsample]:就比较简单了,就是2倍上采样。默认的是通过双线性插值的方式来进行的。
3.怎样更方便的debug yolov3模型结构?
这部分最好的debug方式就是调用parse_model_config()函数去把模型的每一层打印出来,我们在parse_config.py里面添加一个main函数,解析yolov3.cfg文件:
if __name__ == '__main__':
path = "../config/yolov3.cfg"
res = parse_model_config(path)
for i in range(len(res)):
print(f"###layer{i}###")
print(res[i])
观察打印出的模型结构:
###layer0###
{
'type': 'net', 'batch': '16', 'subdivisions': '1', 'width': '416', 'height': '416', 'channels': '3', 'momentum': '0.9', 'decay': '0.0005', 'angle': '0', 'saturation': '1.5', 'exposure': '1.5', 'hue': '.1', 'learning_rate': '0.001', 'burn_in': '1000', 'max_batches': '500200', 'policy': 'steps', 'steps': '400000,450000', 'scales': '.1,.1'}
###layer1###
{
'type': 'convolutional', 'batch_normalize': '1', 'filters': '32', 'size': '3', 'stride': '1', 'pad': '1', 'activation': 'leaky'}
###layer2###
{
'type': 'convolutional', 'batch_normalize': '1', 'filters': '64', 'size': '3', 'stride': '2', 'pad': '1', 'activation': 'leaky'}
###layer3###
{
'type': 'convolutional', 'batch_normalize': '1', 'filters': '32', 'size': '1', 'stride': '1', 'pad': '1', 'activation': 'leaky'}
###layer4###
{
'type': 'convolutional', 'batch_normalize': '1', 'filters': '64', 'size': '3', 'stride': '1', 'pad': '1', 'activation': 'leaky'}
...
...
...
###layer107###
{
'type': 'yolo', 'mask': '0,1,2', 'anchors': '10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326', 'classes': '80', 'num': '9', 'jitter': '.3', 'ignore_thresh': '.7', 'truth_thresh': '1', 'random': '1'}
可以看出总共有107个配置信息,第一个是模型的参数,里面有3个yolo layer的信息。这个配置文件不仅包含生成Darknet53的信息,其实包含了生成整个yolov3的信息。这种配置文件生成模型的方式可以快速调整模型结构,并且十分的清晰,值得学习。
这部分很简单,作者想表达的意思是如果想快速并细致的观测模型结构,就必须把模型结构打印出来,并且对照模型结构图逐步观察,这样基本上一次就可以完全熟悉模型结构。下面是yolov3的结构图:
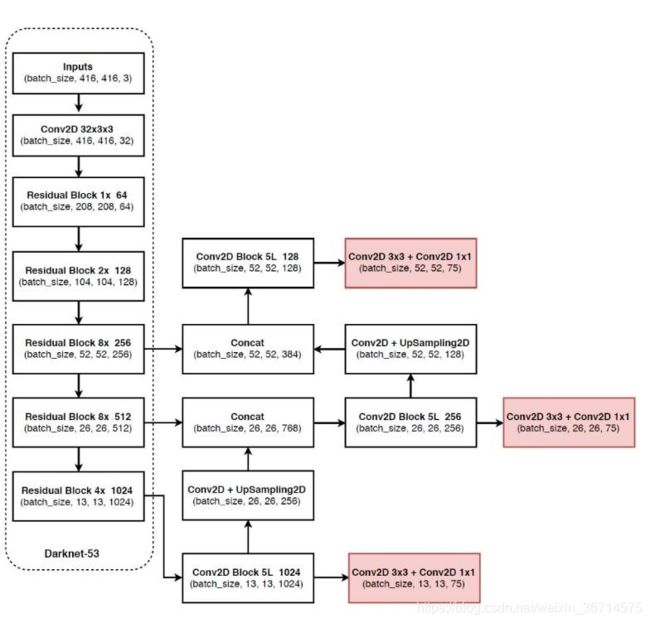
这个图用来配合刚刚打印出来的模型配置信息是非常好的,可以清晰的明白哪里是route,哪里是普通卷积层,哪里是yolo layer。
至此我们拿到了配置文件中每一个module的配置参数,这些module串联起来就可以生成darknet53的的结构,parse_model_config()函数最终得到的是list[dict()]类型的model配置信息表。下一步代码执行了如下内容:
self.hyperparams, self.module_list = create_modules(self.module_defs)
下一步我们就来解析create_modules()函数。
4.create_modules()函数如何构建模型?
首先上这部分的代码:
def create_modules(module_defs):
"""
Constructs module list of layer blocks from module configuration in module_defs
"""
hyperparams = module_defs.pop(0) # 配置信息第一项是超参数
output_filters = [int(hyperparams["channels"])] #记录当前操作输出channel 后面输入channel根据output_filters[-1]取
module_list = nn.ModuleList()
for module_i, module_def in enumerate(module_defs):
modules = nn.Sequential() # 每一层构建单独的nn.Sequential() 最后再统一加到nn.MuduleList()里
if module_def["type"] == "convolutional":
bn = int(module_def["batch_normalize"])
filters = int(module_def["filters"])
kernel_size = int(module_def["size"])
pad = (kernel_size - 1) // 2
modules.add_module(
f"conv_{module_i}",
nn.Conv2d(
in_channels=output_filters[-1],
out_channels=filters,
kernel_size=kernel_size,
stride=int(module_def["stride"]),
padding=pad,
bias=not bn,
),
)
if bn:
modules.add_module(f"batch_norm_{module_i}", nn.BatchNorm2d(filters, momentum=0.9, eps=1e-5))
if module_def["activation"] == "leaky":
modules.add_module(f"leaky_{module_i}", nn.LeakyReLU(0.1))
elif module_def["type"] == "maxpool":
kernel_size = int(module_def["size"])
stride = int(module_def["stride"])
if kernel_size == 2 and stride == 1:
modules.add_module(f"_debug_padding_{module_i}", nn.ZeroPad2d((0, 1, 0, 1)))
maxpool = nn.MaxPool2d(kernel_size=kernel_size, stride=stride, padding=int((kernel_size - 1) // 2))
modules.add_module(f"maxpool_{module_i}", maxpool)
elif module_def["type"] == "upsample":
upsample = Upsample(scale_factor=int(module_def["stride"]), mode="nearest")
modules.add_module(f"upsample_{module_i}", upsample)
elif module_def["type"] == "route": # 对应feature maps间特征融合的结构 方式是concat
layers = [int(x) for x in module_def["layers"].split(",")]
filters = sum([output_filters[1:][i] for i in layers])
modules.add_module(f"route_{module_i}", EmptyLayer())
elif module_def["type"] == "shortcut": # 对应residual的结构 方式是add
filters = output_filters[1:][int(module_def["from"])]
modules.add_module(f"shortcut_{module_i}", EmptyLayer())
elif module_def["type"] == "yolo":
anchor_idxs = [int(x) for x in module_def["mask"].split(",")]
# Extract anchors
anchors = [int(x) for x in module_def["anchors"].split(",")]
anchors = [(anchors[i], anchors[i + 1]) for i in range(0, len(anchors), 2)]
anchors = [anchors[i] for i in anchor_idxs]
num_classes = int(module_def["classes"])
img_size = int(hyperparams["height"])
# Define detection layer
yolo_layer = YOLOLayer(anchors, num_classes, img_size)
modules.add_module(f"yolo_{module_i}", yolo_layer)
# Register module list and number of output filters
module_list.append(modules)
output_filters.append(filters)
return hyperparams, module_list
这部分还是不难理解的。
hyperparams = module_defs.pop(0)
这里拿到了模型和学习策略的配置信息。
for module_i, module_def in enumerate(module_defs):
...
这里开始循环加载模型结构。
if module_def["type"] == "convolutional":
bn = int(module_def["batch_normalize"])
filters = int(module_def["filters"])
kernel_size = int(module_def["size"])
pad = (kernel_size - 1) // 2
modules.add_module(
f"conv_{module_i}",
nn.Conv2d(
in_channels=output_filters[-1],
out_channels=filters,
kernel_size=kernel_size,
stride=int(module_def["stride"]),
padding=pad,
bias=not bn,
),
)
if bn:
modules.add_module(f"batch_norm_{module_i}", nn.BatchNorm2d(filters, momentum=0.9, eps=1e-5))
if module_def["activation"] == "leaky":
modules.add_module(f"leaky_{module_i}", nn.LeakyReLU(0.1))
conv层都默认加了BN,激活函数默认是leaky-relu。这些都是可以调整的,作者在很多竞赛中发现leaky-relu不一定效果会比普通的relu好。
elif module_def["type"] == "maxpool":
kernel_size = int(module_def["size"])
stride = int(module_def["stride"])
if kernel_size == 2 and stride == 1:
modules.add_module(f"_debug_padding_{module_i}", nn.ZeroPad2d((0, 1, 0, 1)))
maxpool = nn.MaxPool2d(kernel_size=kernel_size, stride=stride, padding=int((kernel_size - 1) // 2))
modules.add_module(f"maxpool_{module_i}", maxpool)
elif module_def["type"] == "upsample":
upsample = Upsample(scale_factor=int(module_def["stride"]), mode="nearest")
modules.add_module(f"upsample_{module_i}", upsample)
maxpool是下采样,upsample是上采样,这里都是2倍。但是实际上yolov3里面下采样用的是stride=2的卷积并没有使用maxpool。stride=2的卷积相对于maxpool保留了更多的信息,在一些论文里都有替代maxpool的作用,另外用stride conv下采样的时候也可以考虑大一点的卷积核,但这些都不是本文重点,提一句就此略过。
elif module_def["type"] == "route": # 对应feature maps间特征融合的结构 方式是concat
layers = [int(x) for x in module_def["layers"].split(",")]
filters = sum([output_filters[1:][i] for i in layers])
modules.add_module(f"route_{module_i}", EmptyLayer())
elif module_def["type"] == "shortcut": # 对应residual的结构 方式是add
filters = output_filters[1:][int(module_def["from"])]
modules.add_module(f"shortcut_{module_i}", EmptyLayer())
route和shortcut对应的分别是tensor的拼接和残差结构。EmptyLayer()是一个空层,啥也不做,具体的操作都是在Darknet的forward()函数里才去执行具体的操作。
filters = sum([output_filters[1:][i] for i in layers])
filters = output_filters[1:][int(module_def["from"])]
filters都是在计算相应操作之后的channel数量。所以一个是sum所有的channel的concat,一个是channel保持不变的element-wise 加法。
elif module_def["type"] == "yolo":
anchor_idxs = [int(x) for x in module_def["mask"].split(",")]
# Extract anchors
anchors = [int(x) for x in module_def["anchors"].split(",")]
anchors = [(anchors[i], anchors[i + 1]) for i in range(0, len(anchors), 2)]
anchors = [anchors[i] for i in anchor_idxs]
num_classes = int(module_def["classes"])
img_size = int(hyperparams["height"])
# Define detection layer
yolo_layer = YOLOLayer(anchors, num_classes, img_size)
modules.add_module(f"yolo_{module_i}", yolo_layer)
yolo layer会加载YOLOLayer() module。在观察一下cfg文件里的配置信息:
[yolo]
mask = 0,1,2
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
classes=80
num=9
jitter=.3
ignore_thresh = .7
truth_thresh = 1
random=1
mask代表的是第几个anchor,比如对于这个yolo head就只采用(10,13)、(16,30)、(33,23)这三个anchor信息。我们都知道yolov3采用FPN结构作为输出的结果,拥有三个yolo head,每个head预先设置了3个不同大小的anchor,三个head分别负责大、中、小三类物体。更为具体的信息我们会在后面解析yolo layer源码的时候再分享。
5.Darknet的前向传播过程?
讲完create_modules()函数,我们再回到Darknet Class,剩余的__init__()里面的部分:
def __init__(self, config_path, img_size=416):
super(Darknet, self).__init__()
self.module_defs = parse_model_config(config_path) # 得到list[dict()]类型的model配置信息表
self.hyperparams, self.module_list = create_modules(self.module_defs)
self.yolo_layers = [layer[0] for layer in self.module_list if isinstance(layer[0], YOLOLayer)]
self.img_size = img_size
self.seen = 0
self.header_info = np.array([0, 0, 0, self.seen, 0], dtype=np.int32)
其中第三句:
self.yolo_layers = [layer[0] for layer in self.module_list if isinstance(layer[0], YOLOLayer)]
self.module_list对应的是一个nn.ModuleList(),layer对应的是一个nn.Sequential(),layer(0)对应的是nn.Sequential()里面的第一个module。
下面来看下forward()部分:
def forward(self, x, targets=None):
img_dim = x.shape[2] # 图像的尺寸
loss = 0
layer_outputs, yolo_outputs = [], []
for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):
if module_def["type"] in ["convolutional", "upsample", "maxpool"]:
x = module(x)
elif module_def["type"] == "route":
# torch.cat 对单个tensor相当于保持原样
x = torch.cat([layer_outputs[int(layer_i)] for layer_i in module_def["layers"].split(",")], 1)
elif module_def["type"] == "shortcut":
layer_i = int(module_def["from"])
x = layer_outputs[-1] + layer_outputs[layer_i]
elif module_def["type"] == "yolo":
x, layer_loss = module[0](x, targets, img_dim)
loss += layer_loss
yolo_outputs.append(x)
layer_outputs.append(x)
yolo_outputs = to_cpu(torch.cat(yolo_outputs, 1))
return yolo_outputs if targets is None else (loss, yolo_outputs)
如果是conv、upsample、maxpool就直接执行;如果是route,就根据从cfg拿到的layer编号进行concat;如果是yolo,对应着输出就进行loss的计算。
layer_outputs.append(x)
这里每一层(对应一个create_modules()函数的nn.Sequential()),记录每一层的输出,可以方便的进行route和residual,这种写法是很经典的。
小结
至此,我们讲完了models.py里面的第一部分,涉及模型的构建。下面一篇我们讲重点分析YOLO layer的内容。
谢谢阅读!
下一篇传送门:
yolov3深度剖析+源码debug级讲解(二)