知识回顾
并发工具类我们已经讲了很多,这些工具类的「目标」是让我们只关注任务本身,并且忽视线程间合作细节,简化了并发编程难度的同时,也增加了很多安全性。工具类的对使用者的「目标」虽然一致,但每一个工具类本身都有它独特的应用场景,比如:
- 我会手动创建线程,为什么要使用线程池? 介绍了使用线程池管理线程将一个大任务分解成多个子任务来简单执行,借助 不会用Java Future,我怀疑你泡茶没我快, 又是超长图文!! 的 Future 特性获取子任务执行结果——二者结合使用就可以处理简单的并行任务
- 搞定 CompletableFuture,并发异步编程和编写串行程序还有什么区别? 借助 CompletableFuture 大大降低了异步编程的难度——使用串行的思维对任务进行编排执行(AND 或 OR 聚合)
- 既生 ExecutorService, 何生 CompletionService? 由于任务完成时间有先后,为避免等待阻塞——CompletionService 是批量并行任务的最佳选择
将上面三种通用场景形象化展示一下:

结合上图相信你的脑海里已经浮现出这几个工具类的具体实现方式,感觉这已经涵盖了所有的并发场景。

TYTS,以上这些方式的子线程接到任务后不会再继续拆分成「子子」任务,也就是说,子线程即便接到很大或很复杂的任务也得硬着头皮努力执行完,很显然这个大任务是问题关键
如果能把大任务拆分成更小的子问题,直到子问题简单到可以直接求解就好了,这就是分治的思想
分治思想
在计算机科学中,分治法是一种很重要的算法。字面上的解释是「分而治之」,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解就变成了子问题解的合并。
这个技巧是很多高效算法的基础,如排序算法 (快速排序,归并排序),傅立叶变换 (快速傅立叶变换)……,如果你是搞大数据的,MapReduce 就是分支思想的典型,如果你想更详细的理解分治相关的算法,请参考这篇一文图解分治算法和思想
结合上面的描述,相信你脑海中已经构建出来分治的模型了:

那所有的大任务都能用分治算法来解决吗?很显然不是的
分治法适用的情况
总体来说,分治法所能解决的问题一般具有以下几个特征:
- 该问题的规模缩小到一定的程度就可以容易地解决
- 该问题可以分解为若干个规模较小的相同问题,即该问题具有最优子结构性质。
- 利用该问题分解出的子问题的解可以合并为该问题的解;
- 该问题所分解出的各个子问题是相互独立的,即子问题之间不包含公共的子子问题
了解了分治算法的核心思想,我们就来看看 Java 是如何利用分治思想拆分与合并任务的吧
ForkJoin
有子任务,自然要用到多线程。我们很早之前说过,执行子任务的线程不允许单独创建,要用线程池管理。秉承相同设计理念,再结合分治算法, ForkJoin 框架中就出现了 ForkJoinPool 和 ForkJoinTask。正所谓:
天对地,雨对风。大陆对长空。山花对海树,赤曰对苍穹
套用已有知识,简单理解就是这样滴:

我们之前说过无数次,JDK 不会重复造轮子,这里谈及相似是为了让大家有个简单的直观印象,内里肯定有所差别,我们先大致看一下这两个类:
ForkJoinTask
又是这个男人,Doug Lea,怎么就那么牛(破音)
/**
* Abstract base class for tasks that run within a {@link ForkJoinPool}.
* A {@code ForkJoinTask} is a thread-like entity that is much
* lighter weight than a normal thread. Huge numbers of tasks and
* subtasks may be hosted by a small number of actual threads in a
* ForkJoinPool, at the price of some usage limitations.
*
* @since 1.7
* @author Doug Lea
*/
public abstract class ForkJoinTask implements Future, Serializable 可以看到 ForkJoinTask 实现了 Future 接口(那就是具有 Future 接口的特性),同样如其名,fork() 和 join() 自然是它的两个核心方法
fork(): 异步执行一个子任务(上面说的拆分)join(): 阻塞当前线程等待子任务的执行结果(上面说的合并)
另外,从上面代码中可以看出,ForkJoinTask 是一个抽象类,在分治模型中,它还有两个抽象子类 RecursiveAction 和 RecursiveTask

那这两个子抽象类有什么差别呢?如果你打开 IDE,你应该一眼就能看出差别,so easy

public abstract class RecursiveAction extends ForkJoinTask{
...
/**
* The main computation performed by this task.
*/
protected abstract void compute();
...
}
public abstract class RecursiveTask extends ForkJoinTask{
...
protected abstract void compute();
...
} 两个类里面都定义了一个抽象方法 compute() ,需要子类重写实现具体逻辑
那子类要遵循什么逻辑重写这个方法呢?
遵循分治思想,重写的逻辑很简单,就是回答三个问题:
- 什么时候进一步拆分任务?
- 什么时候满足最小可执行任务,即不再进行拆分?
- 什么时候汇总子任务结果
用「伪代码」再翻译一下上面这段话,大概就是这样滴:
if(任务小到不用继续拆分){
直接计算得到结果
}else{
拆分子任务
调用子任务的fork()进行计算
调用子任务的join()合并计算结果
}(作为程序员,如果你写过递归运算,这个逻辑理解起来是非常简单的)
介绍到这里,就可以用 ForkJoin 干些事情了——经典 Fibonacci 计算就可以用分治思想(不信,你逐条按照上面分治算法适用情况自问自答一下?),直接借用官方 Docs (注意看 compute 方法),额外添加个 main 方法来看一下:
@Slf4j
public class ForkJoinDemo {
public static void main(String[] args) {
int n = 20;
// 为了追踪子线程名称,需要重写 ForkJoinWorkerThreadFactory 的方法
final ForkJoinPool.ForkJoinWorkerThreadFactory factory = pool -> {
final ForkJoinWorkerThread worker = ForkJoinPool.defaultForkJoinWorkerThreadFactory.newThread(pool);
worker.setName("my-thread" + worker.getPoolIndex());
return worker;
};
//创建分治任务线程池,可以追踪到线程名称
ForkJoinPool forkJoinPool = new ForkJoinPool(4, factory, null, false);
// 快速创建 ForkJoinPool 方法
// ForkJoinPool forkJoinPool = new ForkJoinPool(4);
//创建分治任务
Fibonacci fibonacci = new Fibonacci(n);
//调用 invoke 方法启动分治任务
Integer result = forkJoinPool.invoke(fibonacci);
log.info("Fibonacci {} 的结果是 {}", n, result);
}
}
@Slf4j
class Fibonacci extends RecursiveTask {
final int n;
Fibonacci(int n) {
this.n = n;
}
@Override
public Integer compute() {
//和递归类似,定义可计算的最小单元
if (n <= 1) {
return n;
}
// 想查看子线程名称输出的可以打开下面注释
//log.info(Thread.currentThread().getName());
Fibonacci f1 = new Fibonacci(n - 1);
// 拆分成子任务
f1.fork();
Fibonacci f2 = new Fibonacci(n - 2);
// f1.join 等待子任务执行结果
return f2.compute() + f1.join();
}
} 执行结果如下:

进展到这里,相信基本的使用就已经搞定了,上面代码中使用了 ForkJoinPool,那问题来了:
池化既然是一类思想,Java 已经有了ThreadPoolExecutor,为什么又要搞出个ForkJoinPool呢?

借助下面这张图,先来回忆一下 ThreadPoolExecutor 的实现原理(详情请看为什么要使用线程池):

一眼就能看出来这是典型的生产者/消费者模式,消费者线程都从一个共享的 Task Queue 中消费提交的任务。ThreadPoolExecutor 简单的并行操作主要是为了执行时间不确定的任务(I/O 或定时任务等)
JDK 重复造轮子是不可能的,分治思想其实也可以理解成一种父子任务依赖的关系,当依赖层级非常深,用 ThreadPoolExecutor 来处理这种关系很显然是不太现实的,所以 ForkJoinPool 作为功能补充就出现了
ForkJoinPool
任务拆分后有依赖关系,还得减少线程之间的竞争,那就让线程执行属于自己的 task 就可以了呗,所以较 ThreadPoolExecutor 的单个 TaskQueue 的形式,ForkJoinPool 是多个 TaskQueue的形式,简单用图来表示,就是这样滴:

有多个任务队列,所以在 ForkJoinPool 中就有一个数组形式的成员变量 WorkQueue[]。那问题又来了
任务队列有多个,提交的任务放到哪个队列中呢?(上图中的
Router Rule 部分)
这就需要一套路由规则,从上面的代码 Demo 中可以理解,提交的任务主要有两种:
- 有外部直接提交的(submission task)
- 也有任务自己 fork 出来的(worker task)
为了进一步区分这两种 task,Doug Lea 就设计一个简单的路由规则:
- 将
submission task放到 WorkQueue 数组的「偶数」下标中 - 将
worker task放在 WorkQueue 的「奇数」下标中,并且只有奇数下标才有线程( worker )与之相对
应局部丰富一下上图就是这样滴:

每个任务执行时间都是不一样的(当然是在 CPU 眼里),执行快的线程的工作队列的任务就可能是空的,为了最大化利用 CPU 资源,就允许空闲线程拿取其它任务队列中的内容,这个过程就叫做 work-stealing (工作窃取)
当前线程要执行一个任务,其他线程还有可能过来窃取任务,这就会产生竞争,为了减少竞争,WorkQueue 就设计成了一个双端队列:
- 支持 LIFO(last-in-first-out) 的push(放)和pop(拿)操作——操作 top 端
- 支持 FIFO (first-in-first-out) 的 poll (拿)操作——操作 base 端
线程(worker)操作自己的 WorkQueue 默认是 LIFO 操作(可选FIFO),当线程(worker)尝试窃取其他 WorkQueue 里的任务时,这个时候执行的是FIFO操作,即从 base 端窃取,用图丰富一下就是这样滴:

这样的好处非常明显了:
- LIFO 操作只有对应的 worker 才能执行,push和pop不需要考虑并发
- 拆分时,越大的任务越在WorkQueue的base端,尽早分解,能够尽快进入计算
从 WorkQueue 的成员变量的修饰符中也能看出一二了(base 有 volatile 修饰,而 top 却没有):
volatile int base; // index of next slot for poll
int top; // index of next slot for push到这里,相信你已经了解 ForkJoinPool 的基本实现原理了,但也会伴随着很多疑问(这都是怎么实现的?),比如:
- 有竞争就需要锁,ForkJoinPool 是如何控制状态的呢?
- ForkJoinPool 的线程数是怎么控制的呢?
- 上面说的路由规则的具体逻辑是什么呢?
- ......
保留住这些问题,一点点看源码来了解一下吧:

源码分析(JDK 1.8)
ForkJoinPool 的源码涉及到大量的位运算,这里会把核心部分说清楚,想要理解的更深入,还需要大家自己一点点追踪查看
结合上面的铺垫,你应该知道 ForkJoinPool 里有三个重要的角色:
- ForkJoinWorkerThread(继承 Thread):就是我们上面说的线程(Worker)
- WorkQueue:双向的任务队列
- ForkJoinTask:Worker 执行的对象
源码分析的整个流程也是围绕这几个类的方法来说明,但在了解这三个角色之前,我们需要先了解 ForkJoinPool 都为这三个角色铺垫了哪些内容
故事就得从 ForkJoinPool 的构造方法说起
ForkJoinPool 构造方法
public ForkJoinPool() {
this(Math.min(MAX_CAP, Runtime.getRuntime().availableProcessors()),
defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism) {
this(parallelism, defaultForkJoinWorkerThreadFactory, null, false);
}
public ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
boolean asyncMode) {
this(checkParallelism(parallelism),
checkFactory(factory),
handler,
asyncMode ? FIFO_QUEUE : LIFO_QUEUE,
"ForkJoinPool-" + nextPoolId() + "-worker-");
checkPermission();
}除了以上三个构造方法之外,在 JDK1.8 中还增加了另外一种初始化 ForkJoinPool 对象的方式(QQ:这是什么设计模式?):
static final ForkJoinPool common;
/**
* @return the common pool instance
* @since 1.8
*/
public static ForkJoinPool commonPool() {
// assert common != null : "static init error";
return common;
}Common 是在静态块里面初始化的(只会被执行一次):
common = java.security.AccessController.doPrivileged
(new java.security.PrivilegedAction() {
public ForkJoinPool run() { return makeCommonPool(); }});
private static ForkJoinPool makeCommonPool() {
int parallelism = -1;
... 其他默认初始化内容
if (parallelism < 0 && // default 1 less than #cores
(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)
parallelism = 1;
if (parallelism > MAX_CAP)
parallelism = MAX_CAP;
// 执行上面的构造方法
return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,
"ForkJoinPool.commonPool-worker-");
} 因为这是一个单例通用的 ForkJoinPool,所以切记:
如果使用通用 ForkJoinPool,最好只做 CPU 密集型的计算操作,不要有不确定性的 I/O 内容在任务里面,以防拖垮整体
上面所有的构造方法最后都会调用这个私有方法:
private ForkJoinPool(int parallelism,
ForkJoinWorkerThreadFactory factory,
UncaughtExceptionHandler handler,
int mode,
String workerNamePrefix) {
this.workerNamePrefix = workerNamePrefix;
this.factory = factory;
this.ueh = handler;
this.config = (parallelism & SMASK) | mode;
long np = (long)(-parallelism); // offset ctl counts
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);
} 参数有点多,在这里解释一下每个参数的含义:
| 序号 | 参数名 | 描述/解释 |
|---|---|---|
| 1 | parallelism | 并行度,这并不是定义的线程数,具体线程数,以及 WorkQueue 的长度等都是根据这个并行度来计算的,通过上面 makeCommonPool 方法可以知道,parallelism 默认值是 CPU 核心线程数减 1 |
| 2 | factory | 很常见了,创建 ForkJoinWorkerThread 的工厂接口 |
| 3 | handler | 每个线程的异常处理器 |
| 4 | mode | 上面说的 WorkQueue 的模式,LIFO/FIFO; |
| 5 | workerNamePrefix | ForkJoinWorkerThread的前缀名称 |
| 6 | ctl | 线程池的核心控制线程字段 |
在构造方法中就已经有位运算了,太难了:

想知道 ForkJoinPool 的成员变量 config 要表达的意思,就要仔细拆开来看
static final int SMASK = 0xffff; // short bits == max index
this.config = (parallelism & SMASK) | mode;parallelism & SMASK 其实就是要保证并行度的值不能大于 SMASK,上面所有的构造方法在传入 parallelism 的时候都会调用 checkParallelism 来检查合法性:
static final int MAX_CAP = 0x7fff; // max #workers - 1
private static int checkParallelism(int parallelism) {
if (parallelism <= 0 || parallelism > MAX_CAP)
throw new IllegalArgumentException();
return parallelism;
}可以看到 parallelism 的最大值就是 MAX_CAP 了,0x7fff 肯定小于0xffff。所以 config 的值其实就是:
this.config = parallelism | mode;这里假设 parallelism 就是 MAX_CAP , 然后与 mode 进行或运算,其中 mode 有三种:
- LIFO_QUEUE
- FIFO_QUEUE
- SHARED_QUEUE
下面以 LIFO_QUEUE 和 FIFO_QUEUE 举例说明:
// Mode bits for ForkJoinPool.config and WorkQueue.config
static final int MODE_MASK = 0xffff << 16; // top half of int
static final int LIFO_QUEUE = 0;
static final int FIFO_QUEUE = 1 << 16;
static final int SHARED_QUEUE = 1 << 31; // must be negative
所以 parallelism | mode 根据 mode 的不同会产生两种结果,但是会得到一个确认的信息:
config 的第 17 位表示模式,低 15 位表示并行度 parallelism
当我们需要从 config 中获取模式 mode 时候,只需要用mode 掩码 (MODE_MASK)和 config 做与运算就可以了

所以一张图概括 config 就是:


long np = (long)(-parallelism); // offset ctl counts上面这段代码就是将并行度 parallelism 补码转换为 long 型,以 MAX_CAP 作为并行度为例,np 的值就是

这个 np 的值,就会用作 ForkJoinPool 成员变量 ctl 的计算:
// Active counts 活跃线程数
private static final int AC_SHIFT = 48;
private static final long AC_UNIT = 0x0001L << AC_SHIFT;
private static final long AC_MASK = 0xffffL << AC_SHIFT;
// Total counts 总线程数
private static final int TC_SHIFT = 32;
private static final long TC_UNIT = 0x0001L << TC_SHIFT;
private static final long TC_MASK = 0xffffL << TC_SHIFT;
private static final long ADD_WORKER = 0x0001L << (TC_SHIFT + 15); // sign
// 计算 ctl
this.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);np << AC_SHIFT即 np 向左移动 48 位,这样原来的低 16 位变成了高 16 位,再用 AC 掩码(AC_MASK) 做与运算,也就是说 ctl 的 49 ~ 64 位表示活跃线程数np << TC_SHIFT即 np 向左移动 32 位,这样原来的低 16 位变成了 33 ~ 48 位,再用 TC 掩码做与运算,也就是说 ctl 的 33 ~ 48 位表示总线程数
最后二者再进行或运算,如果并行度还是 MAX_CAP ,那 ctl 的最后结果就是:

到这里,我们才阅读完一个构造函数的内容,从最终的结论可以看出,初始化后 AC = TC,并且 ctl 是一个小于零的数,ctl 是 64 位的 long 类型,低 32 位是如何构造的并没有在构造函数中体现出来,但注释给了明确的说明:
/*
* Bits and masks for field ctl, packed with 4 16 bit subfields:
* AC: Number of active running workers minus target parallelism
* TC: Number of total workers minus target parallelism
* SS: version count and status of top waiting thread
* ID: poolIndex of top of Treiber stack of waiters
*
* When convenient, we can extract the lower 32 stack top bits
* (including version bits) as sp=(int)ctl. The offsets of counts
* by the target parallelism and the positionings of fields makes
* it possible to perform the most common checks via sign tests of
* fields: When ac is negative, there are not enough active
* workers, when tc is negative, there are not enough total
* workers. When sp is non-zero, there are waiting workers. To
* deal with possibly negative fields, we use casts in and out of
* "short" and/or signed shifts to maintain signedness.
*
* Because it occupies uppermost bits, we can add one active count
* using getAndAddLong of AC_UNIT, rather than CAS, when returning
* from a blocked join. Other updates entail multiple subfields
* and masking, requiring CAS.
*/这段注释主要说明了低 32 位的作用(后面会从源码中体现出来,这里先有个印象会对后面源码阅读有帮助),按注释含义先完善一下 ctl 的值:
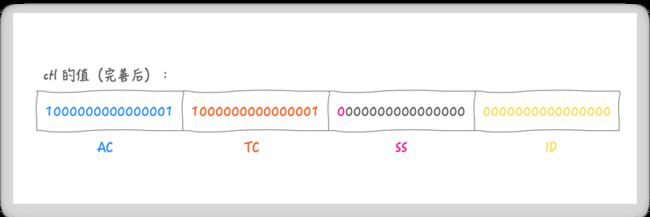
- SS:栈顶工作线程状态和版本数(每一个线程在挂起时都会持有前一个等待线程所在工作队列的索引,由此构成一个等待的工作线程栈,栈顶是最新等待的线程),第一位表示状态
1:不活动(inactive);0:活动(active),后15表示版本号,防止 ABA 问题 - ID: 栈顶工作线程所在工作队列的索引
注释中还说,另 sp=(int)ctl,即获取 64 位 ctl 的低 32 位(SS | ID),因为低 32 位都是创建出线程之后才会存在的值,所以推断出,如果 sp != 0, 就存在等待的工作线程,唤醒使用就行,不用创建新的线程。这样就通过 ctl 可以获取到有关线程所需要的一切信息了


除了构造方法所构建的成员变量,ForkJoinPool 还有一个非常重要的成员变量 runState,和你之前了解的知识一样,线程池也需要状态来进行管理
volatile int runState; // lockable status
// runState bits: SHUTDOWN must be negative, others arbitrary powers of two
private static final int RSLOCK = 1; //线程池被锁定
private static final int RSIGNAL = 1 << 1; //线程池有线程需要唤醒
private static final int STARTED = 1 << 2; //线程池已经初始化
private static final int STOP = 1 << 29; //线程池停止
private static final int TERMINATED = 1 << 30; //线程池终止
private static final int SHUTDOWN = 1 << 31; //线程池关闭runState 有上面 6 种状态切换,按注释所言,只有 SHUTDOWN 状态是负数,其他都是整数,在并发环境更改状态必然要用到锁,ForkJoinPool 对线程池加锁和解锁分别由 lockRunState 和 unlockRunState 来实现 (这两个方法可以暂且不用深入理解,可以暂时跳过,只需要理解它们是帮助安全更改线程池状态的锁即可)
不深入了解可以,但是我不能不写啊...... 你待会不是得回看吗?

lockRunState
/**
* Acquires the runState lock; returns current (locked) runState.
*/
// 从方法注释中看到,该方法一定会返回 locked 的 runState,也就是说一定会加锁成功
private int lockRunState() {
int rs;
return ((((rs = runState) & RSLOCK) != 0 ||
!U.compareAndSwapInt(this, RUNSTATE, rs, rs |= RSLOCK)) ?
awaitRunStateLock() : rs);
}- 因为 RSLOCK = 1,如果 runState & RSLOCK == 0,则说明目前没有加锁,进入
或运算的下半段 CAS - 先通过 CAS 尝试加锁,尝试成功直接返回,尝试失败则要调用
awaitRunStateLock方法
/**
* Spins and/or blocks until runstate lock is available. See
* above for explanation.
*/
private int awaitRunStateLock() {
Object lock;
boolean wasInterrupted = false;
for (int spins = SPINS, r = 0, rs, ns;;) {
//判断是否加锁(==0表示未加锁)
if (((rs = runState) & RSLOCK) == 0) {
// 通过CAS加锁
if (U.compareAndSwapInt(this, RUNSTATE, rs, ns = rs | RSLOCK)) {
if (wasInterrupted) {
try {
// 重置线程终端标记
Thread.currentThread().interrupt();
} catch (SecurityException ignore) {
// 这里竟然 catch 了个寂寞
}
}
// 加锁成功返回最新的 runState,for 循环的唯一正常出口
return ns;
}
}
else if (r == 0)
r = ThreadLocalRandom.nextSecondarySeed();
else if (spins > 0) {
r ^= r << 6; r ^= r >>> 21; r ^= r << 7; // xorshift
if (r >= 0)
--spins;
}
// Flag1 如果是其他线程正在初始化占用锁,则调用 yield 方法让出 CPU,让其快速初始化
else if ((rs & STARTED) == 0 || (lock = stealCounter) == null)
Thread.yield(); // initialization race
// Flag2 如果其它线程持有锁,并且线程池已经初始化,则将唤醒位标记为1
else if (U.compareAndSwapInt(this, RUNSTATE, rs, rs | RSIGNAL)) {
// 进入互斥锁
synchronized (lock) {
// 再次判断,如果等于0,说明进入互斥锁前刚好有线程进行了唤醒,就不用等待,直接进行唤醒操作即可,否则就进入等待
if ((runState & RSIGNAL) != 0) {
try {
lock.wait();
} catch (InterruptedException ie) {
if (!(Thread.currentThread() instanceof
ForkJoinWorkerThread))
wasInterrupted = true;
}
}
else
lock.notifyAll();
}
}
}
}上面代码 33 ~ 34 (Flag1)行以及 36 ~ 50 (Flag2) 行,如果你没看后续代码,现在来理解是有些困难的,我这里先提前说明一下:
Flag1: 当完整的初始化 ForkJoinPool 时,直接利用了 stealCounter 这个原子变量,因为初始化时(调用 externalSubmit 时),才会对 StealCounter 赋值。所以,这里的逻辑是,当状态不是 STARTED 或者 stealCounter 为空,让出线程等待,也就是说,别的线程还没初始化完全,让其继续占用锁初始化即可
Flag2: 我们在讲等待/通知模型时就说,不要让无限自旋尝试,如果资源不满足就等待,如果资源满足了就通知,所以,如果 (runState & RSIGNAL) == 0 成立,说明有线程需要唤醒,直接唤醒就好,否则也别浪费资源,主动等待一会
当阅读到这的代码时,马上就抛出来两个问题:
Q1: 既然是加锁,为什么不用已有的轮子 ReentrantLock 呢?
PS:如果你读过并发系列 Java AQS队列同步器以及ReentrantLock的应用 ,你会知道 ReentrantLock 是用一个完整字段 state 来控制同步状态。但这里在竞争锁的时候还会判断线程池的状态,如果是初始化状态主动 yield 放弃 CPU 来减少竞争;另外,用一个完整的 runState 不同位来表示状态也体现出更细的粒度吧
Q2: synchronized 大法虽好,但是我们都知道这是比较重量级的锁,为什么还在这里应用了呢?
PS: 首先 synchronized 经过不断优化,没有它刚诞生时那么重,另外按照 Flag 2 的代码含义,进入 synchronized 同步块的概率还是很低的,可以用最简单的方式稳稳兜底(奥卡姆剃刀了原理?)
有加锁自然要解锁,向下看 unlockRunState
unlockRunState
解锁的逻辑相对简单多了,总体目标是清除锁标记位。如果顺利将状态修改为目标状态,自然解锁成功;否则表示有别的线程进入了wait,需要调用notifyAll唤醒,重新尝试竞争
/**
* Unlocks and sets runState to newRunState.
*
* @param oldRunState a value returned from lockRunState
* @param newRunState the next value (must have lock bit clear).
*/
private void unlockRunState(int oldRunState, int newRunState) {
if (!U.compareAndSwapInt(this, RUNSTATE, oldRunState, newRunState)) {
Object lock = stealCounter;
runState = newRunState; // clears RSIGNAL bit
if (lock != null)
synchronized (lock) { lock.notifyAll(); }
}
}这两个方法贯穿着后续代码分析的始终,多注意 unlockRunState 的入参即可,另外你也看到了通知都是用的 notifyAll,而不是 notify,这个问题我们之前重点说明过,你还记得为什么吗?如果不记得,打开并发编程之等待通知机制 回忆一下吧

第一层知识铺垫已经差不多了,前进
invoke/submit/execute
回到本文最开始带有 main 函数的 demo,我们向 ForkJoinPool 提交任务调用的是 invoke 方法, 其实 ForkJoinPool 还支持 submit 和 execute 两种方式来提交任务。并发的玩法非常类似,这三类方法的作业也很好区分:
- invoke:提交任务,并等待返回执行结果
- submit:提交并立刻返回任务,ForkJoinTask实现了Future,可以充分利用 Future 的特性
- execute:只提交任务
在这三大类基础上又重载了几个更细粒度的方法,这里不一一列举:
public T invoke(ForkJoinTask task) {
if (task == null)
throw new NullPointerException();
externalPush(task);
return task.join();
}
public ForkJoinTask submit(ForkJoinTask task) {
if (task == null)
throw new NullPointerException();
externalPush(task);
return task;
}
public void execute(ForkJoinTask task) {
if (task == null)
throw new NullPointerException();
externalPush(task);
} 相信你已经发现了,提交任务的方法都会调用 externalPush(task) 这个用法,源码的主角终于要登场了

但是......
如果你看 externalPush 代码,第一行就是声明一个 WorkQueue 数组变量,为了后续流程更加丝滑,咱还得铺垫一点 WorkQueue 的知识(又要铺垫)
WorkQueue
一看这么多成员变量,还是很慌的,不过,我们只需要把我几个主要的就足够了

//初始队列容量
static final int INITIAL_QUEUE_CAPACITY = 1 << 13;
//最大队列容量
static final int MAXIMUM_QUEUE_CAPACITY = 1 << 26; // 64M
// Instance fields
volatile int scanState; // versioned, <0: inactive; odd:scanning
int stackPred; // pool stack (ctl) predecessor 前任池(WorkQueue[])索引,由此构成一个栈
int nsteals; // number of steals 偷取的任务个数
int hint; // randomization and stealer index hint 记录偷取者的索引,方便后面顺藤摸瓜
int config; // pool index and mode
volatile int qlock; // 1: locked, < 0: terminate; else 0
volatile int base; // index of next slot for poll
int top; // index of next slot for push
ForkJoinTask[] array; // the elements (initially unallocated) 任务数组
final ForkJoinPool pool; // the containing pool (may be null)
final ForkJoinWorkerThread owner; // owning thread or null if shared 当前工作队列的工作线程,共享模式下为null
volatile Thread parker; // == owner during call to park; else null 调用park阻塞期间为owner,其他情况为null
volatile ForkJoinTask currentJoin; // task being joined in awaitJoin 记录当前join来的任务
volatile ForkJoinTask currentSteal; // mainly used by helpStealer 记录从其他工作队列偷取过来的任务我们上面说了,WorkQueue 是一个双端队列,线程池有 runState,WorkQueue 有 scanState
- 小于零:inactive (未激活状态)
- 奇数:scanning (扫描状态)
- 偶数:running (运行状态)
操作线程池需要锁,操作队列也是需要锁的,qlock 就派上用场了
- 1: 锁定
- 0:未锁定
- 小于零:终止状态
WorkQueue 中也有个 config,但是和 ForkJoinPool 中的是不一样的,WorkQueue 中的config 记录了该 WorkQueue 在 WorkQueue[] 数组的下标以及 mode
其他字段的含义我们就写在代码注释中吧,主角重新登场,这次是真的
externalPush
文章前面说过,task 会细分成 submission task 和 worker task,worker task 是 fork 出来的,那从这个入口进入的,自然也就是 submission task 了,也就是说:
- 通过
invoke()|submit()|execute()等方法提交的 task, 是submission task,会放到 WorkQueue 数组的偶数索引位置- 调用
fork()方法生成出的任务,叫 worker task,会放到 WorkQueue 数组的奇数索引位置
该方法上的注释也写的很清楚,具体请参考代码注释
/**
* Tries to add the given task to a submission queue at
* submitter's current queue. Only the (vastly) most common path
* is directly handled in this method, while screening for need
* for externalSubmit.
*
* @param task the task. Caller must ensure non-null.
*/
final void externalPush(ForkJoinTask task) {
WorkQueue[] ws; WorkQueue q; int m;
//Flag1: 通过ThreadLocalRandom产生随机数,用于下面计算槽位索引
int r = ThreadLocalRandom.getProbe();
int rs = runState; //初始状态为0
//Flag2: 如果ws,即ForkJoinPool中的WorkQueue数组已经完成初始化,且根据随机数定位的index存在workQueue,且cas的方式加锁成功
if ((ws = workQueues) != null && (m = (ws.length - 1)) >= 0 &&
(q = ws[m & r & SQMASK]) != null && r != 0 && rs > 0 &&
//对WorkQueue操作加锁
U.compareAndSwapInt(q, QLOCK, 0, 1)) {
ForkJoinTask[] a; int am, n, s;
//WorkQueue中的任务数组不为空
if ((a = q.array) != null &&
(am = a.length - 1) > (n = (s = q.top) - q.base)) { //组长度大于任务个数,不需要扩容
int j = ((am & s) << ASHIFT) + ABASE; //WorkQueue中的任务数组不为空
U.putOrderedObject(a, j, task); //向Queue中放入任务
U.putOrderedInt(q, QTOP, s + 1);//top值加一
U.putIntVolatile(q, QLOCK, 0); //对WorkQueue操作解锁
//任务个数小于等于1,那么此槽位上的线程有可能等待,如果大家都没任务,可能都在等待,新任务来了,唤醒,起来干活了
if (n <= 1)
//唤醒可能存在等待的线程
signalWork(ws, q);
return;
}
//任务入队失败,前面加锁了,这里也要解锁
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
//Flag3: 不满足上述条件,也就是说上面的这些 WorkQueue[]等都不存在,就要通过这个方法一切从头开始创建
externalSubmit(task);
}上面加了三处 Flag,为了让大家更好的理解代码还是有必要做进一步说明的:
Flag1: ThreadLocalRandom 是 ThreadLocal 的衍生物,每个线程默认的 probe 是 0,当线程调用ThreadLocalRandom.current()时,会初始化 seed 和 probe,维护在线程内部,这里就知道是生成一个随机数就好,具体细节还是值得大家自行看一下
Flag2: 这里包含的信息还是非常多的
// 二进制为:0000 0000 0000 0000 0000 0000 0111 1110
static final int SQMASK = 0x007e; // max 64 (even) slots- m 的值代表 WorkQueue 数组的最大下表
- m & r 会保证随机数 r 大于 m 的部分不可用
- m & r & SQMASK 因为 SQMASK 最后一位是 0,最终的结果就会是偶数
- r != 0 说明当前线程已经初始化过一些内容
- rs > 0 说明 ForkJoinPool 的 runState 也已经被初始化过
Flag3: 看过 flag2 的描述,你也就很好理解 Flag 3 了,如果是第一次提交任务,必走 Flag 3 的 externalSubmit 方法
externalSubmit
这个方法很长,但没超过 80 行,具体请看方法注释
//初始化所需要的一切
private void externalSubmit(ForkJoinTask task) {
int r; // initialize caller's probe
//生成随机数
if ((r = ThreadLocalRandom.getProbe()) == 0) {
ThreadLocalRandom.localInit();
r = ThreadLocalRandom.getProbe();
}
for (;;) {
WorkQueue[] ws; WorkQueue q; int rs, m, k;
boolean move = false;
// 如果线程池的状态为终止状态,则帮助终止
if ((rs = runState) < 0) {
tryTerminate(false, false); // help terminate
throw new RejectedExecutionException();
}
//Flag1: 再判断一次状态是否为初始化,因为在lockRunState过程中有可能状态被别的线程更改了
else if ((rs & STARTED) == 0 || // initialize
((ws = workQueues) == null || (m = ws.length - 1) < 0)) {
int ns = 0;
//Flag1.1: 加锁
rs = lockRunState();
try {
if ((rs & STARTED) == 0) {
// 初始化stealcounter的值(任务窃取计数器,原子变量)
U.compareAndSwapObject(this, STEALCOUNTER, null,
new AtomicLong());
// create workQueues array with size a power of two
//取config的低16位(确切说是低15位),获取并行度
int p = config & SMASK; // ensure at least 2 slots
//Flag1.2: 如果你看过HashMap 的源码,这个就很好理解了,获取2次幂大小
int n = (p > 1) ? p - 1 : 1;
n |= n >>> 1; n |= n >>> 2; n |= n >>> 4;
n |= n >>> 8; n |= n >>> 16; n = (n + 1) << 1;
//初始化 WorkQueue 数组
workQueues = new WorkQueue[n];
// 标记初始化完成
ns = STARTED;
}
} finally {
// 解锁
unlockRunState(rs, (rs & ~RSLOCK) | ns);
}
}
//Flag2 上面分析过,取偶数位槽位,将任务放进偶数槽位
else if ((q = ws[k = r & m & SQMASK]) != null) {
// 对 WorkQueue 加锁
if (q.qlock == 0 && U.compareAndSwapInt(q, QLOCK, 0, 1)) {
ForkJoinTask[] a = q.array;
int s = q.top;
// 初始化任务提交标识
boolean submitted = false; // initial submission or resizing
try { // locked version of push
//计算内存偏移量,放任务,更新top值
if ((a != null && a.length > s + 1 - q.base) ||
(a = q.growArray()) != null) {
int j = (((a.length - 1) & s) << ASHIFT) + ABASE;
U.putOrderedObject(a, j, task);
U.putOrderedInt(q, QTOP, s + 1);
//提交任务成功
submitted = true;
}
} finally {
//WorkQueue解锁
U.compareAndSwapInt(q, QLOCK, 1, 0);
}
// 任务提交成功了
if (submitted) {
//自然要唤醒可能存在等待的线程来处理任务了
signalWork(ws, q);
return;
}
}
//任务提交没成功,可以重新计算随机数,再走一次流程
move = true; // move on failure
}
//Flag3: 接Flag2,如果找到的槽位是空,则要初始化一个WorkQueue
else if (((rs = runState) & RSLOCK) == 0) { // create new queue
q = new WorkQueue(this, null);
// 设置工作队列的窃取线索值
q.hint = r;
// 如上面 WorkQueue 中config 的介绍,记录当前WorkQueue在WorkQueue[]数组中的值,和队列模式
q.config = k | SHARED_QUEUE;
// 初始化为 inactive 状态
q.scanState = INACTIVE;
//加锁
rs = lockRunState(); // publish index
if (rs > 0 && (ws = workQueues) != null &&
k < ws.length && ws[k] == null)
ws[k] = q; // else terminated
//解锁
unlockRunState(rs, rs & ~RSLOCK);
}
else
move = true; // move if busy
if (move)
r = ThreadLocalRandom.advanceProbe(r);
}
}Flag1.1 : 有个细节需要说一下,我们在 Java AQS队列同步器以及ReentrantLock的应用 时提到过使用锁的范式以及为什么要这样用,ForkJoinPool 这里同样遵循这种范式
Lock lock = new ReentrantLock();
lock.lock();
try{
...
}finally{
lock.unlock();
}Flag1.2: 简单描述这个过程,就是根据不同的并行度来初始化不同大小的 WorkQueue[]数组,数组大小要求是 2 的 n 次幂,所以给大家个表格直观理解一下并行度和队列容量的关系:
| 并行度p | 容量 |
|---|---|
| 1,2 | 4 |
| 3,4 | 8 |
| 5 ~ 8 | 16 |
| 9 ~ 16 | 32 |
Flag 1,2,3: 如果你理解了上面这个方法,很显然,第一次执行这个方法内部的逻辑顺序应该是 Flag1——> Flag3——>Flag2
externalSubmit 如果任务成功提交,就会调用 signalWork 方法了
signalWork
前面铺垫的知识要大规模派上用场(一大波僵尸来袭),are you ready?

如果 ForkJoinPool 的 ctl 成员变量的作用已经忘了,赶紧向上翻重新记忆一下
//常量值
static final int SS_SEQ = 1 << 16; // version count
final void signalWork(WorkQueue[] ws, WorkQueue q) {
long c; int sp, i; WorkQueue v; Thread p;
// ctl 小于零,说明活动的线程数 AC 不够
while ((c = ctl) < 0L) { // too few active
// 取ctl的低32位,如果为0,说明没有等待的线程
if ((sp = (int)c) == 0) { // no idle workers
// 取TC的高位,如果不等于0,则说明目前的工作着还没有达到并行度
if ((c & ADD_WORKER) != 0L) // too few workers
//添加 Worker,也就是说要创建线程了
tryAddWorker(c);
break;
}
//未开始或者已停止,直接跳出
if (ws == null) // unstarted/terminated
break;
//i=空闲线程栈顶端所属的工作队列索引
if (ws.length <= (i = sp & SMASK)) // terminated
break;
if ((v = ws[i]) == null) // terminating
break;
//程序执行到这里,说明有空闲线程,计算下一个scanState,增加了版本号,并且调整为 active 状态
int vs = (sp + SS_SEQ) & ~INACTIVE; // next scanState
int d = sp - v.scanState; // screen CAS
//计算下一个ctl的值,活动线程数 AC + 1,通过stackPred取得前一个WorkQueue的索引,重新设置回sp,行程最终的ctl值
long nc = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & v.stackPred);
//更新 ctl 的值
if (d == 0 && U.compareAndSwapLong(this, CTL, c, nc)) {
v.scanState = vs; // activate v
//如果有线程阻塞,则调用unpark唤醒即可
if ((p = v.parker) != null)
U.unpark(p);
break;
}
//没有任务,直接跳出
if (q != null && q.base == q.top) // no more work
break;
}
}假设程序刚开始执行,那么活动线程数以及总线程数肯定都没达到并行度要求,这时就会调用 tryAddWorker 方法了
tryAddWorker
tryAddWorker 的逻辑就非常简单了,因为是操作线程池,同样会用到 lockRunState/unlockRunState 的锁控制
private void tryAddWorker(long c) {
//初始化添加worker表识
boolean add = false;
do {
//因为要添加Worker,所以AC和TC都要加一
long nc = ((AC_MASK & (c + AC_UNIT)) |
(TC_MASK & (c + TC_UNIT)));
//ctl还没被改变
if (ctl == c) {
int rs, stop; // check if terminating
if ((stop = (rs = lockRunState()) & STOP) == 0)
//更新ctl 的值,
add = U.compareAndSwapLong(this, CTL, c, nc);
unlockRunState(rs, rs & ~RSLOCK);
if (stop != 0)
break;
//ctl值更新成功,开始真正的创建Worker
if (add) {
createWorker();
break;
}
}
// 重新获取ctl,并且没有达到最大线程数,并且没有空闲的线程
} while (((c = ctl) & ADD_WORKER) != 0L && (int)c == 0);
}一切顺利,就要调用 createWorker 方法来创建真正的 Worker 了,形势逐渐明朗
createWorker
介绍过了 WorkerQueue 和 ForkJoinTask,上文说的三个重要角色中的最后一个 ForkJoinWorkerThread 终于登场了
private boolean createWorker() {
ForkJoinWorkerThreadFactory fac = factory;
Throwable ex = null;
ForkJoinWorkerThread wt = null;
try {
//如果工厂已经存在了,就用factory来创建线程,会去注册线程,这里的this就是ForkJoinPool对象
if (fac != null && (wt = fac.newThread(this)) != null) {
//启动线程
wt.start();
return true;
}
} catch (Throwable rex) {
ex = rex;
}
//如果创建线程失败,就要逆向注销线程,包括前面对ctl等的操作
deregisterWorker(wt, ex);
return false;
}Worker 线程是如何与 WorkQueue 对应的,就藏在 fac.newThread(this) 这个方法里面,下面这点代码展示一下调用过程
public ForkJoinWorkerThread newThread(ForkJoinPool pool);
static final class DefaultForkJoinWorkerThreadFactory
implements ForkJoinWorkerThreadFactory {
public final ForkJoinWorkerThread newThread(ForkJoinPool pool) {
return new ForkJoinWorkerThread(pool);
}
}
protected ForkJoinWorkerThread(ForkJoinPool pool) {
// Use a placeholder until a useful name can be set in registerWorker
super("aForkJoinWorkerThread");
this.pool = pool;
this.workQueue = pool.registerWorker(this);
}很显然核心内容在 registerWorker 方法里面了
registerWorker
WorkQueue(ForkJoinPool pool, ForkJoinWorkerThread owner) {
this.pool = pool;
this.owner = owner;
// Place indices in the center of array (that is not yet allocated)
base = top = INITIAL_QUEUE_CAPACITY >>> 1;
}
final WorkQueue registerWorker(ForkJoinWorkerThread wt) {
UncaughtExceptionHandler handler;
//这里线程被设置为守护线程,因为,当只剩下守护线程时,JVM就会推出
wt.setDaemon(true); // configure thread
//填补处理异常的handler
if ((handler = ueh) != null)
wt.setUncaughtExceptionHandler(handler);
//创建一个WorkQueue,并且设置当前WorkQueue的owner是当前线程
WorkQueue w = new WorkQueue(this, wt);
int i = 0; // assign a pool index
//又用到了config的知识,提取出我们期望的WorkQueue模式
int mode = config & MODE_MASK;
//加锁
int rs = lockRunState();
try {
WorkQueue[] ws; int n; // skip if no array
//判断ForkJoinPool的WorkQueue[]都初始化完全
if ((ws = workQueues) != null && (n = ws.length) > 0) {
//一种魔数计算方式,用以减少冲突
int s = indexSeed += SEED_INCREMENT; // unlikely to collide
//假设WorkQueue的初始长度是16,那这里的m就是15,最终目的就是为了得到一个奇数
int m = n - 1;
//和得到偶数的计算方式一样,得到一个小于m的奇数i
i = ((s << 1) | 1) & m; // odd-numbered indices
//如果这个槽位不为空,说明已经被其他线程初始化过了,也就是有冲突,选取别的槽位
if (ws[i] != null) { // collision
int probes = 0; // step by approx half n
//步长加2,也就保证step还是奇数
int step = (n <= 4) ? 2 : ((n >>> 1) & EVENMASK) + 2;
//一直遍历,直到找到空槽位,如果都遍历了一遍,那就需要对WorkQueue[]扩容了
while (ws[i = (i + step) & m] != null) {
if (++probes >= n) {
workQueues = ws = Arrays.copyOf(ws, n <<= 1);
m = n - 1;
probes = 0;
}
}
}
//初始化一个随机数
w.hint = s; // use as random seed
//如文章前面所说,config记录索引值和模式
w.config = i | mode;
//扫描状态也记录为索引值,如文章前面所说,奇数表示为scanning状态
w.scanState = i; // publication fence
//把初始化好的WorkQueue放到ForkJoinPool的WorkQueue[]数组中
ws[i] = w;
}
} finally {
//解锁
unlockRunState(rs, rs & ~RSLOCK);
}
//设置worker的前缀名,用于业务区分
wt.setName(workerNamePrefix.concat(Integer.toString(i >>> 1)));
//返回当前线程创建的WorkQueue,回到上一层调用栈,也就将WorkQueue注册到ForkJoinWorkerThread里面了
return w;
}到这里线程是顺利创建成功了,可是如果线程没有创建成功,就需要 deregisterWorker来做善后工作了
deregisterWorker
deregisterWorker 方法接收刚刚创建的线程引用和异常作为参数,来做善后工作,将 registerWorker 相关工作撤销回来
final void deregisterWorker(ForkJoinWorkerThread wt, Throwable ex) {
WorkQueue w = null;
if (wt != null && (w = wt.workQueue) != null) {
WorkQueue[] ws; // remove index from array
//获取当前线程注册的索引值
int idx = w.config & SMASK;
//加锁
int rs = lockRunState();
//如果奇数槽位都不为空,则清空内容
if ((ws = workQueues) != null && ws.length > idx && ws[idx] == w)
ws[idx] = null;
//解锁
unlockRunState(rs, rs & ~RSLOCK);
}
long c; // decrement counts
//死循环式CAS更改ctl的值,将前面AC和TC加1的值再减1,ctl就在那里,不增不减
do {} while (!U.compareAndSwapLong
(this, CTL, c = ctl, ((AC_MASK & (c - AC_UNIT)) |
(TC_MASK & (c - TC_UNIT)) |
(SP_MASK & c))));
//清空WorkQueue,将其中的task取消掉
if (w != null) {
w.qlock = -1; // ensure set
w.transferStealCount(this);
w.cancelAll(); // cancel remaining tasks
}
//可能的替换操作
for (;;) { // possibly replace
WorkQueue[] ws; int m, sp;
//如果线程池终止了,那就跳出循环即可
if (tryTerminate(false, false) || w == null || w.array == null ||
(runState & STOP) != 0 || (ws = workQueues) == null ||
(m = ws.length - 1) < 0) // already terminating
break;
//当前线程创建失败,通过sp判断,如果还存在空闲线程,则调用tryRelease来唤醒这个线程,然后跳出
if ((sp = (int)(c = ctl)) != 0) { // wake up replacement
if (tryRelease(c, ws[sp & m], AC_UNIT))
break;
}
//如果没空闲线程,并且还没有达到满足并行度的条件,那就得再次尝试创建一个线程,弥补刚刚的失败
else if (ex != null && (c & ADD_WORKER) != 0L) {
tryAddWorker(c); // create replacement
break;
}
else // don't need replacement
break;
}
if (ex == null) // help clean on way out
//处理异常
ForkJoinTask.helpExpungeStaleExceptions();
else // rethrow
ForkJoinTask.rethrow(ex);
}总之 deregisterWorker 方法从线程池里注销线程,清空WorkQueue,同时更新ctl,最后做可能的替换,根据线程池的状态决定是否找一个自己的替代者:
- 有空闲线程,则唤醒一个
- 没有空闲线程,再次尝试创建一个新的工作线程
deregisterWorker 线程解释清楚了是为了帮助大家完整理解流程,但 registerWorker 成功后的流程还没走完,咱得继续,有了 Worker,那就调用 wt.start() 干活吧
run
ForkJoinWorkerThread 继承自Thread,调用start() 方法后,自然要调用自己重写的 run() 方法
public void run() {
if (workQueue.array == null) { // only run once
Throwable exception = null;
try {
onStart();
//Work开始工作,处理workQueue中的任务
pool.runWorker(workQueue);
} catch (Throwable ex) {
exception = ex;
} finally {
try {
onTermination(exception);
} catch (Throwable ex) {
if (exception == null)
exception = ex;
} finally {
pool.deregisterWorker(this, exception);
}
}
}
}方法的重点自然是进入到 runWorker
runWorker
runWorker 是很常规的三部曲操作:
- scan: 通过扫描获取任务
- runTask:执行扫描到的任务
- awaitWork:没任务进入等待
具体请看注释
final void runWorker(WorkQueue w) {
//初始化队列,并根据需要是否扩容为原来的2倍
w.growArray(); // allocate queue
int seed = w.hint; // initially holds randomization hint
int r = (seed == 0) ? 1 : seed; // avoid 0 for xorShift
//死循环更新偏移r,为扫描任务作准备
for (ForkJoinTask t;;) {
//扫描任务
if ((t = scan(w, r)) != null)
//扫描到就执行任务
w.runTask(t);
//没扫描到就等待,如果等也等不到任务,那就跳出循环别死等了
else if (!awaitWork(w, r))
break;
r ^= r << 13; r ^= r >>> 17; r ^= r << 5; // xorshift
}
}先来看 scan 方法
scan
ForkJoinPool 的任务窃取机制要来了,如何 steal 的,就藏在scan 方法中
private ForkJoinTask scan(WorkQueue w, int r) {
WorkQueue[] ws; int m;
//再次验证workQueue[]数组的初始化情况
if ((ws = workQueues) != null && (m = ws.length - 1) > 0 && w != null) {
//获取当前扫描状态
int ss = w.scanState; // initially non-negative
//又一个死循环,注意到出口位置就好
//和前面逻辑类似,随机一个起始位置,并赋值给k
for (int origin = r & m, k = origin, oldSum = 0, checkSum = 0;;) {
WorkQueue q; ForkJoinTask[] a; ForkJoinTask t;
int b, n; long c;
//如果k槽位不为空
if ((q = ws[k]) != null) {
//base-top小于零,并且任务q不为空
if ((n = (b = q.base) - q.top) < 0 &&
(a = q.array) != null) { // non-empty
//获取base的偏移量,赋值给i
long i = (((a.length - 1) & b) << ASHIFT) + ABASE;
//从base端获取任务,和前文的描述的steal搭配上了,是从base端steal
if ((t = ((ForkJoinTask)
U.getObjectVolatile(a, i))) != null &&
q.base == b) {
//是active状态
if (ss >= 0) {
//更新WorkQueue中数组i索引位置为空,并且更新base的值
if (U.compareAndSwapObject(a, i, t, null)) {
q.base = b + 1;
//n<-1,说明当前队列还有剩余任务,继续唤醒可能存在的其他线程
if (n < -1) // signal others
signalWork(ws, q);
//直接返回任务
return t;
}
}
else if (oldSum == 0 && // try to activate
w.scanState < 0)
tryRelease(c = ctl, ws[m & (int)c], AC_UNIT);
}
//如果获取任务失败,则准备换位置扫描
if (ss < 0) // refresh
ss = w.scanState;
r ^= r << 1; r ^= r >>> 3; r ^= r << 10;
origin = k = r & m; // move and rescan
oldSum = checkSum = 0;
continue;
}
checkSum += b;
}
//k一直在变,扫描到最后,如果等于origin,说明已经扫描了一圈还没扫描到任务
if ((k = (k + 1) & m) == origin) { // continue until stable
if ((ss >= 0 || (ss == (ss = w.scanState))) &&
oldSum == (oldSum = checkSum)) {
if (ss < 0 || w.qlock < 0) // already inactive
break;
//准备inactive当前工作队列
int ns = ss | INACTIVE; // try to inactivate
//活动线程数AC减1
long nc = ((SP_MASK & ns) |
(UC_MASK & ((c = ctl) - AC_UNIT)));
w.stackPred = (int)c; // hold prev stack top
U.putInt(w, QSCANSTATE, ns);
if (U.compareAndSwapLong(this, CTL, c, nc))
ss = ns;
else
w.scanState = ss; // back out
}
checkSum = 0;
}
}
}
return null;
}如果顺利扫描到任务,那就要调用 runTask 方法来真正的运行这个任务了
runTask
马上就接近真相了,steal 到任务了,就干点正事吧
final void runTask(ForkJoinTask task) {
if (task != null) {
scanState &= ~SCANNING; // mark as busy
//Flag1: 记录当前的任务是偷来的,至于如何执行task,是我们写在compute方法中的,我们一会看doExec() 方法
(currentSteal = task).doExec();
U.putOrderedObject(this, QCURRENTSTEAL, null); // release for GC
execLocalTasks();
ForkJoinWorkerThread thread = owner;
//累加偷来的数量,亲兄弟明算帐啊,虽然算完也没啥实际意义
if (++nsteals < 0) // collect on overflow
transferStealCount(pool);
//任务执行完后,就重新更新scanState为SCANNING
scanState |= SCANNING;
if (thread != null)
thread.afterTopLevelExec();
}
}Flag1: doExec 方法才是真正执行任务的关键,它是链接我们自定义 compute 方法的核心,来看 doExec 方法
doExec
形势一片大好,挺住,揭开 exec 的面纱,就看到本质了
//ForkJoinTask中的抽象方法,RecursiveTask 和 RecursiveAction 都重写了它
protected abstract boolean exec();
final int doExec() {
int s; boolean completed;
if ((s = status) >= 0) {
try {
completed = exec();
} catch (Throwable rex) {
return setExceptionalCompletion(rex);
}
if (completed)
s = setCompletion(NORMAL);
}
return s;
}
//RecursiveTask重写的内容,终于看到我们文章开头 demo 中的compute 了
protected final boolean exec() {
result = compute();
return true;
}到这里,我们已经看到本质了,绕了这么一大圈,终于和我们自己重写的compute方法联系到了一起,真是不容易,但是 runWorker 三部曲还差最后一曲 awaitWork 没谱,我们来看看
awaitWork
上面说的是 scan 到了任务,要是没有scan到任务,那就得将当前线程阻塞一下,具体标注在注释中,可以简单了解一下
private boolean awaitWork(WorkQueue w, int r) {
if (w == null || w.qlock < 0) // w is terminating
return false;
for (int pred = w.stackPred, spins = SPINS, ss;;) {
if ((ss = w.scanState) >= 0)
break;
else if (spins > 0) {
r ^= r << 6; r ^= r >>> 21; r ^= r << 7;
if (r >= 0 && --spins == 0) { // randomize spins
WorkQueue v; WorkQueue[] ws; int s, j; AtomicLong sc;
if (pred != 0 && (ws = workQueues) != null &&
(j = pred & SMASK) < ws.length &&
//前驱任务队列还在
(v = ws[j]) != null && // see if pred parking
//并且工作队列已经激活,说明任务来了了
(v.parker == null || v.scanState >= 0))
//继续自旋等一会,别返回false
spins = SPINS; // continue spinning
}
}
//自旋之后,再次检查工作队列是否终止,若是,退出扫描
else if (w.qlock < 0) // recheck after spins
return false;
else if (!Thread.interrupted()) {
long c, prevctl, parkTime, deadline;
int ac = (int)((c = ctl) >> AC_SHIFT) + (config & SMASK);
if ((ac <= 0 && tryTerminate(false, false)) ||
(runState & STOP) != 0) // pool terminating
return false;
if (ac <= 0 && ss == (int)c) { // is last waiter
prevctl = (UC_MASK & (c + AC_UNIT)) | (SP_MASK & pred);
int t = (short)(c >>> TC_SHIFT); // shrink excess spares
if (t > 2 && U.compareAndSwapLong(this, CTL, c, prevctl))
return false; // else use timed wait
parkTime = IDLE_TIMEOUT * ((t >= 0) ? 1 : 1 - t);
deadline = System.nanoTime() + parkTime - TIMEOUT_SLOP;
}
else
prevctl = parkTime = deadline = 0L;
Thread wt = Thread.currentThread();
U.putObject(wt, PARKBLOCKER, this); // emulate LockSupport
w.parker = wt;
if (w.scanState < 0 && ctl == c) // recheck before park
U.park(false, parkTime);
U.putOrderedObject(w, QPARKER, null);
U.putObject(wt, PARKBLOCKER, null);
if (w.scanState >= 0)
break;
if (parkTime != 0L && ctl == c &&
deadline - System.nanoTime() <= 0L &&
U.compareAndSwapLong(this, CTL, c, prevctl))
return false; // shrink pool
}
}
return true;
}到这里,ForkJoinPool 的完整流程算是有个基本了解了,但是我们前面讲的这些内容都是从 submission task 作为切入点的。刚刚聊到的 compute 方法,我们按照分治算法范式写了自己的逻辑,具体请回看文中开头的demo,很关键的一点是,我们在 compute 中调用了 fork 方法,这就给我们了解 worker task 的机会了,继续来看 fork 方法

fork
Fork 方法的逻辑很简单,如果当前线程是 ForkJoinWorkerThread 类型,也就是说已经通过上文注册的 Worker,那么直接调用 push 方法将 task 放到当前线程拥有的 WorkQueue 中,否则就再调用 externalPush 重走我们已上说的所有逻辑(你敢再走一遍吗?)
public final ForkJoinTask fork() {
Thread t;
if ((t = Thread.currentThread()) instanceof ForkJoinWorkerThread)
((ForkJoinWorkerThread)t).workQueue.push(this);
else
ForkJoinPool.common.externalPush(this);
return this;
}
//push 方法很简单,这里就不再过多解释了
final void push(ForkJoinTask task) {
ForkJoinTask[] a; ForkJoinPool p;
int b = base, s = top, n;
if ((a = array) != null) { // ignore if queue removed
int m = a.length - 1; // fenced write for task visibility
U.putOrderedObject(a, ((m & s) << ASHIFT) + ABASE, task);
U.putOrderedInt(this, QTOP, s + 1);
if ((n = s - b) <= 1) {
if ((p = pool) != null)
p.signalWork(p.workQueues, this);
}
else if (n >= m)
growArray();
}
} 有 fork 就有 join,继续看一下 join 方法()
join
join 的核心调用在 doJoin,但是看到这么多级联三元运算符,我慌了
public final V join() {
int s;
if ((s = doJoin() & DONE_MASK) != NORMAL)
reportException(s);
return getRawResult();
}
private int doJoin() {
int s; Thread t; ForkJoinWorkerThread wt; ForkJoinPool.WorkQueue w;
//status,task 的运行状态
return (s = status) < 0 ? s :
((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) ?
(w = (wt = (ForkJoinWorkerThread)t).workQueue).
tryUnpush(this) && (s = doExec()) < 0 ? s :
wt.pool.awaitJoin(w, this, 0L) :
externalAwaitDone();
}我们将 doJoin 方法用我们最熟悉的 if/else 做个改动,是不是就豁然开朗了
private int doJoin() {
int s;
Thread t;
ForkJoinWorkerThread wt;
ForkJoinPool.WorkQueue w;
if((s = status) < 0) { // 有结果,直接返回
return s;
}else {
if((t = Thread.currentThread()) instanceof ForkJoinWorkerThread) {
// 如果是 ForkJoinWorkerThread Worker
if((w = (wt = (ForkJoinWorkerThread) t).workQueue).tryUnpush(this) // 类似上面提到的 scan,但是是专项尝试从本工作队列里取出等待的任务
// 取出了任务,就去执行它,并返回结果
&& (s = doExec()) < 0) {
return s;
}else {
// 也有可能别的线程把这个任务偷走了,那就执行内部等待方法
return wt.pool.awaitJoin(w, this, 0L);
}
}else {
// 如果不是 ForkJoinWorkerThread,执行外部等待方法
return externalAwaitDone();
}
}
}其中 awaitJoin 和 externalAwaitDone 都用到了 Helper(帮助) 和 Compensating(补偿) 两种策略,这两种策略大家完全可以自行阅读了,尤其是 awaitJoin 方法,强烈推荐大家自行阅读,其中 pop 的过程在这里,这里不再展开
到这里,有关 ForkJoinPool 相关的内容就算是结束了,为了让大家有个更好的理解 fork/join 机制,我们还是画几张图解释一下
Fork/Join 图解
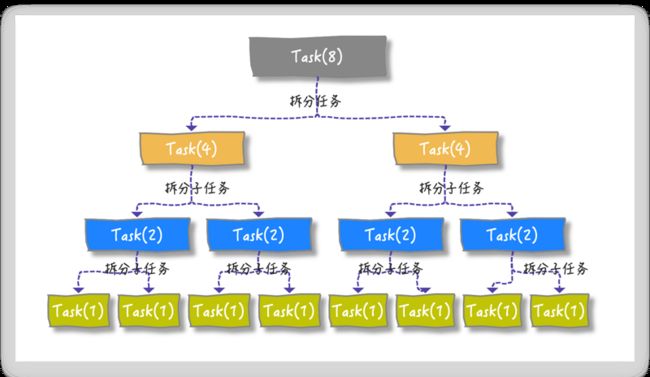
假设我们的大任务是 Task(8), 最终被分治成可执行的最小单元是 Task(1)
按照分治思想拆分任务的整体目标就是这样滴:
从外部先提交一个大的 Task(8),将其放在偶数槽位中(请注意颜色对应)

不满足并行度,会创建 Worker 1 来扫描,并从 base 端窃取到任务 task(8),执行到 compute, fork
出两个 task(4), 并 push到 WorkQueue 中

在执行任务时始终会确认是否满足并行度要求,如果没有就会继续创建新的Worker,与此同时,也会继续 fork 任务,直到最小单元。Worker1 会从 top 端 pop 出来 task(4) 来继续 compute 和 fork,并重新 push 到 WorkQueue 中

task(2) 还不是最小单元,所以会继续 pop 出 task(2),并最终 fork 出两个 task(1) push 到 WorkQueue中

task(1) 已经是最小粒度了,可以直接 pop 出来执行,获取最终结果;在 Worker1 进行这些 pop 操作的同时,为了满足并行度要求也会创建的其他Worker,比如 Worker 2,这时 Worker2 会从 Worker 1 所在队列的 base 端窃取任务

Worker 2 依旧是按照这个规则进行 pop->fork,到最终可以 exec 任务,假设 Worker 1 的任务先执行完,要 join 结果,当 join task(4) 时,通过 hint 定位到是谁偷走了 task(4),这时顺藤摸瓜找到 Worker2,如果 Worker2 还有任务没执行完,Worker1 再窃取回来帮着执行,这样互帮互助,最终快速完成任务
灵魂追问
- 为什么说 ForkjoinPool 效率要更高?同时建议使用 commonPool?
- JDK1.8 Stream 底层就充分用到了 ForkJoinPool,你知道还有哪里用到了 ForkJoinPool 了吗?
- ForkJoinPool 最多会有多少个槽位?
- 下面代码有人说不能充分利用 ForkJoinPool,多个 task 的提交要用 invokeAll,你知道为什么吗?如果不用 invokeAll,要怎样使用 fork/join 呢?
protected Long compute() {
if (任务足够小) {
return cal();
}
SumTask subtask1 = new SumTask(...);
SumTask subtask2 = new SumTask(...);
// 分别对子任务调用fork():
subtask1.fork();
subtask2.fork();
// 分别获取合并结果:
Long subresult1 = subtask1.join();
Long subresult2 = subtask2.join();
return subresult1 + subresult2;
}总结
这又是一篇长文,很多小伙伴私下都建议我将长文拆开,一方面读者好消化,另一方面我自己也在数量的体现上变得高产。几次想拆开,但好多文章拆开就失去了连续性(大家都有遗忘曲线)。过年没回老家,就有时间撸文章了。为了更好的理解源码,文章的基础铺垫内容很多,看到这,你应该很累了,想要将更零散的知识点串起来,那就多看代码注释回味一下,然后一起膜拜 Doug Lea 吧