node.js-基础与常用模块
推荐阅读
- 《新时期的 node.js 入门》- 李锴
- 《深入浅出 node.js》- 朴灵
- 知乎
- node.js interview
- 七天学会 node.js
相关链接
- github 更多文章
- 推荐 在线阅读
文章目录
- 推荐阅读
- 相关链接
- 底层机制
-
- 单线程与多线程
- 并行与并发
- Node中的事件循环(event loop)
- 常用模块(原生node.js)
-
- Buffer
- 文件系统(File System)
- HTTP 服务
-
- 创建 HTTP 服务
- request 对象
- response对象
- Stream
- ReadLine
- Events
-
- path 模块
底层机制
单线程与多线程
其他语言(如 Java、C++等)都有多线程的语言特性,即开发者可以派生出多个线程来协同工作;
Node 并没有提供多线程的机制,开发者无法在一个独立进程中增加新的线程,但是可以派生出多个进程来达到并行完成工作的目的。
Node 的底层实现(C++)并非是单线程的,libuv 会通过类似线程池的实现来模拟不同操作系统下的异步调用,这对开发者来说是不可见的。
Libuv 中的多线程

Libuv 是一个跨平台的异步 IO 库,它结合了 UNIX 下的 libev 和 Windows下的 IOCP 的特性,最早由 Node 的作者开发,专门为 Node 提供多平台下的异步 IO 支持。Node 中的非阻塞 IO 以及事件循环的底层机制,都是由 libuv 来实现的。
在 Windows 环境下,libuv直接使用 Windows 的 IOCP(I/O Completion Port)来实现异步 IO。在非 Windows 环境下,libuv 使用多线程来模拟异步 IO。
以 readFile 为例,读取文件的系统调用是由 libuv 来完成的,Node 只负责调用 libuv 的接口,等数据返回后再执行对应的回调方法。
并行与并发
首先搞清楚这两个概念的差别:这里以一个排队取火车票的场景来进行介绍
并发(Concurrent):并发是假设有两个队伍但只有 1 个取票机,两个队伍轮流取票。
并行(Parallel):并行是假设有两个队伍,不同的是开放了 2 个取票机,那么这两个队列可以同时向前移动。
以操作系统的角度:并发是指宏观上在一段时间内能同时运行多个程序,而并行则指同一时刻能运行多个指令。并行需要硬件支持,如多流水线、多核处理器或者分布式计算系统。操作系统通过引入进程和线程,使得程序能够并发运行。
Node 中的并发:单线程支持高并发,通常是依靠异步+事件循环来实现的,异步使得代码能在面临多个请求时不会发生阻塞,事件循环提供了 IO 调用结束后调用回调函数的能力。
多个请求同时到达时,Java、C++ 等能通过开多个线程来处理请求,而 node.js 却不能开多线程,
其利用事件驱动和异步 I/O 的特性极大地提升了程序性能从而使其有能力这种高并发场景。具体的解释可以参考《深入浅出 node.js》笔记部分。
Node中的事件循环(event loop)
浏览器的事件循环中提到了宏任务和微任务,在 node.js 中,事件循环被分成了 6 个不同的阶段。每个阶段执行特定的宏任务,每执行完一个阶段的回调,就清空一次微任务队列。
宏任务包括
script , setTimeout , setInterval , setImmediate , I/O , UI rendering
微任务包括 process.nextTick, promise.then, Object.observe , MutationObserver
MutationObserver使用方式见这里
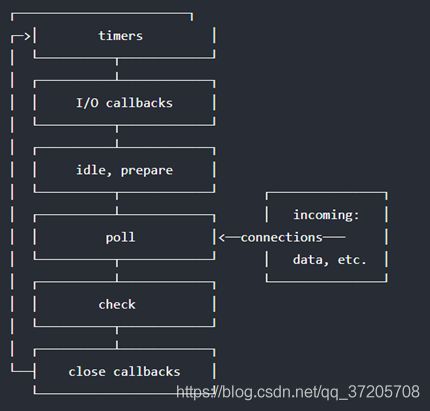
- timers: 用于处理 setTimeout() 和 setInterval() 的回调。
- I/O callbacks: 大多数的回调方法会在这个阶段执行,除了 timers、close 和 setImmediate
- idle, prepare: 仅内部使用。
- poll: 轮训,不断检查有没有新的 I/O 事件
- check: 执行 setImmediate() 事件的回调。
- close callbacks: 处理一些 close 相关的事件,例如 socket.on(‘close’,…)
process.nextTick 与 setImmediate
setImmediate 接受一个回调函数作为参数,其不像 setTimeout 一样可以设置定时器的时间。
事件循环的整个 check 阶段是为 setImmediate 方法而设置的:一般情况下,当事件循环到达 poll 阶段后,就会检查当前代码是否调用了 setImmediate,如果一个回调函数是被 setImmediate 方法调用的,事件循环就会跳出 poll 阶段而进入 check 阶段。
process.nextTick 接受一个回调函数作为参数,该方法定义的回调方法会被加入到名为 nextTickQueue 的队列中。
在事件循环的任何阶段,如果 nextTickQueue 不为空,都会在当前阶段操作结束后优先执行 nextTickQueue 中的回调函数。
看上去似乎和微任务的执行是类似的,那么 promise.then 和 process.nextTick 的回调谁更先执行呢?setImmediate 和 nextTick 的出现是为了解决什么问题呢?
let promise = new Promise((resolve, reject) => {
resolve()
})
promise.then(() => {
console.log('promise')
})
process.nextTick(function () {
console.log('nextTick')
})
// 打印顺序:nextTick promise 无论 Promise 放在之前还是之后都是一样
看上去似乎是 nextTick 的回调比 promise.then 的回调优先级更高
推荐阅读:node 中 setImmediate 和 nextTick 的使用
常用模块(原生node.js)
Buffer
Buffer 是 node.js 特有的(区别于浏览器 JavaScript)的数据类型,主要用来处理二进制数据。前后端通信时二进制数据流十分常见(例如传输一张 gif 图片)。Buffer 属于固有(built-in)类型,因此无需 require 引入。
在文件操作和网络操作中,如果不显式声明编码格式,其返回数据的默认类型就是 Buffer。
拼接Buffer
var data = []
res.on('data', function (chunk) {
data.push(chunk)
})
res.on('end', function () {
var buf = Buffer.concat(data)
console.log(buf.toString())
})
文件系统(File System)
该模块提供了读写文件的能力,借助于底层的 linux 的 C++ API 来实现,这些 API 大多提供同步和异步两种版本。下面仅介绍几个常用的。
fs.readFile(file[, options], callback)
readFile 方法用于异步读取文本文件中的内容,适用于体积较小的文件,数百 MB 的文件建议使用 stream。readFile 读出的数据需要在回调方法中获取,而 readFileSync 直接返回文本数据内容
const fs = require('fs')
fs.readFile('foo.txt', function (err, data) {
if (err) throw err
console.log(data)
})
// 如果不指定readFile的coding配置,其会返回Buffer格式
// fs.writeFile(file, data[, options], callback)
第一个参数为文件名,如果不存在,则会尝试创建它,默认的 flag 为 ’w’
fs.writeFile(filePath, mp3, 'binary', err => {
if (err) {
res.json({
error: 1,
msg: '下载失败'
})
} else {
res.json({
error: 0,
msg: '下载成功',
path: downloadUrl
})
}
})
fs.stat(path, callback)
stat 方法通常用于获取文件的状态,通常开发者可以在调用 open()、read()、或者 write 方法之前调用 fs.stat 方法,用来判断文件是否存在。
如果文件存在,则返回文件的状态信息,如下
Stats {
dev: 215266619,
mode: 33206,
nlink: 1,
uid: 0,
gid: 0,
rdev: 0,
blksize: undefined,
ino: 2251799814181389,
size: 2023,
blocks: undefined,
atimeMs: 1557839146143.9646,
mtimeMs: 1559027178498.3296,
ctimeMs: 1559027178498.3296,
birthtimeMs: 1557839146143.9646,
atime: 2019-05-14T13:05:46.144Z,
mtime: 2019-05-28T07:06:18.498Z,
ctime: 2019-05-28T07:06:18.498Z,
birthtime: 2019-05-14T13:05:46.144Z }
如果文件不存在,则会出现 Error: ENOENT: no such file or directory 的错误
实例:获取目录下所有的文件名
这是一个常见的需求,实现这个功能只需要 fs.readdir 以及 fs.stat 两个 API,readdir 用于获取目录下的所有文件或者子目录,stat 用于判断具体每条记录时文件还是子目录,如果是子目录,则递归调用整个方法
const fs = require('fs')
function getAllFileFromPath(path) {
fs.readdir(path, function (err, res) {
for (let subPath of res) {
// 这里使用同步方法而不是异步
let statObj = fs.statSync(path + '/' + subPath)
if (statObj.isDirectory()) {
// 判断是否为目录
console.log('Dir: ', subPath)
// 如果是文件夹,递归获取子目录中的文件列表
} else {
console.log('File: ', subPath)
}
}
})
}
getAllFileFromPath(__dirname)
HTTP 服务
HTTP 模块提供了一系列用于网络传输的 API,这些 API 大都位于比较底层的位置,可以让开发者自由控制整个 HTTP 传输过程
在 HTTP 模块中,node 定义了一些顶级的类、属性以及方法,如下所示
Class: http.Agent
Class: http.ClientRequest
Class: http.Server
Class: http.ServerResponse
Class: http.IncomingMessage
http.METHODS
http.STATUS_CODES
http.createClient([port], [, host])
http.createServer([requestListener])
http.get(options[, callback])
http.request(options[, callback])
…
创建 HTTP 服务
const http = require('http')
const server = http.createServer(function (req, res) {
res.writeHead(200, {
'Content-Type': 'text/plain'})
res.end('Hello World!')
})
server.listen(3000)
上面的代码使用 createServer 方法创建了一个简单的 HTTP 服务器,该方法返回一个 http.server 类的实例,createServer 方法包含了一个匿名的回调函数,该函数有两个参数 req 和 res,它们分别是 IncomingMessage 和 ServerResponse 的实例。分别表示 HTTP 的 request 和 response 对象,服务器创建完成后,node 进程开始循环监听 3000 端口(由listen方法实现)
处理 HTTP 请求
request 对象
1.method、URL
const method = req.method
const url = req.url
http://example.com/index.html?nam=Lear
-> url: /index.html?name=Lear
2.header
http header 通常为以下的形式
{
'content-length': '123',
'content-type': 'text/plain',
'connection': 'keep-alive',
'host': 'mysite.com'
...
}
通过 req.headers 获取一个 JSON 对象,可以对属性名进行单独索引
const headers = req.headers
const userAgent = headers['user-agent']
3.request body
node 通过 stream 来处理 HTTP 的请求体,stream 注册了 data 和 end 两个事件,可以用如下的代码来获取完整的 HTTP 请求体
let body = []
request.on('data', chunk => {
body.push(chunk)
}).on('end', () => {
body = Buffer.concat(body).toString()
})
response对象
1.设置 response header
通过 setHeader` 方法可以设置 response 的头部信息
response.setHeader('Content-Type': 'application/json')
setHeader 方法只能设置 response header 单个属性的内容,如果想要一次性设置所有的响应头和状态码,可以使用 writeHead 方法
writeHead 方法用于定义 HTTP 响应头,包括状态码等一系列属性
response.writeHead(200, {
'Content-Length': Buffer.byteLength(body),
'Content-Type': 'text/plain'
})
调用该方法后,服务端向客户端发送 HTTP 响应头,后面通常会跟着调用 res.write 等方法,响应头不可重复发送;有时开发者并不会显式调用该方法,调用 res.end 方法也会调用 writeHead 方法,此时 statusCode 会自动设置为 200
2.response body
response 对象是一个 writableStream 实例,可以直接调用 write 方法进行写入,写入完成后,再调用 end 方法将该 stream 发送到客户端
response.write('')
response.write('')
response.write('Hello World!
')
response.write('')
response.write('')
response.end()
// 或者写成这样:直接将 response body 作为 end 方法的参数返回
response.end('Hello World!
')
3.response.end
end 方法在每个 HTTP 请求的最后都会被调用,开发者应该调用该方法来结束 HTTP 请求。如果不调用 end 方法,浏览器地址栏左边的叉号会一直存在,表示该请求尚未完成。
end 方法支持一个字符串或者 buffer 作为参数,可以指定在 HTTP 请求的最后返回的数据,该数据会在浏览器页面上显示出来;如果定义了回调方法,那么会在 end 返回后调用。
res.end('Hello node', () => {
console.log('http cycle end')
})
Stream
文件系统提供的 API 有一个重要的问题,就是如果文件过大,一次性地读或写显然是不可行的,Stream 允许我们把较大的数据分批次地进行读写。
在 node.js 中,一共有四种基础的 stream 类型:
- Readable:可读流(for example fs.createReadStream())
- Writable:可写流(for example fs.createWriteStream())
- Duplex:既可读,又可写(for example net.Socket)
- Transform:操作写入的数据,然后读取结果,通常用于输入数据和输出数据不要求匹配的场景,如 zlib.createDeflate()
// 复制文件
const fs = require('fs')
const path = require('path')
const fileName1 = path.resolve(__dirname, 'data.txt')
const fileName2 = path.resolve(__dirname, 'data-bak.txt')
const readStream = fs.createReadStream(fileName1)
const writeStream = fs.createWriteStream(fileName2)
readStream.pipe(writeStream)
readStream.on('data', chunk => {
console.log(chunk)
console.log(chunk.toString())
})
readStream.on('end', () => {
console.log('copy done')
})
// 也可用于http
const http = require('http')
const fs = require('fs')
const path = require('path')
const fileName1 = path.resolve(__dirname, 'data.txt')
const server = http.createServer((req, res) => {
if (req.method === 'GET') {
const readStream = fs.createReadStream(fileName1)
readStream.pipe(res)
}
})
Writable Stream 主要使用 write 方法来写入数据,该方法是异步的,假设我们创建一个可读流读取一个较大的文件,再调用 pipe 方法将数据通过一个可写流写入另一个位置。如果读取的速度大于写入的速度,那么 node 将会在内存中缓存这些数据。
当然缓冲区也是有大小限制的(state.highWatermark),当达到阈值后,write方法会返回 false,可读流也进入暂停状态,当 writable stream 将缓冲区清空之后,会触发 drain 事件,上游的 readable 重新开始读取数据。
pipe 方法使得数据可以通过管道由可读流流入可写流。pipe 方法接收一个 writable 对象,当 readable 对象调用 pipe 方法时,会在内部调用 writable 对象的 write 方法进行写入。
ReadLine
ReadLine 是一个 node 原生模块,提供了按行读取 Stream 中数据的功能
const readline = require('readline')
const fs = require('fs')
const rl = readline.createInterface({
input: fs.createReadStream('data.txt')
})
// 每读取一行数据出发
rl.on('line', data => {
console.log(data)
})
rl.on('close', () => {
console.log('closed')
})
Events
node 程序中的对象会产生一系列的事件,例如一个 HTTP Server 会在每次有新连接时触发一个事件,一个 Readable Stream 会在文件打开时触发一个事件等。所有能触发事件的对象都是 EventEmitter 类的实例。下面的代码演示了如何注册一个事件并触发它:
const eventEmitter = require('events')
const myEmitter = new eventEmitter()
myEmitter.on('begin', () => {
console.log('begin')
})
myEmitter.emit('begin')
在实际的开发中,通常不会直接使用 Event 模块来进行事件处理,而是选择将其作为基类进行继承的方式来使用 Event,在 node 的内部实现中,凡是提供了事件机制的模块,都会在内部继承 Event 模块,以 fs 模块为例,下面是其源码中的一部分:
function FSWatcher() {
EventEmitter.call(this)
// ......
}
util.inherits(FSWatcher, EventEmitter) // util.inherits 是用来继承的方法
假设我们要用 node 来开发一个网页上的音乐播放器,关于播放和暂停的处理,就可以考虑通过继承 Events 模块来实现:
const util = require('util')
const event = require('events')
function Player() {
event.call(this)
}
util.inherits(Player, event)
const player = new Player()
player.on('pause', () => {
console.log('pause')
})
player.on('play', () => {
console.log('playing')
})
player.emit('play') // playing
path 模块
原文链接:https://www.jianshu.com/p/78fadd20ee61
1.连接路径:path.join([path1][, path2][, …])
path.join() 方法可以连接任意多个路径字符串。要连接的多个路径可做为参数传入。path.join() 方法在接边路径的同时也会对路径进行规范化。例如:
var path = require('path')
// 合法的字符串连接
path.join('/foo', 'bar', 'baz/asdf', 'quux', '..')
// 连接后
'/foo/bar/baz/asdf'
//不合法的字符串将抛出异常
path.join('foo', {
}, 'bar')
// 抛出的异常
TypeError: Arguments to path.join must be strings'
2.路径解析:path.resolve([from …], to)
path.resolve() 方法可以将多个路径解析为一个规范化的绝对路径。其处理方式类似于对这些路径逐一进行 cd 操作,与 cd 操作不同的是,这些路径可以是文件,并且可不必实际存在(resolve() 方法不会利用底层的文件系统判断路径是否存在,而只是进行路径字符串操作)。例如:
path.resolve('foo/bar', '/tmp/file/', '..', 'a/../subfile')
相当于
cd foo/bar
cd /tmp/file/
cd ..
cd a/../subfile
pwd
示例:
path.resolve('/foo/bar', './baz')
// 输出结果为
'/foo/bar/baz'
path.resolve('/foo/bar', '/tmp/file/')
// 输出结果为
'/tmp/file'
path.resolve('wwwroot', 'static_files/png/', '../gif/image.gif')
// 当前的工作路径是 /home/itbilu/node,则输出结果为
'/home/itbilu/node/wwwroot/static_files/gif/image.gif'
3.对比
const path = require('path');
let myPath = path.join(__dirname,'/img/so');
let myPath2 = path.join(__dirname,'./img/so');
let myPath3 = path.resolve(__dirname,'/img/so');
let myPath4 = path.resolve(__dirname,'./img/so');
console.log(__dirname); // D:\myProgram\test
console.log(myPath); // D:\myProgram\test\img\so
console.log(myPath2); // D:\myProgram\test\img\so
console.log(myPath3); // D:\img\so
console.log(myPath4); // D:\myProgram\test\img\so