机器学习概览
机器学习概览
- 前言
- 一、数据预处理
-
- 1.数据清理
- 2.数据集成
- 3.数据规约
- 4.数据变换
- 二、回归
-
- 1.简单的线性回归
- 2.线性回归正则化
- 3.多元线性回归
- 三、分类
-
- 1.逻辑回归
- 2.KNN
- 3.决策树
- 4.SVM
- 四、集成
-
- 1.bagging
- 2.随机森林
- 3.Boosting
- 4.AdaBoost
- 四、聚类
-
- 1.K-means
- 2.层次聚类
- 五、降维
-
- 1.主成分分析(PCA)
- 2.非线性降维方法
- 五、概率图模型
-
- 1.隐马尔科夫模型
- 2.条件随机场
- 六、神经网络
-
- BP
- 七、深度学习与强化学习
-
- 1.深度学习
- 2.强化学习
前言
从去年暑假开始,大半年的时间学习AI,寒假结束之时来个阶段性总结。
本文以机器学习的问题处理流程来写。分为以下几个知识点:数据预处理、回归、分类、集成、聚类、降维、神经网络、概率图模型、最后深度学习和强化学习(在下篇博客详细介绍)。
一、数据预处理
在实际项目中,数据往往是不完整的(即缺少特征或数值)、经常存有噪声、特征之间的关联等。因此有以下几种常用方法进行预处理。
1.数据清理
1)缺失值的处理:
删除变量,统计量填充,插值法填充,定值法填充,模型填充,哑变量填充
2)数据清理离群点处理:
删除、log-scale 对数变换、中位值代替、Tree模型训练等。
3)数据清理噪声处理:
采取分箱或者建立模型反解变量。
2.数据集成
数据集成将多个数据源中的数据结合成、存放在一个一致的数据存储,如数据仓库中。这些源可能包括多个数据库、数据方或一般文件。
3.数据规约
1)维度规约:删除不相关或不重要的属性,减少数据量
2)维度变换:PCA,FA,AVD等,下面将介绍PCA算法。
4.数据变换
数据变换通常进行数据规范化,离散化等,用于挖掘。
1)规范化:有MAX-MIN、Z-Score、对数变换等方法
2)离散化:等频或等宽处理、聚类等
3)稀疏化:可以采用哑变量稀疏化处理。
二、回归
1.简单的线性回归
1)以吴恩达教授的图为例
其中损失函数为误差平方和(除常数)。
目的是要得到合适的参数,使得损失函数最小。

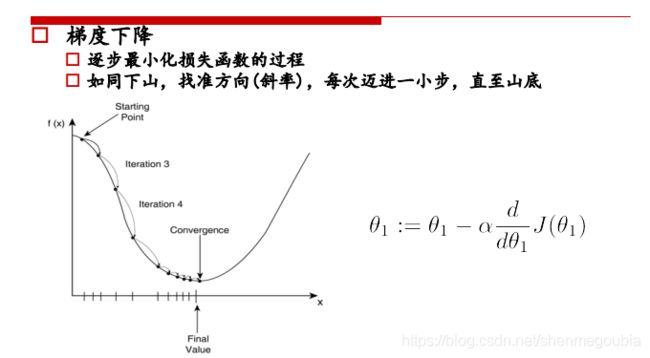
2)求解损失函数最小值的过程(梯度下降)
例如在曲线左侧某点斜率为负值,通过公式可得,θ的值增大,所以点向曲线下方移动。
同时学习率应设置适宜,防止速度过慢或者越过最优点。
2.线性回归正则化
1)过拟合与欠拟合:噪声的存在、模型一般性的学习能力差等原因会导致过拟合,因此需要利用正则化解决过拟合问题。
2)正则化:通过控制参数变化幅度,对参数大的参数进行惩罚。
加入正则化的损失函数:

3.多元线性回归
多元线性回归无非就是特征变多,维数升高,处理方法与基本公式与一元线性回归类似,可以进行多变量梯度下降。
三、分类
1.逻辑回归
逻辑回归是一种分类算法,与多元线性回归类似,但两者因变量不同,这两者可归于广义线性模型。
1)sigmoid函数:
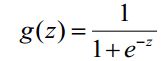

由上可看出,该函数的值域在0-1之间,如果假设有一个阈值0.5,那么大于0.5就输出1,小于0.5就输出0,这样就起到了分类的效果。
2)损失函数:

3)梯度下降求最小值:经过推导,θ的更新过程与线性回归的梯度下降法公式类似,但
模型函数不同。
2.KNN
1)基本思想: 一个样本与数据集中的k个样本最相似, 如果这k个样本中的大多数属于某一个类别, 则该样本也属于这个类别。
2)距离度量:计算相似性时,需要用到距离公式(闵可夫斯基,曼哈顿,欧式,切比雪夫距离等),一般采用欧氏距离。
3)实现步骤:
(1) 计算已知类别数据集中的点与当前点之间的距离
(2) 按距离递增次序排序
(3) 选取与当前点距离最小的k个点
(4) 统计前k个点所在的类别出现的频率
(5) 返回前k个点出现频率最高的类别作为当前点的预测分类

3.决策树
算法框架主要有:
1)主函数:输入数据,划分数据,生长节点,终止判断,递归
2)最优特征子函数:通过信息增益、信息增益率、节点方差等评判标准进行选取
3)划分数据集函数:很简单
4)分类器:通过树找到分类标签,进行分类
5)剪枝:从叶节点向上回溯,对节点进行剪枝,比较损失函数值。最后通过动态规划可以得到全局最优的剪枝方案。
几个重要概念
1)信息:某变量Xi的信息可定义为

2)经验熵

3)条件熵

4)信息增益:即经验条件熵H(D|A)之差

5)信息增益率:即信息增益与经验熵之比
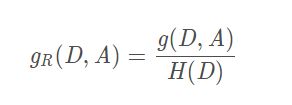
决策树算法中,ID3算法采用信息增益作为特征选择的依据,C4.5采用信息增益率作为依据
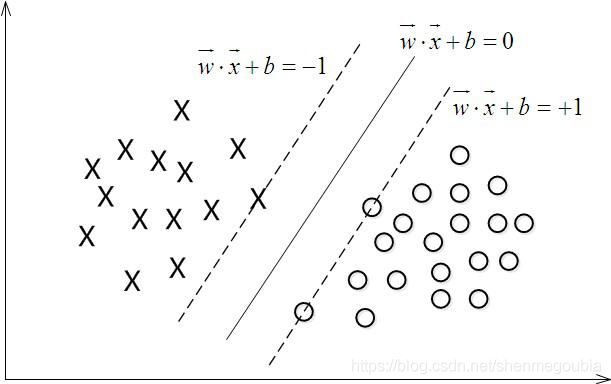
4.SVM
SVM是统计学习理论在算法领域的集中体现,其本身较为复杂,所以只列举几个要点,以后有机会写篇博客谈谈SVM。
1)SVM的理论基础:经验风险最优,VC维定理,结构化风险最优等。
2)相关概念:超平面,最大间隔超平面,拉格朗日法,KKT条件,对偶变换,分类器,高维映射,核函数,松弛变量。
3)求解算法:SMO
四、集成
1.bagging
Bagging使用装袋采样来获取数据子集训练基础学习器.
基本步骤:
1)从原始样本集中抽取训练集。每轮从原始样本集中采用有放回的方法抽取n个训练样本,共进行k轮抽取,得到k个训练集。
2)每次使用一个训练集得到一个模型,共得到k个模型。
3)分类:将k个模型采用投票的方式得到分类结果。
4)回归:计算上述模型的均值作为最后的结果。
2.随机森林
随机森林是一种基于Bagging的方法,其具有较高的准确率和抗过拟合能力,并且处理离散型数据也无需规范化,具体步骤如下:
1)从原始训练集中使用Bootstraping方法随机有放回采样选出m个样本,共进行n次采样,生成n个训练集
2)对于n个训练集,分别训练n个决策树模型
3)对于单个决策树模型,采用适当方法进行分裂(信息增益比等)
4)每棵树都一直分裂下去,直到该节点的所有训练样例都属于同一类。在决策树的分裂过程中不需要剪枝。
5)将生成的多棵决策树组成随机森林。对于分类问题,按多棵树分类器投票决定最终分类结果;对于回归问题,由多棵树预测值的均值决定最终预测结果
3.Boosting
Boosting指的是将弱学习器转换为强学习器。
基本步骤:
1)从初始训练集训练出一个基学习器。
2)再根据基学习器的表现对训练样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注。
3)基于调整后的样本分布来训练下一个基学习器。
4)重复进行上述步骤,直至基学习器数目达到事先指定的值N,最终将这N个基学习器进行加权结合。
4.AdaBoost
AdaBoost基本原理就是将多个弱分类器进行有机结合,成为强分类器
迭代步骤:
1)初始化权值分布。如果有N个样本,则每一个训练样本最开始时都被赋予相同的权值:1/N。
2)训练弱分类器。具体训练过程中,如果某个样本点已经被准确地分类,那么在构造下一个训练集中,它的权值就被降低;相反,如果某个样本点没有被准确地分类,那么它的权值就得到提高。然后,权值更新过的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
3)将训练得到的弱分类器组合成强分类器。最终分类误差率小的分类器在最终分类中起到决定作用。
四、聚类
1.K-means
首先谈谈聚类与分类的区别
分类:从特定的数据中挖掘,做出判断,如分辨垃圾邮件
聚类:事先未知如何去分,由算法自己判断,即无监督学习。
K-means具体步骤
1)输入k的值,将数据集经过聚类得到k个分组。
2)从数据集中随机选择k个数据点作为初始质心
3)对集合中每一个点,计算与每一个质心的距离,离哪个质心距离最近,就划分到此质心。
4)计算第三步划分结束后的每一个聚类集合新质心。
5)若新质心与旧质心距离小于某阈值,则算法终止。
6)若新质心与旧质心距离大于某阈值,则重复3-5.
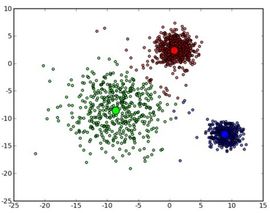
2.层次聚类
层次聚类与K聚类最大的不同在于,其是从底层出发,先计算点与点距离,结合一个类,再计算类与类距离,不停地合并计算,最终得到了众大类。
具体步骤如下:
(1) 将每个对象看作一类,计算其之间的最小距离。
(2) 将距离最小的两个类合并成一个新类。
(3) 重新计算新类与所有类之间的距离。
(4) 重复(2)、(3),直到所有类最后合并成一类。
其优点在于无需预先指定聚类数,限制少。但计算复杂度和聚类效果可能有欠缺。

五、降维
1.主成分分析(PCA)
PCA算法是一种常见的数据分析方式,常用于高维度降维和主成分提取。
因为在许多研究和应用问题中,反应某个规律往往需要大量的数据和特征,多变量大样本无疑会为研究和应用提供了丰富的信息,但许多变量可能存在相关性和存在许多噪声,从而增加了问题分析的复杂性,因此需要想办法在减少分析量时,减少信息损失,PCA就是属于此类方法。
具体步骤:
1)计算每个特征所有数据的均值,然后用原数据减掉均值
2)计算协方差矩阵,即原矩阵与转置乘
3)计算协方差矩阵的特征值和特征向量
4)对每个特征值进行排序,取K个最大的特征值对应的特征向量
5)将样本投影到所选取的特征向量上(用线代知识求解)
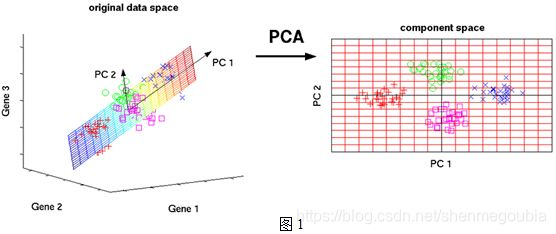
2.非线性降维方法
有LLE、LTSA、MDS、核PCA等。
以LLE为例,其在处理流形降维方面,比PCA效果要好。
LLE具体的算法如下:
1)使用KNN得到临近店
2)求解权重系数矩阵(用到局部协方差矩阵和拉格朗日乘子法)
3)映射到低维空间

五、概率图模型
概率图模型是一类用图的形式表示随机变量之间条件依赖关系的概率模型,是概率论与图论的结合。根据图中边有无方向,常用的概率图模型分为两类:有向图(贝叶斯网络、信念网络)、无向图(马尔可夫随机场、马尔可夫网络)。
1.隐马尔科夫模型
隐马尔科夫模型是一种结构简单的动态贝叶斯生成模型,在自然语言中处理标注问题。
1)马尔科夫过程:该过程中,每个状态的转移只依赖于之前的 n 个状态,这个过程被称为1个 n 阶的模型,其中 n 是影响转移状态的数目。
例如一阶马尔科夫过程,每一个状态转移只依赖于之前那一个,而且这种转移有概率。
2)马尔科夫链:时间和状态都是离散的马尔科夫过程。
3)隐马尔科夫模型:是一种用来描述一个含有隐含未知参数的马尔可夫过程的模型。
2.条件随机场
简单来说就是只要满足“条件随机场”这个条件,就可以根据定义的模型去求解问题,而问题以线性的居多,所谓线性就是满足“线性链条件随机场”,下面介绍线性链条件随机场。
设X,Y均为线性链表示的随机变量序列,若在给定随机变量序列X的条件下,随机变量序列Y的条件概率分布P(Y|X)构成条件随机场,即满足马尔可夫性,则称P(Y|X)为线性链条件随机场。

六、神经网络
神经网络是机器学习一个重要的技术,它以模拟人脑的神经网络来实现诸多功能
目前我接触到的神经网络有:BP,CNN,FFNN,RBF,RBM,DBN,GAN,RNN,LSTM,GRU等
以最基础的BP神经网络为例,后续将会与深度学习一起介绍其他的神经网络。
BP
一个简单的神经网路包含三层,输入层、隐藏层、输出层
层与层之间有连接权值,以logistic作为激活函数
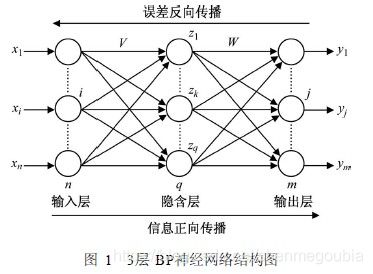
1)BP正向传播过程:每层神经元的实际输出为sigmoid函数,
函数的自变量为输入与权值的乘积加上阈值
2)反向传播:反向传播就是通过计算输出层的梯度和微分,用于更新输出层权值。
误差:

反向传播过程可分为以下几步 :
(1)输出层权重更新:
定义输出层一个误差信号err
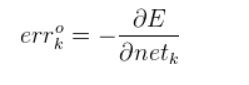
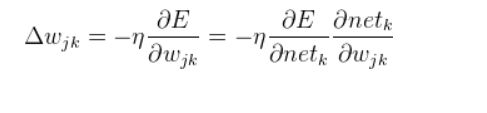
输出层权值向量可调整为

(2)隐藏层权重更新:
定义隐藏层一个误差信号err
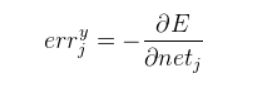
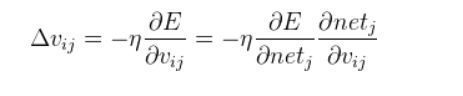
隐藏层权值向量的调整调整为

七、深度学习与强化学习
1.深度学习
深度学习简介:深度学习不是一个算法,它是通过多层神经网络构建出的一套算法框架,擅长解决图像识别、物体检测、自然语言翻译、语音识别和趋势预测等。
以CNN为例,包括输入、卷积层、池化层、全连接层、输出
1)卷积层:卷积层就是从图像数组中提取特征,通过卷积核在图上移动,重要的有参数共享
2)池化层:通过平均值池化、最大值池化等,筛选卷积之后的特征值
3)全连接层:因为用到了所有的局部特征,所以叫全连接层,输出一个N维向量,用来分类等
反向传播是神经网络的基础,CNN也具有反向传播,过程与上面类似。
2.强化学习
强化学习与其他的机器学习算法不同之处在于,它没有监督者,只有reward,其采用边获得样例边学习的方式,再更新自己的模型,具有延时性,在强化学习中,可分为以下几类概念:
1)理解环境与不理解环境:即基于现实环境和虚拟环境(模型)
2)基于概率和基于价值:一类是输出动作概率,适用于连续动作,一类是输出动作价值,无法表示连续动作的价值
3)回合更新和单步更新:每一轮更新一次和走一步更新一次
4)在线学习和离线学习:判断在于估计的行为和价值函数生成样本用到的行为是不是一样。
强化学习有动态规划,Q-learning,Sarsa,DQN,Actor-critic等算法,AlphaGo的用到的就是强化学习算法