pgsql 比较数字字符串_Python数字、字符串如何理解?【乐搏TestPro】
第二章 python数字、字符串
本节所讲内容:
2.1 python 数字类型
2.2 python 字符串类型
2.1 python数字类型
变量以及类型
变量的定义

在程序中,有时我们需要对2个数据进行求和,那么该怎样做呢?
大家类比一下现实生活中,比如去超市买东西,往往咱们需要一个菜篮子,用来进行存储物品,等到所有的物品都购买完成后,在收银台进行结账即可
如果在程序中,需要把2个数据,或者多个数据进行求和的话,那么就需要把这些数据先存储起来,然后把它们累加起来即可
变量就是用来存东西的
在Python中,存储一个数据,需要一个叫做变量的东西,如下示例:
num1 = 100 #num1就是一个变量,就好一个小菜篮子
num2 = 87 #num2也是一个变量
result = num1 + num2 #把num1和num2这两个"菜篮子"中的数据进行累加,然后放到 result变量中
说明:
所谓变量,可以理解为菜篮子,如果需要存储多个数据,最简单的方式是有多个变量,当然了也可以使用一个
程序就是用来处理数据的,而变量就是用来存储数据的
变量起名要有意义
2.变量的类型
生活中的“类型”的例子:

程序中:
为了更充分的利用内存空间以及更有效率的管理内存,变量是有不同的类型的,如下所示:
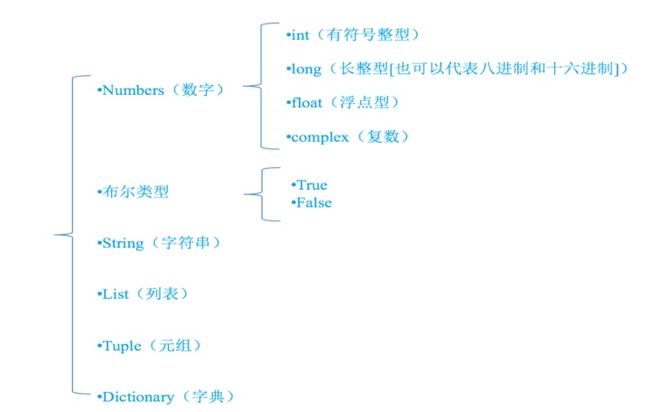
怎样知道一个变量的类型呢?
在python中,只要定义了一个变量,而且它有数据,那么它的类型就已经确定了,不需要咱们开发者主动的去说明它的类型,系统会自动辨别
可以使用type(变量的名字),来查看变量的类型
标示符和关键字
<1>标示符
什么是标示符,看下图:
挖掘机技术哪家强,中国山东找蓝翔
开发人员在程序中自定义的一些符号和名称
标示符是自己定义的,如变量名 、函数名等
<2>标示符的规则
标示符由字母、下划线和数字组成,且数字不能开头
思考:下面的标示符哪些是正确的,哪些不正确为什么
fromNo12
from#12
my_Boolean
my-Boolean
Obj2
2ndObj
myInt
test1
Mike2jack
My_tExt
_test
test!32
haha(da)tt
int
jack_rose
jack&rose
GUI
G.U.I
python中的标识符是区分大小写的
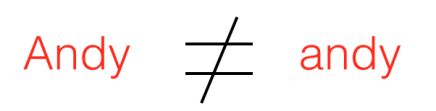
<3>命名规则
见名知意
起一个有意义的名字,尽量做到看一眼就知道是什么意思(提高代码可 读性) 比如: 名字 就定义为 name , 定义学生 用 student
驼峰命名法

小驼峰式命名法(lower camel case): 第一个单词以小写字母开始;第二个单词的首字母大写,例如:myName、aDog
大驼峰式命名法(upper camel case): 每一个单字的首字母都采用大写字母,例如:FirstName、LastName
不过在程序员中还有一种命名法比较流行,就是用下划线“_”来连接所有的单词,比如send_buf
Python推荐就是用下划线“_”来连接所有的单
查看关键字:

2.1.1 Python数字类型介绍
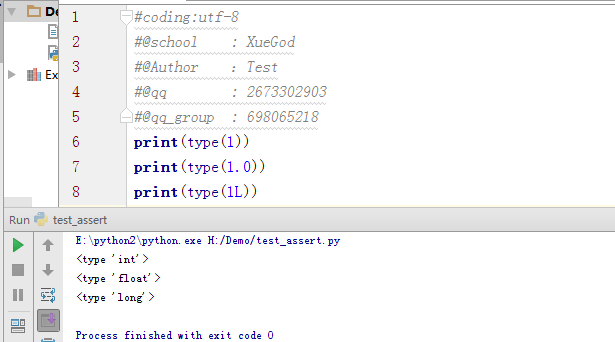
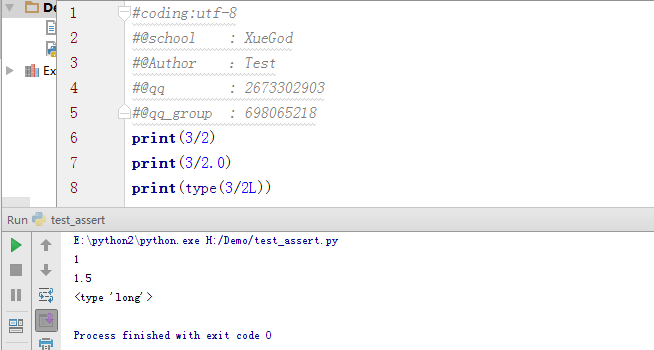
整型:int型,例子:1为整型。
浮点型:float型,例子:2.1为浮点型。
长整型:long型,例子:2L为长整形,数字后面加L就是长整形,理论上长整型的界限为 2147483647
【Tips】:
因为python 2.x版本长整型的不严谨,python 3版本取消了长整型。在python 2.x版本对MySQL操作时,导出的整形数可能就是长整型。
2.2.2 python数字类型转换
我们可以通过类型函数查看数字类型
也可以通过运算改变数字类型:
2.2.3 python数字类型运算符
| 运算符 | 描述 | 实例 |
|---|

2.2 python字符串类型
2.2.1 python字符串类型概述
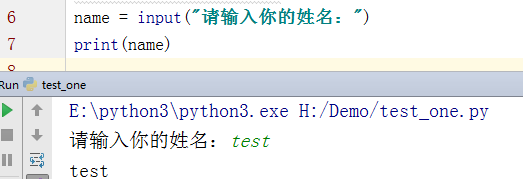
Input:是输入
Print:是输出
案例:
注释:

字符串是一个有序的,不可修改的,元素以引号包围的序列。
python字符串的定义:双引号或者单引号中的数据,就是字符串

字符串存储的另外一种方式:

2.2.2 python字符串的索引(index)
超市储物柜:

在python当中所有有序的序列都是由索引概念的,它们的区别在于序列是否可以被修改;
索引在我们初学的时候我们可以理解为字符串的下标;
字符串里的每一个个体都被称作字符也是该字符串的一个元素;

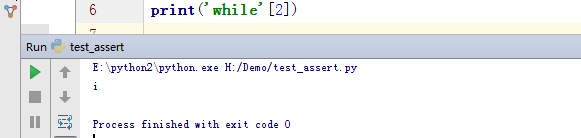
比如字符串‘while’,可以按照下图理解其下标概念,索引号从0开始;
| w | h | i | l | e |
| 0 | 1 | 2 | 3 | 4 |
索引的用法,取单个元素时,使用字符串[索引值] 索引值为对应元素的索引号;
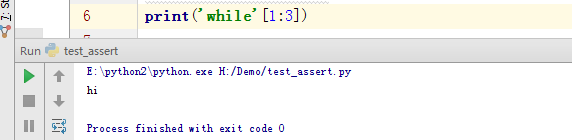
字符串截取:字符串[start:end],得到对应索引范围的元素,该范围包含起始端,不包含结尾端,默认截取的方向是从左往右的;
步长截取:字符串[start:end:step] 按照step步长进行隔取;
切片的语法:[起始:结束:步长]
注意:选取的区间属于左闭右开型,即从"起始"位开始,到"结束"位的前一位结束(不包含结束位本身)。

默认取法:字符串[start:end,step] 这三个参数都有默认值、start;默认值为0;end 默认值未字符串结尾元素;step 默认值为1

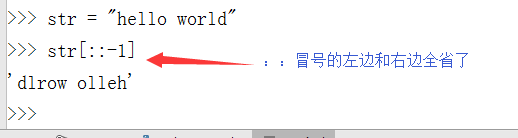
反取:字符串[负数],从右往左取

2.2.3 python字符串的方法
| 字符串的查找 | count | 计数功能,返回自定字符在字符串当中的个数 |
| find | 查找,返回从左第一个指定字符的索引,找不到返回-1 | |
| rfind | 查找,返回从右第一个指定字符的索引,找不到返回-1 | |
| index | 查找,返回从左第一个指定字符的索引,找不到报错 | |
| rindex | 查找,返回从右第一个指定字符的索引,找不到报错 |

| 字符串的分割 | partition | 把mystr以str分割成三部分,str前,str自身和str后 |
| rpartition | 类似于 partition()函数,不过是从右边开始. |

| 字符串的分割 | splitlines | 按照行分隔,返回一个包含各行作为元素的列表,按照换行符分割 |

| 字符串的替换 | replace | 从左到右替换指定的元素,可以指定替换的个数,默认全部替换 |
| Translate | 按照对应关系来替换内容 from string import maketrans |
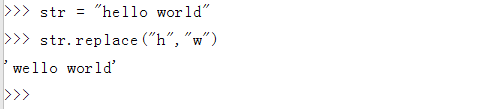
makestrans()用法
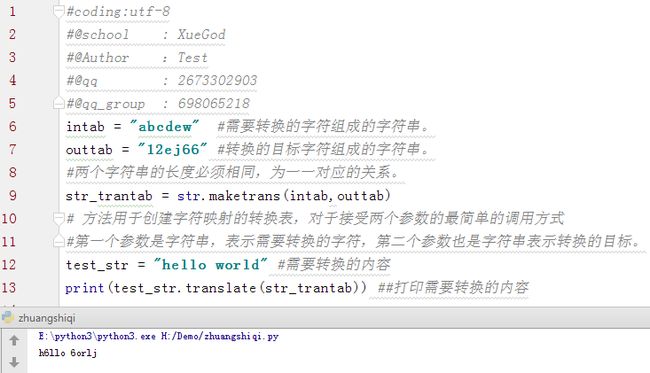
语法: str.maketrans(intab, outtab]);
Python maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,
第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。
注:两个字符串的长度必须相同,为一一对应的关系。
str.maketrans(intab,outtab[,delchars])
· intab -- 需要转换的字符组成的字符串。
· outtab -- 转换的目标字符组成的字符串。
intab = "hecd"# test_str 值
outtab = "3723" #需要编的值
str_trantb = str.maketrans(intab,outtab)
test_str = "hello world"
print(test_str.translate(str_trantb))
| 字符串的修饰 | center | 让字符串在指定的长度居中,如果不能居中左短右长,可以指定填充内容,默认以空格填充 |
| ljust | 让字符串在指定的长度左齐,可以指定填充内容,默认以空格填充 | |
| rjust | 让字符串在指定的长度右齐,可以指定填充内容,默认以空格填充 | |
| zfill | 将字符串填充到指定的长度,不足地方用0从左开始补充 | |
| format | 按照顺序,将后面的参数传递给前面的大括号 | |
| strip | 默认去除两边的空格,去除内容可以指定 | |
| rstrip | 默认去除右边的空格,去除内容可以指定 | |
| lstrip | 默认去除左边的空格,去除内容可以指定 |


字符串的变形
| 字符串的变形 | upper | 将字符串当中所有的字母转换为大写 |
| lower | 将字符串当中所有的字母转换为小写 | |
| swapcase | 将字符串当中所有的字母大小写互换 | |
| title | 将字串符当中的单词首字母大写,单词以非字母划分 | |
| capitalize | 只有字符串的首字母大写 | |
| expandtabs | 把字符串中的 tab 符号('t')转为空格,tab 符号('t')默认的空格数是 8 |


字符串的判断
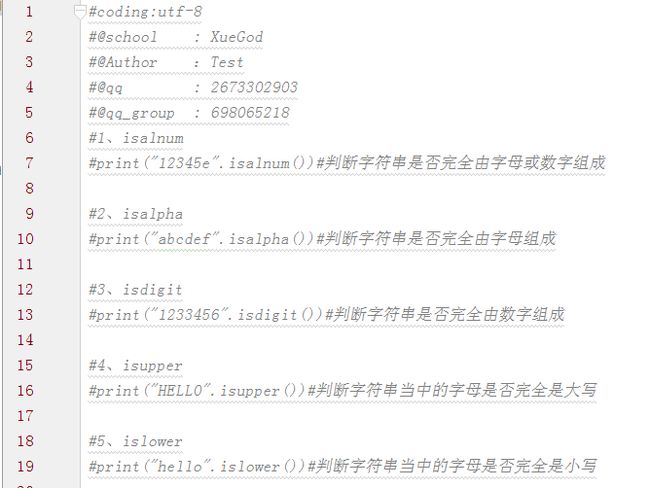
| 字符串的判断 | isalnum | 判断字符串是否完全由字母或数字组成 |
| isalpha | 判断字符串是否完全由字母组成 | |
| isdigit | 判断字符串是否完全由数字组成 | |
| isupper | 判断字符串当中的字母是否完全是大写 | |
| islower | 判断字符串当中的字母是否完全是小写 | |
| istitle | 判断字符串是否满足title格式 | |
| isspace | 判断字符串是否完全由空格组成 | |
| startswith | 判断字符串的开头字符,也可以截取判断 | |
| endswith | 判断字符串的结尾字符,也可以截取判断 | |
| split | 判断字符串的分隔符切片 |

2.2.4 python字符串的编码
encode是编码
decode是解码
| 编码方式 | ASCII | Unicode | UTF-8 |
|---|
编码方式对比:
python字符串是一种数据类型,但是字符串比较特殊,它有一个编码的问题。
因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理。最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节。比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295。
由于计算机是英语国家发明的,最早只有127个字母被编码到计算机里,也就是大小写英文字母、数字和一些符号,这个编码表被称为ASCII编码,比如大写字母A的编码是65,小写字母a的编码是97。
但是要处理中文显然一个字节是不够的,至少需要两个字节,而且还不能和ASCII编码冲突,所以,中国制定了GB2312编码,用来把中文编进去。
全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里,各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。
因此,俗称“万国码”的Unicode应运而生。Unicode把所有语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用两个字节表示一个字符(如果要用到非常偏僻的字符,就需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
现在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器。
由于python的诞生比Unicode标准发布的时间还要早,所以最早的Python只支持ASCII编码,普通的字符串’ABC’在Python内部都是ASCII编码的。Python提供了ord()和chr()函数,可以把字母和对应的数字相互转换,len()函数可以查字符串的长度:


总结:
2.1 python 数字类型
2.2 python 字符串类型