逆向工程发现苹果 M1 未公开的秘密:矩阵协处理器
本文转载自 机器之心
近期,国外开发者 Dougall Johnson 通过逆向工程,在苹果 M1 处理器内发现了一个被称为 AMX 的强大的未公开过的神秘协处理器:矩阵协处理器。

要弄清苹果矩阵协处理器具体是做什么的,我们需要了解什么是协处理器、什么是矩阵,以及为什么还要关心这些?
更重要的是,为什么苹果公司在发布新机的 keynote 里都没有提到这个协处理器?为什么它似乎是一个秘密?如果你已经了解了 M1 片上系统(SoC)中的神经网络处理引擎,可能会对苹果又设计一个矩阵协处理器(AMX)感到困惑。在这之前,我们先来了解一些基本概念。
首先,什么是矩阵?
矩阵(Matrix)是一个按照长方阵列排列的复数或实数集合,最早来自于方程组的系数及常数所构成的方阵,是高等代数中常见的工具。如果你使用过 Microsoft Excel 等电子表格,则矩阵就是与电子表格非常相似的东西。
关键的区别在于,在数学中,这样的数字表有一个它们支持的操作列表和特定的行为。正如在下图中展示的,矩阵可以有不同的风格。有这样一行的矩阵,通常称为行向量。如果一个是列向量,我们称之为列向量。关于矩阵相关内容,相信每一个理工科专业的都应该非常了解,因此不做过多的赘述。
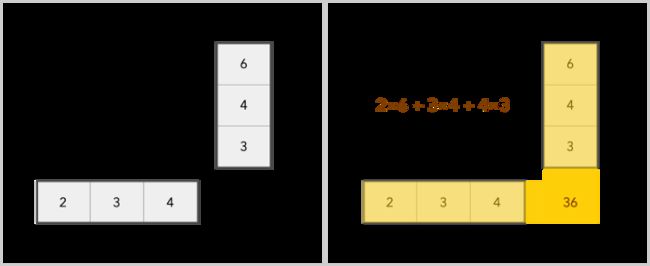
我们可以对矩阵进行加、减、缩放和乘积操作。加法很简单,只需分别添加每个元素,但乘法有点复杂。
这种形式在计算机任务处理中至关重要,矩阵的使用范围主要包括:
-
图像处理;
-
机器学习;
-
语音和手写识别;
-
人脸识别;
-
压缩;
-
多媒体:音频和视频。
机器学习是这几年中最热门的方向。仅仅在 CPU 上增加更多的核心并不能让这个领域的任务速度足够快,因为它的要求很高,这需要专门的硬件。浏览互联网、写电子邮件、文字处理和电子表格等常规任务多年来一直运行得很快。而机器学习,这是我们真正需要提高处理能力的特殊任务。
由于用上了 5 纳米制程,在任何给定的芯片上,苹果公司都有最大数量的晶体管用于构建不同类型的硬件。他们可以增加更多的 CPU 内核,但这实际上只是加快了常规任务的速度,而这些任务已经运行得足够快了。因此,人们经常选择用部分晶体管制造专门的硬件来解决图像处理、视频解码和机器学习。这种专用硬件就是协处理器和加速器。
更多关于协处理器和加速器的讨论请参阅:https://erik-engheim.medium.com/apple-m1-foreshadows-risc-v-dd63a62b2562
苹果的矩阵协处理器和神经网络引擎有何不同?
如果你了解一些关于神经网络引擎的知识,你将会知道它会执行矩阵运算来帮助完成机器学习任务。那么我们为什么还需要矩阵协处理器呢?它们是同一种东西吗?下面我们来解释一下苹果的矩阵协处理器与神经引擎的区别,以及我们为什么需要两者。
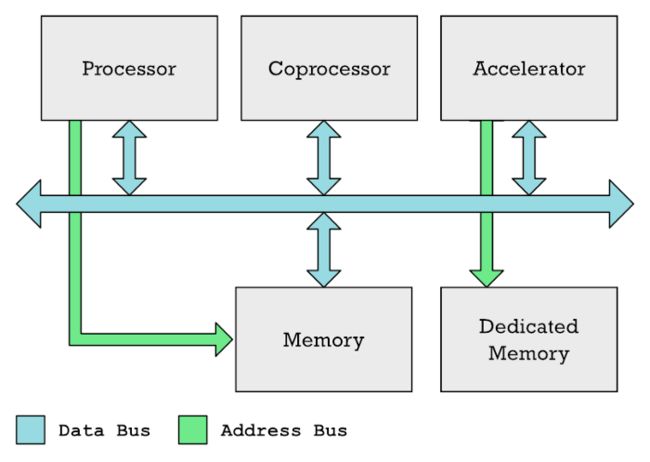
CPU、协处理器和加速器通常可以在共享的数据总线上交换数据。CPU 通常控制内存访问,而专用加速器(例如 GPU)通常具有自己的专用内存(如显存)。
协处理器和加速器并不相同。英伟达显卡中的 GPU 和神经引擎都是加速器的一种。在这两种情况下,都有特殊的内存区域,在该区域 CPU 必须填充要处理的数据,而内存的另一部分则填充加速器应执行的指令列表。CPU 设置这种处理非常耗时。需要进行大量协调,填写数据,然后等待结果。
因此,这只会在更大的任务中得到回报。对于较小的任务,开销太高。
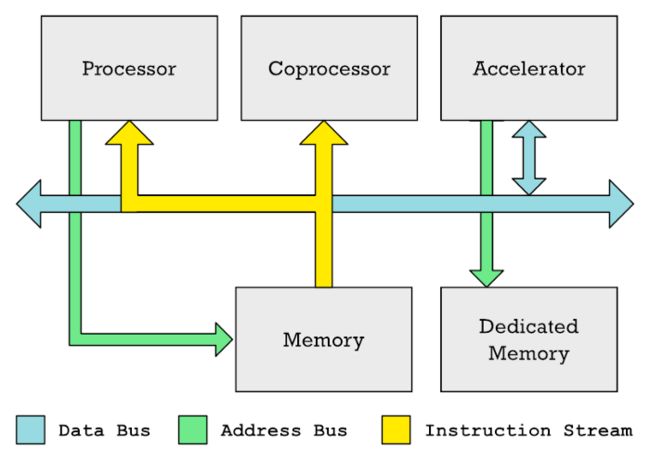
与加速器不同,协处理器监视从内存读取到主处理器的指令流。相比之下,加速器不会遵守 CPU 从内存中提取的指令。
这就是协处理器优于加速器的地方。协处理器会监视从内存 (更具体地说,是缓存) 输入 CPU 的机器代码指令流。协处理器是用来对特定指令作出反应的。与此同时,CPU 通常会忽略这些指令,或者帮助协处理器处理这些指令。
我们从中得到的思路是,协处理器执行的指令可以放在常规代码中。这与 GPU 不同。如果你做过 GPU 编程,则应该知道着色器程序被放置在单独的内存缓冲区中,并且你必须将这些着色器程序显式传输到 GPU。你不能在常规代码中放置特定于 GPU 的指令。因此,对于涉及矩阵处理的较小工作负载,AMX 将优于神经引擎。
这样你需要在微处理器的指令集架构(ISA)中实际定义新的特定的指令。因此,与使用加速器相比,使用协处理器时需要与 CPU 紧密集成。对 ARM 指令集体系架构(ISA)的创建者 ARM 公司来说,长期以来他们一直拒绝向 ISA 中添加自定义指令。
然而,由于客户的压力,ARM 公司放宽了要求,并在 2019 年 10 月做出了让步并宣布将允许扩展。参考:新指令与标准 Arm 指令交织在一起。为了避免软件碎片化并保持一致的软件开发环境,Arm 希望客户在调用的库函数中使用自定义指令。
这可能有助于解释为什么官方文档中没有描述 AMX 指令。ARM 期望苹果将此类指令保存在客户提供的库中。
矩阵协处理器与 SIMD 向量引擎有何不同?
很容易把矩阵协处理器和 SIMD 向量引擎混淆起来,目前大多数现代处理器(包括 ARM 处理器)内都有 SIMD 向量引擎。SIMD(Single Instruction, Multiple Data)即一条指令操作多个数据,是 CPU 基本指令集的扩展,主要用于小体量数据的并行化操作。
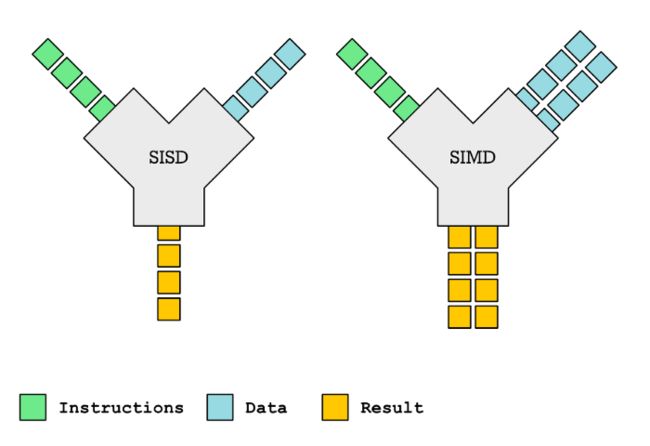
单指令单数据(SISD)VS 单指令多数据(SIMD)
当你需要对多个元素执行相同的操作时,SIMD 是一种获得更高性能的方法。这与矩阵运算密切相关。事实上,SIMD 指令,如 ARM 的 Neon 指令或 Intel x86 SSE 或 AVX 等通常用于加速矩阵乘法。
然而,SIMD 向量引擎是微处理器核心的一部分。就像 ALU(算术逻辑单元)和 FPU(浮点单元)是 CPU 的一部分。在微处理器内部有一个指令解码器,它将拆分一条指令并决定激活哪个功能单元(灰色框)。
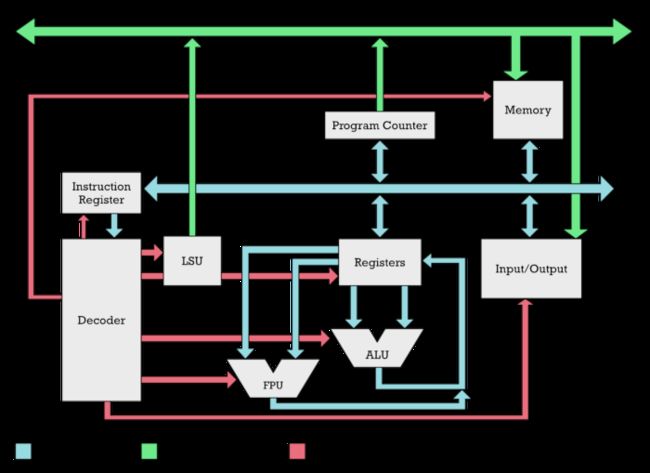
在 CPU 内部,ALU、FPU 以及 SIMD 向量引擎(未显示)作为单独的部分由指令解码器激活。协处理器是外部的。
相反,协处理器在微处理器核心的外部。比如最早的协处理器芯片之一:英特尔 8087,该芯片是一种物理上独立的芯片,旨在加快浮点计算的速度。

英特尔 8087,用于执行浮点运算的早期协处理器之一
对于 8087,你可能会很奇怪,为什么有人会想通过拥有一个像这样的单独芯片来使 CPU 设计复杂化?该芯片必须嗅探从内存到 CPU 的数据流,以查看是否有任何浮点指令。
原因很简单,第一代 PC 中的原始 8086 CPU 包含 29,000 个晶体管。相比之下,8087 要复杂得多,有 45,000 个晶体管。将这两个芯片结合在一起会非常困难和昂贵。
但随着制造技术的进步,将浮点计算单元(FPU)放在 CPU 内部并不是问题。因此 FPU 取代了浮点协处理器。
我们还不清楚为什么 AMX 不是 M1 上 Firestorm 核心的一部分。不管怎样,它们都在同一个硅芯片上。作为协处理器,CPU 继续并行运行可能更容易。苹果可能也喜欢把非标准的 ARM 产品放在 ARM CPU 内核之外。
为什么 AMX 是一个秘密?
如果苹果官方文件中没有描述 AMX,你是怎么知道的?这就多亏了开发人员 Dougall Johnson,他对 M1 进行了逆向工程,发现了这个协处理器。这里描述了他的努力。对于矩阵相关的数学运算,苹果有一些特殊的库或框架,如 Accelerate,它由以下部分组成:
-
vImage:更高层次的图像处理,如格式转换、图像处理等。
-
BLAS:线性代数的一种工业标准(我们称之为处理矩阵和向量的数学)。
-
BNNS:用于运行神经网络和网络训练。
-
vDSP:数字信号处理。傅立叶变换,卷积。这些是在图像处理或真正包括音频的任何信号中很重要的数学运算。
-
LAPACK:更高层次的线性代数函数,例如用于求解线性方程。
Dougall Johnson 知道这些库将使用 AMX 协处理器来加快计算速度。因此,他编写了一些特殊程序来分析和观察这些程序做了什么,以发现未记录的特殊 AMX 机器代码指令。
但是为什么苹果公司不记录这些,让我们直接使用这些指令呢?如前所述,这是 ARM 公司希望避免的。如果自定义指令被广泛使用,它可能会破坏 ARM 生态系统。
然而更重要的是,这对苹果来说是一个优势。通过只允许他们的库使用这些特殊的指令,苹果保留了以后从根本上改变这个硬件工作方式的自由。他们可以删除或添加 AMX 指令。或者他们可以让神经引擎来完成这项工作。无论哪种方式,它们都使开发人员的工作更容易。开发人员只需要使用加速框架,就可以忽略苹果具体如何加快矩阵计算的速度。
这是苹果垂直整合的一大优势。通过控制硬件和软件,他们可以利用这些技术。
苹果的矩阵协处理器有什么优势?
Nod Labs 是一家致力于机器交互、智能和感知的公司,对快速矩阵运算非常感兴趣。其研究人员已经为 AMX 性能测试写了高质量的技术性博客。
博客地址:https://nod.ai/comparing-apple-m1-with-amx2-m1-with-neon/
他们所做的是比较使用 AMX 编写类似代码和使用 Neon 指令编写类似代码的性能,后者得到 ARM 的官方支持。Neon 是一种 SIMD 指令。
Nod Labs 发现,使用 AMX,矩阵的运算性能比 Neon 指令快 2 倍。这并不意味着 AMX 在所有方面都更好,但至少在机器学习和高性能计算(HPC)类型的工作中,我们可以预期 AMX 将在竞争中占据优势。