Python多线程-手慢无的真相
文章目录
- 线程的概念
- 创建多线程
- 主线程
- 阻塞线程
- 线程方法
- 线程同步
-
- 同步的概念
- Python中的锁
- Python中的条件锁
- 小结

我们常说的「手慢无」其实类似多线程同时竞争一个共享资源的结果,要保证结果的唯一正确性,而这让我们从线程(Python)慢慢说起……
线程的概念
线程(Thread)是CPU分配资源的基本单位。一个程序开始运行就变成了一个进程,而一个进程相当于一个或多个线程,使用线程可以实现程序的并发。
一个程序中可以同时运行多个线程,用不同的线程完成不同的任务。
传统的程序设计语言同一时刻只能执行单任务操作,效率很低。比如网络程序在接受数据时发生阻塞,而CPU资源处于闲置状态,只能等到程序接受数据后才能继续运行。
多线程实现后台服务程序可以同时处理多个任务,并不发生阻塞现象。多线程程序设计最大的特点是能够提高程序的执行效率和处理速度。Python程序可同时并行运行多个独立线程。比如开发Email系统,创建一个线程用来接受数据,一个线程用来发送数据,即使发送线程在接受数据时被阻塞,接受数据线程仍然可以运行,互相独立不影响。
Python的线程没有优先级,也不能销毁、停止和挂起、也没有恢复、中断。这和其他语言有所不同。
创建多线程
Python3.X实现多线程的是threading模块,使用它可以创建多线程程序,并且在多线程间进行同步和通讯。
因为是一个模块,所以使用前记得导入:import threading
Python有如下两种方式来创建线程。
一、通过threading.Thread()创建
Thread()语法如下:
threading.Thread(group=None,target=None,name=None,args=(),kwargs=(),*,deamon=None)
- group:必须为None,与ThreadGroup类相关,一般不使用。
- target:目标函数
- name:线程名,默认Thread-x(x从1开始)
- args:为目标函数传递实参、元组
- kwargs:为目标函数传递关键字参数、字典
- daemon:用来设置线程是否随主线程退出而退出
import threading
def test(x,y):
for i in range(x,y):
print(i)
thread1 = threading.Thread(name='t1',target=test,args=(0,5))
thread2 = threading.Thread(name='t2',target=test,args=(5,10))
thread1.start()
thread2.start()
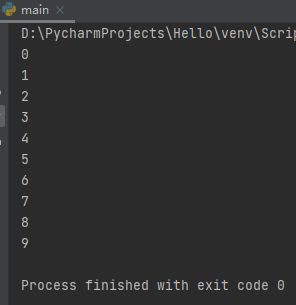
二、通过继承threading.Thread类创建
thread.Thread是一个类,可以使用单继承的方式创建一个自己的子类。
import threading
class mythread(threading.Thread):
def run(self): #重写父类run方法
for i in range(0,5):
print(i)
thread1 = mythread()
thread2 = mythread()
thread1.start()
thread2.start()

如果调用时使用run而不是start,那么run()仅仅时被当作一个普通的函数使用,只有在线程为start时,它才是多线程的一种调用函数。
主线程
介绍主进程前,首先简要介绍下父进程和子进程。如果线程A中启动了一个线程B,那么A就是B的父进程,B就是A的子进程。
Python中,主线程是第一个启动的线程。创建线程时有一个daemon属性可以用来判断主线程,当其值为False时,子进程不会虽主线程退出而退出,反之当其值为True时,如果主进程结束,则它的子进程也会被强制结束。
使用daemon属性几个注意事项:
- 每个进程都有
daemon属性,可以不设置,默认值None - 从主线程创建的所有进程不设置
daemon属性,默认都是False daemon属性必须在start()之前设置,否则会引发RuntimeError- 若子线程不设置
daemon属性,就取当前daemon来设置,子进程继承子进程的daemon值,作用和设置None一样 daemon=True测试并不适用于IDLE环境中的交互模式或脚本运行模式,因为在该环节中的主线程只有在退出Pyhton IDLE时才终止。
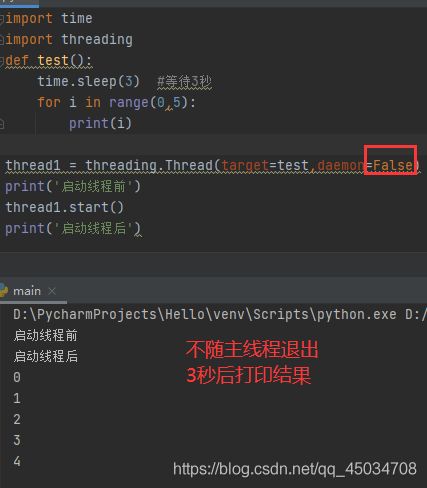
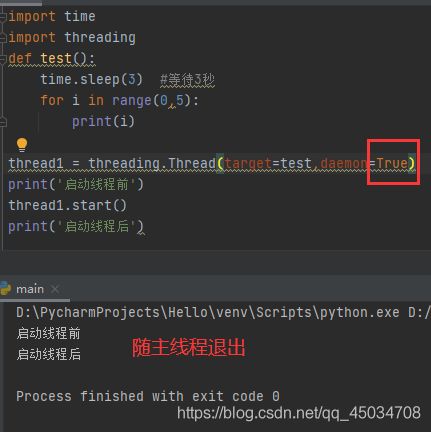
阻塞线程
多线程提供了一个方法join()来阻塞线程,在一个线程中调用另一个线程的join()方法,调用者将被阻塞,直到被调用线程终止。
语法:join(timeout=None)
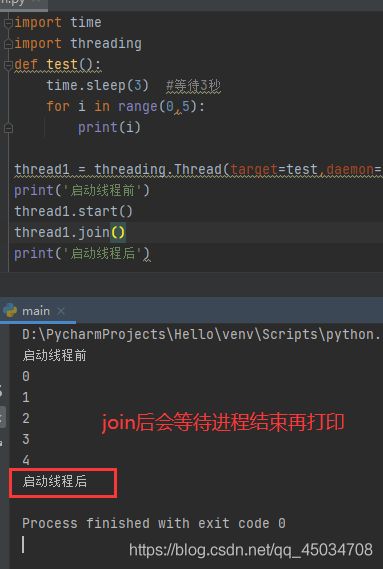
timeout传参是设置超时值,当进程阻塞时间超过该值后,强制结束这个进程。

(
插播反爬信息)博主CSDN地址:https://wzlodq.blog.csdn.net/
线程方法
前面提到的start、join等都是threading.Thread类的方法。
| 方法 | 说明 |
|---|---|
| run | 表示线程活动的方法 |
| start | 启动线程 |
| join | 等待至线程终止 |
| is_alive | 返回线程是否活动 |
| getName | 返回线程名称 |
| setName | 设置线程名称 |
import time
import threading
def test():
time.sleep(3) #等待3秒
for i in range(0,5):
print(i)
thread1 = threading.Thread(target=test)
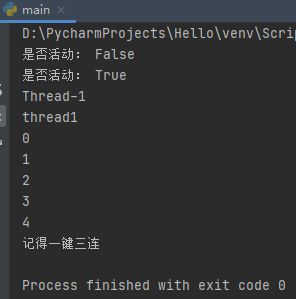
print('是否活动:',thread1.is_alive())
thread1.start()
print('是否活动:',thread1.is_alive())
print(thread1.getName())# 默认threac-x
thread1.setName('thread1')
print(thread1.getName())
thread1.join()
print('记得一键三连')
线程同步
同步的概念
Python应用程序中的多线程可以共享资源,如文件、数据库、内存等。当线程以并发形式访问数据时,共享数据可能会产生冲突。Python引入线程同步的概念,以实现共享数据的一致性。线程同步机制让多个线程有序的访问共享资源,而不是同时操作共享资源。
可以通过购物秒杀的例子来进一步理解同步的概念。比如商品的库存量是1,现在有两个人在平台上同时购买该商品,此时第一个线程查询数据库发现库存量是1可以出售,正准备出售此商品;而同时第二个线程也查询到该商品可以出售并且立即点击购买,这时线程1执行购买时,出现出售两次的错误,大于原库存量1。这就是由于数据不同步导致的错误。(手慢无)
Python中的锁
Python中的threading模块提供了RLock锁(可重入锁)解决方案。一个时间只能让一个线程操作语句放到Rlock的acquire()方法上锁和release()方法解锁。
import threading
class mythread(threading.Thread):
def run(self):
global value # 全局变量
lock.acquire() # 上锁
value+=10 # 设置值
print('%s:%d'%(self.name,value)) # 读取值
lock.release() # 解锁
value = 0 # 初始化
lock=threading.RLock() # 创建可重入锁
thread = [] # 存放线程
for i in range(3): # 创建3个线程
thread.append(mythread())
for i in thread: # 开启线程
i.start()
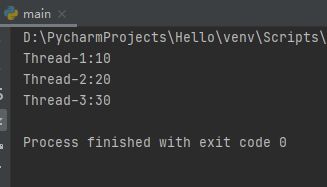
上述代码中,创建了3个线程,为了读取value值时不产生错误,保证输出值正确,使用了RLock锁将设置值和读取值锁起来,以保证线程的同步。
Python中的条件锁
Python的threading还提供了一个方法Conditing(),称为Python中的条件变量。换句话说,这个条件变量必须与一个锁关联,所以也称为条件锁,用于比较复杂的同步。
比如一个线程上锁后、解锁前因为某一条件一直阻塞着,所以就一直解不开锁,其他线程也会一直获取不了锁而导致被迫阻塞着,即所谓的死锁。
这种情况下,变量锁可以让该线程先解锁,然后阻塞着,等待条件满足了再重新唤醒并上锁,这样就不会因为一个线程有问题而影响其他线程了。
条件锁的原理跟设计模式的生产者/消费者模式类似。生产者是一段用于生产的内容,生产的成果供消费者消费,这中间设计一个缓存池用来存储数据,称为仓库。
- 生产者仅仅在仓库未满时生产,仓库满则停止生产。
- 消费者仅仅在仓库有产品时才能消费,空仓则等待。
- 当消费者发现仓库没有产品时可通知生产者生产。
- 生产者生产可消费产品后,应该通知消费者去消费。
条件锁常用方法:
| 方法 | 说明 |
|---|---|
| acquire | 调用关联锁相关方法 |
| release | 解锁 |
| wait | 使线程进入等待池等待通知并解放锁,使用前须获得锁定否则报错 |
| notify | 从等待池挑选一个线程并通知,收到通知的线程将自动调用acquire()尝试获得锁定(进入锁定池);其他线程不会释放锁定,使用前须获得锁定否则报错 |
| notifyAll | 通知等待池中所有线程,这些线程都将进入锁定吃尝试获得锁定,调用这个方法不会释放锁定,使用前须获得锁定否则报错 |
以生产者/消费者为例:
import time
import threading
products = []
condition = threading.Condition()
class Consumer(threading.Thread): # 消费者
def consume(self): # 消费
global condition
global products
condition.acquire() # 上锁
if len(products) == 0: # 判空
condition.wait() # 进入等待池等待通知
print('消费者:没有产品了')
products.pop() # 消费一个产品
print('消费者:已消费一个产品,剩余可消费产品数为'+str(len(products)))
condition.notify() # 通知
condition.release() # 解锁
def run(self):
for i in range(0,10):
time.sleep(3) # 设3秒消费一个产品
self.consume()
class Producer(threading.Thread): # 生产者
def produce(self):
global condition
global products
condition.acquire() # 设置条件锁
if len(products) == 5: # 满仓
condition.wait() # 进入等待池等待通知
print('生产者:已满仓,停止生产')
products.append(1) # 生产一个产品
print('生产者:已生产一个产品,剩余可消费产品数为'+str(len(products)))
condition.notify() # 通知
condition.release() #解锁
def run(self):
for i in range(0,10):
time.sleep(1) # 设1秒生产一个产品
self.produce()
producer = Producer()
consumer = Consumer()
producer.start()
consumer.start()
producer.join()
consumer.join()
上述代码用time.sleep()来控制生产和消费的时间,当产品生产数量达到上限时就停止生产,并调用wait等待线程通知;当剩余可消费产品为0时也停止消费,等待线程通知。

小结
处理大批流程都类似的程序时,使用多线程可以有效节省时间,耗费的不过时一些计算机资源,是典型的以资源换时间,以目前计算机的性能来看,大多都是性能过剩的,理由剩余的计算机资源来节省时间非常合算。
使用多线程是要注意锁的使用,使用锁来保护共享的资源、数据,避免被其他的线程破坏,一般使用互斥锁就可以应付大多数情况了。
Python系列博客持续更新中
原创不易,请勿转载(
本不富裕的访问量雪上加霜)
博主首页:https://wzlodq.blog.csdn.net/
微信公众号:唔仄lo咚锵
如果文章对你有帮助,记得一键三连❤