深入理解希尔排序
>>希尔排序
希尔排序是在插入排序的基础上编写的,由于插入排序元素移动时每次只移动一个位置,所以在数组较大的情况下,效率会很低,因此引入了希尔排序。
希尔排序的思路: 给定一个数组,引入增量,将数组在逻辑上分为几个组,每个组的元素下标相差一个增量,再对这个逻辑上数组进行插入排序。
平均时间复杂度: O(n log n)
最好情况: O(n log^2 n)
最坏情况: O(n log^2 n)
空间复杂度: O(1)
稳定性: 不稳定
幼不晓事,初出牛犊,脑洞大开,写了四种希尔排序,其中第一种是标准按照资料写的,第二种是按照算法给出的思路自己写的,后两种是脑洞大开写的。
: ) 第一种:标准的希尔排序,轮流循环每组元素
代码如下:
/*
* 这是,对每个组轮流插入排序。
*
* 结论:第一种和第二种插入次数相同,但是第二种更加简洁明了。而第一种显得臃肿。
* */
public static void shellSort2(int[] value,int length){
for(int p=length/2;p>0;p/=2){
for(int i=p;i<length;i++){
insertCount2++; //计数用,与算法无关。
int temp=value[i];
int k = i-p;
while(k>=0&&value[k]>temp){
value[k+p]=value[k];
k-=p;
}
value[k+p]=temp;
}
}
}
对每个逻辑组轮流插入排序,其实从代码for(int i=p;i
其中第一层循环中的 p 代表的是增量,利用这个增量分割数组。
这种方式代码简洁明了,看上去很舒服,不亏是经典写法。
: ) 第二种:排完一组,再排另一组
代码如下:
/*
* 这是,对每个组轮流插入排序。
*
* 结论:第一种和第二种插入次数相同,但是第二种更加简洁明了。而第一种显得臃肿。
* */
public static void shellSort2(int[] value,int length){
for(int p=length/2;p>0;p/=2){
for(int i=p;i<length;i++){
insertCount2++; //计数用,与算法无关。
int temp=value[i];
int k = i-p;
while(k>=0&&value[k]>temp){
value[k+p]=value[k];
k-=p;
}
value[k+p]=temp;
}
}
}
这中方式,在逻辑上并没有错误,完全可,但是与第一种想必,就显得臃肿了很多,所以使用优先率肯定没有第一种高。
在实际运行中,我对两种方式插入元素的次数进行了统计,如代码中的insertCount,insertCount2,最中结果是,插入次数完全相等(如下图)。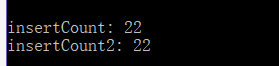
: ) 第三种:自创的,希尔排序二分法版本
温馨提示:内容纯属虚构,请勿模仿 …
代码如下:
/*
* 在第二种基础上使用二分插入排序。
*
* 问题在于:如何找到每组的第一个元素? 可以中 i%p i是当前元素下标,p是增量。
*
* 中间元素如何取?
* */
public static void shellSort3(int[] value,int length){
for(int p=length/2;p>0;p/=2){
for(int i=p;i<length;i++){
int left = i%p;
int right = i-p;
int temp = value[i];
while(left<=right){
/*
* 解析这个式子:
* right-left,得到差值
* (right-left)/p+1,得到left和right之间共有几个数,
* 之所以加1,是因为(right-left)/p,并没有包含left这一项。
* ((right-left)/p+2)/2,得到中间项在第几个,
* 之所是加2,其实包含了两次加1,第一次加1是因为,(right-left)/p除出来,少了第一项,第二次加1是因为,这样除2之后能直接得到中间项。
* (((right-left)/p+1)/2-1)*p,得到中间项的left距中间项的差值
* 之所以要减1,是因为,这个这里计算出来的项数多了left自身。
* 最后加上left,得到中间项的值。
*
* 如:
* 0,3,6,9,12
* 其中:left = 0 , right = 12 , p = 3
* a = right-left = 12;(差值为12)
* b = a/p = 4;
* c = b+2 = 6;(第一次加1等于5,说明共有5项,第二次加1是为了得到中间项3)
* d = c/2 = 3;(第三个为中间项)
* e = d-1 = 2;(left偏移中间项两个增量)
* f = e*p = 6;(偏移量为6)
* g = f+left = 6;
* 最后得到中间项是6
* */
int mid = (((right-left)/p+2)/2-1)*p+left;
if(value[mid]>temp)
right-=p;
else
left+=p;
}
//移动
for(int j=i-p;j>=left;j-=p){
value[j+p]=value[j];
}
value[left]=temp;
}
}
}
当然,完全是能运行的。
改变主要是将前两中的插入部分,改成了二分插入,其中在写的过程,还是遇到很多问题的,其中最大的问题是中间项如何确定?,连吃午饭都在想,最总结出int mid = (((right-left)/p+2)/2-1)*p+left;这个公式,来计算带有增量的中间项。在代码注释中已经给出解释,其实也不难想象。
: ) 第四种:自创的,希尔排序快排版本
温馨提示:内容过于浮夸,请未成年人止步 …
代码如下:
/*
* 在第二种基础上使用快速排序
* */
public static void shellSort4(int[] value,int length){
for(int p=length/2;p>0;p/=2){
for(int i=p;i<length;i++){
quikSort(value,i,p);
}
}
}
public static void quikSort(int[] value,int i,int p){
int start = i%p;
int end = i;
quikSort(value,start,end,p);
}
public static void quikSort(int[] value,int start,int end,int p){
if(start<end){
int i=start-p;
int j=start;
int temp=value[end];
while(j<=end){
if(value[j]<=temp){
i+=p;
swap(value,i,j);
}
j+=p;
}
quikSort(value,start,i-p,p);
quikSort(value,i+p,end,p);
}
}
private static void swap(int[] value,int i,int j){
int temp=value[i];
value[i]=value[j];
value[j]=temp;
}
别,你别乱想,它当然能顺利完成任务!就像调皮捣蛋的孩子喜欢冒险,但他总是知道回家的。
这里对 i 就不再是使用插入排序了,也就是说,现在我把它以及它之前的数当成一个待排数组。
在第一次调用时传入 i 和增量 ,调用的这个函数,只是真正排序函数的重载,它只为了过度到能使用递归函数重载。
最后在实现排序时,要注意的就是对循环数的增减,一定要是用 增量 p。
: ) 运行结果
main函数代码如下:
public static void main(String[] args){
Random rand = new Random();
int length = 10;//Math.abs(rand.nextInt()%1000);
int[] s = new int[length];
for(int i=0;i<length;i++){
s[i] = Math.abs(rand.nextInt()%1000);
}
int[] sc = Arrays.copyOf(s,length);
int[] sd = Arrays.copyOf(s,length);
System.out.println(Arrays.toString(s)+"\n正在排序中...");
long s_time_start=System.nanoTime();
shellSort(s,length);
long s_time_end=System.nanoTime();
long sc_time_start=System.nanoTime();
shellSort2(sc,length);
long sc_time_end=System.nanoTime();
long sd_time_start=System.nanoTime();
shellSort3(sd,length);
long sd_time_end=System.nanoTime();
System.out.println(Arrays.toString(s));
System.out.println("先对一组排序再排另一组所用时间:"+(s_time_end-s_time_start));
System.out.println("每组轮流插入所用时间:"+(sc_time_end-sc_time_start)+" 排序是否成功:"+check(sc,s));
System.out.println("使用二分法所用时间: "+(sd_time_end-sd_time_start)+" 排序是否成功:"+check(sd,s));
//运行希尔排序,快排版本。
int[] se = Arrays.copyOf(s,length);
long se_time_start=System.nanoTime();
shellSort4(se,se.length);
long se_time_end=System.nanoTime();
System.out.println("使用快速排序所用时间:"+(se_time_end-se_time_start)+" 排序是否成功: "+check(se,s));
System.out.println("\n\ninsertCount: "+insertCount+"\ninsertCount2: "+insertCount2);
}
运行结果:(时间单位 纳秒)


以上是部分的运行结果,但是从所有运行情况看的出,他们的优劣很明显。
很明显标准写法是最高效的,而与插入排序关系已经扯的很远的快拍版本效率十分低下,所以虽然看上去有些荒唐的写法,还是给了我好处,那就是强烈的告诉我:希尔排序是对针对插入排序的优化。
所以啊,世间万事无绝对,塞翁失马焉知非福。