Python数据科学学习笔记之——Matplotlib数据可视化
Matplotlib 数据可视化
1、Matplotlib 常用技巧
1.1、导入 Matplotlib
import matplotlib as mpl
import matplotlib.pyplot as plt
1.2、设置绘图样式
我们将使用 plt.style 来选择图形的绘图风格。现在选择经典(classic)风格,这样画出来的图就是经典的 Matplotlib 风格上:
plt.style.use('classic')
1.3、用不用 show()? 如何显示图像
在脚本中画图:那么显示图形的时候必须使用 plt.show()。plt.show() 会启动一个事件循环,并找到所有当前可用的图形对象,然后打开一个或多个交互式窗口显示图形。例如:
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0,10,100)
plt.plot(x,np.sin(x))
plt.plot(x,np.cos(x))
plt.show()

通常一个 Python 会话(session)中只能使用一次 plt.show(),因此通常都把它放在脚本的最后边。多个 plt.show() 命令会导致难以预料的显示异常。
1.4、将图形保存为文件
Matplotlib 的一个优点是能够将图形保存为各种不同的数据格式。你可以用 savefig() 命令将图形保存为文件。例如,如果想将图形保存为 PNG 格式,你可以运行这行代码:
x = np.linspace(0,10,100)
fig = plt.figure()
plt.plot(x,np.sin(x))
plt.plot(x,np.cos(x))
fig.savefig('my_figure.png')

在 savefig() 里面,保存的图片文件格式就是文件的扩展名。Matplotlib 支持许多图形格式,具体格式由操作系统已安装的图形显示接口决定。你可以通过 canvas 对象的方法查看系统支持的文件格式:
print(fig.canvas.get_supported_filetypes())
'''
{'ps': 'Postscript', 'eps': 'Encapsulated Postscript', 'pdf': 'Portable Document Format', 'pgf': 'PGF code for LaTeX', 'png': 'Portable Network Graphics', 'raw': 'Raw RGBA bitmap', 'rgba': 'Raw RGBA bitmap', 'svg': 'Scalable Vector Graphics', 'svgz': 'Scalable Vector Graphics', 'jpg': 'Joint Photographic Experts Group', 'jpeg': 'Joint Photographic Experts Group', 'tif': 'Tagged Image File Format', 'tiff': 'Tagged Image File Format'}
'''
需要注意的是,当你保存图形文件时,不需要使用 plt.show() 或者前面介绍的命令。
2、两种画图接口
2.1、Matlab 风格接口
Matlab 风格的工具位于 pylot(plt) 接口中。
plt.figure() # 创建图形
# 创建两个子图中的第一个,设置坐标轴
plt.subplot(2,1,1) # (行、列、子图编号)
plt.plot(x,np.sin(x))
# 设置两个子图中的第二个,设置坐标轴
plt.subplot(2,1,2) # (行、列、子图编号)
plt.plot(x,np.cos(x))
plt.show()

这种接口最重要的特性是有状态的:它会持续跟踪 “当前的” 图形和坐标轴,所有 plt 命令都可以应用。你可以用 plt.gcf() (获取当前图形)和 plt.gca() (获取当前坐标轴)来查看具体信息。
2.2、面向对象接口
面向对象接口可以适应更复杂的场景,更好地控制你自己的图形。在面向对象接口中,画图函数不再受当前 “活动” 图形或坐标轴的限制,而变成了显式的 Figure 和 Axes 的方法。
# 先创建图形网格
# ax 是一个包含两个 Axes 对象的数组
fig,ax = plt.subplots(2)
# 在每个对象上调用 plot() 方法
ax[0].plot(x,np.sin(x))
ax[1].plot(x,np.cos(x))
plt.show()

3、简易线形图
在所有图形中,最简单的应该就是线性方程 y=f(x) 的可视化了。导入如下命令:
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
import numpy as np
要画 Matplotlib 图形时,都需要先创建一个图形 fig 和一个坐标轴 ax。创建图形与坐标轴的最简单做法如下:
fig = plt.figure()
ax = plt.axes()
plt.show()

在 Matplotlib 里面,figure(plt.Figure 类的一个实例)可以被看成是一个能够容纳各种坐标轴、图形、文字和标签的容器。就像你在图中看到的那样,axes(plt.Axes 类的一个实例)是一个带有刻度和标签的矩形,最终会包含所有可视化的图形元素。
创建好坐标轴后,就可以用 ax.plot 画图了。从一组简单的正弦曲线开始:
fig = plt.figure()
ax = plt.axes()
x = np.linspace(0,10,1000)
ax.plot(x,np.sin(x))
plt.show()
另外也可以用 pylab 接口画图,这时图形与坐标轴都在底层执行:
fig = plt.figure()
ax = plt.axes()
x = np.linspace(0,10,1000)
# ax.plot(x,np.sin(x))
plt.plot(x,np.sin(x))
plt.show()
如果想在一张图中创建多条线,可以重复调用 plot 命令:
fig = plt.figure()
ax = plt.axes()
x = np.linspace(0,10,1000)
# ax.plot(x,np.sin(x))
plt.plot(x,np.sin(x))
plt.plot(x,np.cos(x))
plt.show()

3.1、调整图形:线条的颜色与风格
通常对图形的第一次调整是调整它线条的颜色与风格。plt.plot() 函数可以通过相应的参数设置颜色与风格。要修改颜色,就可以使用 color 参数,它支持各种颜色值的字符串。颜色的不同表示方法如下:
plt.plot(x,np.sin(x - 0),color='blue') # 标准颜色名称
plt.plot(x,np.sin(x - 1),color='g') # 缩写的颜色代码(rgbcmyk)
plt.plot(x,np.sin(x - 2),color='0.75') # 范围在 0~1 之内的灰度值
plt.plot(x,np.sin(x - 3),color='#FFDD44') # 十六进制(RRGGBB,00~FF)
plt.plot(x,np.sin(x - 4),color=(1.0,0.2,0.3)) # RGB 元组,范围在 0~1
plt.plot(x,np.sin(x - 5),color='chartreuse') # HTML 颜色名称

如果不指定颜色,Matplotlib 就会为多条线自动循环使用一组默认的颜色。
与之类似,你也可以用 linestyle 调整线条的风格:
plt.plot(x,x+0,linestyle='solid')
plt.plot(x,x+1,linestyle='dashed')
plt.plot(x,x+2,linestyle='dashdot')
plt.plot(x,x+3,linestyle='dotted')
# plt.plot(x,x+0,linestyle='-') # 实线
# plt.plot(x,x+1,linestyle='--') # 虚线
# plt.plot(x,x+2,linestyle='-.') # 点划线
# plt.plot(x,x+3,linestyle=':') # 点实线

如果你想用一种更简洁的方式,则可以将 linestyle 和 color 编码结合起来,作为 plt.plot() 函数的一个非关键字参数使用:
plt.plot(x,x+0,'-g') # 绿色实线
plt.plot(x,x+1,'--c') # 青色虚线
plt.plot(x,x+2,'-.k') # 黑色点划线
plt.plot(x,x+3,':r') # 红色实点线
这些单字符颜色代码是 RGB(Red/Green/Blue) 与 CMYK(Cyan/Magenta/Yellow/blacK)颜色系统中的标准缩写形式。
3.2、调整图形:坐标轴上下限
调整坐标轴上下限最基础的方法是 plt.xlim() 和 plt.ylim():
plt.plot(x,np.sin(x))
plt.xlim(-1,11)
plt.ylim(-1.5,1.5)

如果想让坐标轴逆序显示,那么也可以逆序设置坐标轴刻度值:
plt.plot(x,np.sin(x))
plt.xlim(10,0)
plt.ylim(1.2,-1.2)

还有一个方法是 plt.axis()。通过传入 [xmin,xmax,ymin,ymax] 对应的值,plt.axis() 方法可以让你用一行代码设置 x 和 y 的限值:
plt.plot(x,np.sin(x))
plt.axis([-1,11,-1.5,1.5])
plt.axis() 能做的可不止如此。它还可以按照图形的内容自动收紧坐标轴,不留空白区域:
plt.plot(x,np.sin(x))
plt.axis('tight')

你还可以实现更高级的配置,例如让屏幕上显示的图形分辨率为 1:1,x 轴单位长度与 y 轴单位长度相等:
plt.axis('equal')
3.3、设置图形标签
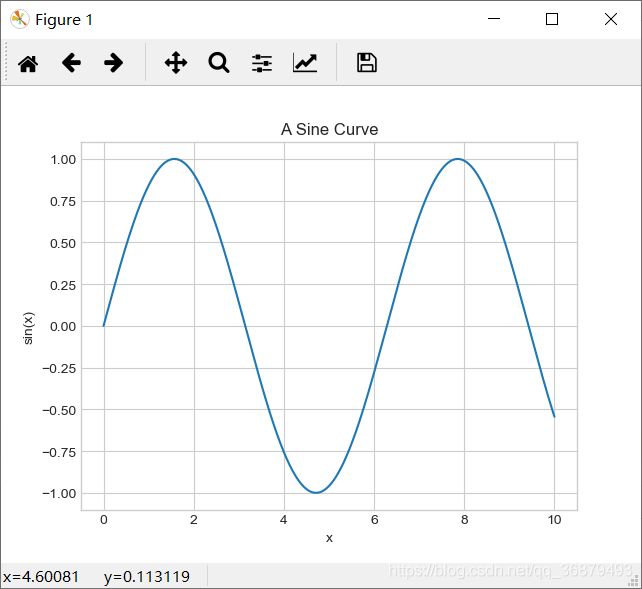
图形标题与坐标轴标签是最简单的标签,快速设置方法如下:
plt.title("A Sine Curve")
plt.xlabel('x')
plt.ylabel('sin(x)')
在单个坐标轴上显示多条线时,创建图例显示每条线是很有效的方法。Matplotlib 内置了一个简单快速的方法,可以用来创建图例,那就是 plt.legend()。然后在 plt.plot 函数中用 label 参数为每条线设置一个标签。
plt.plot(x,np.sin(x),'-g',label='sin(x)')
plt.plot(x,np.cos(x),':b',label='cos(x)')
plt.axis('tight')
plt.legend()

4、简易散点图
这些图形是独立的点、圆圈或其他形状构成。
4.1、用 plt.plot 画散点图
上面介绍了用 plt.plot/ax.plot 画线图的方法,现在用这些函数来画散点图:
x = np.linspace(0,10,30)
y = np.sin(x)
plt.plot(x,y,'o',color='black')

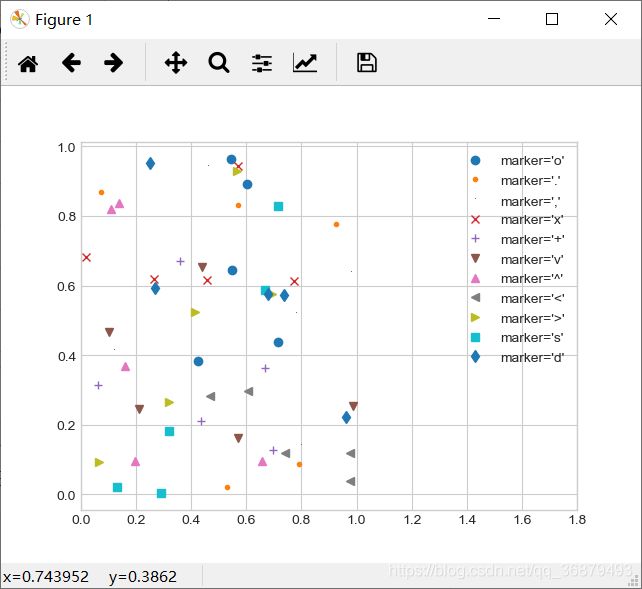
函数的第三个参数是一个字符,表示图形符号类型。绝大部分图形标记都非常直观,在这里演示一部分:
rng = np.random.RandomState(0)
for marker in ['o','.',',','x','+','v','^','<','>','s','d']:
plt.plot(rng.rand(5),rng.rand(5),marker,
label="marker='{0}'".format(marker))
plt.legend(numpoints=1)
plt.xlim(0,1.8)
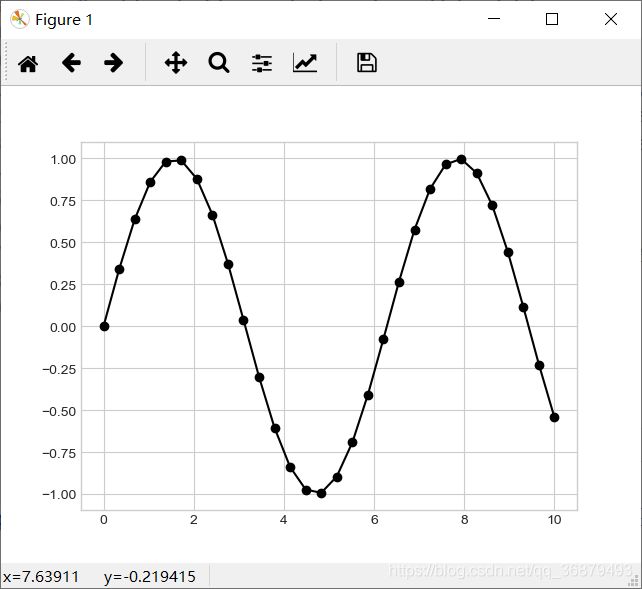
这些代码还可以与线条、颜色代码组合起来,画出一条连接散点的线:
plt.plot(x,y,'-ok') # 直线(-)、圆圈(o)、黑色(k)
4.2、用 plt.scatter 画散点图
另一个可以创建散点图的函数是 plt.scatter。
plt.scatter(x,y,marker='o')

plt.scatter 和 plt.plot 的主要差别在于,前者在创建散点图时具有更高的灵活性,可以单独控制每个散点与数据匹配,也可以让每个散点具有不同的属性(大小、表面颜色、边框颜色等)。
下面创建一个随机散点图,里面有各种颜色和大小的散点。为了能够更好地显示重叠部分、用 alpha 参数来调整透明度:
rng = np.random.RandomState(0)
x = rng.randn(100)
y = rng.randn(100)
colors = rng.rand(100)
sizes = 1000 * rng.rand(100)
plt.scatter(x,y,c = colors,s = sizes,alpha=0.3,cmap='viridis')
plt.colorbar() # 显示颜色条

颜色自动映射成颜色条(通过 colorbar() 显示),散点的大小以像素为单位。这样,散点的颜色与大小就可以在可视化图中显示多维数据的信息了。
例如,可以用 Scikit-Learn 程序库里边的鸢尾花(iris)数据来演示。它里边有三种鸢尾花,每个样本是一种花,其花瓣(petal)与花萼(sepal)的长度与宽度都经过了仔细测量:
from sklearn.datasets import load_iris
iris = load_iris()
features = iris.data.T
plt.scatter(features[0],features[1],alpha=0.2,
s = 100 * features[3],c = iris.target,cmap='viridis')
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1])
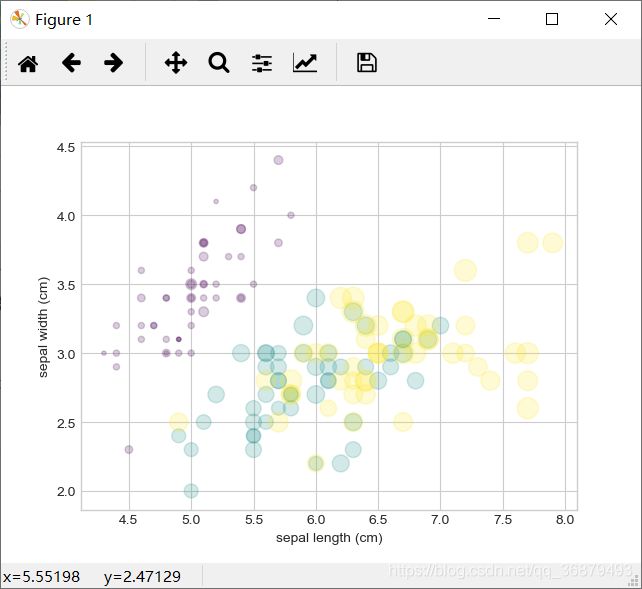
散点图可以让我们同时看到不同维度的数据:每个点的坐标值(x,y)分别表示花萼的长度与宽度,而点的大小表示花瓣的宽度,三种颜色对应三种不同类型的鸢尾花。
5、可视化异常处理
5.1、基本误差线
基本误差线(errorbar)可以通过一个 Matplotlib 函数来创建:
x = np.linspace(0,10,50)
dy = 0.8
y = np.sin(x) + dy * np.random.randn(50)
plt.errorbar(x,y,yerr=dy,fmt='.k')

其中,fmt 是一种控制线条和点的外观的代码格式。除了基本选项之外,errorbar 还有许多改善结果的选项。可以让误差线的颜色比数据点的颜色浅一些效果弧非常好,尤其是在比较密集的图形中:
plt.errorbar(x,y,yerr=dy,fmt='o',color='black',
ecolor='lightgray',elinewidth=3,capsize=0)
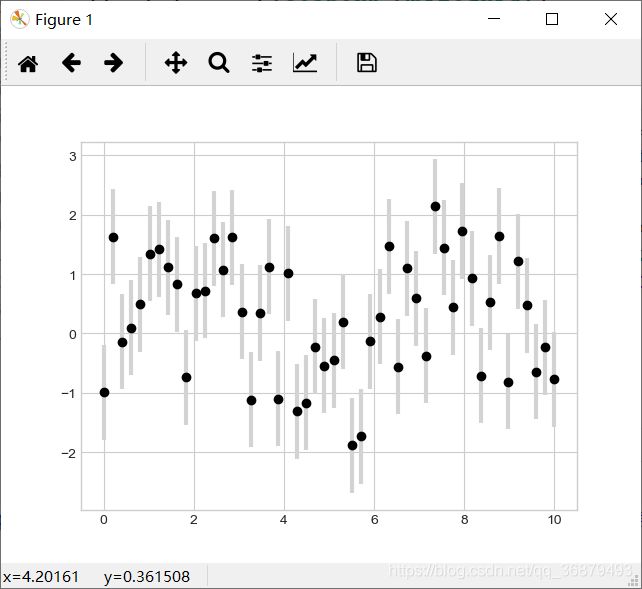
5.2、连续误差
用 Scikit-Learn 程序库 API 里面一个简单的高斯过程回归方法(GPR)来演示。这是一个非参数方程对带有不确定性的连续测量值进行拟合的方法。
from sklearn.gaussian_process import GaussianProcess
# 定义模型和要画的数据
model = lambda x:x * np.sin(x)
xdata = np.array([1,3,5,6,8])
ydata = model(xdata)
# 计算高斯过程拟合结果
gp = GaussianProcess(corr='cubic',theta0=1e-2,thetaL=1e-4,thetaU=1E-1,
random_start=100)
gp.fit(xdata[:,np.newaxis],ydata)
xfit = np.linspace(0,10,1000)
yfit , MSE = gp.predict(xfit[:,np.newaxis],eval_MSE=True)
dyfit = 2 * np.sqrt(MSE) # 2*sigma~95% 置信区间
现在,我们获得了 xfit、yfit 和 dyfit,表示数据的连续拟合结果。接着,如上所示将这些数据传入 plt.errorbar 函数。但是我们并不是真的要为这 1000 个数据点画上 1000 条误差线;相反,可以通过在 plt.fill_betwwen 函数中设置颜色来表示连续误差线。
# 将结果可视化
plt.plot(xdata,ydata,'or')
plt.plot(xfit,yfit,'-',color='gray')
plt.fill_between(xfit,yfit - dyfit,yfit + dyfit,color='gray',alpha=0.2)
plt.xlim(0,10)

6、密度图与等高线图
有时在二维图上用等高线图或者彩色图来表示三维数据是个不错的方法。Matplotlib 提供了三个函数来解决这个问题:用 plt.contour 画等高线图、用 plt.contourf 画带有填充色彩的等高线图的色彩、用 plt.imshow 显示图像。
三维图的可视化
首先用函数 z = f(x,y) 演示一个等高线图,按照下面的方式生成函数 f 样本数据:
def f(x,y):
return np.sin(x) ** 10 + np.cos(10 + y * x) * np.cos(x)
等高线图可以用 plt.contour 函数来创建。它需要三个参数:x 轴、y 轴、z 轴三个坐标轴的网格数据。x 轴与 y 轴表示图形中的位置,而 z 轴将通过等高线的等级来表示。用 np.meshgrid 函数来准备这些数据可能是最简单的方法,它可以从一维数组构建二维网格数据:
x = np.linspace(0,5,50)
y = np.linspace(0,5,50)
X,Y = np.meshgrid(x,y)
Z = f(X,Y)
现在来看看标准的线性等高线图:
plt.contour(X,Y,Z,colors='black')
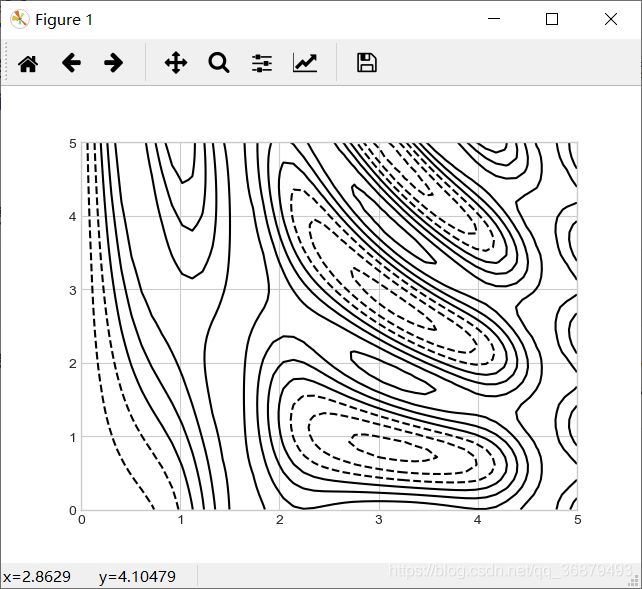
需要注意的是,当图形中只使用一种颜色的时候,默认使用虚线表示负数,使用实线表示正数。另外,你可以使用 cmap 参数设置一个线条配色方法来自定义颜色。还可以让更多的线条显示不同的颜色——可以将数据范围等分为 20 份,然后用不同的颜色表示:
plt.contour(X,Y,Z,20,cmap='RdGy')

现在使用 RdGy(红—灰,Red-Gray 的缩写)配色方案,这对于数据集中度的显示效果比较好。Matplotlib 有非常丰富的配色方案,你可以在浏览 plt.cm 模块。
但是线条之间的间隙还是有点大,可以使用 plt.contourf() 函数来填充等高线图。另外还可以通过 plt.colorbar() 命令自动创建一个表示图形各种颜色对应标签信息的颜色条:
plt.contourf(X,Y,Z,20,cmap='RdGy')
plt.colorbar()

通过颜色条可以清晰地看出,黑色区域是 “波峰”(peak),红色区域是 “波谷”(vally)。
但是图像还有一点不仅如此人意的地方,就是看起来有点 “污渍斑斑”,不是那么干净。这是由于颜色的改变是一个离散而非连续的过程。可以通过 plt.imshow() 函数来处理,它可以将二维数组渲染成渐变图。
plt.imshow(Z,extent=[0,5,0,5],origin='lower',
cmap='RdGy')
plt.colorbar()
plt.axis(aspect='image')

但是,使用 imshow() 函数时应该注意:
- plt.imshow() 不支持用 x 轴和 y 轴数据设置网格,而是必须通过 extent 参数设置图形的坐标范围 [xmin,xmax,ymin,ymax];
- plt.imshow() 默认使用标准的图形数组定义,就是原点位于左上角(浏览器都是如此),而不是绝大不多数等高线图中使用的左下角。这一点在显示网格数据图形时必须调整;
- plt.imshow() 会自动调整坐标轴的精度以适应数据显示。你可以通过 plt.axis(aspect=‘image’) 来设置 x 轴与 y 轴的单位。
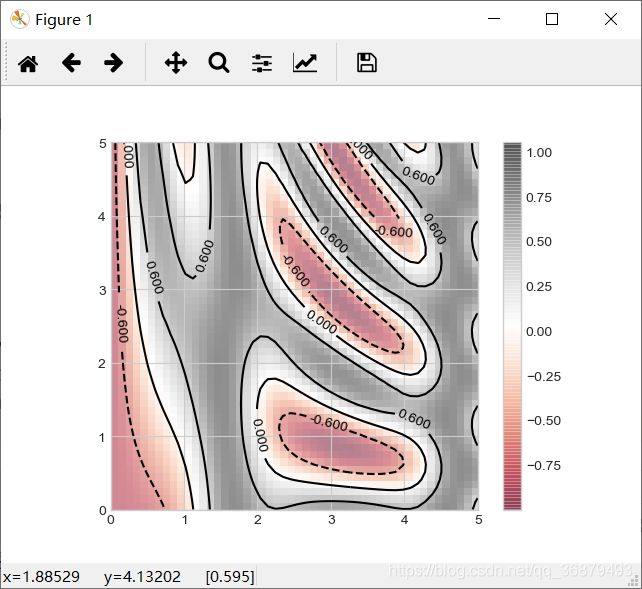
最后还有一个可能会用到的方法,就是将等高线图与彩色图组合起来。例如,如果我们想创建如下的图形,就需要用一幅背景色半透明的彩色图(可以通过 alpha 参数设置透明度),与另一幅坐标轴相同、带数据标签的等高线图叠放在一起(用 plt.clabel() 函数实现):
contours = plt.contour(X,Y,Z,3,colors='black')
plt.clabel(contours,inline=True,frozenset=8)
plt.imshow(Z,extent=[0,5,0,5],origin='lower',cmap='RdGy',alpha=0.5)
plt.colorbar()
7、频次直方图、数据区间划分和分布密度
一个简易的频次直方图可以是理解数据集的良好开端。只要导入画图的函数,只用一行代码就可以创建一个简易的频次直方图。
data = np.random.randn(1000)
plt.hist(data)
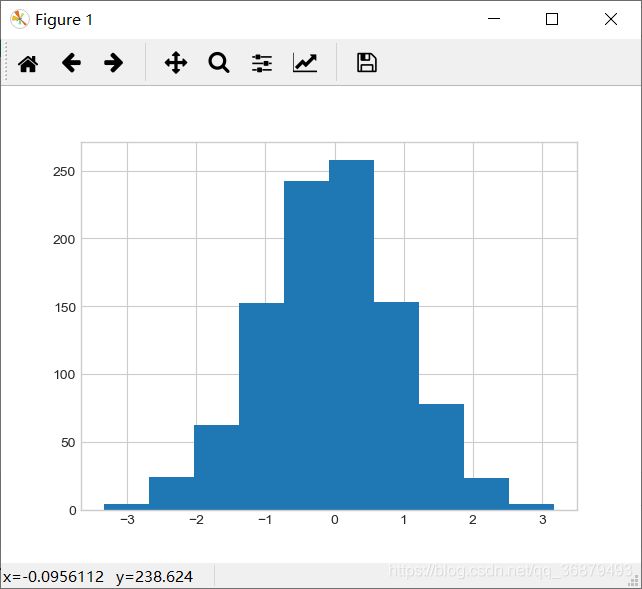
hist() 有许多用来调整计算过程和显示效果的选项,下面是一个更加个性化的频次直方图:
plt.hist(data,bins=30,normed=True,alpha=0.5,
histtype='stepfilled',color='steelblue',
edgecolor='none')
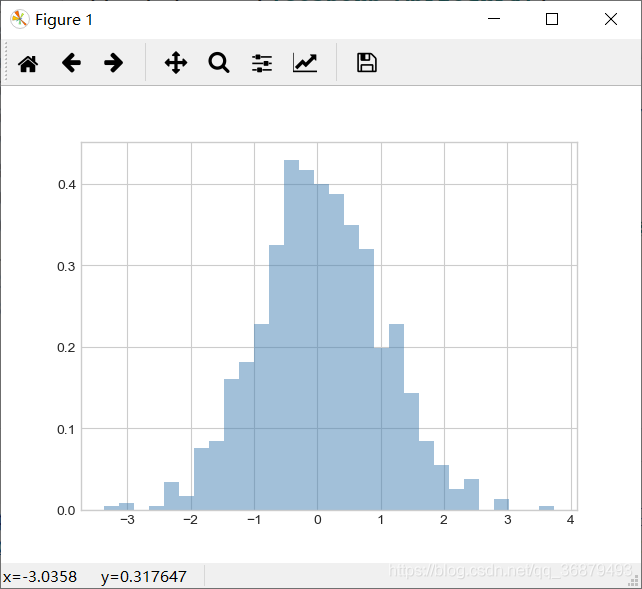
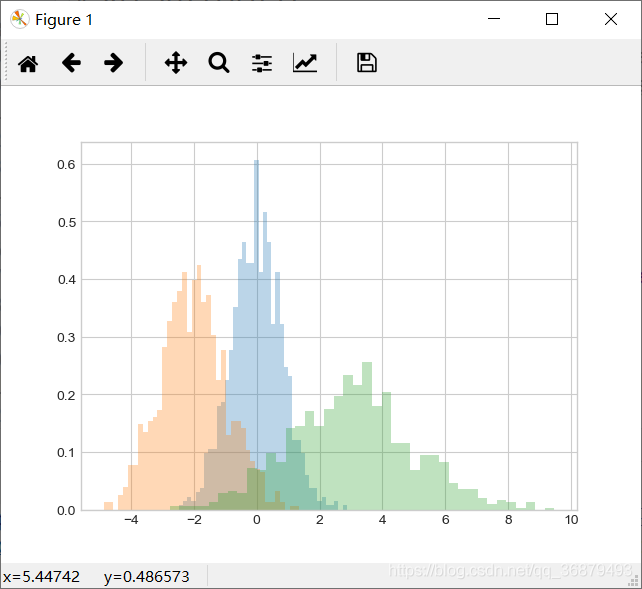
用频次直方图对不同分布特征的样本进行对比时,将 histtype = ‘stepfilled’ 与透明度设置参数 alpha 搭配使用的效果非常好。
x1 = np.random.normal(0,0.8,1000)
x2 = np.random.normal(-2,1,1000)
x3 = np.random.normal(3,2,1000)
kwargs = dict(histtype='stepfilled',alpha=0.3,normed=True,bins=40)
plt.hist(x1,**kwargs)
plt.hist(x2,**kwargs)
plt.hist(x3,**kwargs)
如果只需要简单地计算频次直方图(就是计算每段区间的样本数),而并不想要画图显示他们,那么可以直接用 np.histogram():
counts,bin_edges = np.histogram(data,bins=5)
print(counts) # [ 26 240 512 208 14]
二维频次直方图与数据区间划分
也可以将二维数组按照二维区间进行切分,来创建二维频次直方图。首先,用一个多元高斯分布生成 x 轴与 y 轴的样本数据:
mean = [0,0]
cov = [[1,1],[1,2]]
x,y = np.random.multivariate_normal(mean,cov,10000).T
-
plt.hist2d:二维频次直方图
画二维频次直方图最简单的方法就是使用 Matplotlib 的 plt.hist2d 函数:
mean = [0,0] cov = [[1,1],[1,2]] x,y = np.random.multivariate_normal(mean,cov,10000).T plt.hist2d(x,y,bins=30,cmap='Blues') cb = plt.colorbar() cb.set_label('counts in bin')
-
plt.hexbin:六边形区间划分
二维频次直方图是由坐标轴正交的方块分割而成的,还有一种常用的方式是用正六边形分割。Matplotlib 提供了 plt.hexbin 满足此类需求,将二维数据集分割成蜂窝状:
plt.hexbin(x,y,gridsize=30,cmap='Blues') cb = plt.colorbar(label='counts in bin')
-
核密度估计
还有一种评估多维数据分布密度的常用方法是核密度估计(KDE)。现在先来简单地演示如何使用 KDE 方法 “抹去” 空间中离散的数据点,从而拟合出一个平滑的函数。在 scipy.states 程序包中有一个简单快速的 KDE 实现方法,如下:
from scipy.stats import gaussian_kde # 拟合数组维度[Ndim,Nsample] data = np.vstack([x,y]) kde = gaussian_kde(data) # 用一对规则的网格数据进行拟合 xgrid = np.linspace(-3.5,3.5,40) ygrid = np.linspace(-6,6,40) Xgrid,Ygrid = np.meshgrid(xgrid,ygrid) Z = kde.evaluate(np.vstack([Xgrid.ravel(),Ygrid.ravel()])) # 画出结果图 plt.imshow(Z.reshape(Xgrid.shape), origin='lower',aspect='auto', extent=[-3.5,3.5,-6,6], cmap='Blues') cb = plt.colorbar() cb.set_label('density')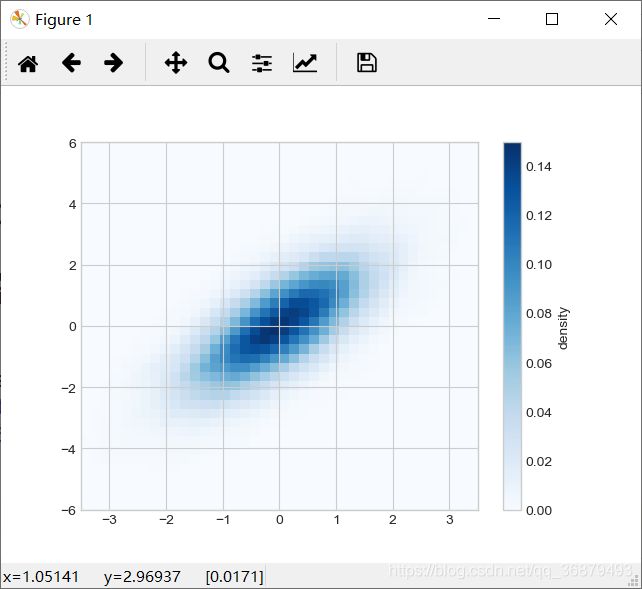
8、配置图例
可以用 plt.legend() 命令来创建最简单的图例,它会自动创建一个包含每个图形元素的图例:
x = np.linspace(0,10,1000)
fig,ax = plt.subplots()
ax.plot(x,np.sin(x),'-b',label='Sine')
ax.plot(x,np.cos(x),'--r',label='Cosine')
ax.axis('equal')
leg = ax.legend()

但是,我们经常需要对图例进行各种个性化配置。例如,我们想要设置图例的位置,并取消外边框:
leg = ax.legend(loc='upper left',frameon=False)
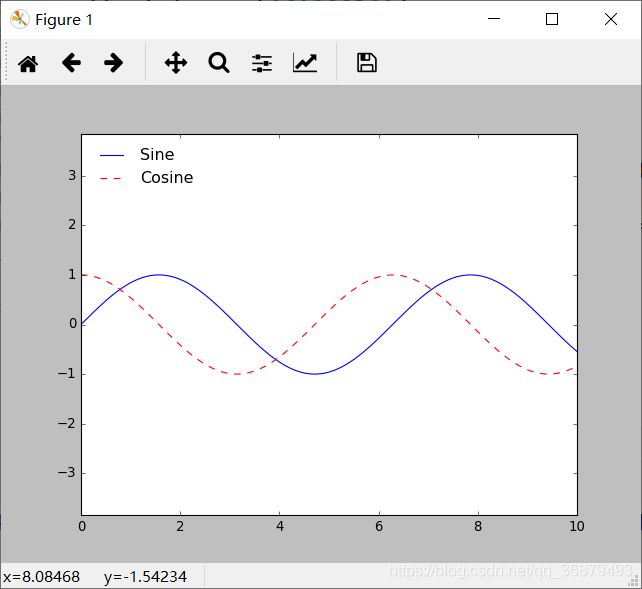
还可以用 ncol 参数设置图例的标签列数:
leg = ax.legend(loc='lower center',frameon=False,ncol=2)

还可以为图例定义圆角边框(fancybox)、增加阴影、改变外边框透明度(framealpha 值),或者改变文字间距:
leg = ax.legend(fancybox=True,framealpha=1,shadow=True,borderpad=1)

8.1、选择图例显示的元素
图例会默认显示所有元素的标签。如果你不想显示全部,可以通过一些图形命令来指定显示图例中的哪些元素和标签。plt.plot() 命令可以一次创建多条线,返回线条示例列表。一种方法是将需要显示的线条传入 plt.legned(),另一种方法是只为需要在图例中显示的线条设置标签:
y = np.sin(x[:,np.newaxis] + np.pi * np.arange(0,2,0.5))
lines = plt.plot(x,y)
# lines 变量是一组 plt.Line2D 实例
plt.legend(lines[:2],['first','second'])
在实践中,发现第一种方法更清晰。当然也可以只为需要在图例中显示的元素设置标签:
plt.plot(x,y[:,0],label='first')
plt.plot(x,y[:,1],label='second')
plt.plot(x,y[:,2:])
plt.legend(framealpha=1,frameon=True)

需要注意的是,默认情况下图例会自动忽略那些不带标签的元素。
8.2、在图例中显示不同尺寸的点
可能需要不同尺寸的点来表示数据的特征,并且希望创建这样的图例来反映这些特征。下面的示例将用点的尺寸来表明美国加州不同城市的人口数量。如果我们想要一个通过尺寸的点显示不同人口数量级的图例,可以通过隐藏一些数据标签来实现这个效果:
for area in [100,300,500]:
plt.scatter([],[],c='k',alpha=0.3,s=area,label=str(area) + ' km$^2$')
plt.legend(scatterpoints=1,frameon=False,labelspacing=1,title='City Area')
8.3、同时显示多个图例
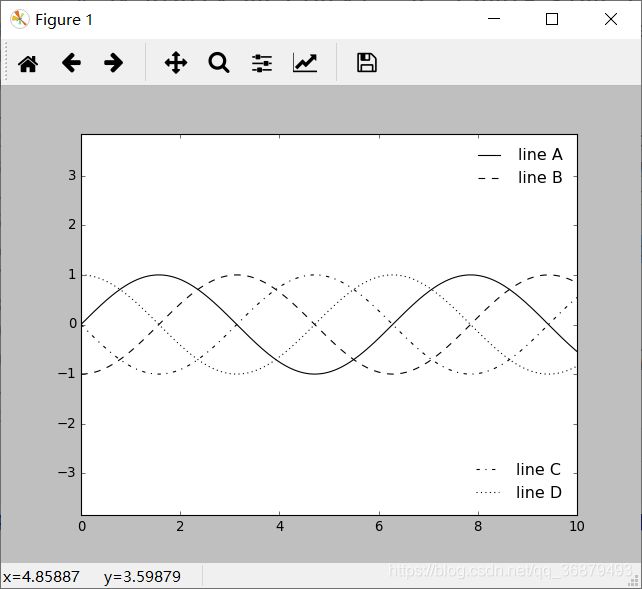
我们可能需要在同一张图上显示多个图例。不过,用 Matplotlib 解决这个问题并不容易,因为通过标准的 legend 接口只能为一张图创建一个图例。如果你想用 plt.legend() 或 ax.legend() 方法创建第二个图例,那么第一个图例就会被覆盖。但是,我们可以通过从头开始创建一个新的图例艺术家对象(legend artist),然后用底层的(lower-level)ax.add_artist() 方法在图上添加第二个图例:
ig,ax = plt.subplots()
lines = []
styles = ['-','--','-.',':']
x = np.linspace(0,10,1000)
for i in range(4):
lines += ax.plot(x,np.sin(x - i * np.pi / 2),
styles[i],color='black')
ax.axis('equal')
# 设置第一个图例要显示的线条和标签
ax.legend(lines[:2],['line A','line B'],
loc='upper right',frameon=False)
# 创建第二个图例,通过 add_artist 方法添加到图上
from matplotlib.legend import Legend
leg = Legend(ax,lines[2:],['line C','line D'],
loc='lower right',frameon=False)
ax.add_artist(leg)
9、配置颜色条
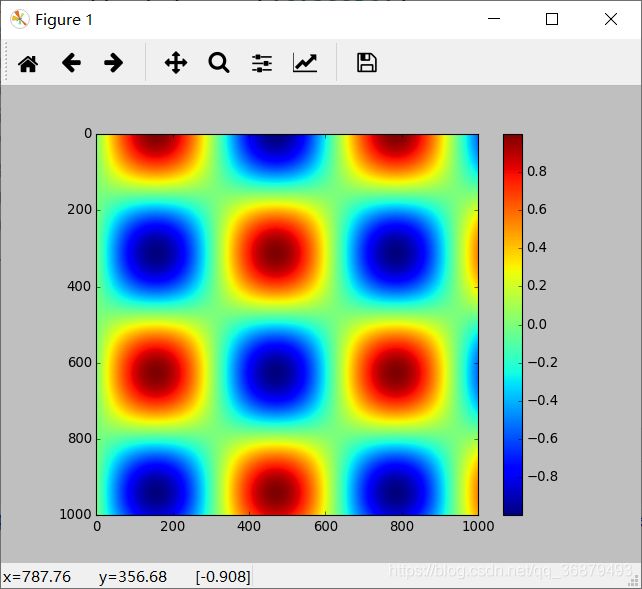
颜色条是一个独立的坐标轴,可以指明图形中颜色的含义。通过 plt.colorbar 就可以创建最简单的颜色条:
x = np.linspace(0,10,1000)
I = np.sin(x) * np.cos(x[:,np.newaxis])
plt.imshow(I)
plt.colorbar()
9.1、配置颜色条
可以通过 cmap 参数为图形设置颜色条的配色方案:
plt.imshow(I,cmap='gray')
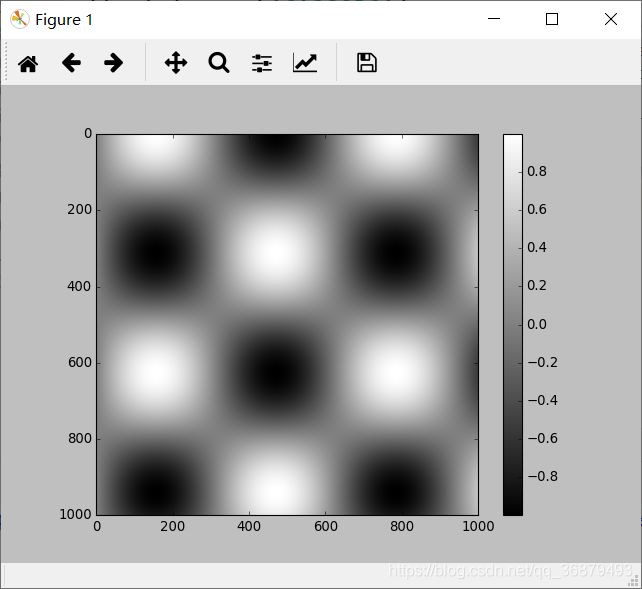
所有可用的配色方案都在 plt.cm 命名空间里。
如何确定用哪种方案?
-
选择配色方案
一般情况下,你只需要关注三种不同的配色方案:
-
顺序配色方案
由一组连续的颜色构成的配色方案(例如 binary 或 viridis)
-
互逆配色方案
通常由两种互补的颜色构成,表示正反两种含义(例如 RdBu 或 PuOr)
-
定性配色方案
随机顺序的一组颜色(例如 rainbow 或 jet)
-
-
颜色条刻度的限制与扩展功能的设置
由于可以将颜色条本身看作是一个 plt.Axes 实例,因此前面所学的所有关于坐标轴和刻度值的格式配置技巧都可以派上用场。颜色条有一些有趣的特性。例如,我们可以缩短颜色取值的上下限,对于超出上下限的数据,通过 extend 参数用三角箭头表示上限大的数或者下限小的数。比如,你想展示一张噪点图:
# 为图像像素设置 1% 噪点 speckles = (np.random.random(I.shape) < 0.01) I[speckles] = np.random.normal(0,3,np.count_nonzero(speckles)) plt.figure(figsize=(10,3.5)) plt.subplot(1,2,1) plt.imshow(I,cmap='RdBu') plt.colorbar() plt.subplot(1,2,2) plt.imshow(I,cmap='RdBu') plt.colorbar(extend='both') plt.clim(-1,1)
左图是用默认的颜色条刻度限制实现的效果,噪点的范围完全覆盖了我们感兴趣的数据。而右边的图形设置了颜色条的刻度上下限,并在上下限之外增加了扩展功能,这样的数据可视化图形显然更有效果。
-
离散型颜色条
虽然颜色条默认都是连续的,但有时你可能也需要表示离散数据。最简单的做法就是使用 plt.cm.get_cmap() 函数,将适当的配色方案的名称以及需要的区间数量传进去即可:
plt.imshow(I,cmap=plt.cm.get_cmap('Blues',6)) plt.colorbar() plt.clim(-1,1)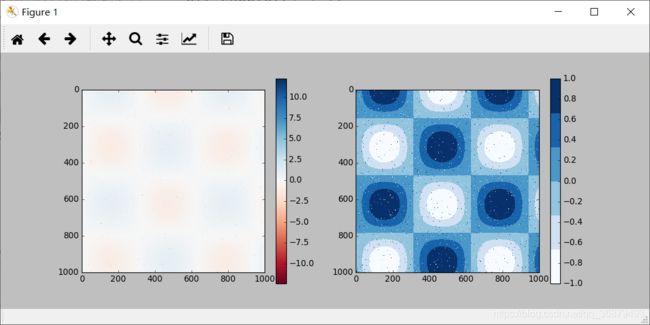
9.2、案例:手写数字
数据在 Scikit-Learn 里面,包含近 2000 份 8 × 8 的手写数字缩略图。
先下载数据,然后用 plt.imshow() 对一些图形进行可视化:
# 加载数字 0~5 的图形,对其进行可视化
from sklearn.datasets import load_digits
digits = load_digits(n_class=6)
fig,ax = plt.subplots(8,8,figsize=(6,6))
for i,axi in enumerate(ax.flat):
axi.imshow(digits.images[i],cmap='binary')
axi.set(xticks=[],yticks=[])

由于每个数字都由 64 像素的色相(hue)构成,因此可以将每个数字看成是一个位于 64 维空间的点,即每个维度表示一个像素的亮度。但是想通过可视化来描述如此高维度的空间是非常困难的。一种解决方案就是降维技术,在尽量保留数据内部重要关联性的同时降低数据的维度,例如流形学习。降维是无监督学习的重要内容。
利用流形学习如何将这些数据投影到二维空间进行可视化:
# 用 IsoMap 方法将数字投影到二维空间
from sklearn.manifold import Isomap
iso = Isomap(n_components=2)
projection = iso.fit_transform(digits.data)
我们将用离散型颜色条来显示结果,调整 ticks 与 clim 参数来改善颜色条:
# 画图
plt.scatter(projection[:,0],projection[:,1],lw=0.1,
c=digits.target,cmap=plt.cm.get_cmap('cubehelix',6))
plt.colorbar(ticks=range(6),label='digit value')
plt.clim(-0.5,5.5)

10、多子图
10.1、plt.axes:手动创建子图
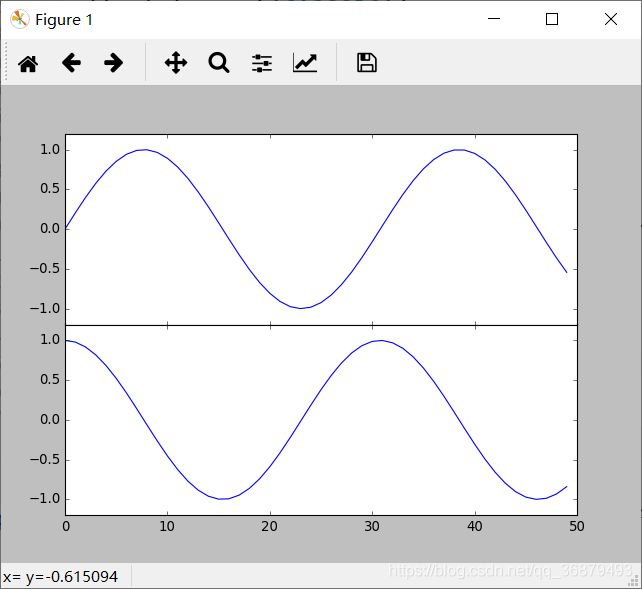
创建坐标轴最基本的方法就是使用 plt.axes 函数。前面介绍过,这个函数的默认配置是创建一个标准的坐标轴,填满整张图。它还有一个可选参数,由图形坐标轴的四个值构成。这四个值分别表示图形坐标系统的 [bottom,left,width,height](底坐标、左坐标、宽度、高度),数值的取值范围是左下角(原点)为 0,右上角为 1。
如果想在右上角创建一个画中画,那么可以首先将 x 与 y 设置为 0.65(就是坐标轴原点位于图形高度 65% 和宽度 65% 的位置),然后将 x 与 y 扩展到 0.2(也就是将坐标轴的宽度与高度设置为图形的 20%),如图:
ax1 = plt.axes() # 默认坐标轴
ax2 = plt.axes([0.65,0.65,0.2,0.2])

面向对象画图接口中类似的命令有 fig.add_axes()。用这个命令创建两个竖直排列的坐标轴:
fig = plt.figure()
ax1 = fig.add_axes([0.1,0.5,0.8,0.4],
xticklabels=[],ylim=(-1.2,1.2))
ax2 = fig.add_axes([0.1,0.1,0.8,0.4],
ylim=(-1.2,1.2))
x = np.linspace(0,10)
ax1.plot(np.sin(x))
ax2.plot(np.cos(x))
10.2、plt.subplot:简易网格子图
若干彼此对齐的行列子图是常见的可视化任务,Matplotlib 拥有一些可以轻松创建它们的简便方法。最底层的就是用 plt.subplot() 在一个网格中创建一个子图。这个命令有三个整型参数——将要创建的网格子图行数、列数和索引数,索引值从 1 开始,从右上角到右下角一次增大。
for i in range(1,7):
plt.subplot(2,3,i)
plt.text(0.5,0.5,str((2,3,i)),
fontsize=18,ha='center')

plt.subplots_adjust 命令可以调整子图之间的间隔。用面向对象接口命令 fig.add_subplot() 可以获得同样的结果:
fig = plt.figure()
fig.subplots_adjust(hspace=0.4,wspace=0.4)
for i in range(1,7):
ax = fig.add_subplot(2,3,i)
ax.text(0.5,0.5,str((2,3,i)),
fontsize=18,ha='center')

我们通过 plt.subplots_adjust 的 hspace 与 wspace 参数设置与图形高度与宽度一致的子图间距,数值以子图的尺寸为单位。(本例中,间距是子图宽度与高度的 40%)
10.3、plt.subplots:用一行代码创建网格
这个函数不是用来创建单个子图的,而是用一行代码创建多个子图,并返回一个包含子图的 NumPy 数组。关键参数是行数与列数,以及可选参数 sharex 与 sharey,通过他们可以设置不同子图之间的关联关系。
我们将创建一个 2 × 3 网格子图,每行的 3 个子图使用相同的 y 轴坐标,每列的 2 个子图使用相同的 x 轴坐标:
fig,ax = plt.subplots(2,3,sharex='col',sharey='row')

设置 sharex 与 sharey 参数之后,我们就可以自动去掉网格内部子图的标签,让图形看起来更整洁。坐标轴实例网格返回的结果是一个 NumPy 数组,这样就可以通过标准的数组取值方式轻松获取想要的坐标轴了:
# 坐标轴存放在一个 NumPy 数组中,按照 [row,col] 取值
for i in range(2):
for j in range(3):
ax[i,j].text(0.5,0.5,str((i,j)),
fontsize=18,ha='center')
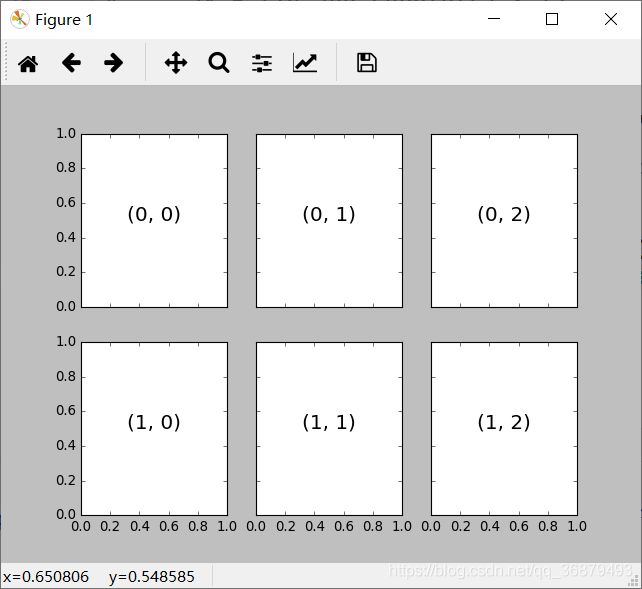
注意,这个索引是从 0 开始的。
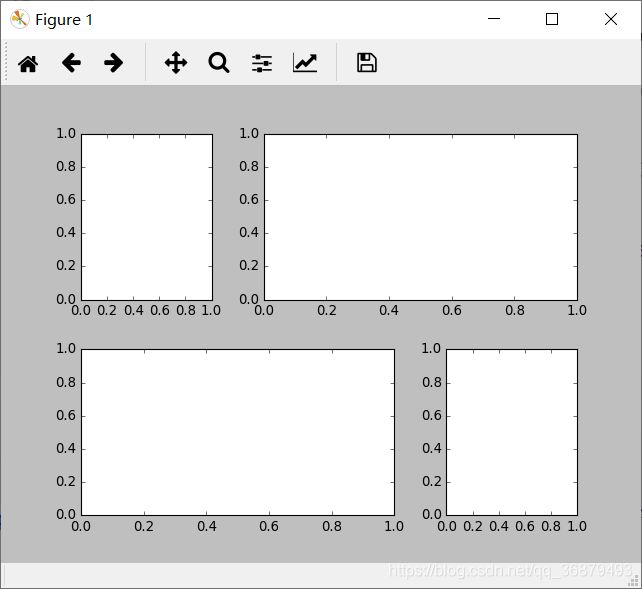
10.4、plt.GridSpec:实现更复杂的排列方式
如果想实现不规则的多行多列子图网格,plt.GridSpec() 是最好的工具。plt.GridSpec() 对象本身不能直接创建一个图形,它只是 plt.subplot() 命令可以识别的简易接口。例如,一个带行列间距的 2 × 3 网格的配置代码如下:
grid = plt.GridSpec(2,3,wspace=0.4,hspace=0.3)
可以通过类似 Python 切片的语法设置子图的位置和扩展尺寸:
plt.subplot(grid[0,0])
plt.subplot(grid[0,1:])
plt.subplot(grid[1,:2])
plt.subplot(grid[1,2])
11、自定义坐标轴刻度
虽然 Matplotlib 默认的坐标轴定位器(locator)与格式生成器(formatter)可以满足大部分需求,但是并非对每一幅图都适合。
Matplotlib 的目标是用 Python 对象表现任意的图形元素。例如,想想前面介绍的 figure 对象,它其实就是一个盛放图形元素的包围盒(bounding box)。可以将每个 Matplotlib 对象都看成是子对象(sub-object)的容器。例如,每个 figure 都会包含一个或多个 axes 对象,每个 axes 对象又会包含其他表示图形内容的对象。
坐标轴也不例外,每个 axes 都有 xaxis 和 yaxis 属性,每个属性同样包含构成坐标轴的线条、刻度和标签全部属性。
11.1、主要刻度与次要刻度
每一个坐标轴都会有主要刻度与次要刻度。顾名思义,主要刻度往往更大或更显著,而次要刻度往往更小。
ax = plt.axes(xscale='log',yscale='log')
11.2、隐藏刻度与标签
最常用的刻度/标签化操作可能就是隐藏刻度与标签了,可以通过 plt.NullLocator() 与 plt.NullFormatter() 实现,如下:
ax = plt.axes()
ax.plot(np.random.rand(50))
ax.yaxis.set_major_locator(plt.NullLocator())
ax.xaxis.set_major_formatter(plt.NullFormatter())
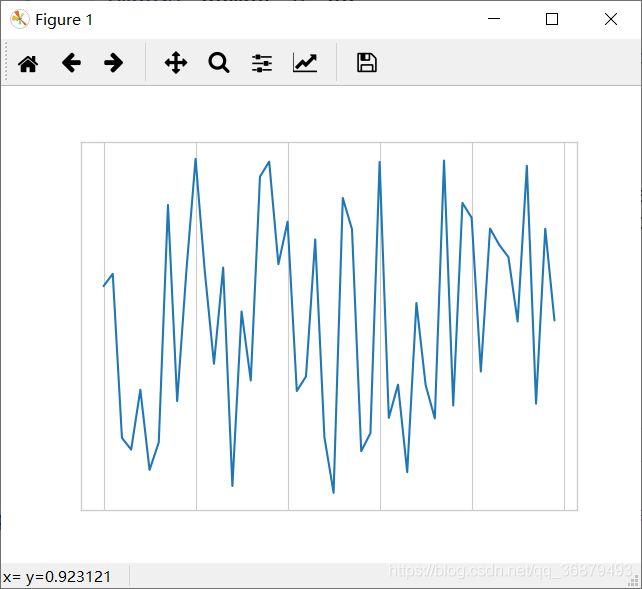
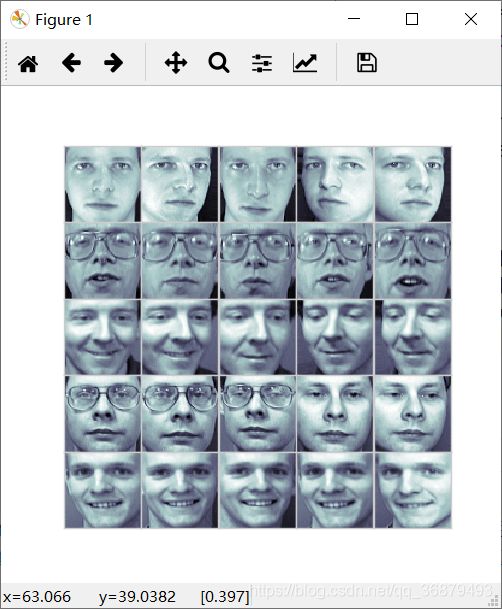
我们移除了 x 轴的标签(但是保留了刻度线/网格线),以及 y 轴的刻度(标签页一并移除)。在许多场景中都不需要刻度线,比如当你需要显示一组图形时。举个例子,包含不同人脸的照片,就是经常用于研究有监督机器学习问题的示例:
fig,ax = plt.subplots(5,5,figsize=(5,5))
fig.subplots_adjust(hspace=0,wspace=0)
# 从 scikit-learn 获取一些人脸照片数据
from sklearn.datasets import fetch_olivetti_faces
faces = fetch_olivetti_faces().images
for i in range(5):
for j in range(5):
ax[i, j].xaxis.set_major_locator(plt.NullLocator())
ax[i, j].yaxis.set_major_locator(plt.NullLocator())
ax[i, j].imshow(faces[10 * i + j],cmap='bone')
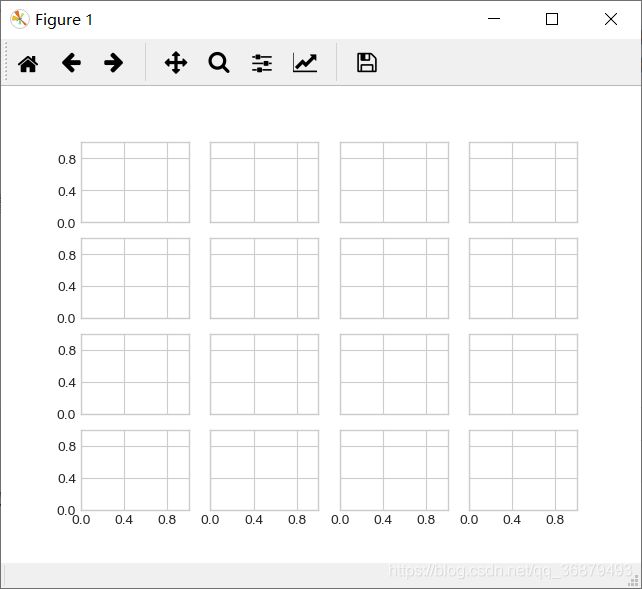
11.3、增减刻度数量
可以设置最多刻度数量,Matplotlib 会自动为刻度安全牌恰当的位置:
fig, ax = plt.subplots(4,4,sharex=True,sharey=True)
# 为每个坐标轴设置主要的刻度定位器
for axi in ax.flat:
axi.xaxis.set_major_locator(plt.MaxNLocator(3))
axi.yaxis.set_major_locator(plt.MaxNLocator(3))
11.4、花哨的刻度格式
一个例子,如下图的正弦曲线和余弦曲线:
# 画正弦曲线和余弦曲线
fig, ax = plt.subplots()
x = np.linspace(0,3 * np.pi,1000)
ax.plot(x,np.sin(x),lw=3,label='Sine')
ax.plot(x,np.cos(x),lw=3,label='Cosine')
# 设置网格、图例和坐标轴上下限
ax.grid(True)
ax.legend(frameon=False)
ax.axis('equal')
ax.set_xlim(0,3 * np.pi)

我们可以稍稍改变一下这幅图。首先,如果刻度与网格线画在 π 的倍数上,图形会更加自然。可以通过设置一个 MultipleLocator 来实现,它可以将刻度放在你提供的数值的倍数上。为了更好地测量,在 π/4 的倍数上添加主要刻度和次要刻度:
ax.axis('equal')
ax.xaxis.set_major_locator(plt.MultipleLocator(np.pi / 2))
ax.xaxis.set_minor_locator(plt.MultipleLocator(np.pi / 4))
ax.set_xlim(0,3 * np.pi)

11.5、格式生成器与定位器小结
| 定位器类 | 描述 |
|---|---|
| NullLocator | 无刻度 |
| FixedLocator | 刻度位置固定 |
| IndexLocator | 用索引作为定位器(如 x = range(len(y))) |
| LinearLocator | 从 min 到 max 均匀分布刻度 |
| LogLocator | 从 min 到 max 按对数分布刻度 |
| MultipleLocator | 刻度和范围都是基数(base)的倍数 |
| MaxNLocator | 为最大刻度找到最优位置 |
| AutoLocator | (默认)以 MaxNLocator 进行简单配置 |
| AutoMinorLocator | 次要刻度的定位器 |
| 格式生成器类 | 描述 |
|---|---|
| NullFormatter | 刻度上无标签 |
| IndexFormatter | 将一组标签设置为字符串 |
| FixedFormatter | 手动为刻度设置标签 |
| FuncFormatter | 用自定义函数设置标签 |
| FormatStrFormatter | 为每个刻度值设置字符串格式 |
| ScalarFormatter | (默认)为标量值设置标签 |
| LogFormatter | 对数坐标轴的默认格式生成器 |
12、Matplotlib 自定义:配置文件与样式表
12.1、手动配置图形
例子,一个默认配置生成的直方图:
x = np.random.randn(1000)
plt.hist(x)
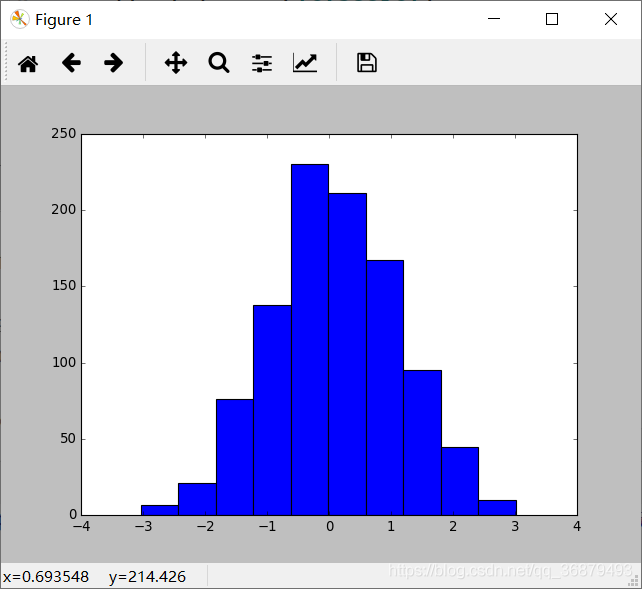
通过手动调整,可以让它更美观:
# 用灰色背景
ax = plt.axes(facecolor='#E6E6E6')
ax.set_axisbelow(True)
# 画上白色的网格线
plt.grid(color='w',linestyle='solid')
# 隐藏坐标轴的线条
for spine in ax.spines.values():
spine.set_visible(False)
# 隐藏上边与右边的刻度
ax.xaxis.tick_bottom()
ax.yaxis.tick_left()
# 弱化刻度与标签
ax.tick_params(colors='gray',direction='out')
for tick in ax.get_xticklabels():
tick.set_color('gray')
for tick in ax.get_yticklabels():
tick.set_color('gray')
# 设置频次直方图轮廓色与填充色
ax.hist(x,edgecolor='#E6E6E6',color='#EE6666')

12.2、修改默认配置
Matplotlib 每次加载时,都会中定义一个运行时配置(rc),其中包含了所有你创建的图形元素的默认风格。你可以用 plt.rc 简便方法随时修改这个配置。调整 rc 参数,用默认图形实现之前手动调整的结果。
先复制一下目前的 rcParams 字典,这样可以在修改之后再修改还原回来:
IPython_default = plt.rcParams.copy()
现在就可以用 plt.rc 函数来修改配置参数了:
from matplotlib import cycler
colors = cycler('color',
['#EE6666','#3388BB','#9988DD',
'#EECC55','#88BB44','#FFBBBB'])
plt.rc('axes',facecolor='#E6E6E6',edgecolor='none',
axisbelow=True,grid=True,prop_cycle=colors)
plt.rc('grid',color='w',linestyle='solid')
plt.rc('xtick',direction='out',color='gray')
plt.rc('ytick',direction='out',color='gray')
plt.rc('patch',edgecolor='3E6E6E6')
plt.rc('lines',linewidth=2)

再画一些线图看看 rc 参数的效果:
for i in range(4):
plt.plot(np.random.rand(10))

12.3、样式表
style 模块里边包含了大量的新式默认样式表,还支持创建和打包你自己的风格。虽然这些样式表实现的格式功能与前面介绍的 .matplotlibrc 文件类似,但是它的文件扩展名是 .mplstyle。
通过 plt.style.available 命令可以看到所有可用的风格,下面介绍前五种风格:
import matplotlib.pyplot as plt
print(plt.style.available[:5])
# ['bmh', 'classic', 'dark_background', 'fast', 'fivethirtyeight']
使用某种样式表的基本方法如下:
plt.style.use('stylename')
但需要注意的是,这样会改变后面所有的风格!如果需要,你可以使用风格上下文管理器(context manager)临时更换至另一种风格:
with plt.style.context('stylename'):
make_a_plot()
来创建一个可以画两种基本图形的函数:
def hist_and_lines():
np.random.seed(0)
fig, ax = plt.subplots(1,2,figsize=(11,4))
ax[0].hist(np.random.randn(1000))
for i in range(3):
ax[1].plot(np.random.rand(10))
ax[1].legend(['a','b','c'],loc='lower left')
-
默认风格
将之前设置的运行时配置还原为默认配置:
# 重置 rcParams plt.rcParams.update(IPython_default)来看看默认风格的效果:
hist_and_lines()
-
FiveThirtyEight 风格
这种风格使用深色的粗线条和透明的坐标轴:
with plt.style.context('fivethirtyeight'): hist_and_lines()
-
ggplot 风格
with plt.style.context('ggplot'): hist_and_lines()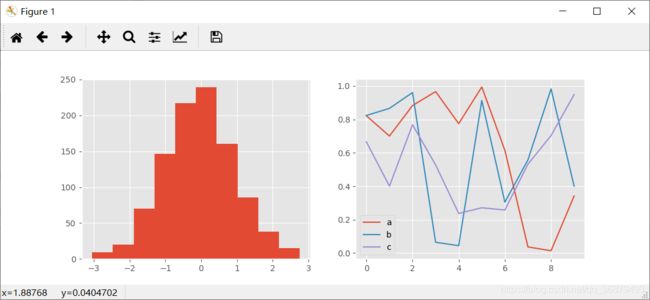
-
bmh 风格
with plt.style.context('bmh'): hist_and_lines()
-
黑色背景风格
with plt.style.context('dark_background'): hist_and_lines()
-
灰度风格
with plt.style.context('grayscale'): hist_and_lines()
-
Seaborn 风格
import seaborn hist_and_lines()
13、用 Matplotlib 画三维图
我们可以导入自带的 Matplotlib 自带的 mplot3d 工具箱来画三维图:
from mpl_toolkits import mplot3d
导入这个子模块后,就可以在创建任意一个普通坐标轴的过程中加入 projection = ‘3d’ 关键字,从而创建一个三维坐标轴:
fig = plt.figure()
ax = plt.axes(projection='3d')
13.1、三维数据点与线
最基本的三维图是由(x,y,z)三维坐标点构成的线图与散点图,可以用 ax.plot3D 与 ax.scatter3D 函数来创建它们。三维图函数的参数与前面二维图函数的参数基本相同。下面来画一个三角螺旋线,在线上随机分布一些散点:
# 三维线的数据
zline = np.linspace(0,15,1000)
xline = np.sin(zline)
yline = np.cos(zline)
ax.plot3D(xline,yline,zline,'gray')
# 三维散点的数据
zdata = 15 * np.random.random(100)
xdata = np.sin(zdata) + 0.1 * np.random.randn(100)
ydata = np.cos(zdata) + 0.1 * np.random.randn(100)
ax.scatter3D(xdata,ydata,zdata,c=zdata,cmap='Greens')

13.2、三维等高线图
mplot3D 也有用同样的输入数据创建三维晕渲图的工具。ax.contour3D 要求所有数据都是二维网格数据的形式,并且由函数计算 z 轴数值。下面演示一个用三维正弦函数画的三维等高线图:
def f(x,y):
return np.sin(np.sqrt(x ** 2 + y ** 2))
x = np.linspace(-6,6,30)
y = np.linspace(-6,6,30)
X, Y = np.meshgrid(x,y)
Z = f(X,Y)
ax.contour3D(X,Y,Z,50,cmap='binary')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
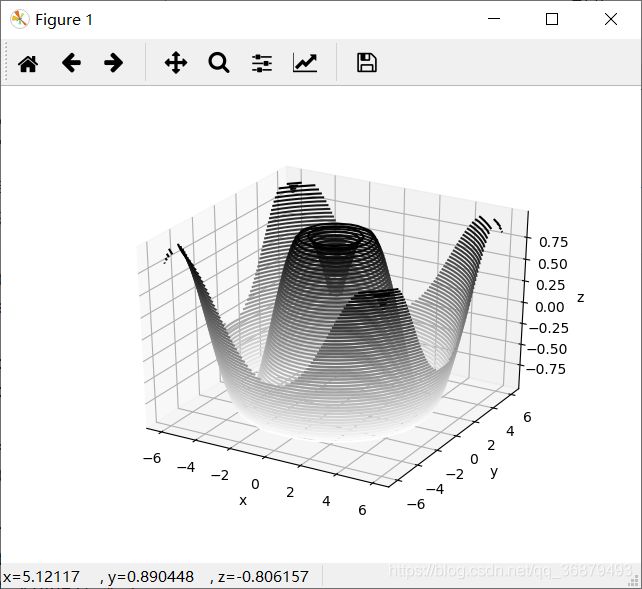
默认的初始观察角度有时不是最优的,view_init 可以调整观察角度与方位角。我们把俯仰角调整为 60 度(这里的 60 度是 x-y 平面的旋转角度),方位角调整为 35 度(就是绕 z 轴顺时针旋转 35 度):
ax.view_init(60,35)

13.3、线框图和曲面图
它们都是将网格数据映射成三维曲面,得到的三维形状非常容易可视化。下面是一个线框图的示例:
ax.plot_wireframe(X,Y,Z,color='black')
ax.set_title('wireframe')
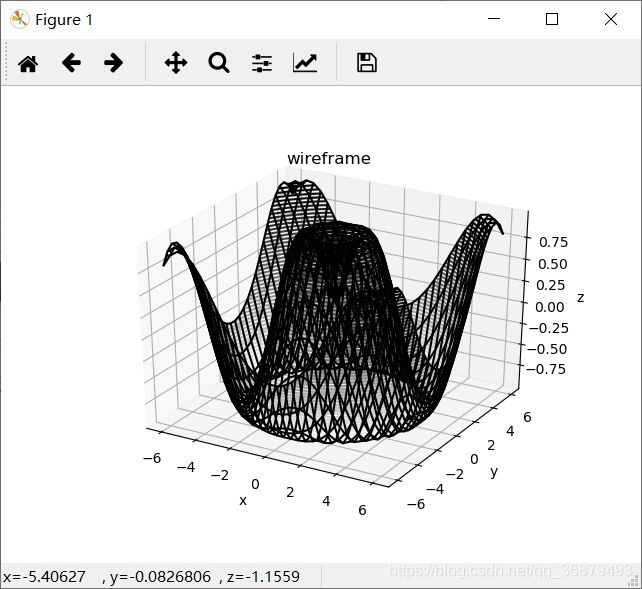
曲面图与线框图类似,只不过线框图的每个面都是由多边形构成的。只要增加一个配色方案来填充这些多边形,就可以让读者感受到可视化图形表面的拓扑结构:
ax.plot_surface(X,Y,Z,rstride=1,cstride=1,
cmap='viridis',edgecolor='none')
ax.set_title('surface')

需要注意的是,画曲面图需要二维数据,但可以不是直角坐标系(也可以用极坐标)。下面的示例创建了一个局部的极坐标网格,当我们把它画成 surface3D 图形时,可以获得一种使用了切片的可视化效果:
r = np.linspace(0,6,20)
theta = np.linspace(-0.9 * np.pi,0.8 * np.pi,40)
r, theta = np.meshgrid(r,theta)
X = r * np.sin(theta)
Y = r * np.cos(theta)
Z = f(X,Y)
ax.plot_surface(X,Y,Z,rstride=1,cstride=1,
cmap='viridis',edgecolor='none')

13.4、曲面三角剖面
如果上面这些要求均匀采样的网格数据显得太过严格且不太容易实现,这时就可以使用三角剖面图形了。如果没有笛卡尔或极坐标网格的均匀绘制图形,我们该如何使用一组随机数据画图呢?
theta = 2 * np.pi * np.random.random(1000)
r = 6 * np.random.random(1000)
x = np.ravel(r * np.sin(theta))
y = np.ravel(r * np.cos(theta))
z = f(x,y)
可以先为数据点创建一个散点图,对将要采样的图形有一个基本的认识:
ax = plt.axes(projection='3d')
ax.scatter(x,y,z,c=z,cmap='viridis',linewidths=0.5)
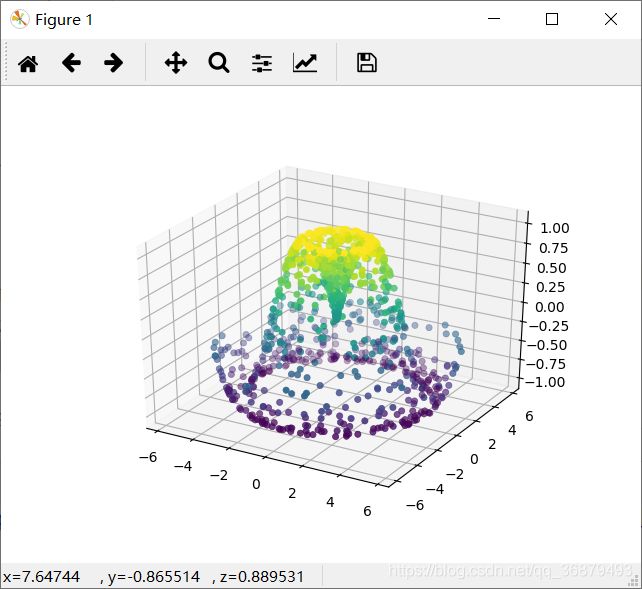
还有许多地方需要修补,这些工作可以由 ax.plot_trisurf 函数完成。它首先找到一组所有点都连接起来的三角形,然后用这些三角形创建曲面(其中 x、y 和 z 都是一维数组):
ax = plt.axes(projection='3d')
ax.plot_trisurf(x,y,z,
cmap='viridis',edgecolor='none')
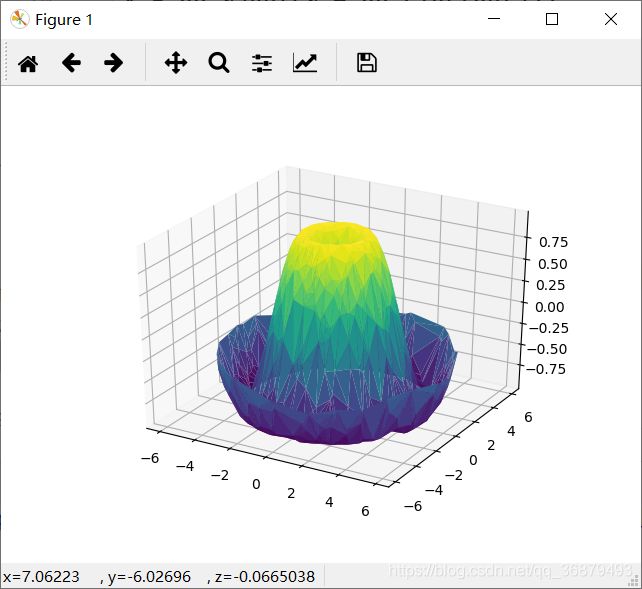
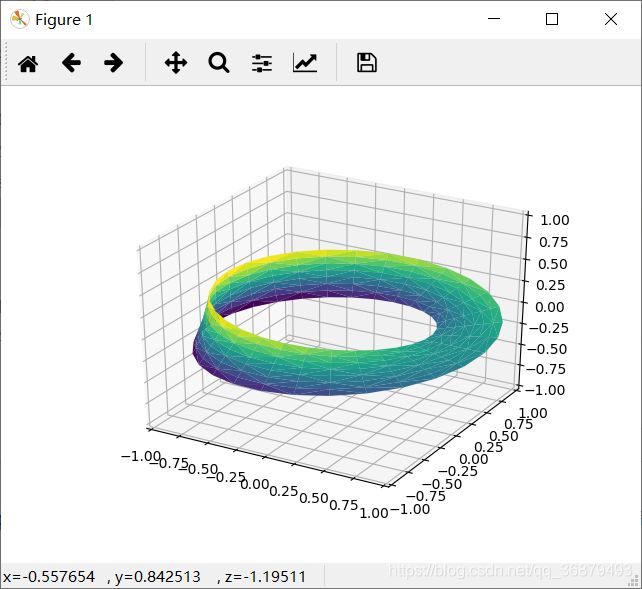
案例:莫比乌斯带
它的绘图参数:由于它是一条二维带,因此需要两个内在维度。让我们把一个维度定义为 θ,取值范围为 0~2π;另一个维度是 w,取值范围为 -1~1,表示莫比乌斯的宽度:
theta = np.linspace(0,2 * np.pi,30)
w = np.linspace(-0.25,0.25,8)
w, theta = np.meshgrid(w,theta)
有了参数后,我们必须确定带上每个点的直角坐标(x,y,z)。
仔细思考下,我们可能会找到两种旋转关系:一种是圆圈绕着圆心旋转(角度用 θ 定义),另一种是莫比乌斯带在自己的坐标轴上旋转(角度用 φ 定义)。因此,对于一条莫比乌斯带,我们必然会有环的一半扭转 180 度:
phi = 0.5 * theta
现在用我们的三角学知识将极坐标转换成三维直角坐标。定义每个点到中心的距离(半径)r,那么直角坐标(x,y,z)就是:
# x-y 平面内的直径
r = 1 + w * np.cos(phi)
x = np.ravel(r * np.cos(theta))
y = np.ravel(r * np.sin(theta))
z = np.ravel(w * np.sin(phi))
最后,要画出莫比乌斯带,还必须确保三角剖分是正确的。最好的实现方法就是首先用基本参数化方法定义三角剖分,然后用 Matplotlib 将这个三角剖分映射到莫比乌斯带的三维空间里,这样就可以画出图形:
# 用基本参数化方法定义三角剖分
from matplotlib.tri import Triangulation
tri = Triangulation(np.ravel(w),np.ravel(theta))
ax = plt.axes(projection='3d')
ax.plot_trisurf(x,y,z,triangles=tri.triangles,
cmap='viridis',linewidths=0.2)
ax.set_xlim(-1,1);ax.set_ylim(-1,1);ax.set_zlim(-1,1);
14、用 Seaborn 做数据可视化
14.1、Seaborn 与 Matplotlib
首先导入一些工具:
import matplotlib.pyplot as plt
plt.style.use('classic')
import numpy as np
import pandas as pd
下面用 Matplotlib 的经典图形样式和配色方案画一个简易的随机游走图:
# 创建一些数据
rng = np.random.RandomState(0)
x = np.linspace(0,10,500)
y = np.cumsum(rng.randn(500,6),0)
然后画一个简易图形:
# 用 Matplotlib 默认样式画图
plt.plot(x,y)
plt.legend('ABCDF',ncol=2,loc='upper left')

现在尝试用 Seaborn 来实现。我们会发现,Seaborn 不仅有许多高级的画图功能,而且可以改写 Matplotlib 的默认参数,从而用简单的 Matplotlib 脚本获得更好的效果。可以用 Seaborn 的 set() 方法设置样式。为简便起见,将 Seaborn 导入简记为 sns:
import seaborn as sns
sns,set()
# 同样的画图代码
plt.plot(x,y)
plt.legend('ABCDF',ncol=2,loc='upper left')

已经优化了!效果一样。
14.2、Seaborn 图形介绍
Seaborn 的主要思想是用高级命令为统计数据探索和统计模型拟合创建各种图形。
14.2.1、频次直方图、KDE 和密度图
data = np.random.multivariate_normal([0,0],[[5,2],[2,2]],size=2000)
data = pd.DataFrame(data,columns=['x','y'])
for col in 'xy':
plt.hist(data[col],normed=True,alpha=0.5)
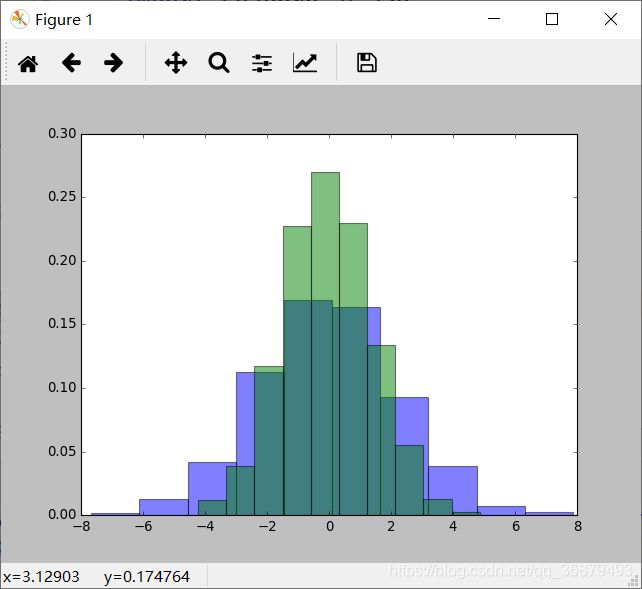
除了频次直方图,我们还可以用 KDE 获取变量分布的平滑估计。Seaborn 通过 sns,kdeplot 实现:
for col in 'xy':
sns.kdeplot(data[col],shade=True)

用 displot 可以让频次直方图与 KDE 结合起来:
sns.distplot(data['x'])
sns.distplot(data['y'])
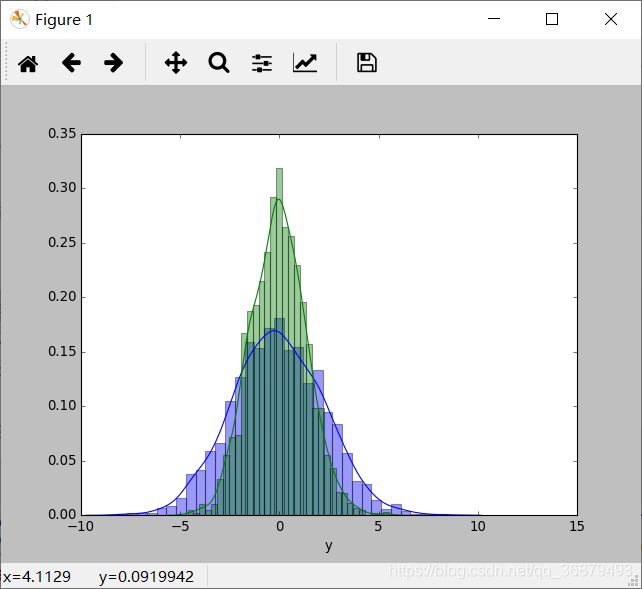
如果向 kdeplot 输入的是二维数据集,那么就可以获得一个二维数据可视化图:
sns.kdeplot(data)

用 sns.joinplot 可以同时看到两个变量的联合分布与单变量的独立分布。在这个图形中,使用白色背景:
with sns.axes_style('white'):
sns.jointplot('x','y',data,kind='kde')

可以向 jointplot 函数传递一些参数。例如,可以用六边形块代替频次直方图:
with sns.axes_style('white'):
sns.jointplot('x','y',data,kind='hex')

14.2.2、矩阵图
当你需要对多维数据集进行可视化时,最终都要使用矩阵图。如果想画出所有变量中任意两个变量之间的图形,用矩阵图探索多维数据不同维度间的相关性非常有效。
下面用著名的鸢尾花数据集来演示,其中有三种鸢尾花的花瓣与花萼数据:
iris = sns.load_dataset('tips')
print(iris.head())
'''
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
'''
可视化样本中多个维度的关系非常简单,直接用 sns.pairplot 即可:
sns.pairplot(iris,size=2.5)

14.2.3、分面频次直方图
有时观察数据最好的方法就是借助数据子集的频次直方图。来看看某个餐厅统计的服务员收取小费的数据:
tips = sns.load_dataset('tips')
print(tips.head())
'''
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4
'''
tips['tip_pct'] = 100 * tips['tip'] / tips['total_bill']
grid = sns.FacetGrid(tips,row='sex',col='time',margin_titles=True)
grid.map(plt.hist,'tip_pct',bins=np.linspace(0,40,15))

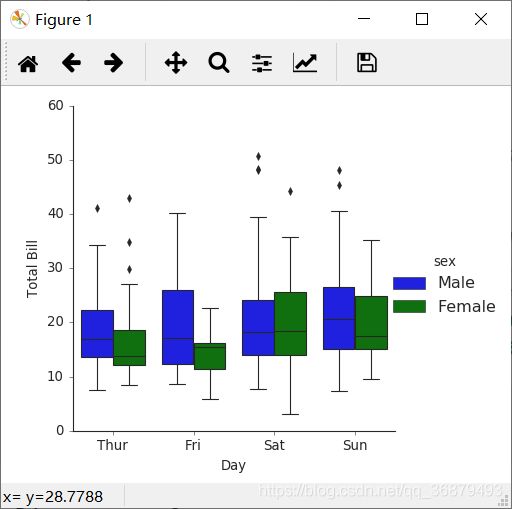
14.2.4、因子图
因子图也是对数据子集进行可视化的方法。你可以通过它观察一个参数在另一个参数间隔中的分布情况:
with sns.axes_style(style='ticks'):
g = sns.factorplot('day','total_bill','sex',data=tips,kind='box')
g.set_axis_labels('Day','Total Bill')
14.2.5、联合分布
与前面介绍的矩阵图类似,可以用 sns.jointplot 画出不同数据集的联合分布和各数据本身的分布:
with sns.axes_style('white'):
sns.jointplot('total_bill','tip',data=tips,kind='hex')

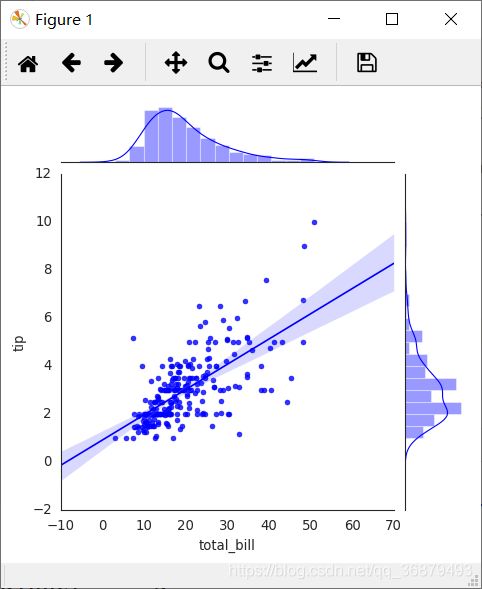
联合分布也可以自动进行 KDE 和回归:
sns.jointplot('total_bill','tip',data=tips,kind='reg')
14.2.6、条形图
时间序列数据可以用 sns.factorplot 画出条形图。我们用行星数据来演示:
planets = sns.load_dataset('planets')
print(planets.head())
'''
method number orbital_period mass distance year
0 Radial Velocity 1 269.300 7.10 77.40 2006
1 Radial Velocity 1 874.774 2.21 56.95 2008
2 Radial Velocity 1 763.000 2.60 19.84 2011
3 Radial Velocity 1 326.030 19.40 110.62 2007
4 Radial Velocity 1 516.220 10.50 119.47 2009
'''
with sns.axes_style('white'):
g = sns.factorplot('year',data=planets,aspect=2,
kind='count',color='steelblue')
g.set_xticklabels(step=5)
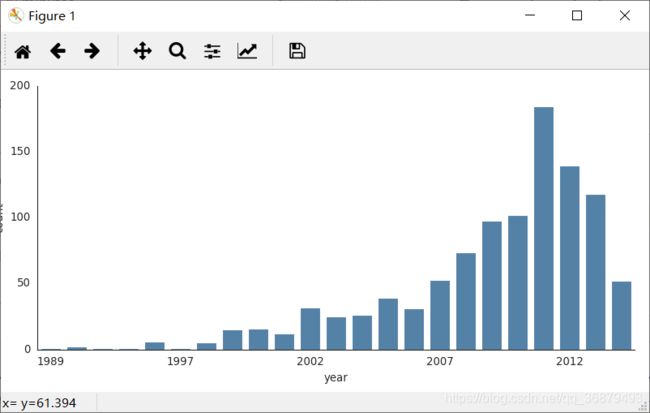
我们还可以对比不同方法(method 参数)发现行星的数量,如图:
with sns.axes_style('white'):
g = sns.factorplot('year',data=planets,aspect=4.0,
kind='count',hue='method',order=range(2001,2005))
g.set_ylabels('Number of Planets Discovered')
