Coursera课程自然语言处理(NLP) 借助概率模型做自然语言处理 deeplearning.ai

借助概率模型做自然语言处理
欢迎来到由 DeepLearning.ai提供的自然语言处理专项的第二门课程。这门课由Younes Bensouda Mourri,Łukasz Kaiser和Eddy Shyu讲授。
目录
- 借助概率模型做自然语言处理
- 目录
- 课程简介
- 自修正和动态规划算法
- 自修正
- 建立模型
- 最小编辑距离
- 最小编辑距离算法
- 词性标注和隐马尔可夫模型
- 词性标注
- 马尔可夫链
- 马尔可夫链和词性
- 隐马尔可夫模型
- 转移矩阵
- 发射矩阵
- 维特比算法
- 初始化
- 前向传播
- 反向传播
- 自修正和语言模型
- N-Grams
- N-grams和概率
- 序列概率
- 句子开始和结束的符号
- N-gram语言模型
- 语言模型的评估
- 处理词汇表外的单词
- 平滑处理
- 神经网络中的词嵌入
- 单词表示的基本方法
- 词嵌入
- 词嵌入方法
- CBOW模型
- 文本预处理
- 将单词转化为向量
- CBOW模型的结构
- CBOW模型的维度
- 激活函数
- 损失函数
- 前向传播
- 反向传播和梯度下降
- 词嵌入向量的特征提取
- 词嵌入模型的评估
- 内在评估
- 外在评估
课程简介
第二门课程的内容简介
In Course 2 of the Natural Language Processing Specialization, offered by deeplearning.ai, you will:
Create a simple auto-correct algorithm using minimum edit distance and dynamic programming,
Apply the Viterbi Algorithm for part-of-speech (POS) tagging, which is important for computational linguistics,
Write a better auto-complete algorithm using an N-gram language model, and
Write your own Word2Vec model that uses a neural network to compute word embeddings using a continuous bag-of-words model.
Please make sure that you’re comfortable programming in Python and have a basic knowledge of machine learning, matrix multiplications, and conditional probability.
By the end of this Specialization, you will have designed NLP applications that perform question-answering and sentiment analysis, created tools to translate languages and summarize text, and even built a chatbot!
This Specialization is designed and taught by two experts in NLP, machine learning, and deep learning. Younes Bensouda Mourri is an Instructor of AI at Stanford University who also helped build the Deep Learning Specialization. Łukasz Kaiser is a Staff Research Scientist at Google Brain and the co-author of Tensorflow, the Tensor2Tensor and Trax libraries, and the Transformer paper.
自修正和动态规划算法
自修正
- 自修正指一种将拼写错误的单词纠正为正确形式的应用。
- 例如:Happy birthday deah friend! ==> dear
- 工作流程:
- 确定错误拼写的单词
- 编辑距离算法:计算单词 1 1 1转化为单词 2 2 2的最小编辑距离
- 筛选编辑候选列表
- 计算单词的概率
建立模型
-
确定错误拼写的单词
- 如果该单词未被存储在词汇表 V V V中即视为错误拼写
-
计算单词 1 1 1转化为单词 2 2 2的最小编辑距离
- 编辑距离
- 计算字符串 a a a转换为字符串 b b b的最少单字符编辑次数
- 插入 (增加一个字母)
- 在当前单词任意部分增加一个字母: to ==> top,two,…
- 删除 (删除一个字母)
- 在当前单词任意部分删除一个字母 : hat ==> ha, at, ht
- 交换 (交换两个邻近的字母)
- 例如: eta=> eat,tea
- 替换 (将一个字母转换为另外一个任意的字母)
- 例如: jaw ==> jar,paw,saw,…
- 插入 (增加一个字母)
- 计算字符串 a a a转换为字符串 b b b的最少单字符编辑次数
- 编辑距离
-
通过组合这 4 4 4种编辑操作,我们获得了所有可能的编辑列表
-
筛选编辑候选列表:
- 从编辑列表中,仅考虑真实和正确拼写的单词
- 如果编辑列表中的单词不存在于词汇表 V V V中==>将其从候选编辑列表中删除
-
计算单词概率:候选单词是概率最高的单词
- 语料库中的单词概率为:单词出现的次数除以单词总数。
- 语料库中的单词概率为:单词出现的次数除以单词总数。



最小编辑距离
-
评估两个单词之间的相似度
-
计算一个字符转换为另一个字符所需的最少编辑次数
-
该算法最小化编辑成本
-
应用:
- 拼写校正
- 文本相似度
- 机器翻译
- DNA测序
- …

最小编辑距离算法
-
源单词位于矩阵的列
-
目标单词位于矩阵的行
-
每个单词开头的空字符设为 0 0 0
-
D [ i , j ] D [i,j] D[i,j]是指源单词空字符到 i i i与目标单词空字符到 j j j之间的最小编辑距离
-
要填写表格的其余部分,我们可以使用以下公式化的方法:


词性标注和隐马尔可夫模型
词性标注
-
词性标注指的是单词或词汇术语的类别
- 标签: 名次, 动词, 形容词, 介词, 副词,…
- 例句示例: why not learn something ?
-
应用:
- 命名实体识别
- 指代消歧
- 语音识别

马尔可夫链
- 马尔可夫链可以被描述为有向图
- 图形是一种数据结构,由一组由线连接的圆可视化表示
- 图的圆圈代表模型的状态
- 从状态 s 1 s1 s1到 s 2 s2 s2的箭头表示转移概率,即从s1到s2的可能性
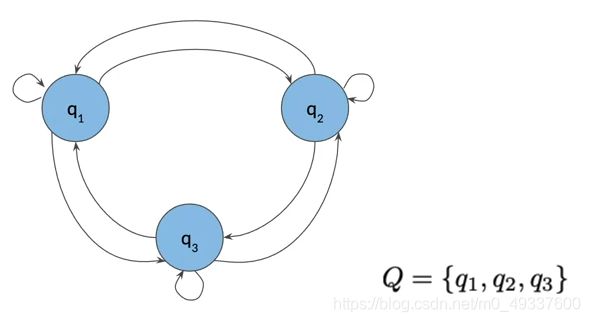
马尔代夫链和词性
- 想象这样一个句子,由一组单词序列组成,并且标注有词性
- 我们可以用图来表示这样一个序列
- 其中某个词性定义为一个事件,可以通过模型图的状态来判断事件发生的可能性
- 状态之间箭头上的权重定义了从一个状态到另一状态的概率
-
即词性转化的概率由下图可以得知
- 下一个事件的概率仅取决于当前事件
- 模型图可以定义为形状为 ( n + 1 × n ) (n + 1 \times n) (n+1×n)的转移矩阵
- 当没有先前状态时,我们引入初始状态 π \pi π。
- 一个状态的所有转移概率的总和应始终为 1 1 1。

隐马尔可夫模型
- 隐马尔可夫模型意味着状态是隐藏的或无法直接观察到的
- 隐马尔可夫模型具有维度 ( N + 1 , N ) (N + 1,N) (N+1,N)转移概率矩阵A,其中N是隐藏状态的数量
- 隐马尔可夫模型具有发射概率矩阵 B B B,描述了从隐藏状态到可观察值的转换(语料库的单词)
- 隐藏状态的发射概率行总和为1

转移矩阵
-
转移矩阵是存储隐马尔可夫模型状态之间的所有转移概率
-
C ( t i − 1 , t i ) C(t_{i-1},t_i) C(ti−1,ti)是计算训练语料库中所有词性的出现次数
-
C ( t i − 1 , t j ) C(t_{i-1},t_j) C(ti−1,tj)是计算词性 t i − 1 t_{i-1} ti−1的出现次数
-

-
为了避免被零除并且转换矩阵中的很多实例为 0 0 0,我们对概率公式应用平滑


发射矩阵
- 计算特定单词和它对应的词性的次数

维特比算法
-
维特比算法实际上是图算法
-
目的是找到隐藏单元的序列或词性标注中最高概率的序列
-
该算法可以分为三个主要步骤:初始化,前向传播和反向传播
-
辅助矩阵 C C C和 D D D
- 矩阵 C C C拥有中间最优概率
- matrix D D D holds the indices of the visited states as we are traversing the model graph to find the most likely sequence of parts of speech tags for the given sequence of words, W 1 W_1 W1all the way to W k W_k Wk
- C C C和 D D D矩阵有 n n n行(词性标注的数量)和 k k k个列(序列中的单词数量)

初始化
-
矩阵 C C C的初始化表明每个单词属于某个词性的概率
-
in D matrix, we store the labels that represent the different states we are traversing when finding the most likely sequence of parts of speech tags for the given sequence of words W1 all the way to Wk.
-
在矩阵 D D D中,我们存储能够代表不同单元

前向传播
-
对于矩阵 C C C,每个单元通过以下公式计算:
-
对于矩阵 D D D,保存 k k k,这将最大化 c i , j c_{i,j} ci,j中的单元

反向传播
- 反向传播将提取出序列中的单词最有可能表达的词性
- 首先,计算矩阵 C C C中最后一列单元中最高概率 C i , k C_{i,k} Ci,k的索引
- 表示当我们观察单词 w i w_i wi时所经过的最后一个隐藏状态
- 使用此索引回溯到矩阵 D D D以重构词性标注的序列
- 将许多非常小的数字相乘,例如概率,会导致数值溢出问题
- 使用对数概率代替,转化成数字相加而不是相乘。
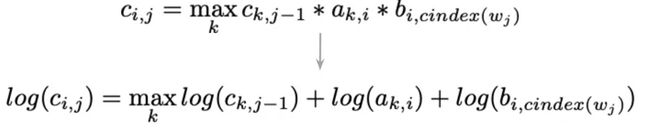
自修正和语言模型
N-Grams
- 语言模型是一种计算句子概率的工具。
- 语言模型可以根据给定历史的单词来估计下一个单词的概率
- 应用语言模型对给定句子自修正后,然后输出对句子的建议
- 应用:
- 语音识别
- 拼写校正
N-grams和概率
-
N-gram是一个单词序列。 N-gram也可以是字符或其他元素
-

-
序列符号
- m m m代表语料库的长度
- W i j W_i^j Wij 是指文本语料库中从索引 i i i到 j j j的单词序列
-
U n i − G r a m Uni-Gram Uni−Gram 概率
-
B i − g r a m Bi-gram Bi−gram 概率
-
N − g r a m N-gram N−gram probability



序列概率
-
giving a sentence the Teacher drinks tea, the sentence probablity can be represented as based on conditional probability and chain rule:
-
给定一个句子[‘Teacher drinks tea’],根据条件概率和连锁规则将句子的概率表示为:
-
这种直接的方法对序列概率有其局限性,句子的较长部分不太可能出现在训练语料库中
- P ( t e a ∣ t h e t e a c h e r d r i n k s ) P(tea|the\space teacher\space drinks) P(tea∣the teacher drinks)
- 由于它们都不可能出现在训练语料库中,因此它们的计数为0
- 在这种情况下,整个句子的概率公式无法给出概率估计
-
序列概率的近似
- 马尔可夫假设:只有最后 N N N个单词重要
- B i g r a m Bigram Bigram $P(w_n| w_{1}^{n-1}) ≈ P(w_n| w_{n-1}) $
- N g r a m Ngram Ngram $ P(w_n| w_{1}^{n-1}) ≈ P(w_n| w_{n-N+1}^n-1) $
- 用 B i g r a m Bigram Bigram建模整个句子:
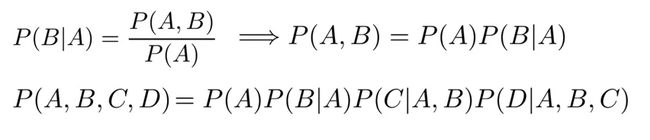
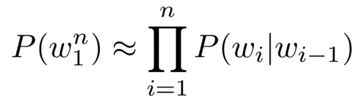
句子开始和结束的符号
- 句子开头符号:
- 句子结尾符号:
N-gram语言模型
-
计数矩阵存储 n − g r a m s n-grams n−grams的出现次数
-
-
计数矩阵转换为概率矩阵,存储 n − g r a m s n-grams n−grams条件概率
-
将概率矩阵与语言模型关联
-
将许多概率相乘会带来数字下溢的风险,请使用乘积的对数代替将项的乘积转化为项的总和



语言模型的评估
-
为了评估语言模型,将语料库分为训练 ( 80 % ) (80%) (80%),验证 ( 10 % ) (10%) (10%)和测试 ( 10 % ) (10%) (10%)集。
-
划分方式可以是:连续文本划分或随机文本划分
-
Evaluate the language models using the perplexity metric
-
使用困惑度指标评估语言模型
-

-
困惑度越小,模型越好
-
字符级别模型 P P PP PP低于基于单词的模型 P P PP PP
-
b i − g r a m bi-gram bi−gram模型的困惑度
-
对数 P P PP PP
-


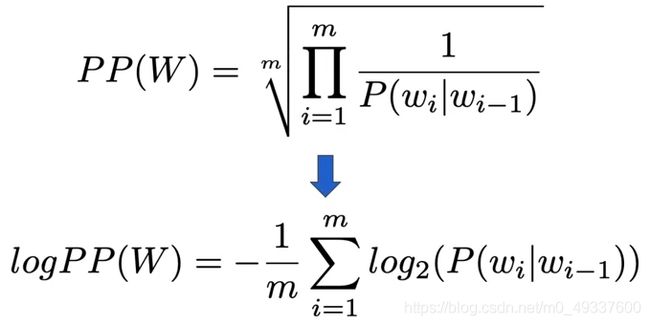
词汇表外的单词
- 未知单词是词汇表 V V V中不存在的单词
- 词汇表 V V V外的单词用特殊字符UNK代替
- 在语料库中但不在词汇表中的单词将由UNK代替
平滑处理
-
当我们在有限的语料库上训练 n − g r a m n-gram n−gram时,某些单词的概率可能会出现问题
- 当训练语料库中缺少由已知单词组成的 N − g r a m N-gram N−gram时,会出现这种情况
- 它们的数量不能用于概率估计

-
拉普拉斯平滑或 A d d − 1 Add-1 Add−1平滑
-
A d d − k Add-k Add−k平滑


神经网络中的词嵌入
单词表示的基本方法
- 将单词转化为数字的最简单方法是给词汇表 V V V中的每个单词分配一个唯一的整数
-

-
尽管它是简单的表示形式,但却没有什么具体意义
-
- 独热编码表示
-
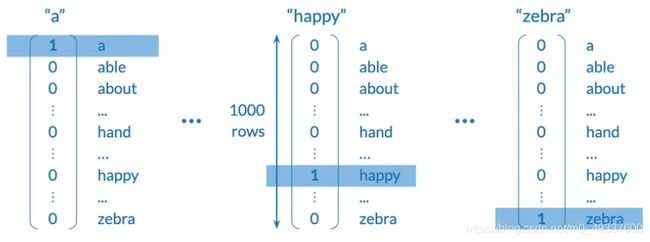
-
尽管它是简单的表示形式并且和顺序无关,但对于计算而言可能是巨大的,并且每个单词之间没有潜入的含义
-
词嵌入
-
词嵌入在相对较小维度中带有含义的向量
-
为了建立词嵌入,需要语料库和嵌入的方法

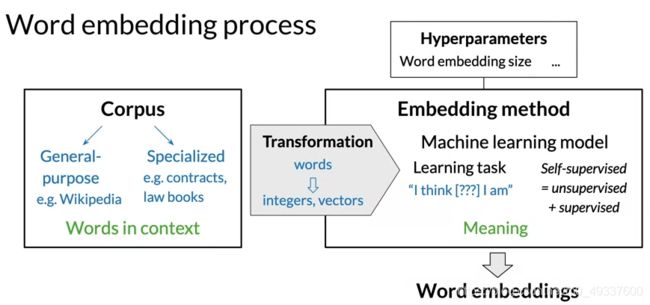
词嵌入方法
- W o r d 2 v e c Word2vec Word2vec:最初普及了机器学习的使用,以生成词嵌入
- Word2vec使用浅层神经网络来学习单词嵌入
- 它提出了两种模型架构
2. C B O W CBOW CBOW模型根据周围的单词预测缺失的单词
2. s k i p − g r a m skip-gram skip−gram模型和 C B O W CBOW CBOW模型相反,是通过学习输入单词周围的单词
- G l o V e GloVe GloVe:涉及分解语料库单词共现矩阵的对数,类似于计数器矩阵
- f a s t T e x t fastText fastText:基于 s k i p − g r a m skip-gram skip−gram模型,并通过将单词表示为 n − g r a m n-gram n−gram考虑单词的结构
- 生成单词嵌入的高级模型的其他示例: B E R T , G P T − 2 , E L M o BERT,GPT-2,ELMo BERT,GPT−2,ELMo
CBOW模型
- C B O W CBOW CBOW是基于机器学习的嵌入方法,根据周围的单词来预测缺失的单词
- 两个单词出现在各种句子中时,经常都被一组相似的词所包围—>这两个词往往在语义上相关
- 要为预测任务创建训练数据,我们需要上下文的单词和目标中心单词,示例
-

-
通过滑动窗口,您可以创建下一个训练示例和目标中心词
-

-
文本预处理
- 我们应该认为语料库的单词不区分大小写 比如: T h e = = T H E = = t h e The==THE==the The==THE==the
- 标点:? 。 ,! 和其他字符作为词汇表 V V V中的一个特殊字符
- 数字:如果数字在用例中不重要,我们可以删除或保留它们(爷可以用特殊令牌替换它们)
- 特殊字符:数学符号/货币符号,段落符号
- 特殊字词:表情符号,标签
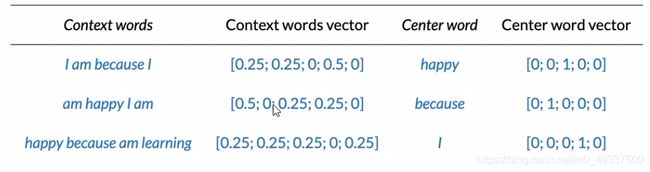
将单词转化为向量
- 通过将中心词和上下文词转换为独热向量
- 最终准备好的训练集是:
CBOW模型的结构
- C B O W CBOW CBOW模型基于具有输入层,隐藏层和输出层的浅层密集神经网络
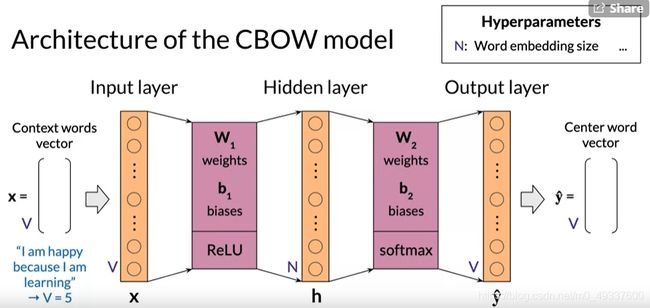
CBOW模型维度


激活函数


损失函数
-
学习过程的目标是使用交叉熵损失找到在给定训练数据集的情况下将损失最小化的参数
-

-

前向传播


反向传播和梯度下降
-
反向传播计算权重和偏差的偏导数
-
梯度下降更新权重和偏差


词嵌入向量的特征提取
-
训练完神经网络后,我们可以提取出三种替代的词嵌入表示
- consider each column of W_1 as the column vector embedding vector of a word of the vocabulary
- 将W_1的每一列视为词汇表单词的列向量嵌入向量
- use each row of W_2 as the word embedding row vector for the corresponding word.
- 使用W_2的每一行作为相应单词的单词嵌入行向量。
- average W_1 and the transpose of W_2 to obtain W_3, a new n by v matrix.



词嵌入模型的评估
内在评估
-
内部评估方法评估词嵌入在本质上如何捕获单词之间的语义(含义)或句法(语法)关系
-
在语义类上测试
-
使用聚类算法,在词向量空间中将相似的单词归为一类
-



外在评估
- 即命名实体识别,词性标注
- 使用一些选定的评估指标(例如准确性或F1分数)在测试集中评估此分类器
- 评估将比内部评估更加耗时,并且更难以排除故障