YOLOv5的使用实战——从利用Anaconda搭建torch环境到实验测试图像和训练个人数据集
文章目录
- 1、YOLOv5的介绍
- 2、 YOLOv5官方模板的使用
-
- 第一步,搭建pytorch环境,配置相关的工具包
-
- 安装package的几点注意:
- 第二步,在pytorch环境下,预训练模型和测试
- 3、使用自己的数据集训练神经网络
-
- 第一步,对需要识别的物体进行标注
- 第二步 训练神经网络
- 第三步,训练结果
1、YOLOv5的介绍
一、YOLOv4到YOLOv5
最初是希望参考YOLOv4进行目标的检测,希望使用深度学习来对电机车轨道的识别,但是,在查阅相关资料后,发现YOLOv4的余温还在,YOLOv5已经开发并进入了使用阶段,于是决定学习搭建YOLOv5的算法。
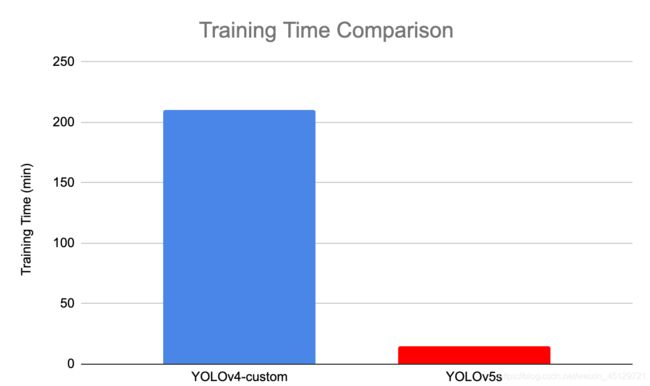
二、YOLOv5与YOLOv4 的比较
参考国外的博客,对YOLOv4和YOLOv5进行各方的比较
2、 YOLOv5官方模板的使用
根据YOLOv5 官方发布的工程,实战完全是作者本人耗时两天进行的,其中遇到了很多困难,最终都一一解决,希望对以后学习YOLOv5 有所指导意义。
提前从官方的Github网址下载并解压官方包:https://github.com/ultralytics/yolov5
第一步,搭建pytorch环境,配置相关的工具包
本文采用的环境是Anaconda和jupyter notebook的环境,对于Anaconda和jupyter的安装可以参考b站的相关视频,使用的python是3.6版本,更高版本的python与之类似。
安装好Anaconda和jupyter后,进行pytorch环境的搭建。
一、打开Anaconda Navigator,在Environments标签下点击Creat,创建一个新的环境,命名任意,命名为torch。
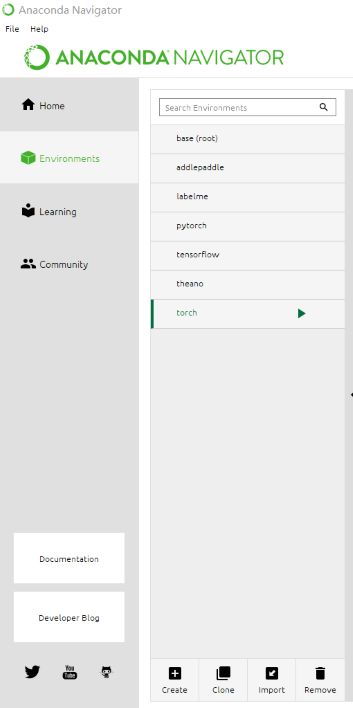
注意,现在创建的Environment是一个框架,相当于只是一个空的屋子,后续需要对屋子内部安装家具。安装各种程序包,这是python的特点,不需要个人进行程序模块的编写,直接调用即可。
二、在Anaconda的安装目录下,找到并打开运行命令程序——Anaconda Prompt,该程序的作用是下载安装和更新packages。
为什么不在Anaconda Navigator中安装呢?主要原因是Anaconda Navigator中安装比较费劲,往往获得不了新版本的package,而且获取版本总是失败。

打开Anaconda Prompt后,进入的是base根目录,我们希望在刚建立的torch环境下,因此需要输入命令进入torch环境
activate torch
在进入新环境后,我们可以确定,新环境下是空的,需要我们自主的安装各种packages。由于python环境下packages较多,选择的package根据官方发布的要求进行安装。
在从Github上下载压缩包中,包含一个requirements.txt文件,里面详细介绍了需要安装的package的类型以及版本号。安装package的方法有几种:
(1)按照Anaconda Prompt的代码进行安装
以torch>=1.7.0为例,直接输入
pip install torch==1.7.0
这样,Anaconda会自动找到所需要的的package包,在该torch环境中进行下载安装。
(2)从网上直接下载安装包,在Anaconda Prompt中输入下载的package所在的文件夹地址安装即可。
pip install D:\software\torch-1.7.1+cu110-cp36-cp36m-win_amd64.whl
安装package的几点注意:
1、使用pip install直接下载可能由于网速原因而非常慢,建议直接搜索安装包手动下载后安装,主要安装packages可从网盘下载:
链接:https://pan.baidu.com/s/1_aWLDyrPrl2rMQ_cu0pw_Q
提取码:qwer
2、安装package可能会存在版本不兼容的问题,具体版本型号按照requirements.txt文件的要求安装即可。
3,、在作者进行安装的过程中,发现pycocotools>=2.0 # COCO mAP该package与现在的torch版本名称有变化,直接用pip install pycocotools指令安装会出现错误,因此,建议在使用下载的.whl文件安装,同时,将requirements.txt文件中的pycocotools>=2.0 # COCO mAP改为pycocotools-win>=2.0 # COCO mAP否则,会报错
DistributionNotFound: The ‘pycocotools>=2.0’ distribution was not found and is required by the application
4、在安装torchvision时,使用pip直接安装的版本是0.5.0版本,而要求版本为0.8.2,发现网上找不到适合windows系统高版本,通过在该网站上搜索,找到了适合CUDA和要求的版本:https://download.pytorch.org/whl/torch_stable.html。安装后,将requirements.txt中torchvision的要求删除即可。
其余的package安装中存在的问题,基本上可以通过Anaconda Prompt解决。安装完毕后,在torch环境下输入pip list,对照要求检查一下,预防在运行代码时候报错。

第二步,在pytorch环境下,预训练模型和测试
一、下载预训练模型
在官方给出的YOLOv5的权重文件中,分为四类:yolov5x、yolov5s、yolov5l、yolov5m

选用最快和最小的权重文件yolov5s,从官网上下载yolov5s.pt文件,放到与detect.py文件相同的根目录下
https://github.com/ultralytics/yolov5/releases/tag/v4.0.
二、打开提前安装好的jupyter notebook(torch),进入jupyter的torch环境根目录,将从官网下载的yolov5-master文件夹放到根目录,打开该文件夹,找到打开测试文件detect.py。
147行中,default项为采用yolov5s.py
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='source') # file/folder, 0 for webcam
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='display results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
opt = parser.parse_args()
三、在jupyter torch环境下,运行测试程序detect.py。jupyter无法直接运行.py文件,需要在yolov5-master文件夹下,新建python3文件,在文件内调用detect.py文件运行。运行文件输入
%run detect.py
detect.py文件中,有调用requirement.txt文件来检验安装的torch环境中package包版本是否符合要求,可以再次检验安装的package是否成功。
如果没有报错,会根据官方所给的images产生结果,并储存在相应的文件夹中:
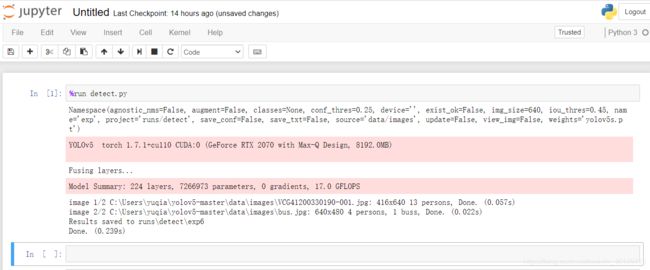

可以在data-images文件夹中添加自己的图片,根据官方所给的权重,进行物体的识别。
从实验结果可以看出,YOLOv5的运算速度非常快,单张图片的处理识别时间仅为零点零几秒,完全可以应用在动态物体的识别检测。
3、使用自己的数据集训练神经网络
在实际应用中,尤其是在工业上,需要识别的不仅仅是所给的模型,根据需要对不同的物体进行识别和标注,下面是如何创建自己的数据集,训练神经网络。
第一步,对需要识别的物体进行标注
常用的图片标注工具有很多,最方便的是labelme工具,该工具可以使用Anaconda创建和使用。也可以从网上搜索软件进行安装,具体安装教程不再这里重复。进入labelme后,打开需要标注的图片。本次的目的是对火车轨道进行识别,通过绘图工具Create Polygons对轨道进行绘制:
标定默认保存为.json格式的文件,需要转换为yolo的.txt格式文件,数据的样式为:

转换方式可以参考
https://blog.csdn.net/hhhhhww/article/details/1.
在转换建立. py文件的时候,注意在jupyter下下载.py文件,否则会找不到文件。
数据集包含所需要的.txt文件和权重文件custom.pt文件
新建权重文件custom.pt,以检测目标为pathway为例,将该文件放到data文件夹中
train: ./data/custom/images/train/
val: ./data/custom/images/val/
nc: 3
names: ['pathway', 'pathway2', 'pathway3']
第二步 训练神经网络
一、训练需要修改和运行train.py文件,在开始的运行detect.文件是已经训练好的网络,当建立新的数据集,需要再一次训练。对train.py代码修改,以训练自己编好的数据集:
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='', help='initial weights path')
#预训练模型一开始是yolov5s,现在默认无
parser.add_argument('--cfg', type=str, default='./models/yolov5s.yaml', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/custom.yaml', help='data.yaml path')
#改为custom的文件位置
parser.add_argument('--hyp', type=str, default='data/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
#default迭代次数可以修改,减少迭代次数
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--log-imgs', type=int, default=16, help='number of images for W&B logging, max 100')
parser.add_argument('--log-artifacts', action='store_true', help='log artifacts, i.e. final trained model')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
opt = parser.parse_args()
二、本文训练使用的yolov5s,因此修改yolov5s.yaml,修改方式很简单,只需要修改类别数目nc即可,修改为之前确定的识别类型的数目。
三、使用jupyter在根目录下新建python3文件,输入运行train.py文件的指令,如果没有报错,则开始训练如图:
%run train.py

训练完成后,会生成权重文件,位置runs\train\exp12\weights\best.pt,将该文件作为新的权重文件,放到与原来detect.py相同的目录下,然后,更改detect.py,将权重文件改为best.pt,再次在jupyter中运行%run detect.py命令,即可获得使用自己建立的数据集训练的网络所获得的图片。题外话,jupyter的运行界面粉色很好看 ^ ^
第三步,训练结果

对车辆识别已经达到很高的精度,但是对轨道的识别仍存在问题。后续会进一步研究,持续更新。