这是why哥的第89篇原创文章
前两天,有一个读者给我发了一张图片。
我问:发什么肾么事了?
于是有了这样的对话:
.png)
他发的图,就是微信运动步数排行榜的截图:

其实扯了这么多,这就是个常见的面试场景题:如何设计一个排行榜?
这个题吧,其实就是考你面试准备范围的广度,见过就会答,没见过...就难说了。
当然,如果你在实际业务中做过排行榜,那么这题正中下怀,你也不要笑出声来,场景题面试官是会给你思考时间的。

所以你不要张口就来,你只需要眉头稍稍一皱,给面试官说:这题我想想啊。
然后稍微组织一下语言,说出来就行。
这次的文章,就带着大家分析一下“排行榜”这个场景题,到底应该怎么做。
基于数据库
这个题,如果是真的之前没有遇见过,可能最容易进入大家视野的就是平时接触的最多的数据库了。
因为一想到“排行榜”,就想到了 order by。
一想了 order by,就想到了数据库。
一想到了数据库...
兄弟,你路就走窄了。
虽然我曾经就基于 MySQL 做过排行榜,因为当时是为了一个比赛临时搭建的服务,根本就没有引入 Redis。我评估了一下搭建 Redis 的时间和用 MySQL 直接开发的时间。
于是选择了 MySQL。
而让我选择 MySQL 的根本原因还是我已经知道进入决赛的队伍只有 10 支,也就是说我的排行榜表里面从始至终也只有 10 条数据。
选手提交代码之后,系统实时算分,然后更新排行榜表。
然后接口返回给前端页面下面这些数据,而下面这些数据都在一个表里面:
- 队伍按照历史最高分数排名
- 队伍名称
- 历史最高分数
- 最近一次提交得分
- 最近一次提交时间
前端每隔一分钟调用我的接口,相同分数,名次相同,所以我在接口里面用一条比较复杂的 sql 去查询数据库,上面的这些字段就都有了。
你看,排行榜确实是可以用 MySQL 来做的。
不一定非得上 Redis,记住一句话:脱离业务场景的方案设计,都是耍流氓。

但是这玩意和“万物皆对象”一样,别对着面试官说,这一定不是面试官想要听到的答案。
或者说,这只是想要听到的一部分回答。
这个回答能用的原因是我给了一个具体的场景,用户量非常的小,怎么玩都可以。
甚至我们不借助 MySQL 的排序,把数据查出来,在内存里面排序都可以。
但是如果,这是一个游戏排行榜,随着游戏玩家的增加,达到千万用户级别的话,这个方案肯定是不行了。
当然,也许你会给我扯什么查询慢就加索引,数据量大就分库分表的方案。
怎么说呢,上面这句话是没有错的。
但是一旦数据量大起来了,这个方案其实就不是一个特别好的方案。
这问题,得从根上治理。
基于 Redis
这个场景其实就是在考察你对于 Redis 的 sorted set 数据结构的掌握。
sorted set,见名知意,就是有序集合的意思。
在 Redis 中它大概是长这样的:

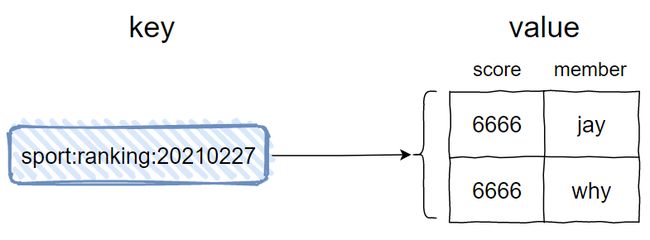
前面的 sport:ranking:20210227 是 Redis 中的 key。
value 是一个集合,且可以看出这个集合是有序的。集合中的每一个 member 都有一个 score,然后按照这个 score 进行降序排序。
需要注意的是,图片中的 score/member 不是我随便写的,官网上就是这样定义的:
https://redis.io/commands/zadd#sorted-sets-101

而且官网上说的是: score / member pairs。
所以我画图的时候,score 在前,member 在后。这可不是随便画的,虽然谁前谁后好像也不影响什么玩意。
另一个需要注意的点是,虽然我的示意图中没有体现出来,但是在有序集合中,元素即 member 是不可以重复的,但是 score 是可以重复的。
这个很好理解,就比如 20210227 这一天的微信步数,我可以走 6666 步,你也可以走 6666 步,这个是不冲突:
但是,问题就随之而来了:当 member 的 score 一样的时候,member 是怎么排序的呢?
看一下来自官网的答案:

当多个元素具有相同的分数时,它们按照 lexicographically 进行排序。
哎呀,lexicographically 这个单词不认识。
不慌,你知道的 why哥还兼职教英文:

当分数一样的时候,按照字典序排序,所以上面的示意图 jay 在 why 之前。
接下来,看一下有序集合的操作函数,一共有 32 个:

我这里就不一个个的做 API 教学了,官网上已经写的很清楚了,如果对于不熟悉的命令,可以去官网上查看,都是有示例代码的。
https://redis.io/commands/zadd#sorted-sets-101
比如这个 ZADD 方法:

为了后面分享的顺利进行,我这里只讲几个需要用到的操作:
- 添加 member 命令格式:zadd key score member [score member ...]
- 增加 member 的 score 命令格式:zincrby key increment member
- 获取 member 排名命令格式:zrank/zrevrank key member
- 返回指定排名范围内的 member 命令格式:zrange/zrevrange key start end [withscores]
先看第一个:添加 member。
比如我们把示意图中的数据添加到到有序集合里面去,语法是这样的:
- zadd key score member [score member ...]
意思是可以一次添加一对或者多对 score-member,比如下面这两个命令:
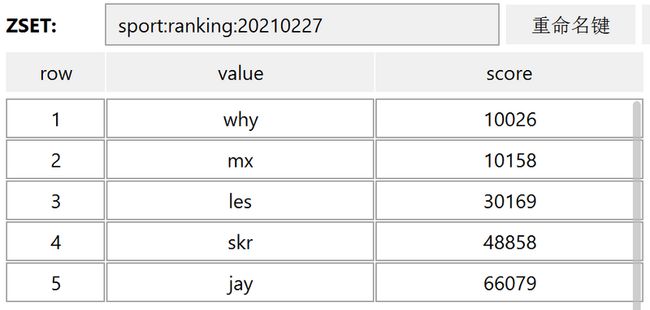
- zadd sport:ranking:20210227 10026 why
- zadd sport:ranking:20210227 10158 mx 30169 les 48858 skr 66079 jay

执行之后,返回的数字代表添加成功的 member 个数。
我用专门操作 Redis 的 RDM 可视化工具来查看插入的数据,和我自己画的示意图相差无几:
接着看第二个:增加 member 的 score
微信运动排行榜的数据是实时更新的。
目前 member 为 why 的步数是 10268,假设我吃完晚饭出门跑步去了,又跑了 5000 步。
这时得更新我的步数,就用 zincrby 命令,语法是这样的:
- zincrby key increment member
对应上面场景的执行命令是这样的:
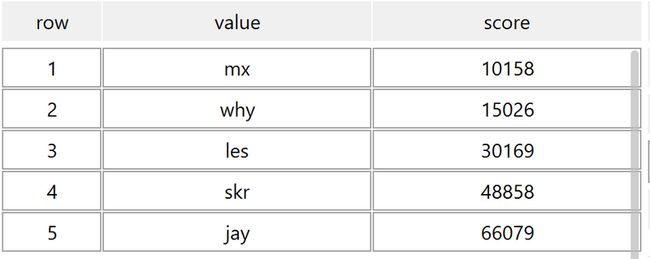
- zincrby sport:ranking:20210227 5000 why
执行完成后,会返回 why 的步数,可以看到从 10026 变成了 15026 :

同时由于我的步数增加,按照 score 倒序,也导致了排序的变化:
所以我们只需要更新 score 就行了,至于排名的变化,Redis 会帮忙保证的。
然后看第三个命令:获取 member 排名
语法是这样的:
- 获取 member 排名:zrank key member
- 获取 member 排名:zrevrank key member
首先,排名都是 0 开始计算的。
zrank 是按照分数从低到高返回 member 排名。
zrevrank 是按照分数从高到低返回 member 排名。
比如现在要获取 jay 的排名,用 zrank 返回结果就是 4。
- zrank sport:ranking:20210227 jay
当用 zrevrank 时,jay 的排名就是 0:
- zrevrank sport:ranking:20210227 jay

所以,在微信步数排行榜的这个需求中,步数越多排名越靠前,我们应该用 zrevrank。
第四个需要掌握的命令是:返回指定排名范围内的 member。
- zrange/zrevrange key start end [withscores] 返回指定排名范围内的 member
这个命令就很关键了。
zrange 是按照 score 从低到高返回指定排名范围内的 member。
zrevrange 是按照 score 从高到低返回指定排名范围内的 member。
在这里,我只演示 zrevrange 的命令。
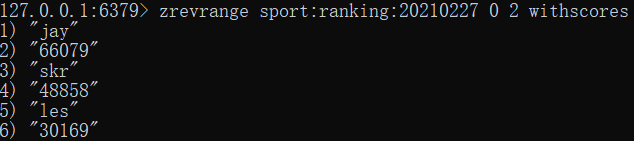
比如我要获取步数排名前三的 member:
- zrevrange sport:ranking:20210227 0 2

这个命令有个可选参数:withscores
当带上这个参数之后,会返回对应 member 的 score:
你想,这不就是排行榜 top N 的场景吗?
假设我现在要获取所有用户的排名,怎么写呢?
如下:
- zrevrange sport:ranking:20210227 0 -1
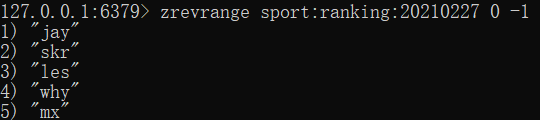
这就是当前的微信步数排行榜,jay 步数最多,mx 步数最少。
咦,怎么回事,排行榜好久就出来了呢?
你想想,讲完几个 API 操作,好像功能就实现了呢?
是的,确实是这样的,甚至我们只需要这两个 API 就能完成排行榜的需求:
- zadd key score member [score member ...] 添加 member
- zrange/zrevrange key start end [withscores] 返回指定排名范围内的 member
好了,如果大家喜欢的话,感谢大家一键三连。本次的文章就到这里了...

那是不可能的。
索然无味的 API 文章多没有意思啊。
虽然前面的部分我们已经可以基于 Redis 的有序集合加上几个简单的命令,就可以实现排行榜需求了。
但是前面只是铺垫,接下来,好戏才刚刚开始。
再次审视排行榜
上面的微信步数排行榜有个问题,你发现了吗?
就上面这个场景而言,所有人来看,看到的都是这样的排序:
而真实情况是,每个人看见的数据排行数据来源自己的微信好友,而微信好友各不相同,所以看到的排行榜也各不相同。
这个特性,我们并没有体现出来。
我们上面的场景更加类似于游戏排行榜,所有的人看到的全服排行榜都是一样的。
那么怎么保证我们每个人看到的各不相同呢?
你思考一下,该从什么角度去解决这个问题呢?

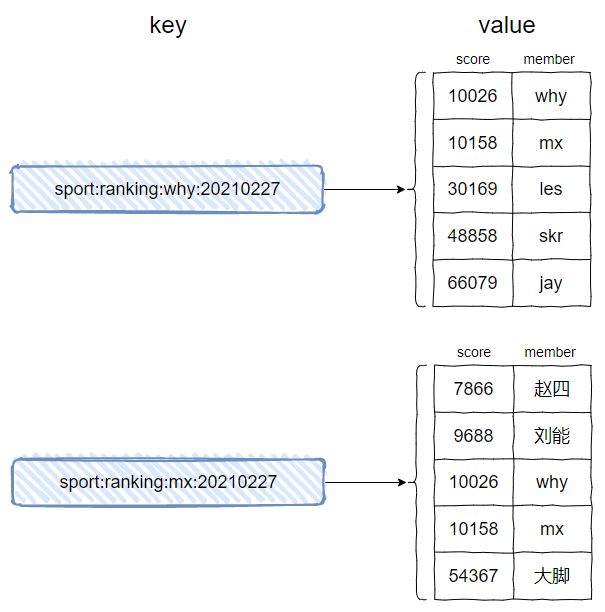
有序集合的 key 不同,就获取到不同的 value 集合。
我们当前的 key 是 sport:ranking:20210227,里面只包含了某一天的信息。
只要我们在 key 里面加上用户的属性就可以了,假设我的微信号是 why。
那么 key 可以设计为这样 sport:ranking:why:20210227。
这样,由于 key 里面多了用户信息,每个人的 key 都各不相同,就像这样的:
对应的命令如下:
- zadd sport:ranking:why:20210227 10026 why 10158 mx 30169 les 48858 skr 66079 jay
- zadd sport:ranking:mx:20210227 7688 赵四 9688 刘能 10026 why 10158 mx 54367 大脚
why 和 mx 看到的都是各自好友某一天的微信步数排行榜。
只要把 key 设计好了,这个问题就迎刃而解了。
但是你仔细思考一下,真的就迎刃而解了吗?
这个问题,我在写第一版的时候可能是被猪油蒙蔽了双眼,没发现。
有种“只缘身在此山中”的味道,一心想着 Redis 了。
你想,如果每个用户都有在redis有一个自己的排行榜,一个用户的分数更新的时候就需要对所有好友的zset更新,这多大的代价啊,对吧?
当以用户为纬度做排行榜的时候,就会出现排行榜巨多的情况,导致维护成本升高。
Redis能做,但不是最佳方案。
那么用什么方案去做呢?
我提个思路吧:
每个用户看到的排行榜不一样,我们其实不用时时刻刻帮用户维护好排行榜。
维护好了,用户还不一定来看,出力不讨好的节奏。
所以还不如延迟到用户请求的阶段。
当用户请求查看排行榜的时候,再去根据用户的好友关系,循环获取好友的步数,生成排行榜。
具体方案,大家自己思考一下吧。
另外多说一嘴,前段时间不是微信支持了修改微信号吗,赢得一大片叫好声。
其实我当时认真的想了一下,从技术上的实现来说这个需求到底有多难。
我不知道有没有历史技术债务在里面。
但是就说当前这个场景,key 里面包含了微信号,注意是微信号,不是微信昵称。
因为在设计之初,产品打包票说:放心,微信号绝对全局唯一,一旦确定,不可变更。
结果呢,现在要变化了。
产品屁颠屁颠的说:怎么实现我不管,这个需求用户呼吁很大,赶紧上线。
你说,对这些类似场景的冲击有多大?
其实冲击也不算特别大,一个字段的变化而已。
但是,微信 14 亿用户啊。
一个简单的需求,涉及到这个体量之后,就一句话:
量变引起质变。
好了,好了,扯远了。说回来。

当我把目光再次放到微信排行榜上的时候,我发现,其实我只是给了一个阉割版的排行榜。
是的,我们现在可以获取到 why 的当前步数是 1680 步,当前排名是 814 名。
比如还是沿用上面的例子,假设现在要获取我的微信好友 jay 的微信步数排行榜情况。
先获取 jay 的名次:
- zrevrank sport:ranking:why:20210227 jay

名次为 0,程序里面可以对其进行加一操作。就是第一名了。
接着获取 jay 的今日步数:
- zscore sport:ranking:why:20210227 jay

66079,步数也有了。
现在我们知道了:why 的好友 jay 今日运动步数 66079 步,在 why 的微信好友中排第一名。
但是你仔细看,这上面我还漏了两个字段:
- 微信头像
- 朋友点赞个数
两个字段应该怎么放呢?
放数据库里面当然可以,但是我们主要还是说一下 Redis 的解决方案。
这个时候其实我们想要存储的是 User 对象,对象里面有这几个字段:昵称、头像图片链接、点赞数、步数。
你说,这个用 Redis 的啥数据结构来存?
可不就得用 Hash 结构了吗。
Hash 结构同样涉及到 key 和 value,那么它们分别是什么呢?
key 就是我们的有序集合的 key 后面再加上好友昵称,比如这样的:
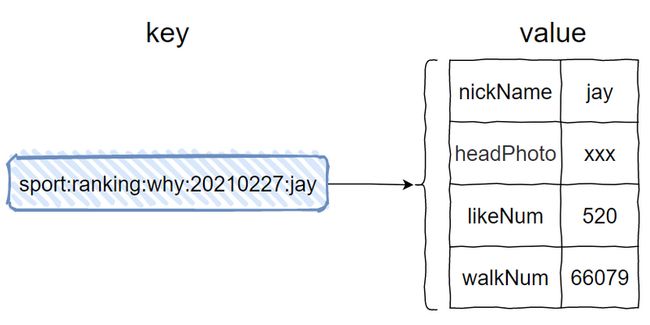
对应的命令是这样的:
- hmset sport:ranking:why:20210227:jay nickName jay headPhoto xxx likeNum 520 walkNum 66079
执行完成之后,在 RDM 里面看起来是这样的:
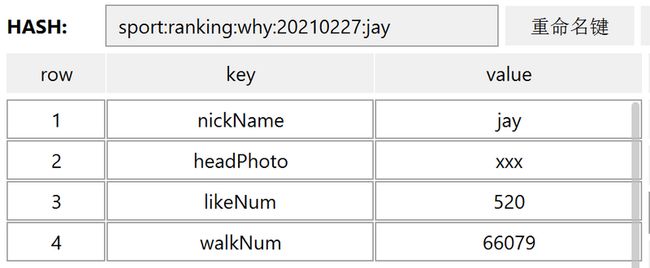
当后续有更多的赞的时候,需要调用更新命令更新 likeNum:
- hincrby sport:ranking:why:20210227:jay likeNum 500
执行完成之后点赞数就会变成 1020:
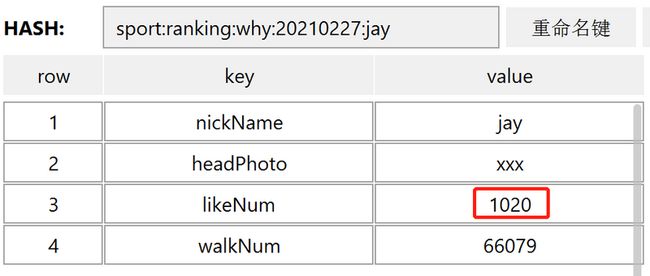
这样,排行榜上的所有字段我们都能获取到了,微信排行榜就说完了。
呃......
怎么感觉还是 API 教学呢?
不得劲,换个其他的。

最近七天排行榜怎么弄?
前面我们说的都是每日排行榜。
假设面试官要求我们提供一个最近七天、上一周、上一月、上个季度、这一年排行榜啥的,又该怎么搞呢?
其实这还是在考察你对于 Redis 有序集合 API 的掌握程度。
也就是这个 API:
- zinterstore/zunionstore destination numkeys key [key ...] [weights weight [weight ...]] [aggregate sum|min|max] 获取交集/并集
这个 API 看起来有点复杂,不要怕,一个个的讲:
- zinterstore/zunionstore其实就是交集/并集
- destination 将交集/并集的结果保存到这个键中
- numkeys 需要做交集/并集的集合的个数
- key [key ...] 具体参与交集/并集的集合
- weights weight [weight ...] 每个参与计算的集合的权重。在做交集/并集计算时,每个集合中的 member 会把自己的 score 乘以这个权重,默认为 1。
- aggregate sum|min|max 对于各个集合中的相同元素是 sum(求和)、min(取最小值)还是max(取最大值),默认为 sum。
拿最近七天举例,我们随便搞点数据进来,你可以直接粘过去玩:
- zadd sport:ranking:why:20210222 43243 why 2341 mx 8764 les 42321 skr
- zadd sport:ranking:why:20210223 57632 why 24354 mx 4231 les 43512 skr 5341 jay
- zadd sport:ranking:why:20210224 10026 why 12344 mx 54312 les 34531 skr 43512 jay
- zadd sport:ranking:why:20210225 54312 why 32451 mx 23412 les 21341 skr 56321 jay
- zadd sport:ranking:why:20210226 3212 why 63421 mx 53652 les 45621 skr 5723 jay
- zadd sport:ranking:why:20210227 5462 why 10158 mx 30169 les 48858 skr 66079 jay
- zadd sport:ranking:why:20210228 43553 why 4451 mx 7431 les 9563 skr 8232 jay
可以看到我们一共有 7 天的数据:
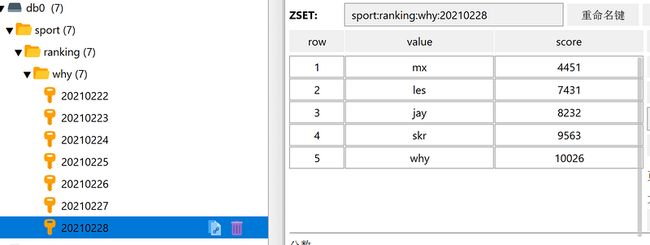
而且需要注意的是 20210222 这一天是没有 jay 的数据的。
现在我们要求出最近 7 天的排行榜,就用下面这行命令,命令有点复杂,但是对着命令格式看,还是很清晰的:
- zunionstore sport:ranking:why:last_seven_day 7 sport:ranking:why:20210222 sport:ranking:why:20210223 sport:ranking:why:20210224 sport:ranking:why:20210225 sport:ranking:why:20210226 sport:ranking:why:20210227 sport:ranking:why:20210228 weights 1 1 1 1 1 1 1 aggregate sum
这条命令后面的 weights 和 aggregate 都是可以不用写的,有默认值,我这里为了不隐藏数据,都写了出来。
执行完成后,可以看到多了一个 key,里面放的就是最近 7 天的数据汇总:
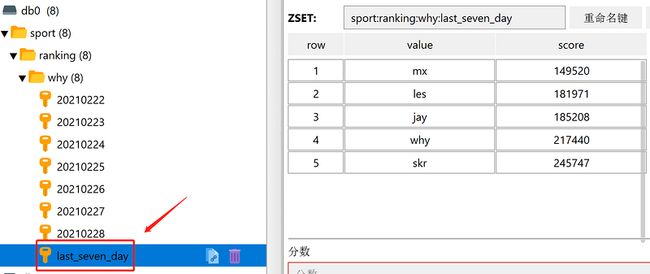
上面用的是并集,如果我们的要求是对最近 7 天,每天都上传运动数据的人进行排序,就用交集来算。
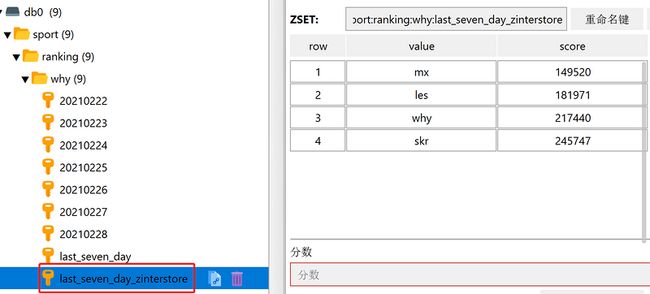
命令和上面的一致,只是把 zunionstore 修改为 zinterstore 即可。
另外为了有对比,合并之后的队列名称也修改一下,命令如下:
- zinterstore sport:ranking:why:last_seven_day_zinterstore 7 sport:ranking:why:20210222 sport:ranking:why:20210223 sport:ranking:why:20210224 sport:ranking:why:20210225 sport:ranking:why:20210226 sport:ranking:why:20210227 sport:ranking:why:20210228 weights 1 1 1 1 1 1 1 aggregate sum
从执行结果可以看出来,由于 jay 同学在 20210222 这一天没有上传运动数据,所以取交集的时候没有他了:
知道最近 7 天的做法了,我们又有每一天数据,上一周、上一月、上个季度、这一年排行榜啥的不都是这个套路吗?
呃......
怎么感觉还是 API 教学呢?
还是不得劲,再换个其他的。
亿级用户排行榜
王者荣耀,妥妥的亿级用户吧。比如我想看看我在亿级用户中排多少名,于是我打开了游戏,二十多分钟(玩了一局)之后我终于找到排行榜的位置。
结果,未上榜:
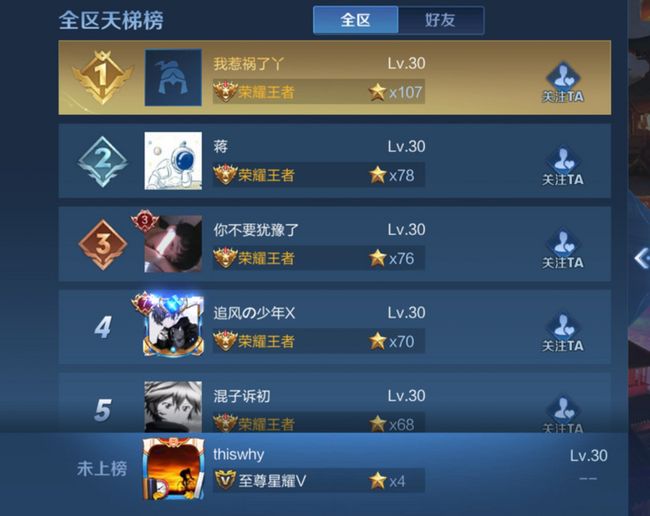
我这个千年老夫子,当然是未上榜了。
就算真的有排名了,排名好几千万,8 位数字,在页面上也不好放呀。
但是假设现在的需求就是要查询用户的全服排名,怎么查?
我瞎说一个我能想到的基于 Redis 的初版方案,注意是我瞎想的,实际做起来肯定是异常复杂的方案。
我是怎么想的呢?
我就寻思,一般面试遇到什么千万条数据、几个 G 文件、上亿的数据啥的,首先想到的方案就是分而治之。
这个亿级用户排行榜的需求也得用分治的思想。
王者一共 8 个段位:
- 1、倔强青铜
- 2、秩序白银
- 3、荣耀黄金
- 4、尊贵铂金
- 5、永恒钻石
- 6、至尊星耀
- 7、最强王者
- 8、荣耀王者
所以我们可以有 8 个桶。
这个桶可以是一个 Redis 里面的 8 个不同的 key,甚至可以是 8 个 Redis 里面各一个 key,看面试官给你的经费是多少,钱多就可劲造。
如下图所示:
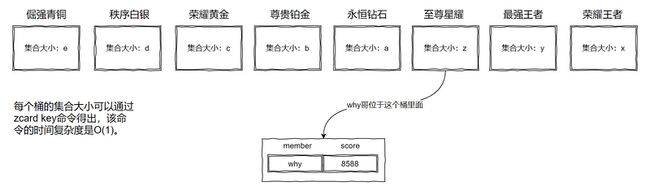
解释一下上面的图片中 score 为 8588 是怎么来的。
首先我们用 Redis 的有序集合,那么我们就得给每个 member 一个 score。
所以,每个用户在桶里面都一个经过公式计算后得出的积分。
比如why哥现在的段位就是星耀,假设计算出来的分数是 8588。
那么现在要算why哥在全服的排名就很好算了:
写程序的时候是可以知道我现在的段位是星耀,那么直接去星耀的桶里面,用 zrevrank 计算出当前桶里面的排名,假设为 n。
然后再通过 zcard 这个 O(1) 的命令获取到,前面的桶,也就是最强王者和荣耀王者这两个桶的集合大小,分别为 y 和 x。
那么why哥的全服排名就是 n+y+x。
所以获取任何一个用户的全服排名,就是看他在自己的桶里面的排名加上前面桶里面的元素个数即可。
而且现在要计算全服 top 100 就很容易了嘛。
直接取最前面的桶,也就是荣耀王者里面的前 100 个就完事了。
搞定。

等等,真的搞定了吗?
思路是对了,但是对于亿级用户只分 8 个桶未免太少了吧?
那就继续分桶呗,别忘了,每个段位里面还有小段位的。
比如星耀,里面就有星耀五到星耀一五个小段位,青铜三到青铜一三个小段位。
全部算上就是 27 个桶。
但是,27 个桶也少。
那么星耀二到星耀一还需要五颗星、青铜三到青铜二要三颗星才行呢。
这样算下来,就是 160 个桶。
160 个桶还是不够?
额。。。
推翻重来,直接把段位加上各种其他条件换算成积分,然后按照积分来拆分:
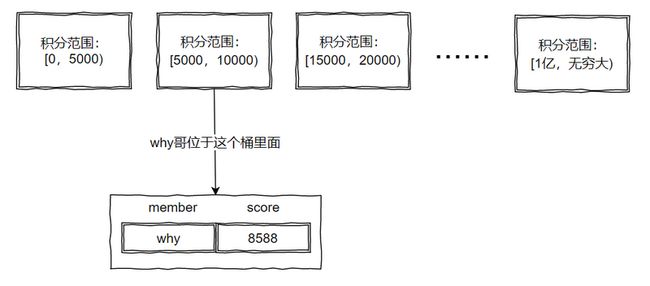
这样,想怎么拆分数段都行、拆多细都行。
完美。
等等,真的完美吗?
你看我的积分范围,都划分的非常的均匀。
按照段位拆分,有些菜鸡选手,打了两把觉得没意思,骂骂咧咧的退出游戏,就一直留在了青铜段位。
所以青铜段位的选手肯定是远大于荣耀王者的。
所以,实际情况下,用户的落点其实并不是均匀的。
怎么办?
这个时候就需要进行数据分析,通过一系列的高数、概率、离散等知识去做个桶大小的预估。
啊,这玩意就超纲了啊。
那就告辞,收工。

技术之外的考虑
做一个排行榜好像是一个很简单的事情。
但是其实不然,特别是推荐类的排行榜,需要避免马太效应:
比如作者推荐榜单,被推荐到前面的作者,曝光度很高。即使输出质量下降,但是还是很容易获得更多的关注。
位于榜单尾部的作者就很没有参与感。
于是两极分化就出现了,马太效应就来了。
对于这种情况怎么处理呢?
里面就涉及到一个复杂的计算公式了,比如掘金社区的掘力值,用于消息流推荐和作者榜单:
https://juejin.cn/book/6844733795329900551/section/6844733795380232206

所以千万不要错误的以为排行榜是一个非常简单的需求,这里面涉及到一些非常复杂的算法。
最后说一句
感谢大家的阅读。
才疏学浅,难免会有纰漏,如果你发现了错误的地方,可以在后台提出来,我对其加以修改。
