简介: 实际项目中沉淀的数据流最佳实践。

数据流是前端一直以来都存在的一个问题,我们项目沉淀了一套最佳实践,如有问题,欢迎探讨
在旧的 Done 项目中,代码复杂度高,已经到了“牵一发而动全身”,技术债极高的情况。由于旧代码“错综复杂”,导致实现一个简单的功能,都需要比正常时间多2~3倍的工作估时。就像下面这张图的情况一样。
我们仔细分析下现有的业务,会得出下面的业务特性:
- 强领域 (比如:项目/文件/团队/用户领域,在很多组件都会同时调用某个领域下的方法,静音/点赞/转移项目……)
- 单页面多且复杂,组件过多,多层嵌套组件间通信多。
- 业务已经实现了从 0~1 , 目前正处于从 1~n 的阶段,在这个阶段,会大量基于用户建议而做出产品交互的调整以打磨精品。需求数量增长,前端变动大,前端人力瓶颈大。
基于上面的业务特性,我们再分析目前项目中的问题:
- 模板代码过多,影响开发效率和可维护性
- 数据流螺旋呈网状调用(强耦合),代码复杂度急剧上升,牵一发而动全身
- 数据全局化
- 原始数据与展示数据转换
- UI 与 数据逻辑耦合,复用低
根据上面的特点和问题,我们有以下的诉求:
- 简单高效拒绝模版代码
- 降低代码复杂度(降低联动影响)
- 提升复用性极大程度的复用 UI / 逻辑层复用 数据转换
基于上面的问题和分析,下面将一步步推导新的架构图 & 技术选型。
问题分析
一、 UI 与 数据逻辑耦合复用度低 & 原始数据与展示数据转换
原先的整体架构如下:Store 与 视图层混合在一起, 一起处理用户行为和业务逻辑,耦合度高,复用率低。
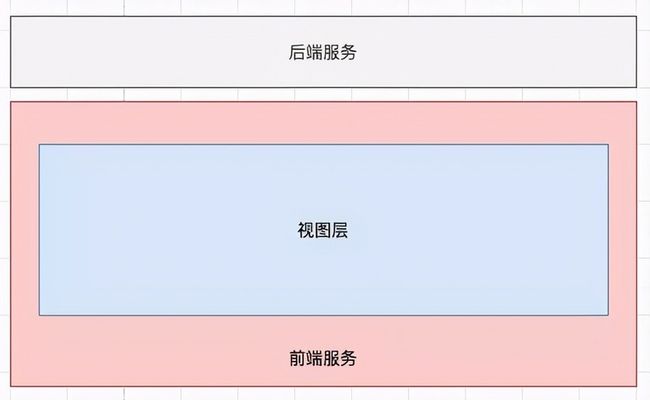
架构演进:

改进点:独立的 Store 层, 封装应用程序与业务逻辑相关的数据以及对数据的处理方法, 在此处独立写逻辑,支持多处组件复用一个逻辑,与视图层独立, 一个逻辑可以复用于多个组件。
众所周知,分层是为了解耦。假设 Store 层发生了改变,那么在视图层不需要变动的,只需要修改 Store 层即可,这样改动的地方就少了,也提升了开发效率&可维护性。
但是,我们还遇到一些场景,当后端接口发生字段变动,要改动的地方实在太多太多。同一个接口,在不同地方展示,由于多人维护,他会经过多次数据转换,最终映射到前端界面。因此,我们再多一个API防腐层,专门处理前端界面和后台界面的数据转换,这样,一旦数据结构发生变化,我们也只需要在 API 层修改即可,无须关注到多个界面组件中。

改进点:独立 API 层, 衔接后端服务与前端服务, 若后台接口发生变化,可在此处进行统一修改,无需多处代码进行修改,方便在该层进行数据检验, 预防后台返回错误的字段等等。
通过上面这样的分层,上面2个问题就迎刃而解了。
二、数据流网状调用
我们对 Store 和 视图进行了分层,但是随着项目的迭代,又出现了下面这种情况,数据流呈网状调用。
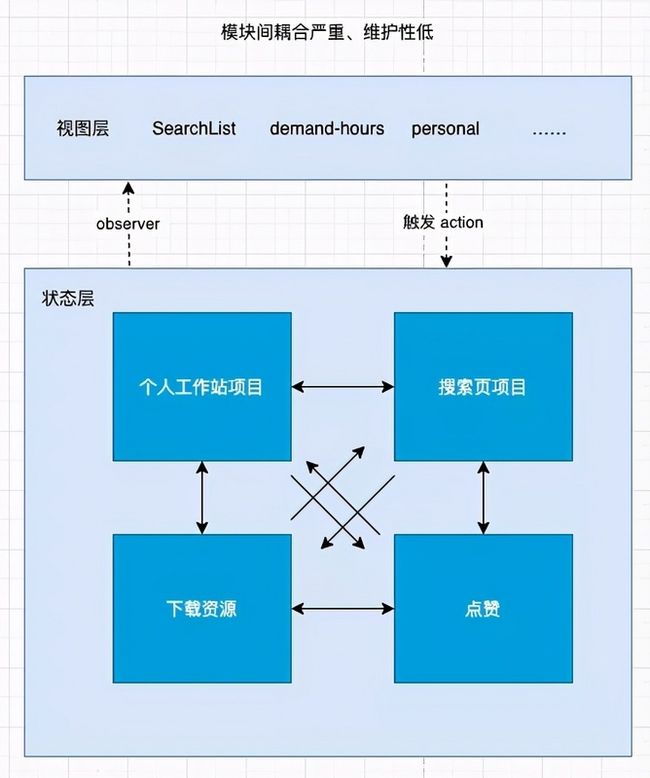
举一个例子:对项目设置静音
在旧的代码中,工作站会调用到团队中的数据,也会修改到团队中的数据,甚至接口回调后,他还会对各个地方涉及到静音界面的相关数据都进行修改。
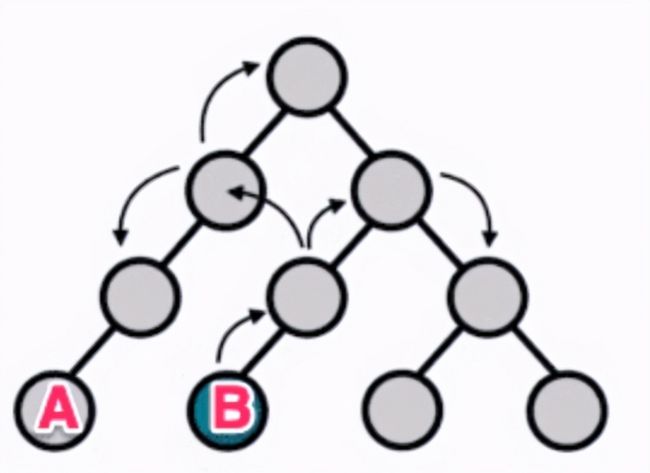
这会带来一个问题,由于是全局共用的 Redux ,我们在 A 地方调用这个方法,这里会更新 B 界面(B 地方并没有出现在用户的界面上),也就是说,修改 A 地方的 action ,还需要同时关注 B,C,D…… 这些地方(实际上,我们并不需要关注其他的地方)
我们知道分层可以解耦,对降低复杂度非常有效。那我们是否也可以对 Store 也进行分层,且约束他们之间互相调用?
架构演进:
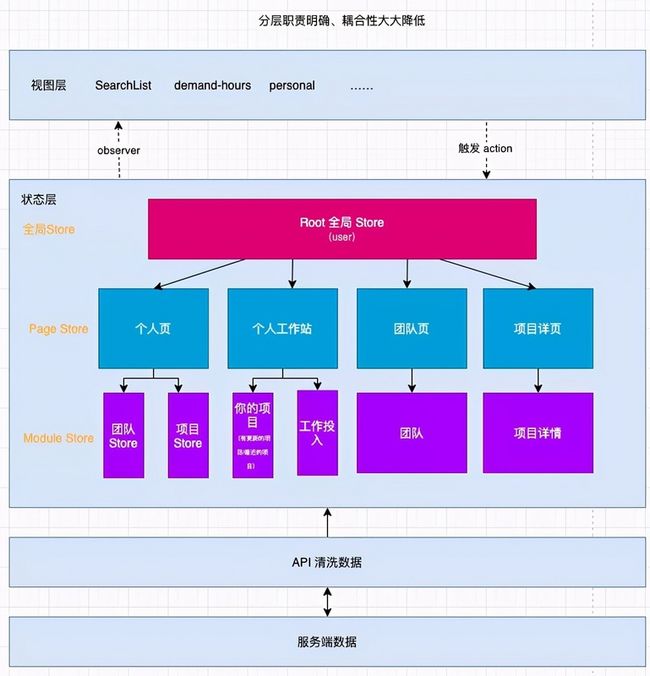
重构后,同层级的 store 不能互相调用,若需要调用,则说明这个 store 要提升到上一层级(下文有详细说明),换成这种方式之后,整个 Store 层也清晰明了,并且不会随着业务迭代而变得越来越复杂。
重构后,我们只需要用下面短短几行代码就可以实现:
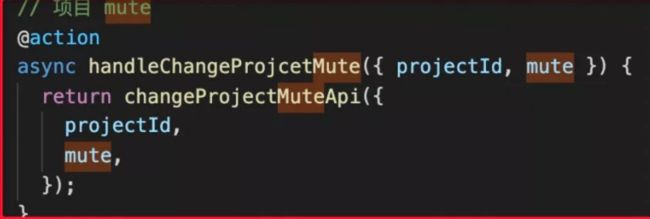
每个视图组件(A/B/C/D)拿到调用“静音”的回调结果,自己做更新界面的操作。
这样子,由原来的一处代码需要关注 N 处, 到现在只需要一处代码关注一处,大大降低了代码的复杂度。
三、数据全局化
举一个例子:在非父子组件之间共享传递一些状态,我们会使用状态提升来解决这个问题。但是如果此时组件之间的嵌套过深,那么中间经过的组件都会帮忙传递这些无用的 props, 且如果需要传递参数或者增加 props ,都需要修改 A、B、中间组件 * n 个地方。
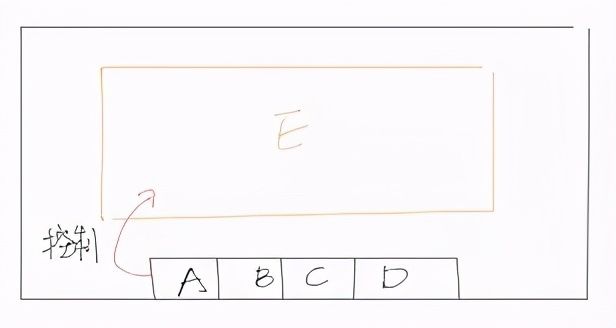
那么这时候,我们就会将这些状态放到全局 redux 中。但这样,又会引来其他的问题,对于一些临时保持的状态,比如在中后台常见的场景:A 组件控制同层弹窗组件 E 的显示隐藏状态,而这些状态对于用户来说,并不需要保存,是一次性的。
此时由于中间跨越的组件过多,我们将他放到了 redux 里面去,久而久之,redux 中的 action 越来越多。慢慢的,我们每次修改都需要确认他是否也一样影响了其他组件(实际上,这个 action 只会在这个模块中使用到,其他模块都无须关注)。
对于 Redux 派的数据流管理,都是中心化的。看了大部分的中后台产品,需要全局共享的数据并不多,一般只有用户 user 信息。在这个背景下,我们看向 mobx ,他天然支持多个 store 。那怎么去设计 store ?
高内聚对于提升项目的可维护性自然是一个好事,但是如果不控制好粒度,也容易引起问题。比如, 我们严格按照 React 官方的指导意见:如果多个 Component 之间要发生交互, 那么状态(即: 数据) 就维护在这些 Component 的最小公约父节点上
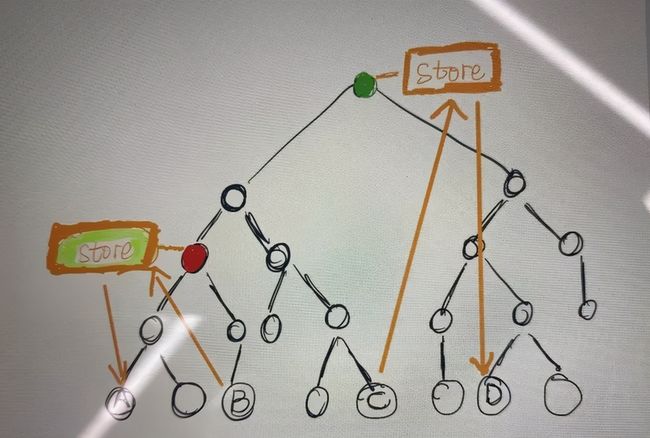
那么按照这种划分,我们的程序会出现成十上百个公约节点, 随着项目的迭代前进,曾经只是 A, B 之间共享,后面变成了 A,B,C 共享, 最大公约节点又需要向上提升,在多人协作的情况下,太多的提升和变更很容易引起项目的不稳定,所以,我们划分了下面三层 store ,最小粒度的 store 为模块 store 。
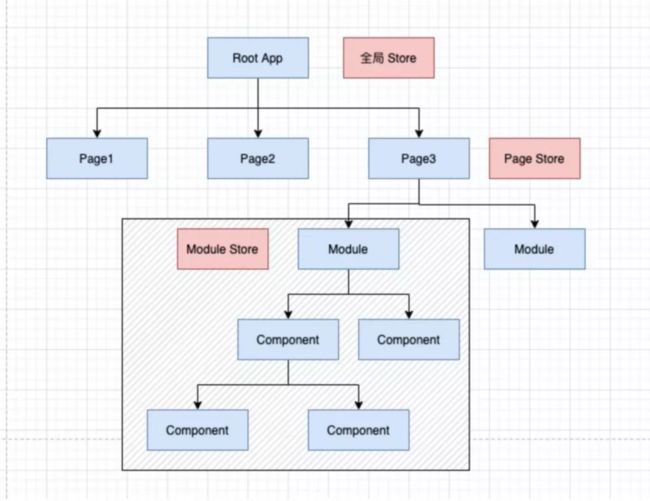
映射到具体项目中的 Store 图如下:
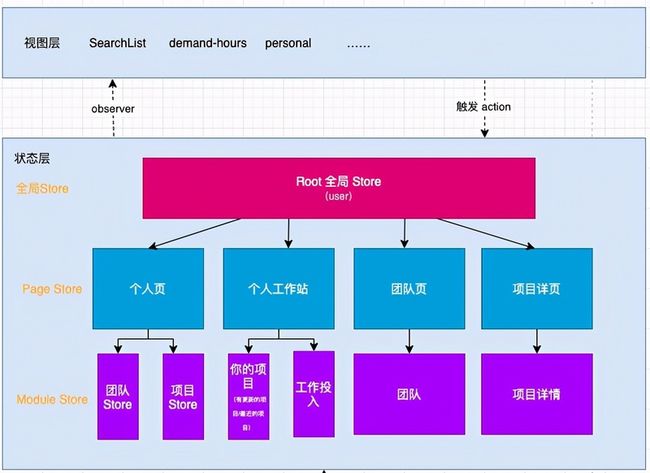
四、领域模型 DDD
我们如何去设计 Store ?我们使用了领域驱动设计,也就是 DDD 。
为何需要 DDD 呢?
- 在传统的前端开发流程中,前端和业务是通过视觉稿来联系的,一旦视觉稿发生变更,就意味大量的修改成本。目前产品到了 1~n 阶段,视觉稿需求稿的变化是必然的。
- 一个复杂的产品,是由多人协作的,如果大家都是按照视觉稿去设计 Store ,那么重复的逻辑会越写越多,后面技术债也越来越大。
- 贴合业务
如果我们采用 DDD ,比如我们抽象一个领域模型「文件」,在这里面,存放文件的相关操作:「修改文件名,删除文件,移动文件…… 」,有了这样一个稳定的领域模型,视图层只需要实现视觉稿和组装业务逻辑,具备很强的灵活性,就好像搭积木一样,底层的领域模型不需要变动,只需要改动交互变更或视图。极大提升了开发效率和维护性。
举个例子,随着项目的迭代,关于文件的相关操作:删除、移动等这些已经沉淀在领域模型中了,如果此时产品变更,删除的入口发生了变化,或者是增加了一个新的删除入口,那我们只需要修改完视图组件,然后在需要调用的地方调用下对应领域的 action 即可
按照领域的划分, Store 之间的界限也更加清晰。
注意:DDD 不是一个框架,而是一种架构思想,所以前端在开发之前,要先细化需求,设计好 Store 再进行开发。
项目中已沉淀的领域
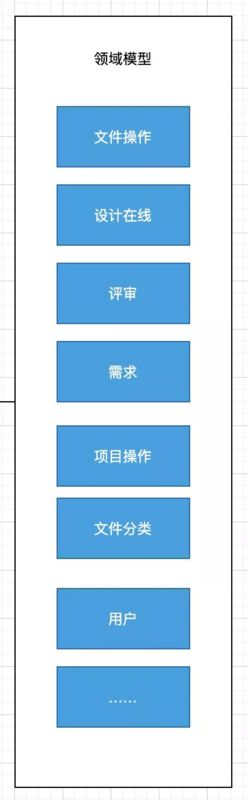
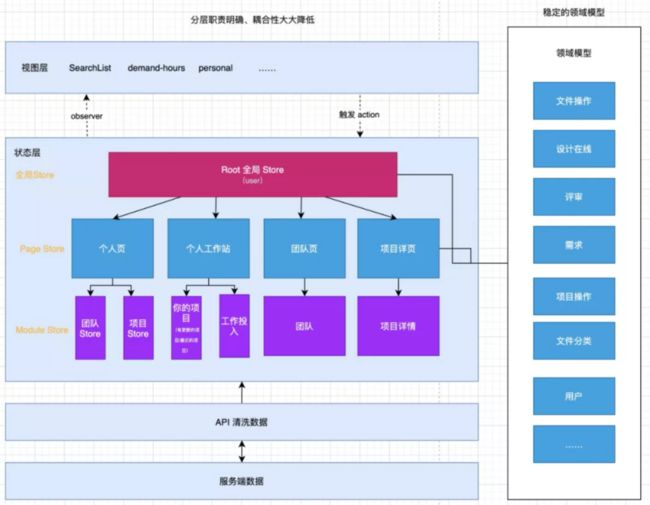
改进点:根据 Mobx 官方指导建议,除了页面一些松散的状态,还会根据整个业务特性沉淀一些通用的领域模型,这些可以根据不同页面需要,注入到对应的 Page Store 中去。
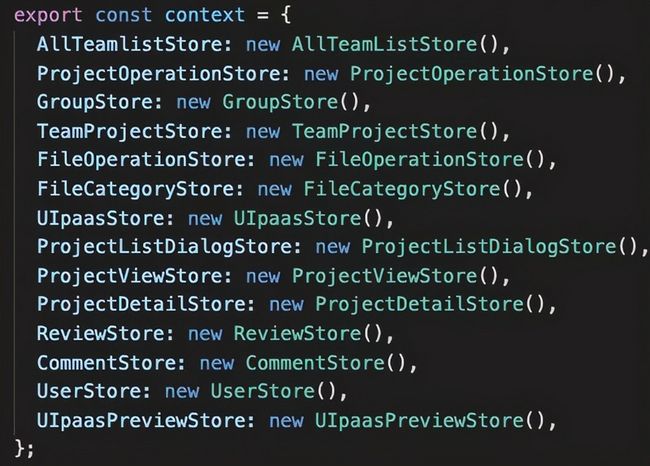
领域驱动设计这个理念已经在我们的业务中摸打滚爬了几个月,参与开发的同学都说好,在前端人力瓶颈大的情况下,后台同学也参与进来写 Store ,Store 与 视图同步并行开发,从串行开发到并行,极大提升了整体的开发效率。
技术选型
写了这么多,新的系统架构需要以下几个特性,才能让系统走得更快更远:
- 合理的分层, UI / 逻辑分离
- 复杂项目 Store 的粒度细化很重要, 领域模型 DDD
- 拒绝模版代码,提升开发效率
- 面向未来&兼容旧代码 -- 支持 hook & class
- 更好的 ts 支持
我们期望拥有这些特性,然后一个一个对比。
unstated-next
- 不知道要写多少 provider ,写法过于灵活,组织成领域模型需要大量改造(在一个小项目试验过,最后随着业务越来越复杂, 放弃了。)
- 旧的业务逻辑需要改造,一旦遇到class的情况,就又要回到旧的写法,在快速迭代业务的时候,是不可能停下来一个一个全部改造成 hook 的。
redux
- 大量的模版代码
- 过于灵活的 Redux 调用(网状调用)
- TS 支持改造成本大
为什么选择 mobx ?
✅少量/无 模版代码
✅面向未来&兼容旧代码 -- 支持 hook & class
✅很方便地对业务进行分层,很方便地设计领域模型
✅TS 支持 0 成本
✅天然支持多态 Store ,去中心化更方便
✅需要显示 DI, 解决了网状调用的问题
关于 Mobx 的缺点业界也说了很多,无非就是以下几个点:
- 状态可以随意被修改 -- 解决方案:开启严格模式限制,且只可在 Store 中修改,不可在视图组件修改
- 不支持 hook ,mobx-react-lite 已支持
综合上面种种原因,如果为了这些特性,重新去造一个轮子或者改造一个轮子,成本远远比直接借助 mobx 的力量更大。所以,在调研了多种数据流方案之后,选择了 Mobx 来支撑我们上面的架构。
总结
没有最好的技术方案,只有最适合业务的技术方案。我们从一个一个“业务痛点”推导出一套解决方案,并且已在实际项目中跑了几个月,也获得了不错的效果。
作者:被单
原文链接
本文为阿里云原创内容,未经允许不得转载