《C++语言程序设计》期末复习手记
一. 写在前面
- 使用教材:《C++语言程序设计》(郑莉,第四版)
- 推荐教材1:《C++ Primer Plus》(很厚,但是比较简单,适合边学边看)
- 推荐教材2:《Effective C++》(很薄,但是有点难,适合有一定基础后再看,否则可能被劝退)
- 推荐MOOC: 程序设计与算法(三)C++面向对象程序设计(北大):https://www.icourse163.org/course/PKU-1002029030
- 期末复习题(纯理论):百度网盘:https://pan.baidu.com/s/11WLevVLJEsL945i083B16w 密码:uyms
Q&A
在Q&A正式开始之前,首先说明一点。本文将持续更新,所以章节暂时不全。
- 小编,你C++考试考哪些章节?
答:第十章不考,第九章只考template用法,其他章节的“深度探索”部分都不考。嘿嘿,不考STL!哈哈哈哈哈…咳咳。 - 小编,为啥概率论考试你是手写提纲,这次咋就码字了?
答:嘿嘿,考试性质不同,复习方式也不同。概率论考试是笔试,所以,就得练练握笔的手感;而C++是机考,所以,就得练练摁键盘的手感。 - 小编,你C++期末考试题型是咋样的?
答:emm…这个我也很想知道。去年学C的时候,考试考的题是像ACM里的那种,更考察算法而非语法。今年C++貌似不一样了,据说有选择填空大题,更考察语法而非算法。诶,其实我挺讨厌这种考试方法的,但没办法。
好啦,言归正传,开启复习之旅吧~
注:文末有彩蛋!!!
二. 复习提纲
第1章 绪论 & 第2章 C++简单程序设计 & 第3章 函数
以笔者之间,这三章节的内容其实都应该算作是绪论的内容,几乎没有复杂的知识点。不过,还是有必要探讨一下,当做进行全书复习的开场白。
还是从《Effective C++》中 “条款01:视C++为一个语言联邦” 讲起吧。在这一章节看来,C++可以视作由四部分组成:
- C in C++。毕竟C++是以C为基础的,C++也可以像C那样面向过程编程。
- Object-Oriented C++。也就是C with Classes所诉求的,体现了面向对象编程。
- Template C++。即模板,这部分使用最少,体现了泛型编程。
- STL。是一个强大的template程序库,体现了泛型编程。(笔者考试不考)
可以说,前三章的内容主要介绍C in C++,而之后章节的内容主要介绍Objective-Oriented C++,同时也介绍了Template C++和STL。
不过,笔者假定大家已经较好掌握了C语言,所以对那些C语言的语法不加赘述。此处仅体现一些较为冷门与独特的知识点。主要的知识点可以分为四条:I/O流,typedef声明,枚举类型enum,内联函数inline。
1. I/O流
第一次接触C++时,我认为,C++与C的很大的区别在于头文件的改变(变成了iostream),多了一句using namespace std; ,同时printf与scanf分别变成了<<和>>。这在一方面使得输出变得简洁,但另一方面也带来了诸多弊端,主要有两点:
- 流输入与流输出的速度慢,如果参加程序设计竞赛的话,不建议使用流输入和流输出(因为竞赛程序往往有运行时间限制),推荐把cstdio作为头文件并使用printf和scanf
- 流输入与流输出导致输出格式控制变得繁琐(比如保留特定位小数之类),不过这些格式控制可以参见第11章
如果要深入理解流输入和流输出的话,可以参见第8章<<和>>的重载,以及第11章。
2. typedef声明
语法形式:typedef 已有类型名 新类型名表;
其实就是给类型名取个小名。例如:
typedef double Area; //给double一个别名Area
typedef int Natural; //给int一个别名Natural
Area a; //相当于double a;
Natural b; //相当于int b;3. 枚举类型enum
语法形式:enum 枚举类型名 {变量值列表};
例如:
enum Weekday{
SUN, MON, TUE, WED, THU, FRI, SAT}
//此时SUN值为0,MON值为1,TUE值为2...以此类推
enum Weekday{
SUN=7, MON=1, TUE, WED, THU, FRI, SAT}
//此时SUN值为7,MON值为1,TUE值为2,WED值为3...以此类推
具体的enum在程序中的用法可以参见课本P54的例2-11
4. 内联函数inline
其实就是在普通函数前加一个inline,据说能提高程序运行效率。(然而笔者亲自实验发现inline未必提高程序运行效率,其效果可能因机而异,就笔者的电脑而言,inline函数比普通函数慢)。
还是写一个简单的inline具体例子吧:
inline double calArea(double radius){
//inline关键字即使去掉也无伤大雅,但有inline据说可以提高程序运行效率
return 3.14*radius*radius;
}
第4章 类与对象
OOP编程有四个特点:抽象,封装,继承,多态。具体定义如下:
- 抽象:把对象概括成类,类定义对象即为“实例化”。
- 封装:把数据和行为相结合,即使不知道具体实现手段也可以使用以及封装好的东西。
- 继承:父类走向子类的过程即是特殊走向一般的过程。
- 多态:一段程序能够处理多种类型对象的能力,包括编译时多态和运行时多态。
其中,继承和多态在之后的章节中都会进行详细说明,而抽象和封装则在编程过程中会渐渐有所体会。仅这一章而言,还是来探讨两个问题:类的最基本的构成以及UML图(特别是聚合和组合的区分)。
1. 类的最基本框架
《Effective C++》条款05说道,如果你写下:
class Empty {
}就好像你写下这样的代码:
class Empty (
public:
Empty() {
... }
Empty(const Empty& rhs) {
... }
~Empty() {
... }
Empty& operator=(const Empty& rhs) {
... }
}构造函数(或许包括默认构造函数),复制构造函数,析构函数,等于符号的重载 可以构成一个类的最基本框架。其中前三这尤为重要。
必须理解每个程序构造函数,复制构造函数,析构函数的调用情况(包括数量与顺序):
- 构造函数在定义新对象时就会调用
- 复制构造函数调用的情况比较复杂,包括三种情况:赋值、函数参数、函数返回值。(详见课本P111)
- 析构函数的调用则与构造函数和复制构造函数的调用顺序称镜像对称,先构造的后析构,后构造的先析构。
课本P119例4-4这个程序特别有代表性,很多同学不明白为何Line line(myp1, myp2);这个语句会导致调用4次Point类的复制构造函数。其实关键点在于Line的复制构造函数的定义,如下:
Line::Line(Point xp1, Point xp2): p1(xp1), p2(xp2){
//第一个括号内Point xp1和Point xp2相当于传参,故此处调用两次Point的复制构造函数
//p1(xp1)和p2(xp2)相当于赋值,故此处再次调用两次Point的复制构造函数
...
}2. UML图(着重理解并区分聚合和组合)
画UML图的都是高端人才,UML图体现了程序的基本框架,根据UML图就可以实现程序。
这里来区分聚合和组合。可以说,聚合符合“has-a”关系,聚合相当于把一堆东西聚在一起成为一个新的东西(比如一堆零部件组装在一起成为电脑),新的东西拆开后,那一堆东西也可以单独存在,这说明聚合关系是比较松散的,是部分聚合后造就了主体。组合符合“is-like-a”关系,组合的主体被分解后,部分则失去意义(比如人体肢解后器官无法运作),这说明组合关系是很牢固的,是主体赋予了部分以意义,主体造就了个体。
在UML图中,因为聚合关系比较松散,所以以空心表示;组合关系比较牢固,所以用实心表示。如下图:
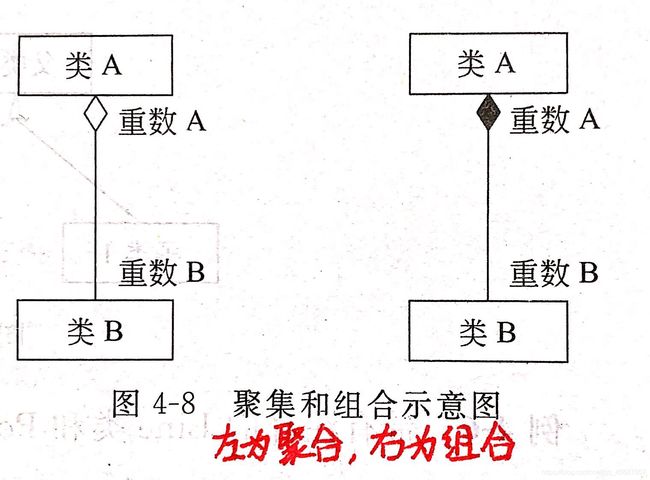
虽然一直强调要区分组合与聚合,但其实两者并非完全泾渭分明。毕竟有人会说,人体肢解后,器官还能移植呢!是的,某些组合在一直宽松的定义里甚至也能算是聚合,反之亦然。
第5章 数据的共享与保护
能用const就用const,不能用const就千万别用const,真让人头疼\发抖
本章主要理解四个概念:静态static成员(和函数),友元friend函数(和类),常成员const,多文件结构。实在想不出什么前言了,直接切入正题吧。
1. 静态成员和函数:关键字static
静态就是指一动也不动。比如一个类A,可以创建很多A的对象,但每个对象里的内容(成员变量的值)各不相同,互相独立。但这时候我希望获得某些和整个类A有关的统计量,我需要知道A的总体情况,比如A的总数,这时候需要引入静态变量。静态变量独立于每个A的对象,但可以体现A的整体性质。
如下程序可以体现:
#include2. 友元函数和类:关键字friend
好丽友,好朋友。好朋友就是要分享,分享就能使得事情变得方便。
声明友元函数可以帮助在它的函数体中可以通过对象名访问类的私有和保护成员。
声明友元类,比如A类为B类的友元类,则A类的所有成员函数都是B类的友元函数,都可以访问B类的私有和保护成员。
可以通过如下程序来理解:
#include需要注意以下三点:
- 友元关系是不能传递的。(我的仆人的仆人不是我的仆人,同理,我的朋友的朋友不是我的朋友)
- 友元关系是单向的。(我对你的爱是单向箭头,是无条件的,你可以利用我的,我却无权利用你的)
- 友元关系是不被继承的。(我的好朋友不是我的孩子的好朋友)
3. 常成员:关键字const
建议参考《Effective C++》如下章节:
- 条款02:尽量以const, enum, inline替换#define
- 条款03:尽可能使用const
- 条款20:宁以pass-by-reference-to-const替换pass-by-value
可以说,const是一个让程序锦上添花的关键字,它可以提升程序编写的安全性。但一般情况下,const不会对程序实现的成功与否产生决定性影响。
4. 多文件结构
多文件结构相当于把原来的单文件拆分,每一个类都分为一个.h和一个.cpp,其中,.h文件仅定义class里的变量与函数名,.cpp中再具体实现这些函数。当然,main函数也单独放置于一个.cpp中。
当然,这需要在.h中需要加上#ifndef,#define,#endif,.cpp中需要加上#include "…"来引用所需要的新增的.h头文件。
就用如下程序来体现说明吧:
//以下为头文件Simple.h
#ifndef SIMPLE_H_ //simple.h可以写成SIMPLE_H,也可以写成SIMPLE_H_,当然也可以写成其他
#define SIMPLE_H_
class SimpleCircle {
private:
int* itsRadius;
public:
SimpleCircle();
SimpleCircle(int r);
SimpleCircle(SimpleCircle& x);
~SimpleCircle();
int get();
void set(int r);
void show();
};
#endif
//以下为Simple.cpp
#include"simple.h" //既可以是simple.h,也可以是Simple.h,大小写不区分
#include需要注意的是,多文件的优势是可以使程序结构清晰(特别是在编写大型程序时),从而便于维护。适应多文件结构是一个很好的习惯。但对于考试的学生而言,这样的做法显然太过繁琐,浪费时间。所以,如果是在考试,如果没有特别说明,就请别用多文件结构,这会剥夺你大量宝贵的时间。毕竟,多文件与单文件的区别仅仅在于结构,其效果是没有任何区别的。
第6章 数组、指针与字符串
据说指针是C语言的精髓,当年学C指针的时候真滴让人头大,如今C++指针正挥手向我们走来\发抖
作为一门面向对象编程课,这里不纠结某些C已有的用法。此处假定C语言中的数组、指针、字符串您已经较为熟练的掌握了,所以本章不会纠结这些概念与用法。当然如果您还没完全理解并较为熟练地应用这些概念,建议您去自学计算机内存相关知识,推荐入门书籍《计算机科学导论》(去年看的时候还只有第三版,今年貌似已经有第四版了)。毕竟,指针即地址,这里的地址就是内存地址。
注:C语言没有string类,但此处不讲解string类了(因为太无聊了),建议全面参看课本P230-234
本章还是来讲讲一些有意思的、C++特有的、体现OOP的知识点。主要包括:this指针,动态内存分配,vector数组,深复制与浅复制
1. this指针
这个概念其实很好理解,但是初学者可能会对此感觉很晕。因为this指针是个无中生有的东西,不符合逻辑。但理解了以后就发现挺容易也挺好用的。
简单的来说,在一个class A类里,有一个private的变量x。其中A的public里的构造函数是A(int x): x(x){},嘿嘿,你可以分得清楚冒号后面的两个x分别指谁的x吗?是private变量x还是int x?我相信你肯定分得清的,前者指private变量x,后者指int x。当然这个构造函数还可以写成 A(int x) { x=x; },括号里的两个x中前者指private变量x,后者指int x。您当然可以这么写,但这么写让人困惑。其实这么写等价于以下语句A(int x){ this->x=x; },也就是说,this的意思是“这个类中定义的”或“这个类的”或直接指“自己这个类”,而" -> "则是如同连词的一个符号。不过不建议这么写,太繁琐,而且还会存在诸多问题。尽量写成A(int x): x(x){}而非 A(int x) { x=x; }(也就是尽量不要在括号里完成赋值工作,至于原因不作讲述)。不过其中的x(x)的意思虽然您能理解,但这样的做法太过学院派风格。所以,比较好的写法是 A(int xx): x(xx){}。
总结一下this的用法。this在一个类的构建中运用,常用在return语句表示返回改造后的自己(以this指针形式),即A fun()函数或A& fun()函数return *this,A* fun()函数return this。其他情况分两种,分别是“this+变量”以及“this+函数”。以变量x与函数fun()为例。在“this+变量”中,this做法是this->x;在“this+函数”中,this做法是this->fun()。
再来讲述三个概念:对象、参数、参数的类型。比如:A a相当于类A创建了一个对象a,A* a则相当于类A创建了一个对象*a,对象*a的参数是a,参数a的类型是A*。是不是有点晕?
同理,A *this相当于类A创建了一个对象*this,对象*this的参数是this,参数this的类型是A*。
2. 动态内存分配
动态的反义词是静态,动态体现了灵活性,尽管程序事先不知道需要多少内存,但它可以动态地分配内存。所以这个用法挺好。不过要记住,新开辟的内存在不要使用的时候就需要删除,不然这片内存将会在你运行程序后被一直占用,直到你关机重启。所以,每当new一片内存后就得在弃用后delete掉。如果new的行为发生在构造函数,那么delete就得写在析构函数。
一般用法如上一章(第5章)最后一个案例程序中的Simple.cpp:
#include"simple.h"
#include其他高阶的new和delete的用法可以参见《Effective C++》第八章“定制new和delele”,包含了条款49至条款52。
3. 深复制与浅复制
要明确浅复制是不对的,深复制是对的。这个问题一般发生在某个类的复制构造函数里,而且这个类的成员变量里有类似指针、数组之类的东西(指针和数组本质上是相同的,都是用来访问或管理一片地址,而不像某些变量只独占一个地址)。在这个类中,默认的复制构造会造成浅复制,所以必须依靠自己写出正确的复制构造函数实现深复制。
具体程序如下:
#include4. vector数组
vector数组(某些翻译官把它翻译成“向量数组”,如果您感觉太low的话,不如直接叫vector数组)其实是STL的内容,即属于泛型编程。虽然STL不考,但vector的用法挺简单的,所以还是需要考。vector数组相较于传统的数组还是有优越感的,因为它是一个成熟的动态数组,还能调用某些函数。
用一个程序就能理解vector的用法:
#include当然,vector数组还自带很多骚操作(某些函数)。先定义vector
第7章 继承与派生
一直不理解为什么superclass被翻译成“父类”而不是“母类”,是不是有点性别歧视?不过过度地恶意解读总是不好的\发抖
继承和派生两者有区别吗?应该是没有的,用课本上的话来讲,“新类继承了原有类的特征,也可以说是从原有的类派生出新类”。这种机制的好处在于代码的“重用性”和“可扩充性”。其实就是所谓站在巨人的肩膀上,取其精华、去其糟粕,实现从抽象走向具体。这一章需要搞懂:
- 继承怎么应用,包括三种继承方式:public,private,protected(一般只用public,后两者确实没啥用不过还是需要有一定的理解滴)
- 类型兼容原则(包括指针和引用)
- 派生类的构造函数、复制构造函数、析构函数该怎么写。
- 派生类成员的标识与访问,包括作用域分辨符、虚基类。
如果您有深入了解继承与派生的需求,请参见《Effective C++》第六章“继承与面向对象设计”,即条款32至条款40。
1. 访问控制:三种继承方式public/protected/private
在派生类中,成员可以按访问属性划分为以下4种:不可访问、私有(private)、保护(protected)、公有(public)
下表展示了父类成员在接受不同继承方式后在子类中访问属性的变化:
| 父类public成员 | 父类private成员 | 父类protected成员 | |
|---|---|---|---|
| public继承方式 | public | 不可访问 | protected |
| private继承方式 | private | 不可访问 | private |
| protected继承方式 | protected | 不可访问 | protected |
需要明确,子类是无法直接访问父类private成员的,如果需要访问则需要在父类的public成员中写几个函数作为接口,比如int getX()来return私有成员中x的值,int getY()同理。
还需要明确,三种继承方式一般只用public。什么时候用public继承合理?也就是子类与父类要满足什么关系时使用public继承才合理?应该是满足“ is-a ”关系时才可以。即子类 is a 父类,而不只只是子类 is like a 父类,更不是子类 has a 父类的关系。比如,矩形 is a 形状,所以Rectangle可以从Shape类中派生出。has-a关系一般指一种聚合关系,而is-like-a关系则一般指一种组合关系。
详细了解这些关系可以参见《Effective C++》条款32:确定你的public继承塑模出is-a关系;条款38:通过复合塑模出has-a或“根据某物实现出”;条款39:明智而谨慎地使用private继承。
2. 类型兼容原则:继承时指针和引用的正确打开方式
课本里的例子很好的说明了这一点
class B {
... }
class D: public B {
... }
B *b1, *pb1;
D d1;
//派生类对象可以隐含转换为基类对象,即用派生类对象中从基类继承来的成员,逐个赋值给基类对象成员
b1 = d1;
//派生类的对象也可以初始化为基类对象的引用
B &rb = d1;
//派生类对象的地址也可以隐含转换为指向基类的指针
pb1 = &d1;当然,类型兼容原则最为常见的应用还是在于指针与引用。此处具体说明这两者的实际用法。
3. 派生类的构造函数、复制构造函数、析构函数
1)单继承情况
一个类从另一个类派生的情况较为简单,只需要考虑代码写法。此处以Square从Rectangle中派生为例:
#include2)多继承情况
一个类从另外一堆类派生的情况较为复杂,除了要考虑代码写法,还需要理解派生类构造函数与析构函数的执行顺序。
首先需要明确派生类构造函数执行的一般次序:
- 调用基类构造函数,调用顺序按照它们被继承时声明的顺序(从左向右)
- 对派生类新增的成员对象初始化,调用顺序按照它们在类中声明的顺序
- 执行派生类的构造函数体中的内容
析构函数的执行顺序则很容易记忆,因为析构函数的执行顺序一定与构造(也可能包括复制构造)函数呈现镜像对称分布。也就是最先构造的对象最后消亡,最后构造的对象最先消亡。以不严谨的比喻来说,这就像堆栈那样遵循LIFO(后进先出)原则。
如下程序可以体现这几点:
#include输出结果如下:
Constructing Base2 2
Constructing Base1 1
Constructing Base3*
Constructing Base1 3
Constructing Base2 4
Constructing Base3*
Destructing Base3
Destructing Base2
Destructing Base1
Destructing Base3
Destructing Base1
Destructing Base2
4. 派生类成员的标识与访问:理解作用域分辨符和虚基类
我们写程序的时候开头总是#include
作用域分辨符在多继承时有很多好处。
好处1:可以解决一个类派生出的多个类中重名函数调用时的多义性。如下为图示结构与相关代码方案:
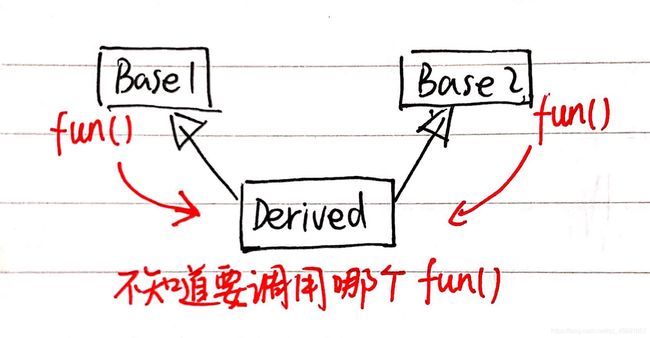
//以下为解决方案
Derived d;
Derived *p = &d;
d.Base1::fun(); //明确调用Base1的fun()
p->Base2::fun(); //明确调用Base2的fun()
好处2:可以解决一个类派生出多个类后,多个类又共同派生出一个类时,这个类调用爷爷类(父类的父类)的函数时产生的路径多义性。如下为图示结构与相关代码方案:
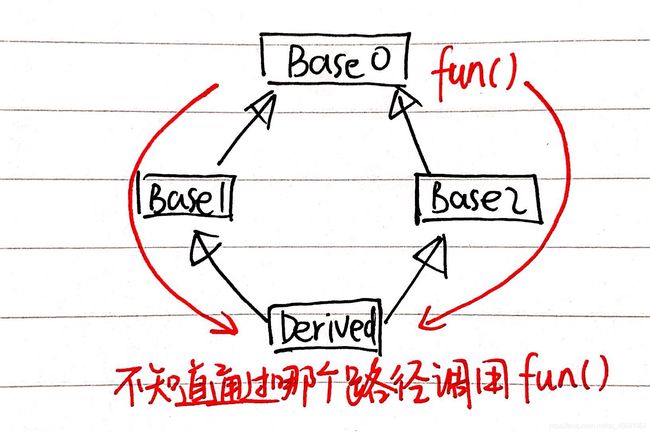
//以下为解决方案
Derived d;
d.Base1::fun(); //明确通过Base1访问基类的fun()
d.Base2::fun(); //明确通过Base2访问基类的fun(),效果与上一行代码相同当然,作用分辨符的好处2可以由虚基类代替,这会使得代码变得简洁。如下为程序:
#include输出结果:
Member of Derived
Member of Base0
第8章 多态性
我至尽还记得,那天上课时老师问我“多态是什么意思?”,我一脸懵逼,场面十分尴尬。
多态是指什么?相信大家肯定都能感觉到什么是多态,而且都能识别出体现多态的代码。但是这里有必要用科学严谨准确的语言进行描述。多态(Polymorphism)字面上指“多种状态”,在编程中指“同样的消息被不同类型的对象接收时导致不同的行为”。
面向对象的多态性可分为4种:重载多态、强制多态、包含多态和参数多态。前两者称为专用多态,后两者称为通用多态。以下详细介绍:
- 重载多态:包括普通函数及类的成员函数的重载,运算符重载(本章讲)。相当于“+”既能在浮点数之间完成相加、又能在整型数之间完成相加
- 强制多态:相当于“+”完成了在浮点数和整型数的相加,途中将整型强行转换成了浮点型
- 包含多态:定义于不同类中的同名函数有着不同的行为,主要通过virtual实现(本章讲)
- 参数多态:采用参数化模板template,通过给出不同的类型参数,使得一个结构有多种类型(第9章讲)
1. 运算符重载 Operator
分为以下四种。虽然不全,但足以应付考试。
1)“ + ” “ - ” 的重载(“ > ” 和 “ < ” 的重载同理,不过返回类型是bool)
class Complex{
private:
double real;
double imag;
public:
...
Complex operator+ (const Complex &c2) const;
Complex operator- (const Complex &c2) const;
...
}
...
Complex Complex::operator+ (const Complex &c2) const{
//返回值不是引用
return Complex(real+c2.real, imag+c2.imag);
}
Complex Complex::operator- (const Complex &c2) const{
//返回值不是引用
return Complex(real-c2.real, imag-c2.imag);
}
...
2)“ = ” “ += ” “ -= ” 的重载
//此处仅以等于符号的重载为例,其他两种相似
class Bitmap {
... }
class Widget{
...
private:
Bitmap *pb;
}
Widget& Widget::operator=(const Widget& rhs) //返回值是引用
{
if (this == &rhs) return *this; //如果是自我赋值,就什么都不做
delete pb;
pb = new Bitmap(*rhs.pb);
return *this;
}
3) 前置"++"与后置“++” 的重载
//详见课本P311-P312
Clock & Clock::operator++(){
//前置++的重载,返回值是引用
second++;
if (second>=60){
second-=60;
minute++;
if (minute>=60){
minute-=60;
hour=(hour+1)%24;
}
}
return *this;
}
Clock Clock::operator++ (int){
//后置++的重载,返回值不是引用
//注意形参表里的整型参数
Clock old=*this;
++(*this);
return old;
}有关返回值是否是引用造成的后果,可以体现在前置++与后置++的性能区别上,如下程序可以很好的展现这一点:
#include程序输出结果是:
44) 流输出“ << ” 与流输入 “ >> ” 的重载
class Rectangle {
private:
double a, b; //这个习惯很不好,为了方便而将length和width随意地写成了a和b
public:
...
double getArea() const {
return a * b; } //由于<<重载时的参数表内有const对象,而且此对象要调用该函数,所以这个函数也要加const,不然会报错,不信你试试
double getGirth() const {
return 2 * (a + b); } //由于<<重载时的参数表内有const对象,而且此对象要调用该函数,所以这个函数也要加const,不然会报错,不信你试试
friend ostream& operator<<(ostream& os, const Rectangle& x); //能加const就加const
friend istream& operator>>(istream& in, Rectangle& x) ; //由于输入时要改变类的成员变量的值,所以不能加const
...
}
...
ostream& operator<<(ostream& os, const Rectangle& x){
//能加const就加const
os << "The length and width are " << x.a << " and " << x.b << endl;
os << "The area is " << x.getArea() << endl;
os << "The girth is " << x.getGirth() << endl;
return os;
}
istream& operator>>(istream& in, Rectangle& x) {
//由于输入时要改变类的成员变量的值,所以不能加const
in >> x.a >> x.b;
if (!in) {
//是个好习惯,防止啥也不输入的情况
x = Rectangle();
}
return in;
}
...
2. 虚函数 Virtual
virtual宜继承时食用,效果最佳。virtual用法很简单,只需要最原始基类的某个函数声明为了virtual,它的子类们的这个函数都相当于带有virtual了(即使子类的这个函数不写virtual)。还有一个值得注意的是纯虚函数,这个往往用在抽象类上。有些抽象的东西是无法直接实例化的,比如说shape,让我画一个精准的shape(而且别人一看到就要知道这是shape而不是其他的东西),我是做不到的。shape太抽象,由shape继承而来的rectangle,triangle,circle之类的才具象。但是shape还是需要有的,为了表达一个概念并且继承出一堆东西,但它本身不需要构造一个实体并让它算面积求周长之类的,它什么也不需要做。所以需要有纯虚函数。
抽象类用法如下:参照课本p323
class Shape {
public:
virtual ~Shape() {
}; //多态基类的析构函数请声明为virtual
virtual double Area() = 0; //纯虚函数,Shape本身不需要计算面积
};其他神奇的virtual事项参见《Effective C++》条款07:为多态基类声明virtual析构函数 以及 条款09:绝不在构造和析构过程中调用virtual函数。
第9章 仅考函数模板和类模板
哈哈哈,只考template的用法,但是5555还是好难啊啊啊~
模板是为了高效,为了实现代码重用。也就是本来需要ctrl+c再ctrl+v的大量代码片段,可以缩减为小小的一块。用书上的话说,模板“可以实现参数化多态性”,而参数化多态性就是“将程序所处理的对象的类型参数化,使得一段程序可以用于处理多种不同类型的对象”。
其实这个含义挺好理解的,用法也比较简单,不过初学者还是会感到很奇葩,毕竟用到了新的英文单词叫template。不过代码多看多写也就熟悉了。既然本章讲的是模板,模板本身也是一个模板,只要把这个模板记住就至少能应付考试了。
1. 函数模板
格式如下:
#include,含义几乎完全相同
T abs(T x)
{
return x < 0 ? -x : x;
}
int main() {
int a = -5;
double b = -5.5;
cout << abs(a) << endl; //此时T被实例化为int
cout << abs(b) << endl; //此时T被实例化为double
return 0;
}
运行结果:
5
5.52. 类模板
格式如下:
#include,注意该行语句末尾没有分号
class Circle {
private:
T radius;
public:
Circle(T r=0);
T Area();
};
template<class T> //每次实现成员函数都要先写一段template
Circle<T>::Circle(T r):radius(r){
} //不用模板时是Circle:: 用了模板后要改成Circle::
template<class T>
T Circle<T>::Area() {
return 3.14 * radius * radius;
}
int main() {
Circle<int> a(1); //如果想要创建一个Circle对象必须先指明T是啥
Circle<double> b(1); //如果想要创建一个Circle对象必须先指明T是啥
cout << a.Area() << endl;
cout << b.Area() << endl;
return 0;
}运行结果:
3
3.14
第11章 流类库与输入输出
由于这一章节临近期末,所以上课时基本在复习其他学科\发抖…emm…基本没听课的我表示一脸懵逼…
输入与输出,这个概念本身是很好理解的。难点在于,有关输入流与输出流存在大量的新代码,这些代码是很难通过逻辑去记忆的,只能通过英语语义去记忆。换言之,该章节的难度不在于理解结构的精巧,而在于背英语单词般的痛苦。这是作为一名程序员所无法忍受的。不过好在代码本身就是为便捷而生,单词难度与数量都比4级低得多,多看看或者多写写也许就能记住。
不过,在背单词之前,首先值得注意的是,输入与输出的相对性。也就是说,对于毗邻的两个区域而言,当我们站在分界线上时,出一个区域恰恰意味着入另一个区域。出与入是相对的,输出与输入同理。所以理解输入与输出的对象可以让我们在背完单词后不会顿感迷茫。
下面来解释输入与输出。假设有一个叫input.txt的文件,还有一个程序,该程序的输出就是读取input.txt中的内容并将其复制粘贴到新构造的一个叫output.txt的文件中。那么,读取input.txt的过程,即input.txt的内容流出自身并流入程序中,是输入还是输出?答案是“输入”。也就是说,输入与输出是对于程序本身而言的,文档的内容流入程序就是“输入”,而该内容从程序流出并流入另一个程序叫做“输出”。
理解了输入与输出的相对性后,就可以开始背单词了。
1. 输出流
3个输出流:ostream, ofstream, ostringstream
3种输出:cout(标准输出), cerr(标准错误输出), clog(类似cerr, 但是有缓冲)
1) 构造输出流对象
ofstream fileo; //定义一个静态文件输出流对象
fileo.open(“output.txt”); //使用open函数,新建文本文档output.txt
2) 使用插入运算符和操纵符
(向流中)进行“写操作”被称为“插入”,插入运算符:<<;操纵符则定义在ios_base类以及iomanip头文件中。
输出宽度:#include
方式1:cout.width(10); cout<<…;
方式2:cout<
2. setw和width影响不是持久的
对齐方式:#include
#include
cout<
2. setiosflags影响是持久的,直到由resetiosflags重新恢复默认值
3. ios_base::left是左对齐,ios_base::right是右对齐,填充字符自动为空格,也可手动设置: cout.fill(’&’); //以&来填充
精度: cout< 进制: cout< 对于ofstream对象fileo,函数包括open, close, put, write, seekp, tellp和一堆错误处理函数。 fileo.open(“output.txt”, ios_base::out) //该处的ios_base::out可不写,因为是默认的。还可替换成ios_base::binary,这样将会以二进制模式打开文件 fileo.close(); //就像构造函数与析构函数的关系那样,既然打开了一个文件,那就必须在弃用时关闭它 fileo.put(‘A’); //等价于fileo<<‘A’; 如果说cout<<'A’是在屏幕上输出,fileo则是在output.txt里输出 write, seekp, tellp和一堆错误处理函数函数这里就不纠结了,参见课本p489-490 3个输入流:istream, ifstream, istringstream ifstream filei; //定义一个静态文件输入流对象 (在流中)进行“读操作”被称为“提取”,提取运算符:>>;操纵符则定义在ios_base类以及iomanip头文件中。 对于ifstream对象filei,函数包括open, close, get, getline, read, seekg, tellg 其中open函数和close函数与输出流基本同理 c=filei.get(); //等价于filei>>c; 如果说cin>>c是读取屏幕上的输入,filei则是读取input.txt的内容 getline, read, seekg, tellg在此处不加赘述,参见课本p494-p497 题目:新建output.txt文件,实现将input.txt的内容导入到output.txt中,同时每一段的段首加上一个引号 异常处理是为了啥?好像即使异常处理了,遇到异常程序还是终止了,反正即使不处理的话遇到异常程序也会中止,那为啥还要煞费苦心地写异常处理的代码呢?个人感觉首先是为了好看\发抖,就像出门前花去大把时间用来化妆那样,有了异常处理的程序遇到异常时出现的错误提示将由开发者定夺,会显得整洁美观。当然,花瓶也是要有实用性的。有些异常往往是让程序崩溃的那种,而且是莫名其妙的崩溃,这时候如果能有点有益的提示告诉用户除了什么问题的话往往可以省下大把时间。最后,不只是C++,其他语言比如Java,Python(当然这些语言也是由C++发展而来的)等等都有异常处理机制。不同于C++的是,其他语言如果运行时遇到错误,弹出的错误提示会直白地指出源代码第几行有啥错误。如果用户是个可爱的小白,那还没啥事;但如果用户是个不可爱的小黑,那么,本该被封装的程序代码本身的秘密将会被泄漏,程序被找到漏洞并被攻击那是迟早的事。所以,通过异常处理来让程序在遇到异常时换一种口吻,指出用户自己输入的错误,往往可以达到保护程序自身的目的。 啊!原来化妆也是大有裨益的!(很多男生,特别是程序员,无法理解的那种)不过,话说回来,异常处理其实有很多种方式,不过,课本第十二章只介绍了臃肿但功能齐全的一种异常处理方式,那就是try-throw-catch的方式,这种方式的灵活度比较大,但学起来比较头疼。其他异常处理方式比如exit()等等非常简单易学,此处将不介绍(应试教育被迫如此),如果想要自学可以参考《C++ primer plus》的15.3 异常 板块。 来看一个例子: 这个程序的运行结果是: 为什么会只显示一行?那是因为catch在抓住第一个错误后就不会理会其他错误了。 应用案例搭建了try-throw-catch用法的概念,至少可以用来应付考试了。 终于大功告成啦! 如果说还有什么要嘱托的话,那就是,在调试程序时要积极运用逐语句调试和逐过程调试哦~(在visual studio里的快捷键分别是F11和F10)这种调试方式可以使得程序逐句逐句运行,从而帮助你找到程序中的错误。 还是来展望一下未来吧! 考完C++后的假期该做些什么?我个人有以下愿望吧: 对于第1条,个人认为那些热衷于程序竞赛的孩纸们很有必要这么做,毕竟像ACM之类的比赛大多数人还是使用C++语言的(因为效率高,不啰嗦)。所以推荐一些书吧:《More Effective C++》《C++标准库》《深度探索C++对象模型》。当然,如果您非常渴望参加ACM之类的竞赛且缺乏经验,推荐程序设计竞赛入门级书籍《算法竞赛入门经典》(有三本)。值得注意的是,据说参加ACM的投入产出比非常低,几乎无法获得大奖,而一般奖项对出国保研等无益,只对实习工作很有帮助。所以,什么才能算真正的热爱程序设计?什么才能算非常渴望参加ACM?那就是,当你花费大量精力(放弃了一部分正常学业)拿了ACM金牌,却发现你心仪的读研的大学(国外或者国内)不认可这个奖项时,你能自豪地说出:“我不后悔!” 对于第2条,如果要自学Java,推荐的书籍是《Java编程思想》。这本书比较厚,但很有趣,建议读英文原版的(特别是对于那些想出国读研的朋友)。当然,如果您更爱听课而非看书的话,推荐中国大学MOOC上观看浙江大学《面向对象程序设计——Java语言》(翁恺老师讲的),当然如果一下子无法适应Java繁琐的语句的话,也可以先用2倍速看一看浙江大学《零基础学Java语言》(也是翁恺老师讲的)。MOOC真是一个好地方!好的大学没有围墙!当然也相信有些同学对Python语言很感兴趣,确实,无论是数据可视化、人工智能、网络爬虫等等都需要Python。Python是个很简洁的语言,入门书籍有《Python编程从入门到实践》(这本书可能连初中生都能看懂),进阶书籍包括《Python学习手册》(太厚了,以至于有人觉得繁琐)、《Python核心编程》(对初学者而言有点难)。当然也可以去听MOOC,推荐中国大学MOOC上北京理工大学的Python系列课(有好多门,一部分是嵩天老师讲的)。有关数据可视化、人工智能、网络爬虫的相关书籍暂时不推荐了,待笔者有了更直观的认知后再推荐吧。 对于第3条,数据结构据说是一门挺难的课,提前预习还是很有必要的。国内的教材有很多,可以使用清华大学出版社的数据结构(当然也有很多版本)。国外教材当然就是《算法导论》了,宛如圣经一般的算法书。如果要听MOOC的话,推荐中国大学MOOC中浙江大学《数据结构》,好评如潮的一门课。其他课程的话可以去B站上找找MIT的算法课(推荐那些要出国的孩纸多多围观国外大学课程)。另外,也有人说,先学一学离散数学对学数据结构有帮助,那就推荐一本《离散数学及其应用》。不过,听课之余得记住一条至理名言:一学就会、一写就废。所以要多多进行编程实验。 来一份附录吧(笔者推荐的课的网址): Java部分: 零基础学Java语言(浙大):https://www.icourse163.org/course/ZJU-1001541001 面向对象程序设计——Java语言(浙大):https://www.icourse163.org/course/ZJU-1001542001 Python语言程序设计:https://www.icourse163.org/course/BIT-268001 Python数据分析与展示:https://www.icourse163.org/course/BIT-1001870002 Python网络爬虫与信息提取:https://www.icourse163.org/course/BIT-1001870001 Python游戏开发入门:https://www.icourse163.org/course/BIT-1001873001 Python云端系统开发入门:https://www.icourse163.org/course/BIT-1001871002 Python科学计算三维可视化:https://www.icourse163.org/course/BIT-1001871001 数据结构(浙大):https://www.icourse163.org/course/ZJU-93001 离散数学概论(北大):https://www.icourse163.org/course/PKU-1002525004 MIT计算结构:https://www.bilibili.com/video/BV197411s736 MIT离散数学:https://www.bilibili.com/video/BV1zt411M7D2 MIT算法导论:https://www.bilibili.com/video/BV1Tb411M7FA3) 文件输出流成员
2. 输入流
1) 构造输入流对象
filei.open(“input.txt”); //使用open函数,打开已经写好的文本文档input.txt2) 使用插入运算符和操纵符
3) 文件输出流成员
3. 输入输出流的综合应用
程序如下:#include第12章 异常处理
由于这一章节临近期末,所以上课时也基本在复习其他学科\发抖…emm…基本没听课的我表示一脸懵逼…不过这一章的好处在于它的内容比较少,不至于像上一章那样疯狂记单词1. try-throw-catch
#include8除以0了!!!
当然,值得注意的是,在这个程序中catch(…)必须写在三个catch的最后一个,不然程序在运行前就会报错。报错为:“E0532,处理程序由默认处理程序屏蔽”
综上,try-throw-catch的总体格式如下:try{
...
}
catch(int e){
//处理int型异常
}
catch(const char* s){
//处理const char* 型异常
}
catch(...){
//处理所有类型的异常(考虑到throw出来的类型可能不止以上两种)
}
END
三. 后记
Python部分:
数据结构部分: