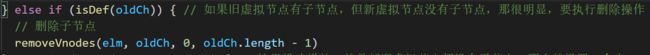vue 虚拟dom和diff算法详解
虚拟dom是当前前端最流行的两个框架(vue和react)都用到的一种技术,都说他能帮助vue和react提升渲染性能,提升用户体验。那么今天我们来详细看看虚拟dom到底是个什么鬼
虚拟dom的定义与作用
- 什么是虚拟dom
大家一定要记住的一点就是,虚拟dom就是一个普通的js对象。是一个用来描述真实dom结构的js对象,因为他不是真实dom,所以才叫虚拟dom。
- 虚拟dom的结构
从下图中,我们来看一看虚拟dom结构到底是怎样的

如上图,这就是虚拟dom的结构,他是一个对象,下面有6个属性,sel表示当前节点标签名,data内是节点的属性,elm表示当前虚拟节点对应的真实节点(这里暂时没有),text表示当前节点下的文本,children表示当前节点下的其他标签

- 虚拟dom的作用
1、我们都知道,传统dom数据发送变化的时候,我们都需要不断的去操作dom,才能更新dom的数据,虽然后面出现了模板引擎这种东西,可以让我们一次性去更新多个dom。但模板引擎依旧没有一种可以追踪状态的机制,当引擎内某个数据发生变化时,他依然要操作dom去重新渲染整个引擎。
而虚拟dom可以很好的跟踪当前dom状态,因为他会根据当前数据生成一个描述当前dom结构的虚拟dom,然后数据发送变化时,又会生成一个新的虚拟dom,而这两个虚拟dom恰恰保存了变化前后的状态。然后通过diff算法,计算出两个前后两个虚拟dom之间的差异,得出一个更新的最优方法(哪些发生改变,就更新哪些)。可以很明显的提升渲染效率以及用户体验
2、因为虚拟dom是一个普通的javascript对象,故他不单单只能允许在浏览器端,渲染出来的虚拟dom可同时在node环境下或者weex的app环境下允许。有很好的跨端性
什么是diff算法
diff算法就是用于比较新旧两个虚拟dom之间差异的一种算法。具体详情,后面我们会说
vue中的虚拟dom
目前虚拟dom的类库有多种,常见的有snabbdom和virtual-dom, vue以前用的是virtual-dom,从2.x版本后都是使用的snabbdom。(snabbdom源码下载) 今天,我们就通过snabbdom源码来解析vue的虚拟dom
首先我们看下snabbdom源码结构。
要搞清楚vue虚拟dom,我们就需要搞清楚几个核心的方法
- h函数
- patch函数
- patchVnode函数
- updateChildren函数
这几个核心函数的源码,看着可能会比较累,我就不一一对源码做详细的介绍,我主要会介绍每个函数主要做了什么事情,然后后面再附上源码,会加点注释,看的懂得可以详细看看
h函数
h函数,看着是不是很眼熟? 他是在vue的什么阶段去调用的?
眼熟吧,是不是在这地方看过啊。没错,h函数就是在render函数内运行的。我们在前面vue生命周期的文章中就提过,vue在created–>beforeMount之间的时候会将模板编译成render函数,其实就是将模板编译成某种格式放在render函数内,然后当render函数运行得时候,就会生成虚拟dom。那么编译成什么格式呢。就是编译成h函数所认可的格式。那么我们来看看h函数需要什么格式

有的人可能会说,唉,这个h函数怎么定义了多个啊。没错,h函数是使用函数重载的方式定义的,那么什么是函数重载
函数重载
函数重载就是定义多个重名函数,利用函数的参数个数以及参数类型来区分。当参数个数不同,参数类型不同时,函数内执行的代码也会相应不同。
下面,我们就来看下最典型得一种,也就是图中得第四种。
- 第一个参数sel 表示dom选择器,如: div#app.wrap ==》
- 第二个参数表示dom属性,是个对象如:{ class: ‘ipt’, value: ‘今天天气很好’ }
- 第三个参数表示子节点,子节点也可以是一个子虚拟节点,也可以是文本节点
const vdom = h('div', {
class: 'vdom'}, [
h('p', {
class: 'text'}, ['hello word']),
h('input', {
class: 'ipt', value: '今天星期二' })
]) // 模板就是会编译成这种格式
console.log(vdom)
而h函数内最主要得就是执行了 vnode函数,vnode函数得主要作用就是将h函数传进来得参数转行为了js对象(即虚拟dom)
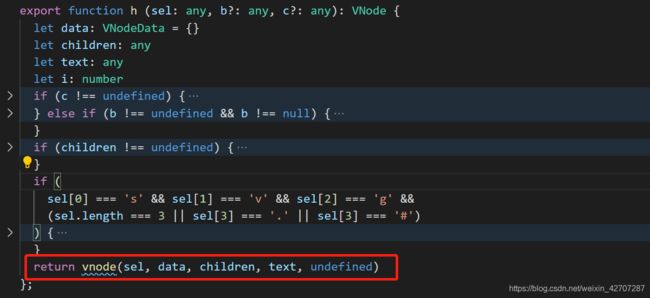
而vnode函数,我就不多说了,没几句代码,也很简单,反正就是执行了生成js对象(虚拟dom)的代码。直接上图
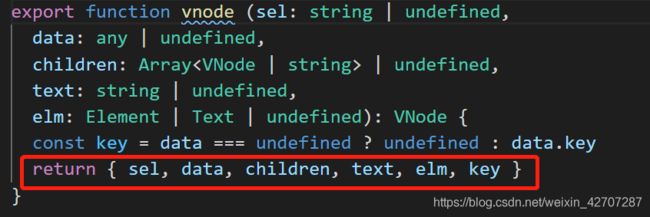
看到现在,我们心里应该要清楚虚拟dom是怎么生成的,什么时候生成的。如果不清楚,那么请往上滑,再看一遍,哈哈。下面我们总结下虚拟dom生成的过程。
- 首先,代码初次运行,会走生命周期,当生命周期走到created到beforeMount之间的时候,会编译template模板成render函数。然后当render函数运行时,h函数被调用,而h函数内调用了vnode函数生成虚拟dom,并返回生成结果。故虚拟dom首次生成。
- 之后,当数据发生变化时会重新编译生成一个新vdom。再后面就等待新 旧两个vdom进行对比吧。我们后面就继续说对比的事情。
diff 比较规则
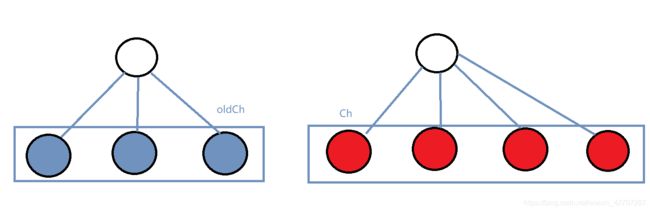
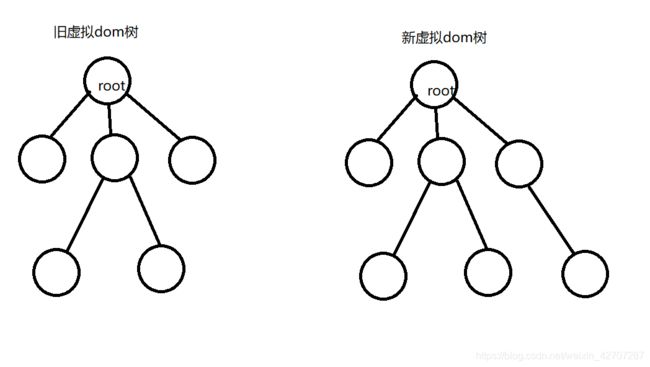
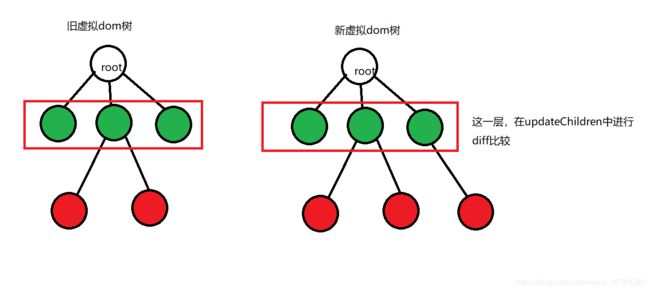
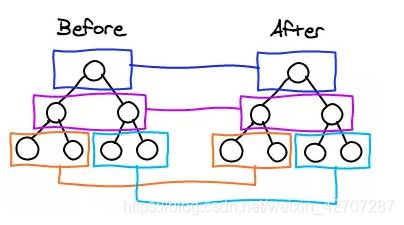
1、diff 比较两个虚拟dom只会在同层级之间进行比较,不会跨层级进行比较。而用来判断是否是同层级的标准就是
- 是否在同一层
- 是否有相同的父级
下面,我们来一张图,就很好理解了(盗用网上一张很经典的图)
2、diff是采用先序深度优先遍历得方式进行节点比较的,即,当比较某个节点时,如果该节点存在子节点,那么会优先比较他的子节点,直到所有子节点全部比较完成,才会开始去比较改节点的下一个同层级节点。不好理解吗?没关系,我们画个图看一下,就很清晰了
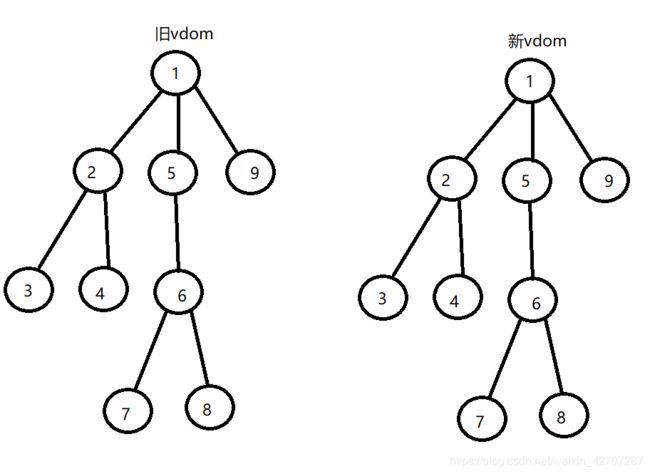
当比较新旧两个dom时,会按照图中1-9的顺序去进行比较。
不过,既然话都说到他的比较顺序了,我就想干脆,先整体将他每一步是如何比较的,让大家心里有一个总体的比较思路后,我们再去一步一步看patch函数,patchVnode函数和updateChildren函数
diff比较整体思路
首先开始比较两个vdom时,这两个vdom肯定是都有各自的根节点的,且根节点必定是一个元素,不可能存在多个。我们首先要比较的肯定是根节点,那我们都知道根节点只有一个,就可以直接比较了。而一个节点的比较,通常分为3个部分
声明,下面所说的sel选择器相同,指的是标签名,id,class都相同。
例如
’这样一个dom,他的sel是"div#app.abc"
- 比较两个节点是否是相同节点,判断是否是相同节点的条件是,key和sel(选择器)必须都相同(那有的人可能会说了,那我标签没有key怎么办啊,没有key那就是undefined,undefined === undefined 始终为true,所以没有key只需要保证sel相同就行)。如果不相同,那么执行替换操作(即新增新vnode上的元素,删除旧vnode上的元素 例如,原来是div,新vnode变成了p,那么就是新增p元素,再删除div元素。相当于就是p替换了div),这一步,只有比较根节点时,是在patch函数中进行的。非根节点都是在updateChildren函数中执行的,因为根节点只会有一个,可以直接比较,而其他节点会存在多个,需要通过一些算法来判断,具体详情后面会说
- 如果节点相同,那么进去第二部分,即比较两个节点的属性是否相同,节点是否存在文本,文本是否相同。是否存在子节点,子节点是否相同。这部分主要在patchVnode中执行
那么,在第二部分,会做哪些事情呢。
1、如果存在文本时,更新文本
2、如果存在属性时,更新属性
3、如果存在子节点时,更新子节点
那么,如何更新呢,逻辑也很简单,遵循以下规则:
1、如果旧vnode上存在,而新vnode上不存在,那么执行删除操作
2、如果旧vnode上不存在,而新vnode上存在,那么执行新增操作
3、如果新旧vnode上都存在,那么执行替换操作(即,新增新的,删除旧的),文本,和属性的替换是在这部分完成。而对于子节点,如果新vnode和旧vnode上都存在子节点时,那么会进入第三部分比较。比较子节点的差异。- 第三部分,主要在updateChildren函数中执行,主要用于比较某个节点下的子节点差异。而在这里,就要用到diff的一个算法了。具体怎么算。我们后面详细说updateChildren时再说。
可能大家看的有点懵,没关系,看完心里有个大概的步骤就好,下面我们再来详细讲每一步对应的函数
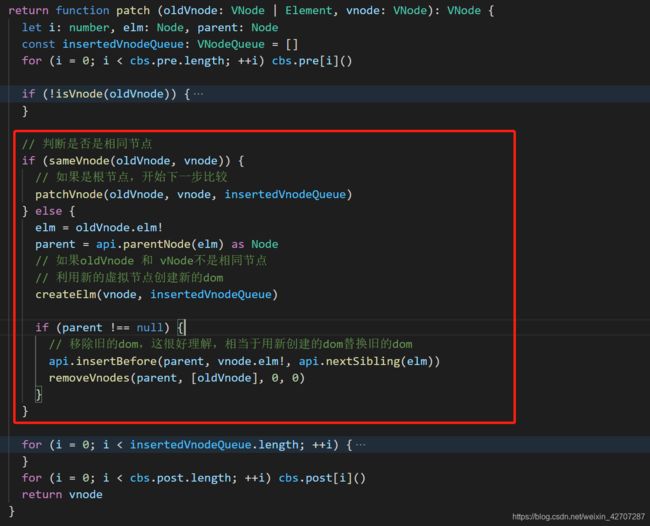
patch 函数
上面我们说了,patch是比较的开始,相当于是diff的入口,diff就是从这一步开始的。那么既然是开始,说明patch函数比较的肯定就是两个新旧vdom的根节点了。所以,两个vdom直接的比较,patch是只会触发一次的。
作用:比较两个虚拟dom根节点是否相同。下面我们看下主要的核心代码
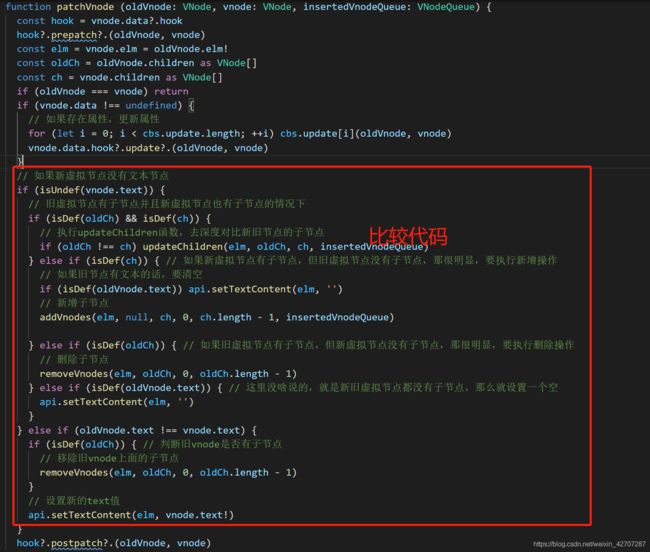
patchVnode
patchVnode 是用于比较两个相同节点的子级(文本,或子节点)的一个函数。故它的调用总是在sameVnode判断之后。只有判断当前比较的两个vnode相同时(这里我最后再解释一次,两个vnode相同仅仅代表key相同且sel选择器相同),才会被执行。
但,在比对之前,会先判断下oldVnode === vNode ,因为如果全等,代表子级肯定也完全相等,那么就没必要对比了,直接return;
作用:对比新旧两个节点,更新dom的子级(子级包含文本或者是子节点)
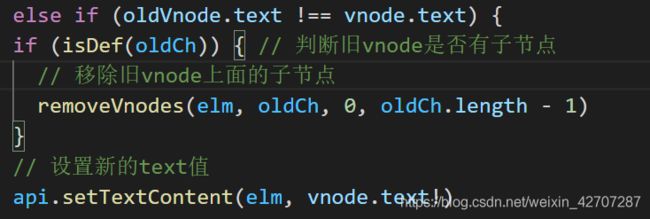
对比过程:1、如果新vnode有text属性
- 旧vnode是否有子节点,如果有,代表原来是子节点,现在变成文本了,那么删除子节点,并且设置vnode对象的真实dom的text值(使用setTextContent函数)
- 其他情况不用管,直接设置vnode对象的真实dom的text值
2、如果新vnode没有text属性
如果新vnode和旧vnode都存在子节点时。是不是要深度对比两个vnode的子节点啊。这个时候会进入第三步,比较子节点(执行updateChildren)
如果只有新vnode有子节点,老vnode没有,那么很简单,执行添加节点的操作
如果只有旧vnode有子节点,新vnode没有子节点,很明显,要执行删除旧vnode子节点的操作
如果两个vnode上都没有子节点。但旧节点有text,那么很简单,说明原来有文本,现在没有了,清空vnode对应dom的text
下面,我们看下整体代码
updateChildren
终于到这最复杂的一步了。首先,我先说一下这一步的作用以及具体做了些什么
作用:用于比较新旧两个vnode的子节点
那具体做了什么,怎么比较的。
比较规则声明:下文中所指的匹配上,指的就是判断是否是sameVnode,即上文中所说的,key相同,sel选择器相同
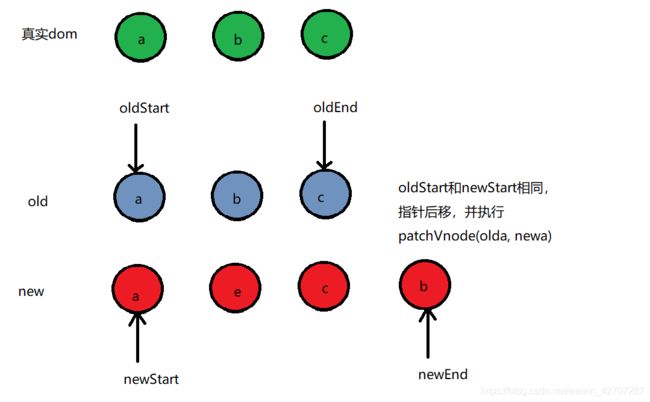
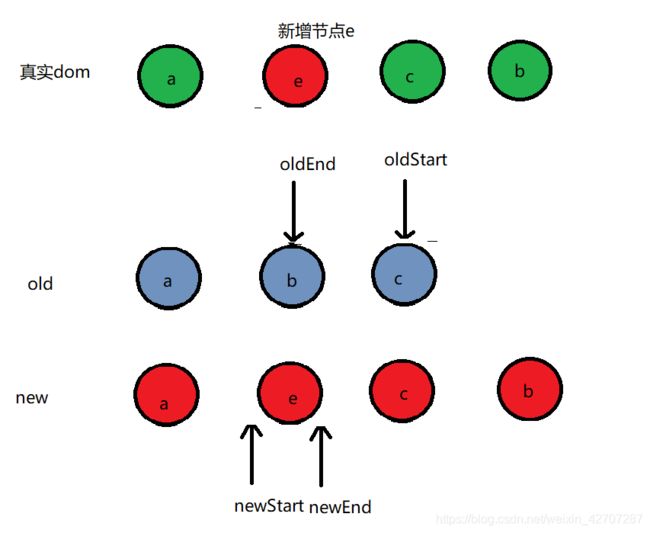
- 首先,会将新旧vnode的子节点(oldCh, Ch)提取出来,并分别加上两个指针oldStart, oldEnd, newStart, newEnd。分别指向odlCh的第一个节点,oldCh的最后一个节点,Ch的第一个节点,Ch的最后一个节点
- 比较时,会优先拿oldStart<—>newStart,oldStart<—>newEnd,oldEnd<—>newStart,oldEnd<—>newEnd 两两进行对比。如果匹配上,那么会将旧节点对应的真实dom移到新节点的位置上。并将匹配上了的指针往中间移动。同时匹配上了的两个节点会继续指向patchVnode函数去进一步比对(指针的移动相当于永远保持指针中间的节点还是尚未匹配状态,已经匹配到的移到指针外面去)
- 如果上面4种比较都没有匹配上,那么这个时候,有key和没key处理方式就不一样了。具体怎么处理,后面会细说。
- 当oldStart > oldEnd 或者 newStart > newEnd时,结束对比。此时
1、如果是oldStart > oldEnd,代表oldCh都已匹配完成,而此时,如果newStart <= newEnd,那么代表 newStart 和 newEnd直接的节点为新增节点。那么真实dom会在当前newStart 和newEnd之间新增newStart 和 newEnd中间还未匹配的节点。
2、如果是newStart > newEnd,代表Ch全都已经匹配完成,而此时,如果oldStart 和 newEnd之间还有节点,则说明,这些节点是原来存在的,但现在没有了,此时真实dom删除这些节点。
此时,比较结束。下面,我们通过图例来进一步理解
上图表示的就是oldCh 和 Ch。那么怎么来比较。我们一一来看每一种情况
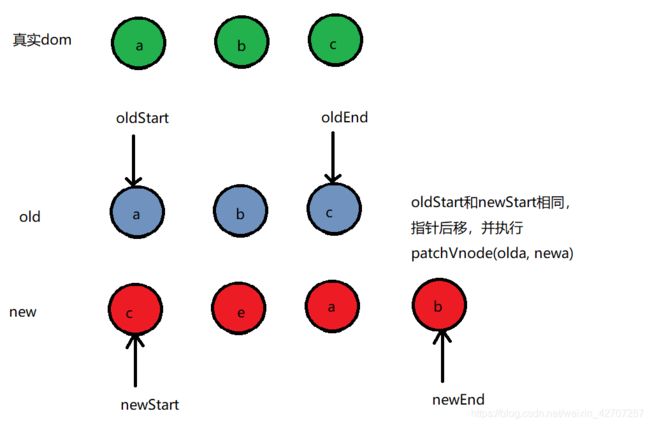
- oldStart 和 newStart相同
指针后移后,
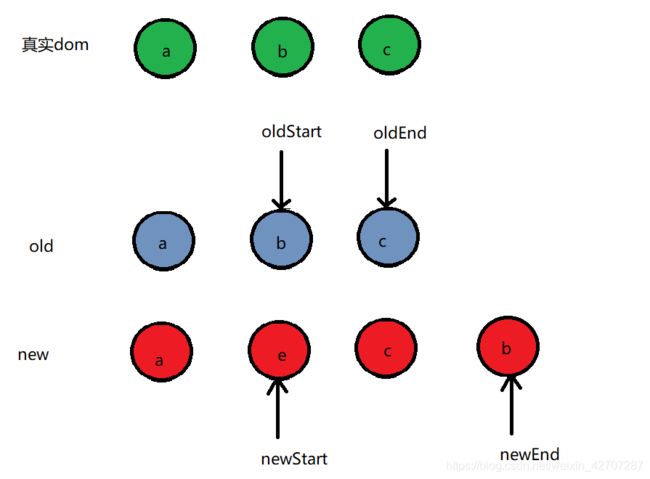
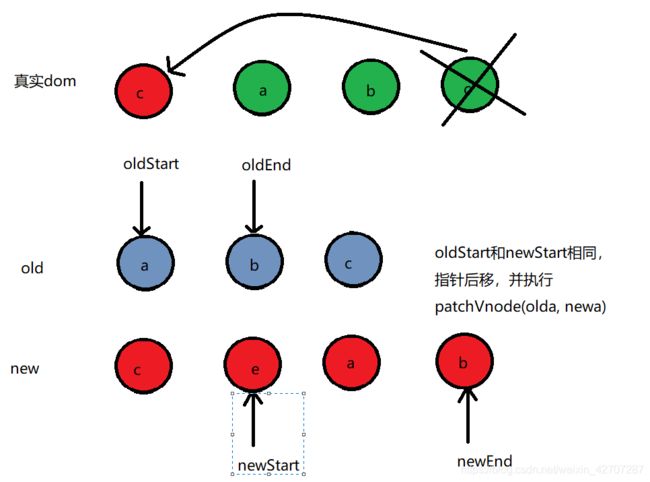
- oldStart 和 newEnd相同,此时会将oldStart对应的真实dom移动newEnd对应的位置
我们就以上图为例了,不重新画图了,上图,oldStart 和 newEnd相同,此时真实dom会将b移动最末尾。同时oldStart 和 newEnd指针向中间移
- oldEnd 和 newEnd相同 。我们还是以上图为例(就是这么巧,上图刚好oldEnd和 newEnd相同,哈哈)c 和 c相同,oldEnd 和 newEnd往中间移动,并执行patchVnode(oldc,newc)
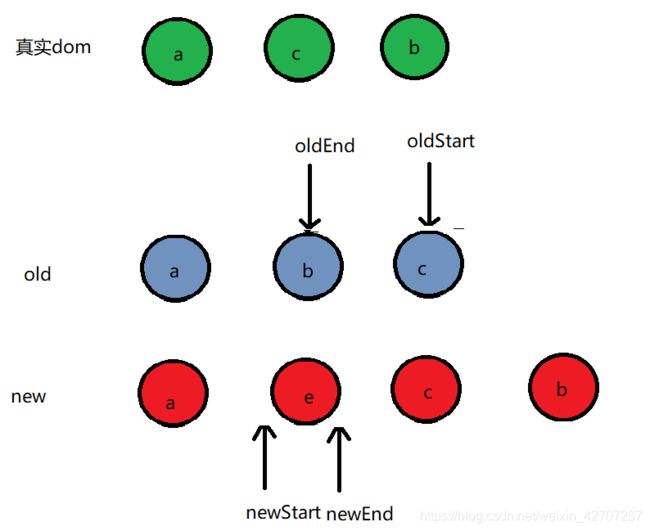
- oldEnd和newStart相同的我们后面再画,根据上图,我们继续将oldStart > oldEnd的情况。上图中,oldStart 大于 oldEnd,说明oldCh已经全部匹配完,而此时newCh中,newStart 和 newEnd之间还有个e没有匹配。那说明e是新增节点。此时真实dom会在newStart和newEnd之间新增还未匹配的dom(新增节点执行addVnodes函数)
此时,整个oldCh和newCh的比较就已经完成了。可以看到,此时,真实dom已经变成和newCh的一样了。- oldEnd 和 newStart 相同时
此时,oldEnd所对应的真实dom会移动newStart所在位置,然后oldEnd 和 newStart指针往中间移动。移动后,如下图
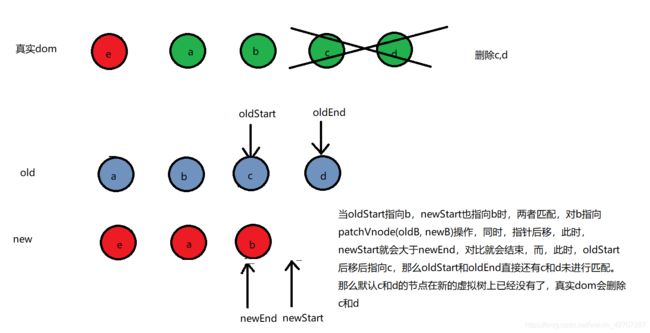
- 当newStart > newEnd的时候,此时,如果oldStart 和 oldEnd之间还存在没有匹配完成的节点时,那么认为,oldCh中,那么还没匹配到的节点在新的虚拟dom树上已经没有了,此时,执行删除操作(removeVnodes函数),删除还oldStart和oldEnd之间的节点。
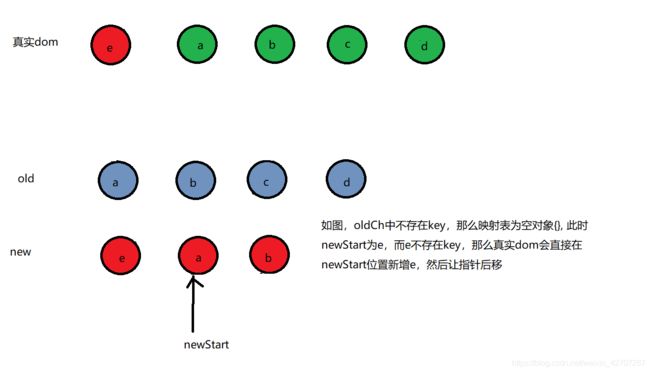
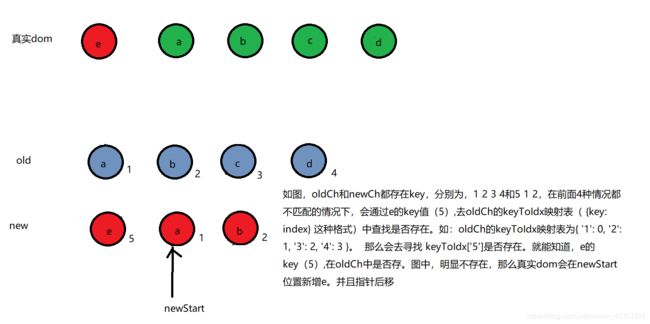
好了,现在前面4种情况以及两种匹配结束时的情况我们已经说完了。现在就剩最后一种情况,即:头尾分别都没匹配上,且没有结束比较的时候。我们继续来看第7种情况。- 当前面(1,2,3,5)这4种情况都匹配不到时,会拿当前newStart指针所指的那个节点去和oldCh中找。看是否能找到。这个时候,就要看是不是存在key了。因为首先,会建立一个oldCh中key和index的一个映射表,格式为{key: idx}。如果都没有key,那么映射表为空对象{}。此时会有3种情况
1、如果newStart指针所指的节点不存在key,那么不会去oldCh中寻找和这个一样的节点。而是直接新增newStart所指的这个节点,新增后,newStart指针后移
2、如果newStart指针所指的节点存在key,那么会去oldCh的key和Idx的映射表中寻找newStart节点的key是否存在。如果不存在,那么默认newStart节点为新增节点。真实dom会在newStart位置直接新增节点。新增完成后,指针后移
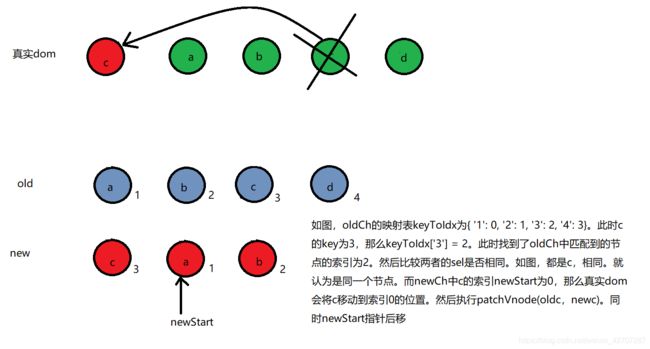
3、同样newStart指针所指的节点存在key,那么去oldCh的映射表中查找。此时如果找到了。那么会继续判断key相同的这两个节点的sel选择器是否相同。如果也相同,那么默认这是同一个节点,那么真实节点会将匹配到的节点,移到newStart对应的位置,然后执行patchVnode(oldVnode, newVnode)进行进一步对比。同时newStart指针后移。而oldCh中被匹配到的那个位置,置为undefined。
总体过程就是这样,然后不停的patchVnode,updateChildren循环递归下去,知道oldVode和newVnode所有节点都对比完成。下面附上updateChildren函数源码(每一步都添加了详细注释)
function updateChildren (parentElm: Node,oldCh: VNode[],newCh: VNode[],insertedVnodeQueue: VNodeQueue) { let oldStartIdx = 0 let newStartIdx = 0 let oldEndIdx = oldCh.length - 1 let oldStartVnode = oldCh[0] let oldEndVnode = oldCh[oldEndIdx] let newEndIdx = newCh.length - 1 let newStartVnode = newCh[0] let newEndVnode = newCh[newEndIdx] let oldKeyToIdx: KeyToIndexMap | undefined let idxInOld: number let elmToMove: VNode let before: any // 通过while不断循环进行对比,直到oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) { if (oldStartVnode == null) { // 这一步的操作是始终保证oldStartVnode为oldStartIdx指针所指向的那个节点 oldStartVnode = oldCh[++oldStartIdx] } else if (oldEndVnode == null) { // 这一步的操作是始终保证oldEndVnode为oldEndIdx指针所指向的那个节点 oldEndVnode = oldCh[--oldEndIdx] } else if (newStartVnode == null) { // 这一步的操作是始终保证newStartVnode为newStartIdx指针所指向的那个节点 newStartVnode = newCh[++newStartIdx] } else if (newEndVnode == null) { // 这一步的操作是始终保证newEndVnode为newEndIdx指针所指向的那个节点 newEndVnode = newCh[--newEndIdx] } else if (sameVnode(oldStartVnode, newStartVnode)) { // oldStart和newStart相同时,执行patchVnode进一步比较 patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue) oldStartVnode = oldCh[++oldStartIdx] // 并将指针往中间移动 newStartVnode = newCh[++newStartIdx] // 并将指针往中间移动 } else if (sameVnode(oldEndVnode, newEndVnode)) { // oldEnd和newEnd相同时,执行patchVnode进一步比较 patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue) oldEndVnode = oldCh[--oldEndIdx] // 并将指针往中间移动 newEndVnode = newCh[--newEndIdx] // 并将指针往中间移动 } else if (sameVnode(oldStartVnode, newEndVnode)) { // oldStart和newEnd相同时,执行patchVnode进一步比较 patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue) api.insertBefore(parentElm, oldStartVnode.elm!, api.nextSibling(oldEndVnode.elm!)) oldStartVnode = oldCh[++oldStartIdx] // 并将指针往中间移动 newEndVnode = newCh[--newEndIdx] // 并将指针往中间移动 } else if (sameVnode(oldEndVnode, newStartVnode)) { // oldEnd和newStart相同时,执行patchVnode进一步比较 patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue) api.insertBefore(parentElm, oldEndVnode.elm!, oldStartVnode.elm!) oldEndVnode = oldCh[--oldEndIdx] // 并将指针往中间移动 newStartVnode = newCh[++newStartIdx] // 并将指针往中间移动 } else { // 这里面就是当前面4种情况都不匹配时的处理结果 if (oldKeyToIdx === undefined) { // 存在key的情况下 得到oldCh中 key和idx的一个映射关系,格式为{key: idx}, oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx) } idxInOld = oldKeyToIdx[newStartVnode.key as string] // 通过key,找到当前key的节点在oldCh中的位置,如果找不到会返回undefined if (isUndef(idxInOld)) { // 如果是undefind,说明newStartVnode的节点的key在oldCh中不存在,或者newStartVnode没有key // 此时会直接创建新的节点,所以key的设置,会优化比较步骤 api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm!) } else { // 如果找到了newStartVnode的可以在oldCh中的位置,说明可能只是移动了位置。 elmToMove = oldCh[idxInOld] // 获取需要移动的旧节点 if (elmToMove.sel !== newStartVnode.sel) { // 如果旧节点和新节点的sel不同,代表变了(比如原来是div,现在变成了p) // 新增新的节点 api.insertBefore(parentElm, createElm(newStartVnode, insertedVnodeQueue), oldStartVnode.elm!) } else { // sel相等,说明是相同节点,那么patchVnode进一步进行比较 patchVnode(elmToMove, newStartVnode, insertedVnodeQueue) oldCh[idxInOld] = undefined as any // 真实节点移动到相应的位置 api.insertBefore(parentElm, elmToMove.elm!, oldStartVnode.elm!) } } // newStart指针往中间移 newStartVnode = newCh[++newStartIdx] } } if (oldStartIdx <= oldEndIdx || newStartIdx <= newEndIdx) { // 如果比对结束 if (oldStartIdx > oldEndIdx) { // newCh的start和end之间还有节点时,新增这些节点 before = newCh[newEndIdx + 1] == null ? null : newCh[newEndIdx + 1].elm addVnodes(parentElm, before, newCh, newStartIdx, newEndIdx, insertedVnodeQueue) } else { // 否则 oldCh的start和end之间还有节点时,移除这些节点 removeVnodes(parentElm, oldCh, oldStartIdx, oldEndIdx) } } }总结
我们在最后整理一下步骤。
1、比较两个虚拟dom树,对根节点root进行执行patch(oldVnode,newVnode)函数,比较两个根节点是否是相同节点。如果不同,直接替换(新增新的,删除旧的)
2、如果相同,对两个节点执行patchVnode(oldVnode, newVnode),比较属性,文本,已经子节点。此时,要么新增,要么删除。要么直接修改文本内容。只有当都存在子节点时,并且oldVnode === newVnode 为false时。会执行updateChildren函数,去进一步比较他们的子节点。
3、比较分3大类。
第一类:oldStart === newStart, oldStart === newEnd,oldEnd === newStart,oldEnd === newEnd 这4种情况的比较。如果这4种情况中任何一种匹配。那么会执行patchVnode进一步比较。同时指针往中间移第二类:oldStart > oldEnd 或者 newStart > newEnd时。表示匹配结束。此时,多余的元素删除,新增的元素新增。
第三类:上面几种情况都不匹配。那么这个时候key是否存在。就起到关键性作用了。存在key时,可以直接通过key去找到节点的原来的位置。如果没有找到,就新增节点。找到了,就移动节点位置。查找效率非常高
而如果没有key呢,那么压根就不会去原来的节点中查找了。而是直接新增这个节点。这就导致这个节点下的所有子节点都会被重新新增。会出现明显的性能损耗。所以,合理的应用key,也是一种性能上的优化。总之一句话。diff的过程,就是一个 patch —> patchVnode —> updateChildren —> patchVnode —> updateChildren —> patchVnode… 这样的一个循环递归的过程
题外话 diff和数据劫持的共同工作原理
另外,我这里再插一句。可能有的人会疑惑了,那我通过这个虚拟dom的diff算法,就能精准的知道被更新的地方在哪,然后去更新变动的部分。那我vue靠这个就够了呀。我为什么还需要数据劫持呢,还需要getter,setter呢。没错,其实单单靠虚拟dom的diff确实是可以实现的。比如react就是这么做的。react精确查找数据的更新就是纯用虚拟dom的diff的。
但是这会产生一个什么问题呢。当项目非常大的时候,dom树是非常复杂的,如果每次一个小小的改动,就要通过diff算法去精确找到改动的地方,那么这个计算量是非常大的。产生的性能损耗也会巨大。这显然是不合理的。那么vue和react分别是怎么解决这个问题的vue: 了解vueMVVM原理的人应该都清楚,vue通过Object.defineproperty的数据劫持,会劫持到每一个状态数据,给他们加上getter,setter。并且创建一个发布者Dep,同时,会给依赖这个状态数据的每个依赖者添加一个订阅者watcher。这样,当数据发生变化时,会触发对应的setter,从而Dep会发布通知,通知每一个订阅者watcher,然后watcher更新对应的数据。但是,如果任何一个数据的依赖我都增加一个watcher。那么项目中的watcher数量是会非常庞大的。细粒度太高,会带来内存和依赖关系维护的巨大消耗。这样一种情况下,vue采用响应式+diff的方式。通过响应式的getter,setter快速知道数据的变化发生在哪个组件中,然后组件内部再通过diff的方式去获取更详细的更新情况,并更新数据。
react: 而react却是通过他的一个生命周期函数shouldComponentUpdate实现的。通过手动在这个生命周期函数中判断当前组件的数据是否有发生变化,来决定当前组件是否需要更新。这样,没有发生状态数据变化的组件就不需要进行diff。从而缩小diff的范围。
好了,今天的文章就写到这了。如果有问题,欢迎评论!!