Python与Java操作Spark
一、Python操作Spark
测试数据如下:
"id","name","money"
"1","aaa","900"
"2","bbb","1000"
"3","ccc","1000"
"5","ddd","1000"
"6","ddd","1000"
安装pyspark用于操作,findspark查找配置
1、RDD
import findspark
findspark.init()
from pyspark.sql import SparkSession
sparkSession = SparkSession.builder.appName("spark").master("local").getOrCreate()
rdd = sparkSession.read.option("header", True).csv("../files/account.csv").rdd
for row in rdd.collect():
print(row)
运行结果:

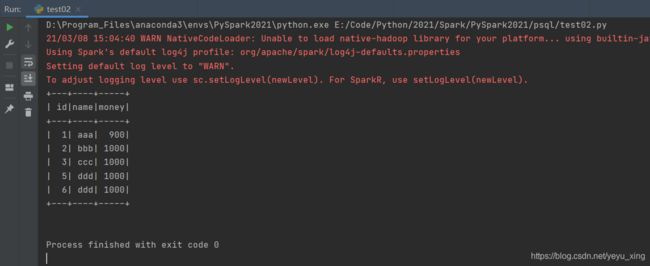
2、SparkSQL
import findspark
findspark.init()
from pyspark.sql import SparkSession
sparkSession = SparkSession.builder.appName("spark").master("local").getOrCreate()
df = sparkSession.read.option("header", True).csv("../files/account.csv")
df.createTempView("account")
sparkSession.sql("select * from account").show()
运行结果:
3、读取hdfs上的文件
import findspark
findspark.init()
from pyspark.sql import SparkSession
sparkSession = SparkSession.builder.appName("spark").master("local").getOrCreate()
df = sparkSession.read.option("header", True).csv("hdfs://master:9000/testdata/account/account.csv")
df.createTempView("account")
sparkSession.sql("select * from account").show()
二、Java操作Spark
测试数据如下:
"id","name","money"
"1","aaa","900"
"2","bbb","1000"
"3","ccc","1000"
"5","ddd","1000"
"6","ddd","1000"
导入maven坐标:
<dependency>
<groupId>org.apache.sparkgroupId>
<artifactId>spark-sql_2.12artifactId>
<version>2.4.7version>
dependency>
1、RDD
package com.it.spark_sql;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class SparkDemo01 {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("spark");
SparkContext sc = new SparkContext(conf);
SparkSession sparkSession = new SparkSession(sc);
JavaRDD<Row> rdd = sparkSession.read().option("header", true).csv("files/account.csv").toJavaRDD();
for (Row row : rdd.collect()) {
System.out.println(row);
}
sparkSession.close();
}
}
运行结果:

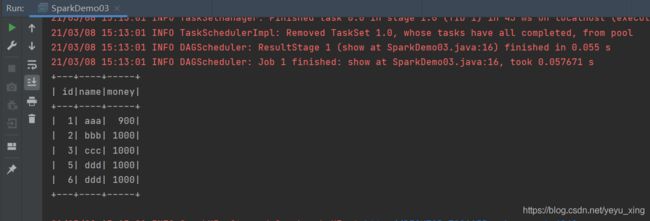
2、SparkSQL
package com.it.spark_sql;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class SparkDemo02 {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("spark");
SparkContext sc = new SparkContext(conf);
SparkSession sparkSession = new SparkSession(sc);
Dataset<Row> ds = sparkSession.read().option("header", true).csv("files/account.csv");
ds.createOrReplaceTempView("account");
sparkSession.sql("select * from account").show();
sparkSession.close();
}
}
运行结果:

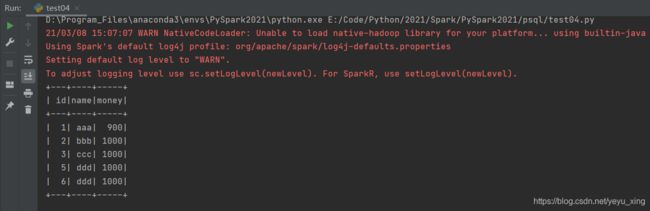
3、读取hdfs上的文件
package com.it.spark_sql;
import org.apache.spark.SparkConf;
import org.apache.spark.SparkContext;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
public class SparkDemo03 {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("spark");
SparkContext sc = new SparkContext(conf);
SparkSession sparkSession = new SparkSession(sc);
Dataset<Row> ds = sparkSession.read().option("header", true).csv("hdfs://master:9000/testdata/account/account.csv");
ds.createOrReplaceTempView("account");
sparkSession.sql("select * from account").show();
sparkSession.close();
}
}
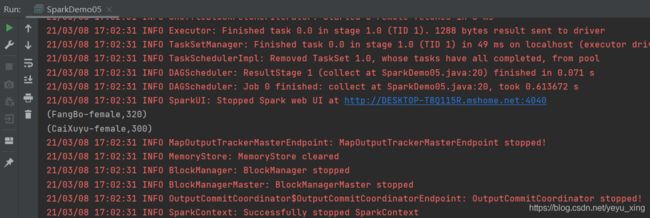
三、案例
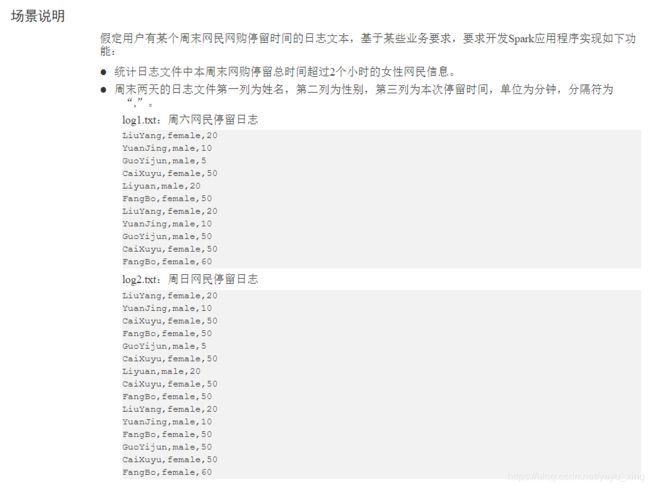
数据:
LiuYang,female,20
YuanJing,male,10
GuoYijun,male,5
CaiXuyu,female,50
Liyuan,male,20
FangBo,female,50
LiuYang,female,20
YuanJing,male,10
GuoYijun,male,50
CaiXuyu,female,50
FangBo,female,60
LiuYang,female,20
YuanJing,male,10
CaiXuyu,female,50
FangBo,female,50
GuoYijun,male,5
CaiXuyu,female,50
Liyuan,male,20
CaiXuyu,female,50
FangBo,female,50
LiuYang,female,20
YuanJing,male,10
FangBo,female,50
GuoYijun,male,50
CaiXuyu,female,50
FangBo,female,60
1、Python代码
import findspark
findspark.init()
from pyspark import SparkContext
sc = SparkContext()
result = sc.textFile("../files/inputdata.txt").map(
lambda line: ('{}-{}'.format(line.split(",")[0], line.split(",")[1]), int(line.split(",")[2]))
).reduceByKey(lambda a, b: a + b) \
.filter(lambda i: i[1] > 120) \
.filter(lambda i: 'female' in i[0])\
.collect()
for i in result:
print(i)
运行结果:

2、Java代码:
package com.it.spark_sql;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
public class SparkDemo05 {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("local").setAppName("spark");
JavaSparkContext jsc = new JavaSparkContext(conf);
JavaPairRDD<String, Integer> female = jsc.textFile("files/inputdata.txt")
.mapToPair(tuple2 -> {
String[] fields = tuple2.split(",");
return new Tuple2<>(fields[0] + "-" + fields[1], Integer.parseInt(fields[2]));
}
)
.reduceByKey(Integer::sum).filter(tuple2 -> tuple2._1.contains("female"))
.filter(tuple2 -> tuple2._2 > 120);
female.collect().forEach(System.out::println);
jsc.close();
}
}
运行结果: