正则 指定开头结尾_Python核心知识系列:正则表达式与JSON

1 正则表达式必知必会
1.1 简介
正则表达式:是一些用来匹配和处理文本的字符串。
正则表达式的使用场景主要以下两种情况:一是查找特定的信息(搜索),二是查找并编辑特定的信息(替换)。
用模式(pattern)表示实际的正则表达式。
1.2 匹配单个字符
- 匹配普通文本:正则表达式为待匹配的文本。
- 匹配任意字符:
.字符(英文句号)可以匹配任意单个字符,如字符、字母、数字,甚至是.字符本身。 - 匹配特殊字符:使用
转义地字符,如.。
1.3 匹配一组字符
- 匹配多个字符中的某一个
使用[]定义一个字符集合,对于连续字符使用-连字符来定义字符区间。集合内字符是OR关系,匹配其中之一。
[A-Z]:匹配从A到Z的所有大写字母。
[a-z]:匹配从a到z的所有小写字母。
[0-9]:匹配从0到9的所有数字。
- 排除
使用元字符^来排除字符集合里指定的那些字符,如[^0-9]。注意,^的效果将作用于给定字符集合里的所有字符或字符区间。
1.4 使用元字符
1.4.1 元字符转义
元字符:在正则表达式里有特殊含义的字符。
转义:元字符可以通过在前面加上一个反斜杠()进行转义,这样匹配的就是该字符本身而不是特殊的元字符含义。
1.4.2 匹配空白字符
元字符大概可以分为两种:一种是用来匹配文本的(如.),另一种是正则表达式语法的组成部分(如[])。
空白元字符:换页符(f)、换行符(n)、回车符(r)、制表符(t)。
一般来说,需要匹配r、n和t等空白字符的情况比较多见。rn匹配一个回车+换行组合。
1.4.3 匹配特定的字符类型
- 匹配数字与非数字:
d:任何一个数字字符(等价于[0-9])
D:任何一个非数字字符(等价于[^0-9])
- 匹配字母数字或下划线:
w:任何一个字母数字或下划线字符(等价于[a-zA-Z0-9_])
W:任何一个非字母数字或非下划线字符(等价于[^a-zA-Z0-9_])
- 匹配空白字符与非空白字符:
s:任何一个空白字符(等价于[fnrtv])
S:任何一个非空白字符(等价于[^fnrtv])
1.5 重复匹配
- 匹配一个或多个字符:
+匹配一个或多个字符,在一个给定字符集合加上+后缀时,必须放在整个字符集合的外面,如[0-9]+。
一般来说,当在字符集合使用时,像.和+这样的元字符被解释为普通字符,不需要转义,但转义也不影响。
- 匹配零个或多个字符:
*用来匹配字符或字符集合出现零次或多次的情况。
- 匹配零个或一个字符:
?可以匹配某个字符或字符集合的零次或一次。
[]的常规用法是把多个字符定义为一个集合,但不少程序员喜欢把一个字符也定义为一个集合,好处是可以增加可读性和避免产生误解。同时使用[]和?时,要把?放在字符集合的外面。
- 具体的匹配次数:
设置具体的匹配次数,把数字写在{}中,如{3}。
可以为重复匹配的次数设定一个区间范围,设置最小次数和最大次数,如{3, 5}。
也可以指定至少要匹配的次数,如{3, }。
- 防止过度匹配:
在使用重复匹配如果没有上限值,则有时会导致过度匹配的现象。
像*和+这些都是“贪婪型”元字符,其匹配行为是多多益善和不是适可而止,会尽可能从一段文本的开头一直匹配到末尾,而不会碰到第一个匹配时就停止。
+、*、?这些叫做量词,量词是贪婪的。
为了防止过度匹配,我们可以使用量词的“懒惰型”版本(匹配尽可能少的字符,而非尽可能多地去匹配),懒惰型量词地写法是在贪婪型量词后加?。
1.6 位置匹配
位置匹配用于指定应该在文本什么地方进行匹配操作。位置匹配需要用到边界,即一些用于指定模式前后位置(或边界)的特殊元字符。
- 单词边界
由b指定单词边界,用来匹配一个单词的开头或结尾。b匹配的是字符之间的一个位置:一边是单词(能够被w匹配的字母数字和下划线),另一边是其他内容(能够被W匹配的字符)。注意:b匹配的是一个位置,而不是任何实际的字符。
如果我们想匹配一个完整的单词,就必须在匹配的文本前后加上b。如果不想匹配单词边界,可以使用B。
- 字符串边界
字符串边界元字符有两个:^表示字符串开头,$表示字符串结尾。
注意:有些元字符有多种用途,如^。如果^出现在字符集合[]里且紧跟在左方括号[后面时,它才表示排除该字符集合。如果^出现在字符集合之外并且位于模式的开头,^将匹配字符串的起始位置。
- 多行模式
多行模式影响的是^和$的匹配规则:在默认模式下,^和$匹配的是整个字符串的起始位置和结束位置,但是在多行模式下,它们也能匹配字符串内部某一行文本的起始位置和结束位置。多行模式迫使正则表达式引擎将换行符视为字符串分隔符,这样一来,^既可以匹配字符串开头,也可匹配换行符之后的起始位置(新行);$不仅能匹配字符串结尾,也能匹配换行符之后的结束位置。
启用多行模式,使用(?m),并且其必须出现在整个模式最前面。
1.7 子表达式
子表达式是更长的表达式的一部分。划分子表达式的目的是为了将其视为单一的实体来使用。子表达式使用()进行定义,并用于对表达式进行分组。
- 指定子表达式的重复次数
匹配IP:(d{1, 3}.){3}d{1, 3}
- 与模式里的
|(或)连用
(19|20)d{2},匹配19或20开头的年份。
- 子表达式的嵌套
匹配一个有效的IP:
(((25[0-5])|(2[0-4]d)|(1d{2})|(d{1, 2})).){3}(((25[0-5])|(2[0-4]d)|(1d{2})|(d{1, 2})))
1.8 反向引用
反向引用:指的是这些实体引用的是先前的子表达式。
使用小括号()指定一个子表达式后,匹配这个子表达式的文本(也就是此分组捕获的内容)可以在表达式或其它程序中作进一步的处理。
- 默认组号
默认情况下,每个分组会自动拥有一个组号,规则是:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。1是引用匹配模式中使用的第一个子表达式,2匹配模式中的第二个子表达式,以此类推。0可以用来匹配整个表达式。
- 自定义子表达式的组名
(?或(?'name'exp):匹配exp,并捕获文本到名称为name的组里。
- 匹配但不捕获,也不分配组号
(?:exp):匹配exp,不捕获匹配的文本,也不给此分组分配组号。
1.9 环视
- 向前查看
向前查看指定了一个必须匹配但不用在结果中返回的模式。向前查看是查看以匹配文本之后的内容,但不消耗这些内容。向前查看是一个子表达式,以?=开头,需要匹配的文本跟在=的后面。例如:.+(?=:)可以匹配http://www.baidu.com,https://www.baidu.com/中的http和https。
- 向后查看
向后查看是查看以匹配文本之前的内容,操作符为?<=。
以上两个都属于肯定式查看,与之相对应的是否定式查看,即否定式向前查看和否定式向后查看。
- 否定式向前查看
否定式向前查看会向前查看不匹配指定模式的文本,操作符为?!。
- 否定式向后查看
否定式向后查看是向后查看不匹配指定模式的文本,操作符为?。
1.10 嵌入式条件
正则表达式里的条件用?来定义。嵌入式条件主要以下两种情况:一是根据反向引用来进行条件处理,二是根据环视来进行条件处理。
- 反向引用条件
反向引用条件仅在一个前面的子表达式得以匹配的情况下才允许使用另一个表达式。定义这种条件的语法是(?(backreference)true),其中?表明这是一个条件,括号里的backreference是一个反向引用。
条件还可以使用else表达式,定义这种条件的语法:(?(backreference)true|false)。
示例:(()?d{3}(?(1))|-)d{3}-d{4}
- 环视条件
环视条件允许根据向前查看或向后查看操作是否成功来决定要不要执行表达式。
示例:d{5}(?(?=-))-d{4}
1.11 正则表达式测试网站
http://www.pyregex.com/
https://regex101.com/
https://c.runoob.com/front-end/854
1.12 常见问题的正则表达式解决方案
2 Python中的正则表达式
在Python中,标准库中的模块re提供了正则表达式操作。
2.1 re模块中的函数
2.1.1 re.complie()
将正则表达式的样式编译为一个 正则表达式对象 (正则对象),正则表达式对象支持match()、search() 等方法。
"""
语法:re.compile(pattern, flags)
参数:pattern为一个字符串形式的正则表达式,flags为可选参数,表示匹配模式,具体参数为:
re.I:忽略大小写
re.M:多行模式
re.S:让‘.’匹配任何字符,包括换行符
re.X:为了增加可读性,忽略空格和#后面的注释
"""
import re
pattern = re.compile(r'd+')
res = pattern.search('abc123def456') # search:扫描整个字符串并返回第一个成功的匹配结果
print(res)
print(res.group()) # 匹配整体结果
# 输出
123 在re模块中,也提供了一些和match()、search()这些方法功能一致的函数。
2.1.2 re.match()
"""
尝试从字符串的起始位置匹配一个模式,如果起始位置匹配失败,则返回None。
语法:re.match(pattern, string, flags=0)
参数:pattern为正则表达式样式,string为待匹配的字符串,flags为匹配模式。
返回值:如果匹配成功则返回一个匹配对象,否则返回None。
"""
import re
res1 = re.match(r'd+', 'abc123def456')
res2 = re.match(r'd+', '123abc456def')
print(res1)
print(res2.group(0))
print(res2.groups())
# 输出
None
123
()匹配对象有两个主要的方法:group() 和 groups() 。
- group(num=0):group()和group(0)返回整个匹配对象,group(1)、group(2),...,返回特定组的匹配结果。
- groups():返回所有匹配子组的元组,组号从1开始。
除此之外,匹配对象还支持其他方法:
- start():返回匹配的开始位置
- end():返回匹配的结束位置
- span():以元组形式返回匹配的范围
2.1.3 re.search()
"""
扫描整个字符串并返回第一个成功的匹配。
语法:re.search(pattern, string, flags=0)
返回值:如果匹配成功则返回一个匹配对象,否则返回None。
"""
import re
res = re.search(r'd+', 'abc123def456')
print(res.group())
# 输出
1232.1.4 re.findall()
"""
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
语法:findall(string, start_pos, end_pos)
参数:string为待匹配的字符串,start_pos指定字符串的起始位置(可选),默认为0,end_pos指定字符串的结束位置(可选),默认为字符串的长度。
返回值:以列表形式返回所有匹配结果
"""
import re
res = re.findall(r'd+', 'abc123def456')
print(res)
# 输出
['123', '456']注意:re.findall()返回的结果是一个匹配结果的列表,不支持group()和groups()这些方法。
2.1.5 re.finditer()
"""
和findall类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
语法:re.finditer(pattern, string, flags=0)
返回值:返回所有匹配对象构成的迭代器。
"""
import re
res = re.finditer(r"d+","abc123def456")
for match in res:
print(match) # 迭代器中的每个元素都为匹配对象,支持group()
print(match.group())
# 输出
123
456 2.1.6 re.split()
"""
按照能够匹配的子串将字符串分割后返回列表。
语法:re.split(pattern, string[, maxsplit=0, flags=0])
参数:maxsplit为最大分隔次数,默认为0,即不限次数,flags为匹配模式。
返回值:返回以匹配子串分隔的字符串列表。
"""
import re
res = re.split(r"W+","abc,123,def,456")
print(res)
# 输出
['abc', '123', 'def', '456']2.1.7 re.sub()
"""
替换字符串中的匹配项。
语法:re.sub(pattern, repl, string, count=0, flags=0)
参数:repl为替换的字符串或函数,string为待匹配的原始字符串,count为替换的最大次数,默认为0,表示替换所有的匹配。
返回值:返回替换后的字符串。
"""
import re
res = re.sub(r"d", "*", "abc123def456")
print(res)
# 输出
abc***def***2.1.8 re.subn()
"""
与sub()相同, 但返回一个元组, 其中包含新字符串和替换次数。
"""
import re
res = re.subn(r"d", "*", "abc123def456")
print(res)
# 输出
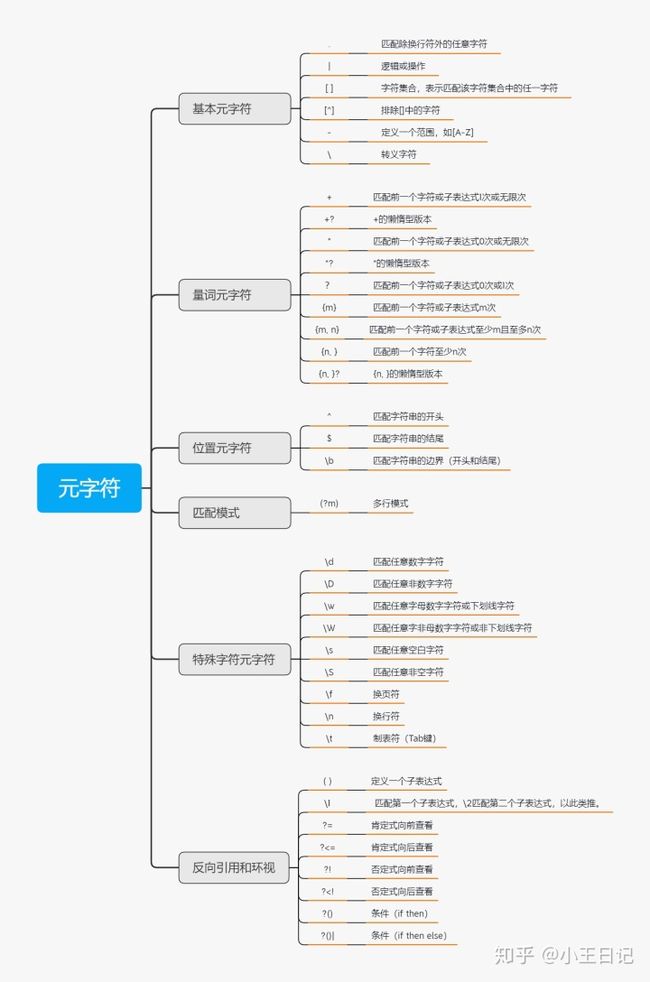
('abc***def***', 6)2.2 元字符
3 JSON
3.1 简介
JSON是一种轻量级的数据交换格式。符合JSON格式的字符串称为JSON字符串。JSON优点:
- 易于阅读
- 易于解析
- 网络传输效率高
- 跨语言交换数据
JSON对象类似于Python中的字典,由键值对组成。键必须是字符串,值可以是字符串, 数字, 对象, 数组, 布尔值或 null。需注意,JSON对象中的字符串必须用双引号(" ")。
{
"name": "Tom", "age": 28, "address": "Shanghai"}3.2 序列化
序列化:将python数据类型向json字符串转换的过程。
3.2.1 json.dumps()
dumps()函数中有一些参数需要了解:
- ensure_ascii:指定输出内容的编码,默认是ascii编码,如果需要输出中文,设置
ensure_ascii=False。 - skipkeys:如果要将字典转换为json字符串,则字典键只能是基本数据类型(
str,unicode,int,long,float,bool,None),否则会抛出异常。将skipkeys设置为True,则会跳过哪些类型不是基本类型的键。 - indent:根据数据格式缩进显示。
- sort_keys:sort_keys设置为True,输出内容按键进行排序。
- separators:作用是去掉
','和':'后面的空格。
import json
stu = {
'name': 'Tom', 'age': 28, 'school': 'Harvard University'}
stu_arr = [{
'name': 'Tom', 'age': 28, 'school': 'Harvard University'},
{
'name': 'Henry', 'age': 27, 'school': '清华大学'}]
print(type(json.dumps(stu)))
print(json.dumps(stu))
print(json.dumps(stu_arr, ensure_ascii=False, indent=2))
# 输出
{
"name": "Tom", "age": 28, "school": "Harvard University"}
[
{
"name": "Tom",
"age": 28,
"school": "Harvard University"
},
{
"name": "Henry",
"age": 27,
"school": "清华大学"
}
] 3.2.2 json.dump()
"""
将Python对象转换为json对象并保存到文件中
"""
import json
stu = {
'name': 'Tom', 'age': 28, 'school': 'Harvard University'}
with open('student_info.json', 'w') as f:
json.dump(stu, f)3.3 反序列化
反序列化:将json字符串转换为python中的数据类型。
json可以转换为python对应的类型
json python
object dict
array list
string str
number int/float
true True
false False
null None3.3.1 json.loads()
import json
stu = '{"name": "Tom", "age": 28, "school": "Harvard University"}'
print(type(json.loads(stu)))
print(json.loads(stu))
# 输出
{
'name': 'Tom', 'age': 28, 'school': 'Harvard University'} 3.3.2 json.load()
import json
with open('student_info.json', 'r') as f:
data = json.load(f)
print(data)
# 输出
{
'name': 'Tom', 'age': 28, 'school': 'Harvard University'}--END--