Fisher信息度量下的对抗攻击
该文是我投稿于人工智能前沿的一篇文章,如果大家有什么问题想要跟我讨论,可以留言跟我一起交流。
核心思想
本论文从信息几何的角度为深度模型的脆弱性提出了一种合理的解释。通过将数据空间视为具有从神经网络诱导的Fisher信息度量的非线性空间,并提出另一种攻击算法单步谱攻击(OSSA),该方法由Fisher信息矩阵的约束二次型形式描述,其中最优的对抗扰动由第一特征向量给出,并且脆弱性由特征值反映。特征值越大,模型越容易被相应的特征向量攻击。
利用该属性,我们还提出了一种特征值作为特征的对抗性检测方法。
论文的贡献
在深度模型脆弱性的解释中,引入Fisher信息矩阵(FIM)具有3个重大意义:
-
FIM是KL散度的Hssian矩阵,它是概率分布有意义的度量方式。
-
FIM是对称且半正定的,使得对矩阵的优化更加简单有效。
-
只要输出的概率可能性没有变化,FIM对于重新参数化也是不变的。
本文的贡献可以分为以下三个部分:
-
提出了一种基于信息几何的攻击深度神经网络的新算法。
该算法可以表征邻域中的多个对抗子空间,并且可以在不同条件下对深度模型进行高成功率的攻击。 -
采用FIM的特征值作为检测对抗性攻击的特征。分析表明,特征值为其特征的分类器对各种最先进的攻击具有鲁棒性。
-
为深度学习漏洞提供了一种新颖的几何解释。
理论结果证实了该攻击方法的优越性,并作为表征深度学习模型脆弱性的基础。
Fisher信息度量下的对抗攻击
对抗攻击的目标函数
对抗扰动 η \eta η会使得概率 p ( y ∣ x + η ) p(y | \boldsymbol{x}+\boldsymbol{\eta}) p(y∣x+η)由正确的概率输出变为错误的概率输出,用KL散度度量概率 p ( y ∣ x ) p(y|x) p(y∣x)的变化情况,则优化目标可以总结为如下形式:
max η D K L ( p ( y ∣ x ) ∥ p ( y ∣ x + η ) ) (1) \tag{1} \max _{\boldsymbol{\eta}} D_{K L}(p(y | \boldsymbol{x}) \| p(y | \boldsymbol{x}+\boldsymbol{\eta})) ηmaxDKL(p(y∣x)∥p(y∣x+η))(1) s.t. ∥ η ∥ 2 2 = ϵ \text { s.t. }\|\boldsymbol{\eta}\|_{2}^{2}=\epsilon s.t. ∥η∥22=ϵ
假定对抗 ∣ ∣ η ∣ ∣ ||\eta|| ∣∣η∣∣足够小,则可以对似然函数 log p ( y ∣ x + η ) \log p(y|x+\eta) logp(y∣x+η)进行二阶泰勒展开,会有如下的FIM简单的二阶形式: D K L ( p ( y ∣ x ) ∥ p ( y ∣ x + η ) ) = E y ∣ x [ log p ( y ∣ x ) p ( y ∣ x + η ) ] ≈ 1 2 η T G x η (2) \tag{2} \begin{aligned} D_{K L}(p(y | \boldsymbol{x}) \| p(y | \boldsymbol{x}+\boldsymbol{\eta})) &=\mathbb{E}_{\boldsymbol{y} | \boldsymbol{x}}\left[\log \frac{p(y | \boldsymbol{x})}{p(y | \boldsymbol{x}+\boldsymbol{\eta})}\right] \\ & \approx \frac{1}{2} \boldsymbol{\eta}^{T} \boldsymbol{G}_{\boldsymbol{x}} \boldsymbol{\eta} \end{aligned} DKL(p(y∣x)∥p(y∣x+η))=Ey∣x[logp(y∣x+η)p(y∣x)]≈21ηTGxη(2)
其中,样本 x x x的Fisher信息量为 G x = E y ∣ x [ ( ∇ x log p ( y ∣ x ) ) ( ∇ x log p ( y ∣ x ) ) T ] (3) \tag{3} \boldsymbol{G}_{\boldsymbol{x}}=\mathbb{E}_{\boldsymbol{y} | \boldsymbol{x}}\left[\left(\nabla_{\boldsymbol{x}} \log p(y | \boldsymbol{x})\right)\left(\nabla_{\boldsymbol{x}} \log p(y | \boldsymbol{x})\right)^{T}\right] Gx=Ey∣x[(∇xlogp(y∣x))(∇xlogp(y∣x))T](3)
证明: E y ∣ x [ log p ( y ∣ x ) p ( y ∣ x + η ) ] = E y ∣ x [ log p ( y ∣ x ) ] − E y ∣ x [ log p ( y ∣ x + η ) ] (4) \tag{4} E_{y|x}[\log \frac{p(y|x)}{p(y|x+\eta)}]=E_{y|x}[\log p(y|x)] - E_{y|x}[\log p(y|x+\eta)] Ey∣x[logp(y∣x+η)p(y∣x)]=Ey∣x[logp(y∣x)]−Ey∣x[logp(y∣x+η)](4)
其中, log p ( y ∣ x + η ) = log p ( y ∣ x ) + ∇ x log p ( y ∣ x ) ⋅ η + 1 2 η T ∇ x T ∇ x log p ( y ∣ x ) η + O ( η 2 ) \log p(y|x+\eta)=\log p(y|x)+ \nabla_{\boldsymbol{x}}\log p(y|x) \cdot \eta + \frac{1}{2}\eta ^{T}\nabla_{\boldsymbol{x}}^{T}\nabla_{\boldsymbol{x}}\log p(y|x)\eta+O(\eta^{2}) logp(y∣x+η)=logp(y∣x)+∇xlogp(y∣x)⋅η+21ηT∇xT∇xlogp(y∣x)η+O(η2)
计算 F x ′ \mathbb{F}_{x}^{'} Fx′如下: F x ′ = E y ∼ p ( y ∣ x ) [ ∇ x log p ( y ∣ x ) ∇ x T log p ( y ∣ x ) ] = E y ∼ p ( y ∣ x ) [ ∇ x p ( y ∣ x ) p ( y ∣ x ) ⋅ ∇ x T p ( y ∣ x ) p ( y ∣ x ) ] = E y ∼ p ( y ∣ x ) [ ∇ x p ( y ∣ x ) ∇ x T p ( y ∣ x ) p 2 ( y ∣ x ) ] (5.1) \tag{5.1} \begin{aligned} \mathbb{F}_{x}^{'} &=\mathbb{E}_{y \sim p(y | x)}\left[\nabla_{x} \log p(y | x) \nabla_{x}^{T} \log p(y | x)\right] \\ &= \mathbb{E}_{y \sim p(y | x)}\left[\frac{\nabla_{x} p(y | x)}{p(y | x)} \cdot \frac{\nabla_{x}^{T} p(y | x)}{p(y | x)}\right] \\ &= \mathbb{E}_{y \sim p(y | x)}\left[\frac{\nabla_{x} p(y | x)\nabla_{x}^{T} p(y | x)}{p^{2}(y | x)} \right] \end{aligned} Fx′=Ey∼p(y∣x)[∇xlogp(y∣x)∇xTlogp(y∣x)]=Ey∼p(y∣x)[p(y∣x)∇xp(y∣x)⋅p(y∣x)∇xTp(y∣x)]=Ey∼p(y∣x)[p2(y∣x)∇xp(y∣x)∇xTp(y∣x)](5.1) 计算 F x ′ ′ \mathbb{F}_{x}^{''} Fx′′如下: F x ′ ′ = E y ∼ p ( y ∣ x ) [ ∇ x T ( ∇ x p ( y ∣ x ) p ( y ∣ x ) ) ] = E y ∼ p ( y ∣ x ) [ ∇ x T ( ∇ x p ( y ∣ x ) p ( y ∣ x ) ) ] = E y ∼ p ( y ∣ x ) [ ( ∇ x T ∇ x p ( y ∣ x ) ) p ( y ∣ x ) − ∇ x T p ( y ∣ x ) ∇ x p ( y ∣ x ) p 2 ( y ∣ x ) ] (5.2) \tag{5.2} \begin{aligned} \mathbb{F}_{x}^{''} &=\mathbb{E}_{y \sim p(y | x)}\left[\nabla_{x}^{T}(\frac{\nabla_{x}p(y|x)}{p(y|x)}) \right] \\ &=\mathbb{E}_{y \sim p(y | x)}\left[\nabla_{x}^{T}(\frac{\nabla_{x}p(y|x)}{p(y|x)}) \right] \\ &= \mathbb{E}_{y \sim p(y | x)}\left[\frac{(\nabla_{x}^{T} \nabla_{x} p(y | x)) p(y | x) - \nabla_{x}^{T} p(y | x)\nabla_{x} p(y | x) }{p^{2}(y | x)} \right] \end{aligned} Fx′′=Ey∼p(y∣x)[∇xT(p(y∣x)∇xp(y∣x))]=Ey∼p(y∣x)[∇xT(p(y∣x)∇xp(y∣x))]=Ey∼p(y∣x)[p2(y∣x)(∇xT∇xp(y∣x))p(y∣x)−∇xTp(y∣x)∇xp(y∣x)](5.2)又容易推导出: E y ∼ p ( y ∣ x ) [ ∇ x T ∇ x p ( y ∣ x ) p ( y ∣ x ) ] = 0 (5.3) \tag{5.3} \mathbb{E}_{y \sim p(y | x)}[\frac{\nabla_{x}^{T} \nabla_{x} p(y | x)}{p(y | x)}]=0 Ey∼p(y∣x)[p(y∣x)∇xT∇xp(y∣x)]=0(5.3)
从而根据式子 ( 5.1 ) (5.1) (5.1), ( 5.2 ) (5.2) (5.2), ( 5.3 ) (5.3) (5.3)可知, F x ′ = F x ′ ′ \mathbb{F}_{x}^{'} = \mathbb{F}_{x}^{''} Fx′=Fx′′所以有: E y ∼ p ( y ∣ x ) [ ∇ x T ∇ x log p ( y ∣ x ) ] = − E y ∼ p ( y ∣ x ) [ ∇ x log p ( y ∣ x ) ∇ x T log p ( y ∣ x ) ] (6) \tag{6} \mathbb{E}_{y \sim p(y | x)}[\nabla_{\boldsymbol{x}}^{T}\nabla_{\boldsymbol{x}}\log p(y|x)]=-\mathbb{E}_{y \sim p(y | x)}[\nabla_{\boldsymbol{x}}\log p(y|x)\nabla_{\boldsymbol{x}}^{T}\log p(y|x)] Ey∼p(y∣x)[∇xT∇xlogp(y∣x)]=−Ey∼p(y∣x)[∇xlogp(y∣x)∇xTlogp(y∣x)](6)
综上, E y ∣ x [ log p ( y ∣ x ) p ( y ∣ x + η ) ] = − E y ∣ x [ ∇ x log p ( y ∣ x ) ⋅ η ] + 1 2 η T G x η + O ( η 2 ) ≈ 1 2 η T G x η (7) \tag{7} \begin{aligned} \mathbb{E}_{\boldsymbol{y} | \boldsymbol{x}}\left[\log \frac{p(y | \boldsymbol{x})}{p(y | \boldsymbol{x}+\boldsymbol{\eta})}\right] &= -\mathbb{E}_{y|x}[\nabla_{\boldsymbol{x}}\log p(y|x)\cdot \eta] + \frac{1}{2}\eta^{T}G_x\eta+O(\eta^2)\\ & \approx \frac{1}{2}\eta^{T}G_x\eta \end{aligned} Ey∣x[logp(y∣x+η)p(y∣x)]=−Ey∣x[∇xlogp(y∣x)⋅η]+21ηTGxη+O(η2)≈21ηTGxη(7)
其中, G x = E y ∣ x [ ∇ x log p ( y ∣ x ) ∇ x T log p ( y ∣ x ) ] (8) \tag{8} \boldsymbol{G}_{\boldsymbol{x}}=\mathbb{E}_{y|x}[\nabla_{\boldsymbol{x}}\log p(y|x)\nabla_{\boldsymbol{x}}^{T}\log p(y|x)] Gx=Ey∣x[∇xlogp(y∣x)∇xTlogp(y∣x)](8)
证毕。
样本 x x x的Fisher信息量的离散形式表示为: G x = ∑ i p i [ ∇ x J ( y i , x ) ] [ ∇ x J ( y i , x ) ] T (9) \tag{9} \boldsymbol{G}_{\boldsymbol{x}}=\sum_{i} p_{i}\left[\nabla_{\boldsymbol{x}} \mathcal{J}\left(y_{i}, \boldsymbol{x}\right)\right]\left[\nabla_{\boldsymbol{x}} \mathcal{J}\left(y_{i}, \boldsymbol{x}\right)\right]^{T} Gx=i∑pi[∇xJ(yi,x)][∇xJ(yi,x)]T(9)
其中, J ( y , x ) = − log p ( y ∣ x ) \mathcal{J}(y, \boldsymbol{x})=-\log p(y | \boldsymbol{x}) J(y,x)=−logp(y∣x)表示得是样本 x x x为第 y y y类的损失函数。综上,会得到目标函数的变体如下所示: max η η T G x η s.t. ∥ η ∥ 2 2 = ϵ , J ( y , x + η ) > J ( y , x ) (10) \tag{10} \max _{\boldsymbol{\eta}} \boldsymbol{\eta}^{T} \boldsymbol{G}_{\boldsymbol{x}} \boldsymbol{\eta} \quad \text { s.t. }\|\boldsymbol{\eta}\|_{2}^{2}=\epsilon, \mathcal{J}(y, \boldsymbol{x}+\boldsymbol{\eta})>\mathcal{J}(y, \boldsymbol{x}) ηmaxηTGxη s.t. ∥η∥22=ϵ,J(y,x+η)>J(y,x)(10)
可知,此函数的拉格朗日函数为如下形式: L ( η , λ ) = η T G x η − λ η T η (11) \tag{11} L(\eta,\lambda)=\eta^{T}G_{x}\eta-\lambda\eta^{T}\eta L(η,λ)=ηTGxη−ληTη(11)
对拉格朗日求导可得: ∂ L ( η , λ ) ∂ η = 0 (12) \tag{12} \frac{\partial L(\eta,\lambda)}{\partial \eta} = 0 ∂η∂L(η,λ)=0(12) 求解为:
2 G x η − 2 λ η = 0 (13) \tag{13} 2G_{x}\eta-2\lambda\eta=0 2Gxη−2λη=0(13) 化简可得: G x η = λ η (14) \tag{14} G_{x}\eta=\lambda\eta Gxη=λη(14) 进一步可以得出 m a x { η T G x η } = λ m a x η T η = λ m a x ⋅ ε (15) \tag{15} max\{ \eta^{T} G_{x} \eta\}=\lambda_{max}\eta^{T}\eta=\lambda_{max}\cdot \varepsilon max{ ηTGxη}=λmaxηTη=λmax⋅ε(15)
至此,可以将对优化问题的求解可以看成是对矩阵 G x G_{x} Gx进行特征分解并求其最大特征值 λ m a x \lambda_{max} λmax的过程,此时最大特征值 λ m a x \lambda_{max} λmax对应的特征向量 η \eta η即为所求。另外需要加入 J ( y , x + η ) > J ( y , x ) \mathcal{J}(y, \boldsymbol{x}+\boldsymbol{\eta})>\mathcal{J}(y, \boldsymbol{x}) J(y,x+η)>J(y,x)的约束条件保证对抗样本的损失函数要比干净样本的损失函数要大,即保证对抗样本的对抗性。这个方法的重要意义是当考虑到 D K L ( p ( y ∣ x ) ∥ p ( y ∣ x + η ) ) D_{K L}(p(y | \boldsymbol{x}) \| p(y | \boldsymbol{x}+\boldsymbol{\eta})) DKL(p(y∣x)∥p(y∣x+η))为对抗扰动 η \eta η的函数时,则Fisher信息矩阵是KL散度的Hessian矩阵。这意味着深度模型的脆弱性可以由KL散度的曲率来描述。对定一个样本 x x x,Fisher信息矩阵的特征值表征了对应特征向量的子空间的鲁棒性。特征值越大,深度模型越脆弱。
优化策略
在大数据集下,如果直接特征分解矩阵 G x G_{x} Gx的最大的特征向量,那么计算复杂度会非常大。为了避免计算开销可以通过计算 G x η \boldsymbol{G}_{\boldsymbol{x}} \boldsymbol{\eta} Gxη来代替。则会有如下形式:
G x η = E y ∣ x [ ( g y T η ) g y ] (19) \tag{19} \boldsymbol{G}_{\boldsymbol{x}} \boldsymbol{\eta}=\mathbb{E}_{y | \boldsymbol{x}}\left[\left(\boldsymbol{g}_{y}^{T} \boldsymbol{\eta}\right) \boldsymbol{g}_{y}\right] Gxη=Ey∣x[(gyTη)gy](19)
其中, g y = ∇ x J ( y , x ) \boldsymbol{g}_{y}=\nabla_{\boldsymbol{x}} \mathcal{J}(y, \boldsymbol{x}) gy=∇xJ(y,x)是类 y y y的损失函数关于样本 x x x的梯度。此方法是通过计算内积来代替处理矩阵的特征分解,其中,最大的特征值为 E y ∣ x [ ( g y T η ) 2 ] \mathbb{E}_{y | \boldsymbol{x}}\left[\left(\boldsymbol{g}_{y}^{T} \boldsymbol{\eta}\right)^{2}\right] Ey∣x[(gyTη)2]。用幂迭代的方法来加速矩阵 G x G_{x} Gx的特征分解,具体的迭代形式如下所示:
η k + 1 = E y ∣ x [ ( g y T η k ) g y ] ∥ E y ∣ x [ ( g y T η k ) g y ] ∥ (20) \tag{20} \boldsymbol{\eta}_{k+1}=\frac{\mathbb{E}_{y | \boldsymbol{x}}\left[\left(\boldsymbol{g}_{y}^{T} \boldsymbol{\eta}_{k}\right) \boldsymbol{g}_{y}\right]}{\left\|\mathbb{E}_{y | \boldsymbol{x}}\left[\left(\boldsymbol{g}_{y}^{T} \boldsymbol{\eta}_{k}\right) \boldsymbol{g}_{y}\right]\right\|} ηk+1=∥∥Ey∣x[(gyTηk)gy]∥∥Ey∣x[(gyTηk)gy](20)相似的方法可以用来计算前 m m m个大的特征值和与之对应的特征向量。计算矩阵 G x G_{x} Gx的另一个难点在于求和计算需要依赖于分布 p ( y ∣ x ) p(y | x) p(y∣x),但是模拟一个类别很大的数据集的分布会比较困难。在实际中,对分布 p ( y ∣ x ) p(y | x) p(y∣x)进行蒙特卡洛模拟来进而对积分进行近似求解。采样的数量是大约是类别的 1 5 \frac{1}{5} 51,但是模拟估计的数值依旧准确。随机采样用到的方法是alias方法。具体的算法如下所示:

OSSA算法在MNIST, CIFAR-10,ILSVRC-2012数据集上生成的对抗样本的可视化如下图所示:

几何解释
研究对抗性样本的一个重要问题就是表征神经网络的脆弱性。在欧式度量下已经表明识别RELU网络中最坏对抗扰动是一个NP-hard问题。本论文从另一个不同的方面来解释深度学习的脆弱性,即在Fisher信息量度标准下,通过OSSA算法获得的对抗扰动不会经过神经网络而映射压缩掉,这导致了深度学习的脆弱性。其中,在不需要假设任何网络结构条件下由OSSA算法获得最优性对抗扰动的理论基础可以解释为过度线性解释的推广。这说明由Goodfellow(2014)提出的过度线性化的理论可能不是神经网络脆弱性的充分条件,并且使用OSSA算法可以在具有平滑激活的网络中再现对抗攻击,例如指数线性单位。
实验结果
白盒攻击算法性能比较
本实验比较OSSA,FGM,OTCM这三种攻击算法的攻击模型的能力。如下图(a)所示,在单步攻击下,模型误分类率随着扰动大小的增加而增大,并且可知OSSA攻击算法在给定一个扰动下,它会以更快的速度达到一个高的攻击准确率。如下图(b)所示,在多步迭代攻击中,模型误分类率随着攻击的迭代次数的的增加而增大,并且可知OSSA算法在给定一个扰动下,能更快的收敛到一个较高的攻击准确率。

黑盒攻击迁移性探究
本实验是探究由OSSA算法生成对抗样本在不同模型(尤其是通过对抗训练正则化的模型)中迁移性的情况,该实验是在MNIST上进行的,该网络具有四个不同的网络:LeNet,VGG及其对抗训练变体,在这里分别称为LeNet-adv和VGG-adv。实验结果如下表所示,对抗样本跨模型的迁移率在不同模型之间是不对称的,未经对抗训练的模型迁移到经过对抗训练的模型平均会产生22.51%的误分类率,而反之平均产生80.52%的误分类率。

表征多重对抗子空间
Fisher信息度量可以用于测量模型局部鲁棒性,因此本实验来验证模型鲁棒性与Fisher信息矩阵的最大特征值之间的关系。如下图所示,显示了MNIST和CIFAR-10的验证集中的800个随机选择的样本的分散性,。横轴是特征值的对数,而纵轴是最小的对抗扰动大小。结果表明,特征值与模型易损性之间存在明显的相关性:最小扰动随特征值的指数增长线性减小。合理的解释是,特征值反映了Fisher信息量度下的扰动大小。根据最优性分析,较大的特征值会导致输出似然性的等距变化,从而更有可能以较小的扰动大小欺骗模型。

Fisher信息度量的对抗检测
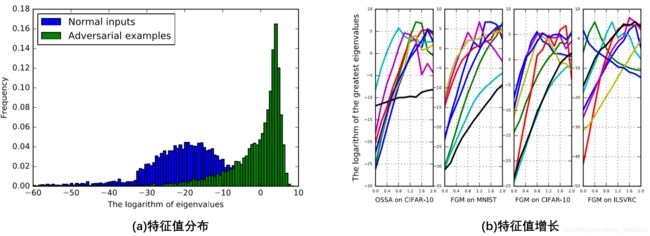
本实验探究Fisher信息矩阵中的特征值是如何检测对抗攻击。如下图所示,图(a)显示了特征值分布的直方图,FGM为MNIST的样本生成对抗样本,并在FIM中评估其最大特征值。直方图显示正常样本和对抗样本的特征值分布大小不同。后者的特征值在较大的域中密集分布,而前者的分布近似为具有较小均值的高斯分布,但是通过添加更多特征值作为特征,可以大大增强对抗示例的可分离性。图(b)为特征值随扰动大小的增加而大,这表明与正常样本相比,对抗样本在Fisher信息矩阵中具有更高的特征值。
总结交流
本文研究了基于信息几何的对抗攻击与检测,提出了一种将对抗性攻击与检测相结合的方法。对于攻击,本文证明了在Fisher信息度量下,最优对抗扰动是输入空间和输出空间之间的等距,这可以通过求解FIM的一个约束二次型得到。对于检测,Fisher信息矩阵的特征值能够很好地描述模型的局部脆弱性。这种特性能够建立机器学习分类器来检测具有特征值的对抗性攻击。实验结果表明,以特征值为特征的分类器对各种最新攻击的检测具有很好的鲁棒性。解决对抗性攻击问题通常是困难的。其中一个巨大的挑战是缺乏描述和分析深度学习模型的理论工具。黎曼几何学是一种很有前途的方法,可以更好地理解深度学习的脆弱性。
在本文中主要关注的是分类任务,其中模型的似然估计是离散分布。除了分类之外,还有许多其他的任务可以表示为统计问题,例如回归任务的高斯分布。因此,研究其他任务的对抗性攻击和防御将是一个有趣的未来方向。