利用python处理excel文件实战
通过导入excel文件,最终输出一个excel文件保存处理结果。
目录
1. 代码的Mermaid流程图
2. 代码示例
3. 打包方法
4. 结果展示
1. 代码逻辑架构
计算
划分数据集
汇总结果,调整格式
getExcel
Calculate
main
Merge
Total
2. 代码示例
import pandas as pd
import time
import os
import tkinter as tk
from tkinter import filedialog
'''
getExcel()
导入P8数据,并按支用账号去重
'''
def getExcel(filefullpath):
p8data= pd.DataFrame(pd.read_excel(filefullpath,encoding = 'utf-8'))
p8data.drop_duplicates('支用账号', 'first', True) #按支用账号去重
return p8data
'''
Calculate()
计算规则函数
'''
def Calculate(data,groupedby):
temp_data = pd.DataFrame()
grouped = data.groupby(data[groupedby])
temp_data[groupedby] = grouped[groupedby].count().index
temp_data['num'] = grouped['支用账号'].count().values
temp_data['sum'] = grouped['贷款余额'].sum().values * 0.0001
return temp_data
'''
main()
区分不同类别的贷款数额,包括全量,逾期,不良
'''
def main(p8data,groupedby):
data1 = p8data.copy()
data1 = data1[(data1['账户状态'] != '核销') & (data1['账户状态'] != '销户')] # 全量
data2 = data1[data1['拖欠天数'] > 0] # 逾期
fl = ['损失级', '可疑一级', '可疑二级', '次级一级', '次级二级']
data3 = data1[data1['十二级分类'].isin(fl)] # 不良
data1_cal = Calculate(data1, groupedby)
data2_cal = Calculate(data2, groupedby)
data3_cal = Calculate(data3, groupedby)
result = pd.merge((pd.merge(data1_cal, data2_cal, how='left', on=groupedby)), data3_cal, how='left', on=groupedby)
result.set_axis([groupedby, '全量数', '全量贷款余额(万元)', '逾期数', '逾期金额(万元)', '不良数','不良金额(万元)'], axis='columns', inplace=True)
result['逾期笔数占比(%)'] = (result.逾期数/result.全量数).apply(lambda x: format(x, '.2%'))
result['逾期金额占比(%)'] = (result['逾期金额(万元)'] / result['全量贷款余额(万元)']).apply(lambda x: format(x, '.2%'))
result['不良笔数占比(%)'] = (result.不良数 / result.全量数).apply(lambda x: format(x, '.2%'))
result['不良金额占比(%)'] = (result['不良金额(万元)'] / result['全量贷款余额(万元)']).apply(lambda x: format(x, '.2%'))
return result
'''
汇总函数Total()
在下方增加新行,显示汇总数值
'''
def Total(result):
result.loc['合计'] = result[['全量数', '全量贷款余额(万元)', '逾期数', '逾期金额(万元)', '不良数', '不良金额(万元)']].apply(lambda x: x.sum())
return result
if __name__=='__main__':
root = tk.Tk()
root.withdraw()
filefullpath = filedialog.askopenfilename()
p8data = getExcel(filefullpath)
print('------------ step 1 -----------------')
print('读取成功!正在处理...... _(¦3」∠)_')
time_start = time.time()
#输出按支行
result1 = main(p8data, groupedby='上级支行').sort_values('上级支行').reset_index(drop=True)
result1 = Total(result1)
#输出按网点
result2 = main(p8data, groupedby='经办行')
result2 = pd.merge(p8data[['上级支行', '经办行']].drop_duplicates(), result2, how='right', on='经办行')
result2 = result2.sort_values(['上级支行', '经办行']).reset_index(drop=True)
result2 = Total(result2)
print('------------ step 2 -----------------')
print('处理成功!正在输出结果...... (*╹▽╹*)')
excelName = 'P8Total' + time.strftime('%Y%m%d', time.localtime(time.time()))+ '.xlsx'
WritePath = pd.ExcelWriter(os.path.join(os.path.dirname(filefullpath), excelName))
result1.to_excel(WritePath, sheet_name='按支行')
result2.to_excel(WritePath, sheet_name='按网点')
WritePath.save()
print('------------ step 3 -----------------')
print('Okay!已保存为 {}/{} (*^▽^*)'.format(os.path.dirname(filefullpath),excelName))
time_end = time.time()
print('-------------------------------------')
print('已用时:{} s'.format(time_end - time_start))
input('请输入任意按键退出')
3. 打包方法
到这一步,整个报表的处理逻辑已经写完了,接下来就是打包,生成exe文件了。
先使用win+r进入命令行控制台,使用pip install pyinstaller .已经装了也没关系,会提示你已经安装过。如果确认安装了之后:
简单的打包方法
cd进入demo.py所在文件夹,然后使用pyinstaller -F demo.py 就可以了,最后在dist中可找到demo.exe。**
4. 结果示例
有图有真相,打开打包好的exe,就会弹出以下提示框,选中要处理的excel文件。

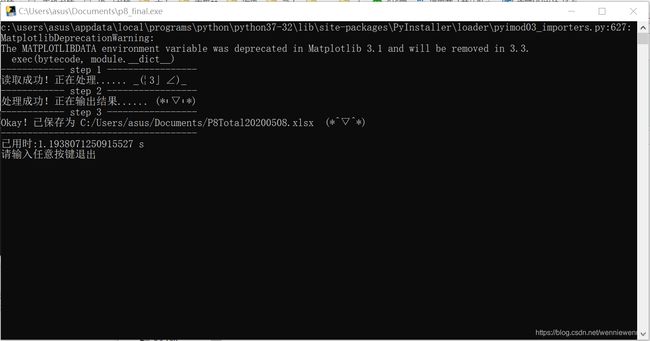
这个时候就会在选择导入的文件夹下看到一个demo+日期的excel文件了,也就是我们最终要的结果。

希望这篇文章能在你想用python做excel的工作时帮助到你。平时业务人员用excel加工该项统计结果,用时将近1个小时。采用python打包好的exe文件,只需短短几秒,即可得到最终结果。