YOLOv5系列(2)——YOLOv5导出jit,onnx,engine
文章目录
- 一、YOLOv5导出jit
- 二、YOLOv5导出onnx
- 三、使用onnx
- 四、YOLOv5导出engine(tensorrt/trt)
- 五、总结所有代码
-
- 5.1 models/common.py
- 5.2 models/yolo.py
- 5.3 pkg/test00.py
- 5.4 pkg/onnx_export.py(test01.py)
- 5.5 models/yolov5s.yaml
- 5.6 pkg/common.py
- 5.7 pkg/engine_export.py(test03.py)
做个YOLOv5的专题,这部分写一些YOLOv5的工程部署方面的问题,持续更新。
一、YOLOv5导出jit
YOLOv5自导出,我们可以直接用它的导出代码:models/export.py
"""Exports a YOLOv5 *.pt model to ONNX and TorchScript formats
Usage:
$ export PYTHONPATH="$PWD" && python models/export.py --weights ./weights/yolov5s.pt --img 640 --batch 1
"""
import argparse
import torch
from utils.google_utils import attempt_download
from utils.general import set_logging
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='./yolov5s.pt', help='weights path')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='image size')
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
opt = parser.parse_args()
opt.img_size *= 2 if len(opt.img_size) == 1 else 1 # expand
print(opt)
set_logging()
# Input
img = torch.zeros((opt.batch_size, 3, *opt.img_size)) # image size(1,3,320,192) iDetection
# Load PyTorch model
attempt_download(opt.weights)
model = torch.load(opt.weights, map_location=torch.device('cpu'))['model'].float()
model.eval()
model.model[-1].export = True # set Detect() layer export=True
y = model(img) # dry run
# TorchScript export
try:
print('\nStarting TorchScript export with torch %s...' % torch.__version__)
f = opt.weights.replace('.pt', '.torchscript.pt') # filename
ts = torch.jit.trace(model, img)
ts.save(f)
print('TorchScript export success, saved as %s' % f)
except Exception as e:
print('TorchScript export failure: %s' % e)
# ONNX export
try:
import onnx
print('\nStarting ONNX export with onnx %s...' % onnx.__version__)
f = opt.weights.replace('.pt', '.onnx') # filename
model.fuse() # only for ONNX
torch.onnx.export(model, img, f, verbose=False, opset_version=12, input_names=['images'],
output_names=['classes', 'boxes'] if y is None else ['output'])
# Checks
onnx_model = onnx.load(f) # load onnx model
onnx.checker.check_model(onnx_model) # check onnx model
print(onnx.helper.printable_graph(onnx_model.graph)) # print a human readable model
print('ONNX export success, saved as %s' % f)
except Exception as e:
print('ONNX export failure: %s' % e)
# CoreML export
try:
import coremltools as ct
print('\nStarting CoreML export with coremltools %s...' % ct.__version__)
# convert model from torchscript and apply pixel scaling as per detect.py
model = ct.convert(ts, inputs=[ct.ImageType(name='images', shape=img.shape, scale=1 / 255.0, bias=[0, 0, 0])])
f = opt.weights.replace('.pt', '.mlmodel') # filename
model.save(f)
print('CoreML export success, saved as %s' % f)
except Exception as e:
print('CoreML export failure: %s' % e)
# Finish
print('\nExport complete. Visualize with https://github.com/lutzroeder/netron.')
打包成jit格式成功如下表示打包成功:
![]()
二、YOLOv5导出onnx
导出onnx时同样使用上面的代码,但是如果不做更改的话,显示如下图:

根据说明,找到问题所在为hardswish不支持导出onnx,找到hardswitch在common.py里的Conv模块内,因此我们重写hardswish函数:
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
# self.act = nn.Hardswish() if act else nn.Identity()
self.act = Hardswish() if act else nn.Identity()
我们先寻找hardswish具体函数是什么:

发现和RELU6很像啊:
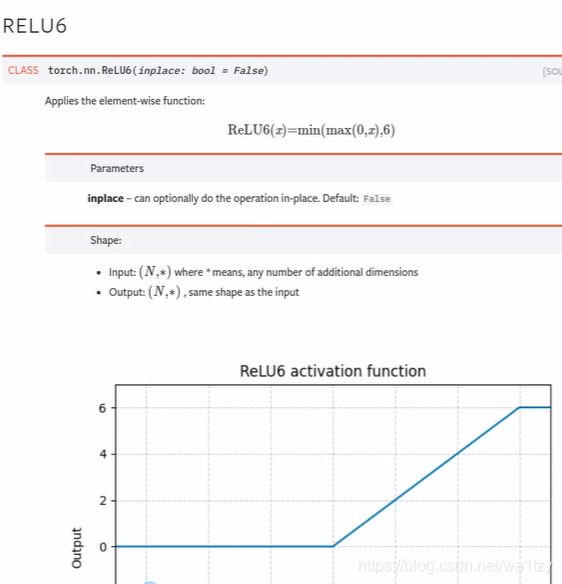
修改来了(也在common.py):
class Hardswish(nn.Module):
def forward(self, x):
return x * nn.functional.relu6(x + 3) / 6
导出,发现还是上面的错误,明明修改了,问题在哪里呢,在export.py中的
model = torch.load(opt.weights, map_location=torch.device('cpu'))['model'].float()
加载模型过程中,加载的是opt.weights,说白了就是加载的yolov5s.pt文件,这个文件不仅有权重,而且有模型本身(之前训练好的),我们修改了激活函数,导致导出出错,我们需要的仅仅是权重而已。
解决问题的方案:
一、把权重抽离出来,再使用yolo.py重新生成一个权重模型,使用这个权重模型去做onnx的导出
二、更简单的方案,这边我就讲这个手段吧,新建一个文件test01.py,复制hubconf.py里面的代码:
import torch
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True, channels=3, classes=80)
运行,生成新文件,windows在.cache文件夹下,linux在.cache/torch/hub/里面。
将models/common.py复制到同样的位置,这边我重写了导出onnx的代码:
import torch, cv2, numpy as np
from utils import datasets, torch_utils
from models.yolo import *
device = torch.device("cpu")
torch.backends.cudnn.benchmark = True
if __name__ == '__main__':
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True, channels=3, classes=80)
src_img = cv2.imread("1.jpg")
img = src_img[:, :, ::-1]
img = datasets.letterbox(img, new_shape=640)[0]
img = img.transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device).float()
img /= 255.
print(img.shape)
# img = torch.randn(3,512,640)
model.to(device).eval()
#重要提示%%%只打包onnx这段代码就屏蔽掉,如果要打包tensorrt这段代码就是需要的%%%%%
#model.model[-1].export = True
torch.onnx.export(model, img[None], "ys.onnx", verbose=True, opset_version=12,
input_names=['images'],
output_names=['output'])
打包成功(部分截图):

三、使用onnx
import onnx
import cv2
from utils import datasets,torch_utils
import numpy as np
import torch
import onnxruntime
from utils.general import (
check_img_size, non_max_suppression, apply_classifier, scale_coords,
xyxy2xywh, plot_one_box, strip_optimizer, set_logging)
src_img = cv2.imread("1.jpg")
img = src_img[:, :, ::-1] #BGR TO RGB
img = datasets.letterbox(img, new_shape=640)[0]
img = img.transpose(2, 0, 1)
img = img.astype(np.float32)
img /= 255.
ort_session = onnxruntime.InferenceSession("ys.onnx")
pred = ort_session.run(None, {
ort_session.get_inputs()[0].name: img[None]})[0]
det = non_max_suppression(torch.tensor(pred), 0.3, 0.5, classes=None, agnostic=False)[0]
print(det)
if det is not None and len(det):
det[:, :4] = scale_coords(img.shape[1:], det[:, :4], src_img.shape).round()
boxes = det.cpu().detach().numpy()
for box in boxes:
box = box.astype(np.int)
cv2.rectangle(src_img, (box[0], box[1]), (box[2], box[3]), (0, 255, 0), 2)
cv2.imshow("....", src_img)
cv2.waitKey(0)
显示成功
四、YOLOv5导出engine(tensorrt/trt)
首先下载tensorrt,找官网,下载对应的版本,找到开发者指南:Getting startesd–>Installation Guide–>Installing TensorRT,按照提升装就OK。


找到例子:根据例子修改自己的代码

common.py
#
# Copyright 1993-2019 NVIDIA Corporation. All rights reserved.
#
# NOTICE TO LICENSEE:
#
# This source code and/or documentation ("Licensed Deliverables") are
# subject to NVIDIA intellectual property rights under U.S. and
# international Copyright laws.
#
# These Licensed Deliverables contained herein is PROPRIETARY and
# CONFIDENTIAL to NVIDIA and is being provided under the terms and
# conditions of a form of NVIDIA software license agreement by and
# between NVIDIA and Licensee ("License Agreement") or electronically
# accepted by Licensee. Notwithstanding any terms or conditions to
# the contrary in the License Agreement, reproduction or disclosure
# of the Licensed Deliverables to any third party without the express
# written consent of NVIDIA is prohibited.
#
# NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
# LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
# SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
# PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
# NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
# DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
# NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
# NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
# LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
# SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
# DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
# WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
# ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
# OF THESE LICENSED DELIVERABLES.
#
# U.S. Government End Users. These Licensed Deliverables are a
# "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
# 1995), consisting of "commercial computer software" and "commercial
# computer software documentation" as such terms are used in 48
# C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
# only as a commercial end item. Consistent with 48 C.F.R.12.212 and
# 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
# U.S. Government End Users acquire the Licensed Deliverables with
# only those rights set forth herein.
#
# Any use of the Licensed Deliverables in individual and commercial
# software must include, in the user documentation and internal
# comments to the code, the above Disclaimer and U.S. Government End
# Users Notice.
#
from itertools import chain
import argparse
import os
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import tensorrt as trt
try:
# Sometimes python2 does not understand FileNotFoundError
FileNotFoundError
except NameError:
FileNotFoundError = IOError
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
def GiB(val):
return val * 1 << 30
def add_help(description):
parser = argparse.ArgumentParser(description=description, formatter_class=argparse.ArgumentDefaultsHelpFormatter)
args, _ = parser.parse_known_args()
def find_sample_data(description="Runs a TensorRT Python sample", subfolder="", find_files=[]):
'''
Parses sample arguments.
Args:
description (str): Description of the sample.
subfolder (str): The subfolder containing data relevant to this sample
find_files (str): A list of filenames to find. Each filename will be replaced with an absolute path.
Returns:
str: Path of data directory.
'''
# Standard command-line arguments for all samples.
kDEFAULT_DATA_ROOT = os.path.join(os.sep, "usr", "src", "tensorrt", "data")
parser = argparse.ArgumentParser(description=description, formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("-d", "--datadir", help="Location of the TensorRT sample data directory, and any additional data directories.", action="append", default=".")
args, _ = parser.parse_known_args()
def get_data_path(data_dir):
# If the subfolder exists, append it to the path, otherwise use the provided path as-is.
data_path = os.path.join(data_dir, subfolder)
if not os.path.exists(data_path):
print("WARNING: " + data_path + " does not exist. Trying " + data_dir + " instead.")
data_path = data_dir
# Make sure data directory exists.
if not (os.path.exists(data_path)):
print("WARNING: {:} does not exist. Please provide the correct data path with the -d option.".format(data_path))
return data_path
data_paths = [get_data_path(data_dir) for data_dir in args.datadir]
return data_paths, locate_files(data_paths, find_files)
def locate_files(data_paths, filenames):
"""
Locates the specified files in the specified data directories.
If a file exists in multiple data directories, the first directory is used.
Args:
data_paths (List[str]): The data directories.
filename (List[str]): The names of the files to find.
Returns:
List[str]: The absolute paths of the files.
Raises:
FileNotFoundError if a file could not be located.
"""
found_files = [None] * len(filenames)
for data_path in data_paths:
# Find all requested files.
for index, (found, filename) in enumerate(zip(found_files, filenames)):
if not found:
file_path = os.path.abspath(os.path.join(data_path, filename))
if os.path.exists(file_path):
found_files[index] = file_path
# Check that all files were found
for f, filename in zip(found_files, filenames):
if not f or not os.path.exists(f):
raise FileNotFoundError("Could not find {:}. Searched in data paths: {:}".format(filename, data_paths))
return found_files
# Simple helper data class that's a little nicer to use than a 2-tuple.
class HostDeviceMem(object):
def __init__(self, host_mem, device_mem):
self.host = host_mem
self.device = device_mem
def __str__(self):
return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)
def __repr__(self):
return self.__str__()
# Allocates all buffers required for an engine, i.e. host/device inputs/outputs.
def allocate_buffers(engine):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
for binding in engine:
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream
# This function is generalized for multiple inputs/outputs.
# inputs and outputs are expected to be lists of HostDeviceMem objects.
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
# Transfer input data to the GPU.
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# Run inference.
context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# Synchronize the stream
stream.synchronize()
# Return only the host outputs.
return [out.host for out in outputs]
# This function is generalized for multiple inputs/outputs for full dimension networks.
# inputs and outputs are expected to be lists of HostDeviceMem objects.
def do_inference_v2(context, bindings, inputs, outputs, stream):
# Transfer input data to the GPU.
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# Run inference.
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# Synchronize the stream
stream.synchronize()
# Return only the host outputs.
return [out.host for out in outputs]
test03.py
from utils import datasets
import tensorrt as trt
from pkg import common
import torch
import numpy as np
import cv2
from utils.general import (
check_img_size, non_max_suppression, apply_classifier, scale_coords,
xyxy2xywh, plot_one_box, strip_optimizer, set_logging)
class ModelData(object):
MODEL_PATH = "ys.onnx"
INPUT_SHAPE = (3, 512, 640)
DTYPE = trt.float32
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
def build_engine_onnx(model_file):
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(common.EXPLICIT_BATCH) as network, trt.OnnxParser(
network, TRT_LOGGER) as parser:
# builder.fp16_mode = True
builder.max_workspace_size = common.GiB(1)
with open(model_file, 'rb') as model:
if not parser.parse(model.read()):
print('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
return builder.build_cuda_engine(network)
def build_engine(model_file):
with open(model_file, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
def load_normalized_test_case(test_image, pagelocked_buffer):
def normalize_image(image):
img = image[:, :, ::-1]
img = datasets.letterbox(img, new_shape=640)[0]
img = img.transpose(2, 0, 1)
img = img.ravel()
img = img.astype(np.float32)
img /= 255.
img = np.ascontiguousarray(img)
return img
np.copyto(pagelocked_buffer, normalize_image(test_image))
return test_image
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
def main():
anchors = [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]]
a = torch.tensor(anchors).float().view(3, -1, 2)
anchor_grid = a.clone().view(3, 1, -1, 1, 1, 2)
stride = torch.tensor([8., 16., 32.])
with build_engine_onnx(ModelData.MODEL_PATH) as engine:
# with build_engine("y.engine") as engine:
# with open("y.engine", "wb") as f:
# f.write(engine.serialize())
# exit()
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
with engine.create_execution_context() as context:
src_img = load_normalized_test_case(cv2.imread("1.jpg"), inputs[0].host)
trt_outputs = common.do_inference_v2(context, bindings=bindings, inputs=inputs, outputs=outputs,
stream=stream)
print(trt_outputs[0].shape, trt_outputs[1].shape, trt_outputs[2].shape)
# exit()
x = []
x.append(torch.tensor(trt_outputs[0].reshape(1, 3, 64, 80, 85)))
x.append(torch.tensor(trt_outputs[1].reshape(1, 3, 32, 40, 85)))
x.append(torch.tensor(trt_outputs[2].reshape(1, 3, 16, 20, 85)))
print(x[2][0, :, 0])
z = []
grid = [torch.zeros(1)] * 3
for i in range(3):
# x[i] = x[i].permute(0, 3, 1, 2)
bs, _, ny, nx, _ = x[i].shape
grid[i] = _make_grid(nx, ny)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + grid[i]) * stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * anchor_grid[i] # wh
z.append(y.view(bs, -1, 85))
pred = torch.cat(z, 1)
det = non_max_suppression(pred, 0.3, 0.3, classes=None, agnostic=False)[0]
print(det)
if det is not None and len(det):
det[:, :4] = scale_coords([512, 640], det[:, :4], src_img.shape).round()
boxes = det.cpu().detach().numpy()
for box in boxes:
box = box.astype(np.int)
cv2.rectangle(src_img, (box[0], box[1]), (box[2], box[3]), (0, 255, 0), 2)
cv2.imshow("....", src_img)
cv2.waitKey(0)
if __name__ == '__main__':
main()
先讲坑:
一、models/yolo.py下这段代码导出的onnx,tensorrt是不支持的,只支持到前面的代码,后期这块需要自己添加。
好在可以在models/common.py使用model.model[-1].export = True导出
二、然后用test03.py导出,报错:

问题在于onnx支持Pytorch的nn.Upsample,而tensorrt是不支持的,所以需要对nn.Upsamle进行修改:在yolov5s.yaml,修改nn.Upsample为UpsampleNearest,models/common.py需要增加新函数UpsampleNearest,models/yolo.py导入UpsampleNearest:
class UpsampleNearest(nn.Module):
def __init__(self, *args):
super().__init__()
def forward(self, x):
n, c, h, w = x.shape
x = x.repeat(1, 1, 2, 2)
x = x.reshape(n, c, 2, h, 2, w)
x = x.permute(0, 1, 3, 2, 5, 4)
x = x.reshape(n, c, h * 2, w * 2)
return x


最后,需要把yolo.py,yolov5s.yaml,common.py复制到.cache/torch/hub/对应的位置(替换掉之前的),再次运行test03.py即可。
五、总结所有代码
5.1 models/common.py
# This file contains modules common to various models
import math
import torch
import torch.nn as nn
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
def DWConv(c1, c2, k=1, s=1, act=True):
# Depthwise convolution
return Conv(c1, c2, k, s, g=math.gcd(c1, c2), act=act)
class Hardswish(nn.Module):
def forward(self, x):
return x * nn.functional.relu6(x + 3) / 6
# return nn.functional.leaky_relu(x, 0.1)
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
# self.act = nn.Hardswish() if act else nn.Identity()
self.act = Hardswish() if act else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
class SPP(nn.Module):
# Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=(5, 9, 13)):
super(SPP, self).__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
def forward(self, x):
x = self.cv1(x)
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
class Concat(nn.Module):
# Concatenate a list of tensors along dimension
def __init__(self, dimension=1):
super(Concat, self).__init__()
self.d = dimension
def forward(self, x):
return torch.cat(x, self.d)
class Flatten(nn.Module):
# Use after nn.AdaptiveAvgPool2d(1) to remove last 2 dimensions
@staticmethod
def forward(x):
return x.view(x.size(0), -1)
class Classify(nn.Module):
# Classification head, i.e. x(b,c1,20,20) to x(b,c2)
def __init__(self, c1, c2, k=1, s=1, p=None, g=1): # ch_in, ch_out, kernel, stride, padding, groups
super(Classify, self).__init__()
self.aap = nn.AdaptiveAvgPool2d(1) # to x(b,c1,1,1)
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False) # to x(b,c2,1,1)
self.flat = Flatten()
def forward(self, x):
z = torch.cat([self.aap(y) for y in (x if isinstance(x, list) else [x])], 1) # cat if list
return self.flat(self.conv(z)) # flatten to x(b,c2)
class UpsampleNearest(nn.Module):
def __init__(self, *args):
super().__init__()
def forward(self, x):
n, c, h, w = x.shape
x = x.repeat(1, 1, 2, 2)
x = x.reshape(n, c, 2, h, 2, w)
x = x.permute(0, 1, 3, 2, 5, 4)
x = x.reshape(n, c, h * 2, w * 2)
return x
5.2 models/yolo.py
import argparse
import math
import logging
from copy import deepcopy
from pathlib import Path
import torch
import torch.nn as nn
from models.common import Conv, Bottleneck, SPP, DWConv, Focus, BottleneckCSP, Concat, UpsampleNearest
from models.experimental import MixConv2d, CrossConv, C3
from utils.general import check_anchor_order, make_divisible, check_file, set_logging
from utils.torch_utils import (
time_synchronized, fuse_conv_and_bn, model_info, scale_img, initialize_weights, select_device)
logger = logging.getLogger(__name__)
class Detect(nn.Module):
stride = None # strides computed during build
export = False # onnx export
def __init__(self, nc=80, anchors=(), ch=()): # detection layer
super(Detect, self).__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
a = torch.tensor(anchors).float().view(self.nl, -1, 2)
self.register_buffer('anchors', a) # shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl, 1, -1, 1, 1, 2)) # shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output conv
def forward(self, x):
# x = x.copy() # for profiling
z = [] # inference output
self.training |= self.export
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i] = self._make_grid(nx, ny).to(x[i].device)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + self.grid[i].to(x[i].device)) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1), x)
@staticmethod
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
class Model(nn.Module):
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None): # model, input channels, number of classes
super(Model, self).__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg) as f:
self.yaml = yaml.load(f, Loader=yaml.FullLoader) # model dict
# Define model
if nc and nc != self.yaml['nc']:
print('Overriding %s nc=%g with nc=%g' % (cfg, self.yaml['nc'], nc))
self.yaml['nc'] = nc # override yaml value
self.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelist, ch_out
# print([x.shape for x in self.forward(torch.zeros(1, ch, 64, 64))])
# Build strides, anchors
m = self.model[-1] # Detect()
if isinstance(m, Detect):
s = 128 # 2x min stride
m.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forward
m.anchors /= m.stride.view(-1, 1, 1)
check_anchor_order(m)
self.stride = m.stride
self._initialize_biases() # only run once
# print('Strides: %s' % m.stride.tolist())
# Init weights, biases
initialize_weights(self)
self.info()
print('')
def forward(self, x, augment=False, profile=False):
if augment:
img_size = x.shape[-2:] # height, width
s = [1, 0.83, 0.67] # scales
f = [None, 3, None] # flips (2-ud, 3-lr)
y = [] # outputs
for si, fi in zip(s, f):
xi = scale_img(x.flip(fi) if fi else x, si)
yi = self.forward_once(xi)[0] # forward
# cv2.imwrite('img%g.jpg' % s, 255 * xi[0].numpy().transpose((1, 2, 0))[:, :, ::-1]) # save
yi[..., :4] /= si # de-scale
if fi == 2:
yi[..., 1] = img_size[0] - yi[..., 1] # de-flip ud
elif fi == 3:
yi[..., 0] = img_size[1] - yi[..., 0] # de-flip lr
y.append(yi)
return torch.cat(y, 1), None # augmented inference, train
else:
return self.forward_once(x, profile) # single-scale inference, train
def forward_once(self, x, profile=False):
y, dt = [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
try:
import thop
o = thop.profile(m, inputs=(x,), verbose=False)[0] / 1E9 * 2 # FLOPS
except:
o = 0
t = time_synchronized()
for _ in range(10):
_ = m(x)
dt.append((time_synchronized() - t) * 100)
print('%10.1f%10.0f%10.1fms %-40s' % (o, m.np, dt[-1], m.type))
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if profile:
print('%.1fms total' % sum(dt))
return x
def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.
m = self.model[-1] # Detect() module
for mi, s in zip(m.m, m.stride): # from
b = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)
b[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)
b[:, 5:] += math.log(0.6 / (m.nc - 0.99)) if cf is None else torch.log(cf / cf.sum()) # cls
mi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
def _print_biases(self):
m = self.model[-1] # Detect() module
for mi in m.m: # from
b = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)
print(('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))
# def _print_weights(self):
# for m in self.model.modules():
# if type(m) is Bottleneck:
# print('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weights
def fuse(self): # fuse model Conv2d() + BatchNorm2d() layers
print('Fusing layers... ')
for m in self.model.modules():
if type(m) is Conv:
m._non_persistent_buffers_set = set() # pytorch 1.6.0 compatability
m.conv = fuse_conv_and_bn(m.conv, m.bn) # update conv
m.bn = None # remove batchnorm
m.forward = m.fuseforward # update forward
self.info()
return self
def info(self): # print model information
model_info(self)
def parse_model(d, ch): # model_dict, input_channels(3)
logger.info('\n%3s%18s%3s%10s %-40s%-30s' % ('', 'from', 'n', 'params', 'module', 'arguments'))
anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']
na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchors
no = na * (nc + 5) # number of outputs = anchors * (classes + 5)
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, args
m = eval(m) if isinstance(m, str) else m # eval strings
for j, a in enumerate(args):
try:
args[j] = eval(a) if isinstance(a, str) else a # eval strings
except:
pass
n = max(round(n * gd), 1) if n > 1 else n # depth gain
if m in [nn.Conv2d, Conv, Bottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP, C3]:
c1, c2 = ch[f], args[0]
# Normal
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1.75 # exponential (default 2.0)
# e = math.log(c2 / ch[1]) / math.log(2)
# c2 = int(ch[1] * ex ** e)
# if m != Focus:
c2 = make_divisible(c2 * gw, 8) if c2 != no else c2
# Experimental
# if i > 0 and args[0] != no: # channel expansion factor
# ex = 1 + gw # exponential (default 2.0)
# ch1 = 32 # ch[1]
# e = math.log(c2 / ch1) / math.log(2) # level 1-n
# c2 = int(ch1 * ex ** e)
# if m != Focus:
# c2 = make_divisible(c2, 8) if c2 != no else c2
args = [c1, c2, *args[1:]]
if m in [BottleneckCSP, C3]:
args.insert(2, n)
n = 1
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum([ch[-1 if x == -1 else x + 1] for x in f])
elif m is Detect:
args.append([ch[x + 1] for x in f])
if isinstance(args[1], int): # number of anchors
args[1] = [list(range(args[1] * 2))] * len(f)
else:
c2 = ch[f]
m_ = nn.Sequential(*[m(*args) for _ in range(n)]) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
np = sum([x.numel() for x in m_.parameters()]) # number params
m_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number params
logger.info('%3s%18s%3s%10.0f %-40s%-30s' % (i, f, n, np, t, args)) # print
save.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
ch.append(c2)
return nn.Sequential(*layers), sorted(save)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--cfg', type=str, default='yolov5s.yaml', help='model.yaml')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
opt = parser.parse_args()
opt.cfg = check_file(opt.cfg) # check file
set_logging()
device = select_device(opt.device)
# Create model
model = Model(opt.cfg).to(device)
# model.train()
# Profile
# img = torch.rand(8 if torch.cuda.is_available() else 1, 3, 640, 640).to(device)
# y = model(img, profile=True)
# ONNX export
# model.model[-1].export = True
# torch.onnx.export(model, img, opt.cfg.replace('.yaml', '.onnx'), verbose=True, opset_version=11)
# Tensorboard
# from torch.utils.tensorboard import SummaryWriter
# tb_writer = SummaryWriter()
# print("Run 'tensorboard --logdir=models/runs' to view tensorboard at http://localhost:6006/")
# tb_writer.add_graph(model.model, img) # add model to tensorboard
# tb_writer.add_image('test', img[0], dataformats='CWH') # add model to tensorboard
5.3 pkg/test00.py
import torch
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True, channels=3, classes=80)
5.4 pkg/onnx_export.py(test01.py)
import torch, cv2, numpy as np
from utils import datasets, torch_utils
from models.yolo import *
device = torch.device("cpu")
torch.backends.cudnn.benchmark = True
if __name__ == '__main__':
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True, channels=3, classes=80)
src_img = cv2.imread("1.jpg")
img = src_img[:, :, ::-1]
img = datasets.letterbox(img, new_shape=640)[0]
img = img.transpose(2, 0, 1)
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device).float()
img /= 255.
print(img.shape)
# img = torch.randn(3,512,640)
model.to(device).eval()
model.model[-1].export = True#要导出tensorrt的时候再用这个
torch.onnx.export(model, img[None], "ys.onnx", verbose=True, opset_version=12,
input_names=['images'],
output_names=['output'])
5.5 models/yolov5s.yaml
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, UpsampleNearest, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, UpsampleNearest, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
5.6 pkg/common.py
#
# Copyright 1993-2019 NVIDIA Corporation. All rights reserved.
#
# NOTICE TO LICENSEE:
#
# This source code and/or documentation ("Licensed Deliverables") are
# subject to NVIDIA intellectual property rights under U.S. and
# international Copyright laws.
#
# These Licensed Deliverables contained herein is PROPRIETARY and
# CONFIDENTIAL to NVIDIA and is being provided under the terms and
# conditions of a form of NVIDIA software license agreement by and
# between NVIDIA and Licensee ("License Agreement") or electronically
# accepted by Licensee. Notwithstanding any terms or conditions to
# the contrary in the License Agreement, reproduction or disclosure
# of the Licensed Deliverables to any third party without the express
# written consent of NVIDIA is prohibited.
#
# NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
# LICENSE AGREEMENT, NVIDIA MAKES NO REPRESENTATION ABOUT THE
# SUITABILITY OF THESE LICENSED DELIVERABLES FOR ANY PURPOSE. IT IS
# PROVIDED "AS IS" WITHOUT EXPRESS OR IMPLIED WARRANTY OF ANY KIND.
# NVIDIA DISCLAIMS ALL WARRANTIES WITH REGARD TO THESE LICENSED
# DELIVERABLES, INCLUDING ALL IMPLIED WARRANTIES OF MERCHANTABILITY,
# NONINFRINGEMENT, AND FITNESS FOR A PARTICULAR PURPOSE.
# NOTWITHSTANDING ANY TERMS OR CONDITIONS TO THE CONTRARY IN THE
# LICENSE AGREEMENT, IN NO EVENT SHALL NVIDIA BE LIABLE FOR ANY
# SPECIAL, INDIRECT, INCIDENTAL, OR CONSEQUENTIAL DAMAGES, OR ANY
# DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS,
# WHETHER IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS
# ACTION, ARISING OUT OF OR IN CONNECTION WITH THE USE OR PERFORMANCE
# OF THESE LICENSED DELIVERABLES.
#
# U.S. Government End Users. These Licensed Deliverables are a
# "commercial item" as that term is defined at 48 C.F.R. 2.101 (OCT
# 1995), consisting of "commercial computer software" and "commercial
# computer software documentation" as such terms are used in 48
# C.F.R. 12.212 (SEPT 1995) and is provided to the U.S. Government
# only as a commercial end item. Consistent with 48 C.F.R.12.212 and
# 48 C.F.R. 227.7202-1 through 227.7202-4 (JUNE 1995), all
# U.S. Government End Users acquire the Licensed Deliverables with
# only those rights set forth herein.
#
# Any use of the Licensed Deliverables in individual and commercial
# software must include, in the user documentation and internal
# comments to the code, the above Disclaimer and U.S. Government End
# Users Notice.
#
from itertools import chain
import argparse
import os
import pycuda.driver as cuda
import pycuda.autoinit
import numpy as np
import tensorrt as trt
try:
# Sometimes python2 does not understand FileNotFoundError
FileNotFoundError
except NameError:
FileNotFoundError = IOError
EXPLICIT_BATCH = 1 << (int)(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)
def GiB(val):
return val * 1 << 30
def add_help(description):
parser = argparse.ArgumentParser(description=description, formatter_class=argparse.ArgumentDefaultsHelpFormatter)
args, _ = parser.parse_known_args()
def find_sample_data(description="Runs a TensorRT Python sample", subfolder="", find_files=[]):
'''
Parses sample arguments.
Args:
description (str): Description of the sample.
subfolder (str): The subfolder containing data relevant to this sample
find_files (str): A list of filenames to find. Each filename will be replaced with an absolute path.
Returns:
str: Path of data directory.
'''
# Standard command-line arguments for all samples.
kDEFAULT_DATA_ROOT = os.path.join(os.sep, "usr", "src", "tensorrt", "data")
parser = argparse.ArgumentParser(description=description, formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("-d", "--datadir", help="Location of the TensorRT sample data directory, and any additional data directories.", action="append", default=".")
args, _ = parser.parse_known_args()
def get_data_path(data_dir):
# If the subfolder exists, append it to the path, otherwise use the provided path as-is.
data_path = os.path.join(data_dir, subfolder)
if not os.path.exists(data_path):
print("WARNING: " + data_path + " does not exist. Trying " + data_dir + " instead.")
data_path = data_dir
# Make sure data directory exists.
if not (os.path.exists(data_path)):
print("WARNING: {:} does not exist. Please provide the correct data path with the -d option.".format(data_path))
return data_path
data_paths = [get_data_path(data_dir) for data_dir in args.datadir]
return data_paths, locate_files(data_paths, find_files)
def locate_files(data_paths, filenames):
"""
Locates the specified files in the specified data directories.
If a file exists in multiple data directories, the first directory is used.
Args:
data_paths (List[str]): The data directories.
filename (List[str]): The names of the files to find.
Returns:
List[str]: The absolute paths of the files.
Raises:
FileNotFoundError if a file could not be located.
"""
found_files = [None] * len(filenames)
for data_path in data_paths:
# Find all requested files.
for index, (found, filename) in enumerate(zip(found_files, filenames)):
if not found:
file_path = os.path.abspath(os.path.join(data_path, filename))
if os.path.exists(file_path):
found_files[index] = file_path
# Check that all files were found
for f, filename in zip(found_files, filenames):
if not f or not os.path.exists(f):
raise FileNotFoundError("Could not find {:}. Searched in data paths: {:}".format(filename, data_paths))
return found_files
# Simple helper data class that's a little nicer to use than a 2-tuple.
class HostDeviceMem(object):
def __init__(self, host_mem, device_mem):
self.host = host_mem
self.device = device_mem
def __str__(self):
return "Host:\n" + str(self.host) + "\nDevice:\n" + str(self.device)
def __repr__(self):
return self.__str__()
# Allocates all buffers required for an engine, i.e. host/device inputs/outputs.
def allocate_buffers(engine):
inputs = []
outputs = []
bindings = []
stream = cuda.Stream()
for binding in engine:
size = trt.volume(engine.get_binding_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_binding_dtype(binding))
# Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
device_mem = cuda.mem_alloc(host_mem.nbytes)
# Append the device buffer to device bindings.
bindings.append(int(device_mem))
# Append to the appropriate list.
if engine.binding_is_input(binding):
inputs.append(HostDeviceMem(host_mem, device_mem))
else:
outputs.append(HostDeviceMem(host_mem, device_mem))
return inputs, outputs, bindings, stream
# This function is generalized for multiple inputs/outputs.
# inputs and outputs are expected to be lists of HostDeviceMem objects.
def do_inference(context, bindings, inputs, outputs, stream, batch_size=1):
# Transfer input data to the GPU.
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# Run inference.
context.execute_async(batch_size=batch_size, bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# Synchronize the stream
stream.synchronize()
# Return only the host outputs.
return [out.host for out in outputs]
# This function is generalized for multiple inputs/outputs for full dimension networks.
# inputs and outputs are expected to be lists of HostDeviceMem objects.
def do_inference_v2(context, bindings, inputs, outputs, stream):
# Transfer input data to the GPU.
[cuda.memcpy_htod_async(inp.device, inp.host, stream) for inp in inputs]
# Run inference.
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
# Transfer predictions back from the GPU.
[cuda.memcpy_dtoh_async(out.host, out.device, stream) for out in outputs]
# Synchronize the stream
stream.synchronize()
# Return only the host outputs.
return [out.host for out in outputs]
5.7 pkg/engine_export.py(test03.py)
from utils import datasets
import tensorrt as trt
from pkg import common
import torch
import numpy as np
import cv2
from utils.general import (
check_img_size, non_max_suppression, apply_classifier, scale_coords,
xyxy2xywh, plot_one_box, strip_optimizer, set_logging)
class ModelData(object):
MODEL_PATH = "ys.onnx"
INPUT_SHAPE = (3, 512, 640)
DTYPE = trt.float32
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
def build_engine_onnx(model_file):
with trt.Builder(TRT_LOGGER) as builder, builder.create_network(common.EXPLICIT_BATCH) as network, trt.OnnxParser(
network, TRT_LOGGER) as parser:
# builder.fp16_mode = True
builder.max_workspace_size = common.GiB(1)
with open(model_file, 'rb') as model:
if not parser.parse(model.read()):
print('ERROR: Failed to parse the ONNX file.')
for error in range(parser.num_errors):
print(parser.get_error(error))
return None
return builder.build_cuda_engine(network)
def build_engine(model_file):
with open(model_file, "rb") as f, trt.Runtime(TRT_LOGGER) as runtime:
return runtime.deserialize_cuda_engine(f.read())
def load_normalized_test_case(test_image, pagelocked_buffer):
def normalize_image(image):
img = image[:, :, ::-1]
img = datasets.letterbox(img, new_shape=640)[0]
img = img.transpose(2, 0, 1)
img = img.ravel()
img = img.astype(np.float32)
img /= 255.
img = np.ascontiguousarray(img)
return img
np.copyto(pagelocked_buffer, normalize_image(test_image))
return test_image
def _make_grid(nx=20, ny=20):
yv, xv = torch.meshgrid([torch.arange(ny), torch.arange(nx)])
return torch.stack((xv, yv), 2).view((1, 1, ny, nx, 2)).float()
def main():
anchors = [[10, 13, 16, 30, 33, 23], [30, 61, 62, 45, 59, 119], [116, 90, 156, 198, 373, 326]]
a = torch.tensor(anchors).float().view(3, -1, 2)
anchor_grid = a.clone().view(3, 1, -1, 1, 1, 2)
stride = torch.tensor([8., 16., 32.])
# with build_engine_onnx(ModelData.MODEL_PATH) as engine:# 解析onnx,跟下面with open("y.engine", "wb") as f:f.write(engine.serialize())一块用
with build_engine("y.engine") as engine:#直接加载引擎,更快
# with open("y.engine", "wb") as f:
# f.write(engine.serialize())
# exit()
inputs, outputs, bindings, stream = common.allocate_buffers(engine)
with engine.create_execution_context() as context:
src_img = load_normalized_test_case(cv2.imread("1.jpg"), inputs[0].host)
trt_outputs = common.do_inference_v2(context, bindings=bindings, inputs=inputs, outputs=outputs,
stream=stream)
print(trt_outputs[0].shape, trt_outputs[1].shape, trt_outputs[2].shape)
# exit()
x = []
x.append(torch.tensor(trt_outputs[0].reshape(1, 3, 64, 80, 85)))
x.append(torch.tensor(trt_outputs[1].reshape(1, 3, 32, 40, 85)))
x.append(torch.tensor(trt_outputs[2].reshape(1, 3, 16, 20, 85)))
print(x[2][0, :, 0])
z = []
grid = [torch.zeros(1)] * 3
for i in range(3):
# x[i] = x[i].permute(0, 3, 1, 2)
bs, _, ny, nx, _ = x[i].shape
grid[i] = _make_grid(nx, ny)
y = x[i].sigmoid()
y[..., 0:2] = (y[..., 0:2] * 2. - 0.5 + grid[i]) * stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * anchor_grid[i] # wh
z.append(y.view(bs, -1, 85))
pred = torch.cat(z, 1)
det = non_max_suppression(pred, 0.3, 0.3, classes=None, agnostic=False)[0]
print(det)
if det is not None and len(det):
det[:, :4] = scale_coords([512, 640], det[:, :4], src_img.shape).round()
boxes = det.cpu().detach().numpy()
for box in boxes:
box = box.astype(np.int)
cv2.rectangle(src_img, (box[0], box[1]), (box[2], box[3]), (0, 255, 0), 2)
cv2.imshow("....", src_img)
cv2.waitKey(0)
if __name__ == '__main__':
main()