1.private 修饰的方法可以通过反射访问,那么private修饰的意义在哪里?
因为private本职上是一种编程思想的体现,即封装的思想,用private修饰的变量和方法本质上都是不对外提供的,那么对于调用者来说,这些就是不可见的,所以它并不对这个事情负责;尤其是在一个大型工程里面来说,各个模块的业务范畴的定义是需要非常明确的,不归自己管的绝对不想管,所以如果我定义了一个private,那就意味着你尽量别用,如果你非得用,那么好,出了问题你负责,我不管的。
2.Java的类初始化顺序
总的原则就是先基类后自己,先静态后普通代码块后构造函数:
所以,基类的静态字段和静态代码块-->>派生类的静态代码块-->>基类普通代码块和基类普通成员变量-->>基类构造函数-->>派生类普通代码块-->>派生类构造函数
至于为什么先基类后自己,这个是很容易想明白的,因为加入我派生类依赖基类的某个变量,那肯定是要先基类准备好了,自己再去是更好的。而为什么先静态后普通代码块呢?我个人理解,是因为静态变量是属于某个类的,只要这个类被使用了,静态的就要先加载,至于后面实例化的哪个,它不管的。
3.对方法区和永久区的理解以及它们之间的关系
方法区是jvm规范里要求的,永久区是Hotspot虚拟机对方法区的具体实现,前者是规范,后者是实现方式。而Java8其实又做了修改,已经不再有永久区了,而是metaspace;
4.一个java文件有3个类,编译后有几个class文件
这个应该是有三个文件才是。
5.局部变量使用前需要显式地赋值,否则编译通过不了,为什么这么设计
因为编译器识别不出成员变量究竟会在啥时候使用和赋值,所以可以给个默认值,但是局部变量是很明显的,所以这种时候编译器给出这种约束可以极大的避免一些问题的产生。
6.ReadWriteLock读写之间互斥吗
读锁和读锁之间不互斥,其他都是互斥的。
读写锁其实是有两个锁,一个读,一个写,他们共享同一个sync,但是分别用的是共享模式和非共享模式,这个是用state的头16位和尾16位去做的。
7.Semaphore拿到执行权的线程之间是否互斥
不是互斥的。
8.写一个单例模式
public class Singleton{
private static class SingltonHandler{
private staticSingleton singleton=new Singleton();
}
publicstaticSingletongetInstance() {
return SingltonHandler.singleton;
}
}
最简单的写法就是静态内部类,静态内部类维护一个外部的变量,而不用的时候也不会去加载它。
9.B树和B+树是解决什么样的问题的,怎样演化过来,之间区别
B+树和B树之间的核心区别就在于,mysql的每个节点是存储在一个页上面的,而对于B树来说每个页所存储的数据包含三个部分(key,子节点指针和data),所以我们希望每个页上存储更多的子节点这样能够保证B树更大的度,也就带来了更小的树深度,所以这就是为什么B+树把真实的data都放在叶子节点上的原因;
10.写一个生产者消费者模式
可以用lock和condition或者wait+notify的方式来写;
11.写一个死锁
这个很简单,两个线程互斥的取两份资源即可;
12.cpu的100%定位
先找到top进程,然后jstack,然后找这个进程中的top线程,最后转换下16进制就好了;
13.int a=1是原子操作吗?
是的,a++不是,long 不是,long被volatile修饰就是了
14.for循环可以删除arraylist吗?
不可以,因为删除元素时涉及到数组元素的移动。
15.新的任务提交到线程池,线程池是怎样处理
这个其实是个考察线程池原理的问题,线程池包含核心线程数,最大线程数,和队列,一般如果没有到核心线程数,会扩大核心线程数,如果是超过核心线程数,不到队列数,会加到队列里,如果是超过了队列+核心线程数,会扩容到最大线程数,最后,都不行,会执行拒绝策略;
16.AQS和CAS原理
CAS待梳理;
17.synchronized底层实现原理
是在Java对象的头上mark word里面存放的有:
锁状态 对象的hashcode 对象分代年龄 是否是偏向锁 锁标志位
锁一共有四种状态,从低到高分别是:无锁、偏向锁、轻量级锁和重量级锁,会随着竞争情况逐渐升级但只能升级不能降级。
偏向锁是在栈帧中记录拥有偏向锁的线程id,如果是同个线程则直接获取,如果不是同个线程,那此线程会失败,并且通知这个偏向锁撤销;
重点看下锁升级:
偏向锁:如果有其他线程竞争锁,而且此时锁的拥有者还无法释放的时候,就会升级为轻量级锁;
轻量级自选锁:如果自旋次数超过了某个阈值,或者线程1在执行,线程2在自旋等待,线程3又过来竞争的时候,就膨胀成重量级锁;
18.volatile的作用
防止指令重排,可见性;
提到volatile就不得不说操作系统的解决各个cpu的高速缓存之间的缓存一致性的问题的思路,
1.在总线上加lock,但是这种的话各个cpu都阻塞了;
2.缓存一致性协议,如果发现操作的是共享变量,那就通知其他的cpu让这个缓存失效,这也就是会引发所谓的一致性协议风暴和缓存行失效的问题,也就是为什么要用clh队列做aqs的问题。
19.AOP和IOC原理
待梳理;
20.Spring怎样解决循环依赖的问题
利用缓存,先提前把各个bean暴露出去;
22.dispatchServlet是怎样分发任务的?
mvc待整理;
23.jvm gc复制算法
24.注解的原理
25.进程间通信方式;
26.Reentrantlock是可重入锁,啥是可重入?
就是可以同一个线程进入两次,这个取决于它的实现,tryacquire的时候,发现如果当前线程和占领它的锁的线程是同个线程,就会直接获取锁;
27.线程如果异常会怎样?
线程的异常必须要线程自身去捕获并处理,如果不处理,这个线程会死掉,而且,这个线程的异常并不会被主线程所捕获;
28.hashMap原理;
1.8以后版本:
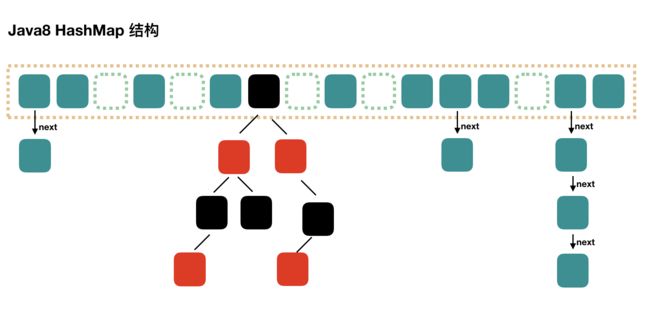
1.7以前的版本就不看了,因为目前核心重点在关注的就是1.8了,首先还是一个链表或者叫数组吧,然后每个节点上下面不一定是链表了,还有可能是红黑树,这个阈值是8;
先看put,如果不存在,直接插入就好,然后如果存在,那就进入到里面去,先取出对应位置的值放着;
首先如果是红黑树,直接插进去,如果是链表,先插进去,再转换成红黑树。
最后判断这取出的node是不是空,如果不空,覆盖掉它的value;
最后,如果整个的值超过了阈值,就扩容;
关于扩容:
第一步:把数组扩大到两倍,把阈值扩大到两倍
第二步:把原有的数据放到新的数组里,需要重新做hash,注意,这里的hash用的还是很巧妙的,它用的是hashcode&&table.size()-1 ,这样其实就把这个值散列到表的每个位置上面去,所以就也要求这个表的size必须要是powerof 2;说起来如何判断一个数字是powerof2也有个巧妙的方法,就是直接n&&(n-1)==0;
至于concurrentHashmap,最难的地方在于扩容,扩容的过程是这样的:先把这个扩容的过程分成多个子任务,然后每个子任务去做各自的扩容;
29.jvm虚拟机;
30.Java类加载和双亲委派
其实整个类加载有个非常核心的关键之处,就在于Java把获取class信息转换成byte数组这一步骤外包出去了,就是它不管你从哪里获取这个byte数组,你完全可以自行获取,这样才引出了各种各样的类加载器和双亲委派的类加载机制。
Java有两类加载器,一类是系统提供的,另外一类是自定义的:
系统提供的有三个:
bootstrap :负责加载核心类库的
extension:扩展库的ext
app:classPath下的;
所谓SPI,其实就是自己定义好了interface,但是不实现,让别人来实现,但是这里有几个问题:
1.别人的实现你怎么知道在哪儿呢?
那就放在固定的地方去META/INF底下,读取某个约定好的位置的信息,然后取出来看看叫啥名字
2.自己的类可能是引导类加载器加载的,而别人的实现无法用引导类加载器加载?
Java 应用运行的初始线程的上下文类加载器是系统类加载器。在线程中运行的代码可以通过此类加载器来加载类和资源。