Cluster集群模式
1 拓扑结构
Redis Cluster是Redis的分布式系统实现,拥有高性能和线性扩展性,建议不超过1000个节点,没有代理,使用异步复制的方式,并且不对值执行合并操作。建议搭建集群时至少6个节点,以下是6个节点的拓扑结构
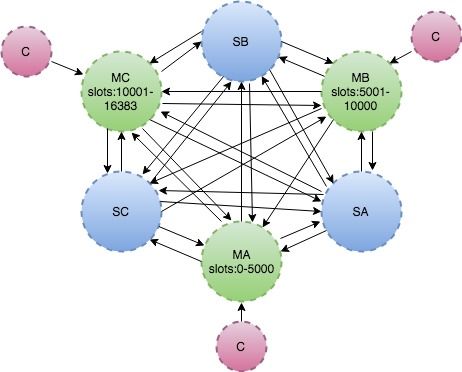
- 每个节点都有唯一的ID,第一次启动时生成(/dev/urandom)随后会保存在节点对应的配置文件中(配置文件可配置或启动时指定)
- 集群将键空间分成16384个slots,每一个主节点负责处理一部分。可以通过hash tag的方式使不同的key落在同一个节点上:例如:{user}user_id:1和{user}user_id:2会落在同一个节点,因为在进行slot分布计算时,只会计算第一个"{"和它右边的第一个"}"之间的字符串,如果长度为0则计算整个key
- 每个节点会与其他的节点建立TCP链接,通过bus port(通常是client port + 10000)。每个节点会有N-1条传出的链接和N-1条传入的链接。通过gossip协议心跳机制保持活跃。
2 节点握手
节点启动时开启集群模式(cluster_enabled),默认模式下每个节点都是独立存在,假设有两个节点A和B,都以集群模式的启动,现在介绍一下将节点B加入到节点A的集群流程
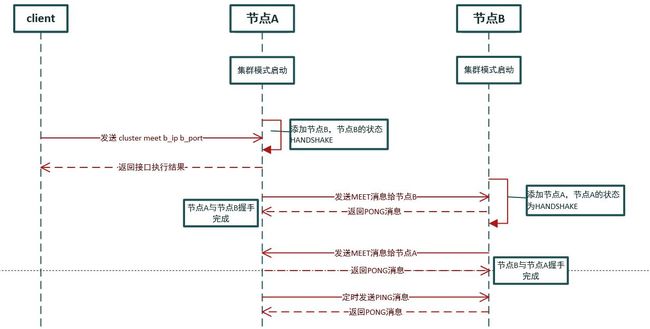
- 客户端向节点A发送 cluster meet node_b_ip node_b port命令
- 节点A将节点B添加到自己维护的节点列表
- 节点A在下一个clusterCron中,发现未连接的节点B,于是与B建立连接,并发送MEET消息
- 节点B收到MEET消息后,将节点A添加到自己维护的集群节点列表,并返回PONG消息
- 节点A接收到节点B返回的PONG消息,此时节点A与节点B握手完成
- 节点B在下一个clusterCron中,发现未连接的节点A,于是向A发起连接,并发送MEET消息
- 节点A收到节点B发送的MEET消息,回一个PONG消息
- 节点B收到节点A的PONG消息,此时节点B与节点A握手完成
3 节点间通讯协议
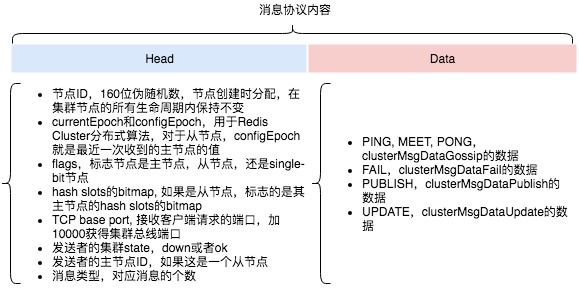
先看以下通讯协议相关的几个结构体
//消息通讯结构体
typedef struct {
char sig[4]; /* Siganture "RCmb" (Redis Cluster message bus). */
//如果是ping,meet,pong消息的总长度: sizeof(clusterMsg) + (gossipcount - 1)*(sizeof(clusterMsgDataGossip)),如果是fail或update消息则总长度跟fail和update结构相关
uint32_t totlen; /* Total length of this message */
uint16_t ver; /* Protocol version, currently set to 1. */
//节点TCP端口,例如6379
uint16_t port; /* TCP base port number. */
//消息类型 CLUSTERMSG_TYPE_XXX
uint16_t type; /* Message type */
//包含多少个gossip消息
uint16_t count; /* Only used for some kind of messages. */
uint64_t currentEpoch; /* The epoch accordingly to the sending node. */
uint64_t configEpoch; /* The config epoch if it's a master, or the last
epoch advertised by its master if it is a
slave. */
//主从复制偏移量,如果是从节点则获取对应主节点的复制偏移量
uint64_t offset; /* Master replication offset if node is a master or
processed replication offset if node is a slave. */
//发送节点的node_id
char sender[CLUSTER_NAMELEN]; /* Name of the sender node */
unsigned char myslots[CLUSTER_SLOTS/8];
//如果是从节点,主节点的node_id
char slaveof[CLUSTER_NAMELEN];
//发送节点对外的ip
char myip[NET_IP_STR_LEN]; /* Sender IP, if not all zeroed. */
char notused1[34]; /* 34 bytes reserved for future usage. */
//节点间通讯的端口
uint16_t cport; /* Sender TCP cluster bus port */
//发送节点的状态 参考:
uint16_t flags; /* Sender node flags */
//发送者所记录的集群状态
unsigned char state; /* Cluster state from the POV of the sender */
unsigned char mflags[3]; /* Message flags: CLUSTERMSG_FLAG[012]_... */
union clusterMsgData data;
} clusterMsg;
//消息数据结构体
union clusterMsgData {
/* PING, MEET and PONG */
struct {
/* Array of N clusterMsgDataGossip structures */
clusterMsgDataGossip gossip[1];
} ping;
/* FAIL */
struct {
clusterMsgDataFail about;
} fail;
/* PUBLISH */
struct {
clusterMsgDataPublish msg;
} publish;
/* UPDATE */
struct {
clusterMsgDataUpdate nodecfg;
} update;
};
/*Gossip协议结构体*/
typedef struct {
//节点的node_id
char nodename[CLUSTER_NAMELEN];
//上一次发送ping的时间
uint32_t ping_sent;
//上一次收到pong的时间
uint32_t pong_received;
char ip[NET_IP_STR_LEN]; /* IP address last time it was seen */
uint16_t port; /* base port last time it was seen */
uint16_t cport; /* cluster port last time it was seen */
uint16_t flags; /* node->flags copy */
uint32_t notused1;
} clusterMsgDataGossip;
每一次通讯的数据包格式如下
4 节点间心跳策略
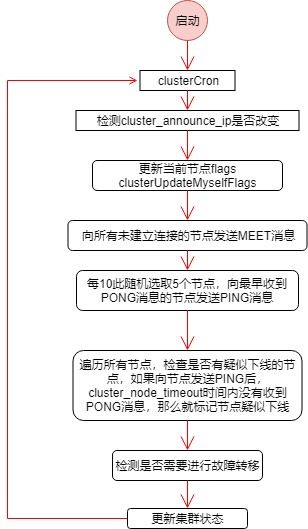
节点之间的连接利用心跳机制探测集群的状态,每一个节点会记录其向其它节点发送PING消息的时间(clusterNode.ping_sent),以及收到PONG消息的时间(clusterNode.pong_received),心跳的发送时机与这两个值相关
- 每次clusterCron向所有未建立连接的节点发送MEET消息
- 每10次clusterCron(1秒)随机选取5个节点,向最早收到PONG消息的节点发送PING消息
- 每次clusterCron会向收到PONG消息超过server.cluster_node_timeout/2的节点发送PING消息
- 收到PING或MEET消息,回复PONG消息
- 收到PONG后将clusterNode.ping_sent设置成0
5 clusterCron
前面多次提到了clusterCron,现在简单介绍一下。clusterCron在serverCron中被调用,一般情况下,serverCron每1毫秒执行一次,clusterCron每100毫秒执行一次.
int serverCron(struct aeEventLoop *eventLoop, long long id, void *clientData) {
// 省略若干代码
/* Run the Redis Cluster cron. */
run_with_period(100) {
if (server.cluster_enabled) clusterCron();
}
// 省略若干代码
}
6 节点故障检测
节点有两个状态跟故障检测相关,CLUSTER_NODE_PFAIL和CLUSTER_NODE_FAIL。当向一个节点发送PING消息后,超过server.cluster_node_time后没有收到PONG消息,就会把该节点标记成PFAIL状态,该状态通过Gossip协议进行传递。当集群中达到server.cluster->size / 2 + 1个主节点标记该节点为PFAIL状态时,会将该节点设置成FAIL状态,立即广播给其他节点.
//标记PFAIL状态代码
delay = now - node->ping_sent;
if (delay > server.cluster_node_timeout) {
/* Timeout reached. Set the node as possibly failing if it is
* not already in this state. */
if (!(node->flags & (CLUSTER_NODE_PFAIL|CLUSTER_NODE_FAIL))) {
serverLog(LL_DEBUG,"*** NODE %.40s possibly failing",
node->name);
node->flags |= CLUSTER_NODE_PFAIL;
update_state = 1;
}
}
//标记成FAIL状态代码
void markNodeAsFailingIfNeeded(clusterNode *node) {
int failures;
int needed_quorum = (server.cluster->size / 2) + 1;
//节点没超时
if (!nodeTimedOut(node)) return; /* We can reach it. */
if (nodeFailed(node)) return; /* Already FAILing. */
//获取标记node超时的主节点数量(PFAIL)
failures = clusterNodeFailureReportsCount(node);
/* Also count myself as a voter if I'm a master. */
if (nodeIsMaster(myself)) failures++;
if (failures < needed_quorum) return; /* No weak agreement from masters. */
serverLog(LL_NOTICE,
"Marking node %.40s as failing (quorum reached).", node->name);
/* Mark the node as failing. */
node->flags &= ~CLUSTER_NODE_PFAIL;
node->flags |= CLUSTER_NODE_FAIL;
node->fail_time = mstime();
/* Broadcast the failing node name to everybody, forcing all the other
* reachable nodes to flag the node as FAIL. */
//广播节点变成FAIL状态消息
if (nodeIsMaster(myself)) clusterSendFail(node->name);
clusterDoBeforeSleep(CLUSTER_TODO_UPDATE_STATE|CLUSTER_TODO_SAVE_CONFIG);
}
7 节点故障转移(master故障时)

- 假设当达到server.cluster->size / 2 + 1个master标记某个其中一个master为FAIL,被标记FAILmaster的slaves就会发起申请为master的请求 FAILOVER_AUTH_REQUEST.
- 一个master只能给一个slave投票, 根据currentEpoch值进行判断,FAILOVER_AUTH_ACK
- 当达到server.cluster->size / 2 + 1的master都投票给一个slave时,那么这个slave就能升级成master
- 如果在2被server.cluster_node_time时间内没有达到server.cluster->size/2+1时,将会server.cluster_node_time*4后开启另外一轮投票,重复前面的步骤
- 当slave升为master的条件满足后,将自己的升为master,并广播一条PONG消息通知其他所有节点。
当一个master有多个slave时,那么哪一个slave会成为master也有一定的策略
- 首先会对每一个slave进行排序rank,根据repl_offset, 值越大排名越靠前,值越小
- 发送FAILOVER_AUTH_REQUEST的时间 = mstime + 500 + random() %500 + rank*1000
8 备份迁移
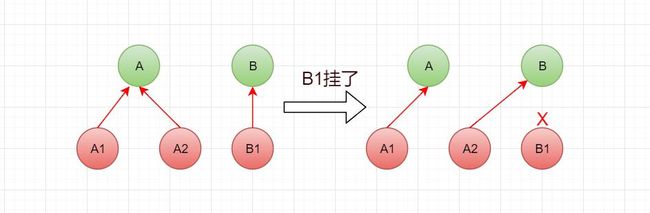
当一个master只有一个slave时,如果slave挂掉后没及时启动新的slave,master也挂掉了,那么就有一部分slots没有节点在服务。整个集群就会处于error状态(开启了cluster-require-full-coverage)
备份迁移是slave自动重配的过程。例如集群拥有两个个master:A、B,A有2个slave:A1和A2,而B只有1个salve:B1。一个简单的备份迁移过程如下:
- master B发送故障,B1升为master
- A2迁移为B1的slave,否则B1就会没有一个slave
- 如果此时B1也发生了故障
- A2就会升为master代替B1
- 此时集群还能正常提供服务
备份迁移算法过程如下:
- 计算出孤立master节点的数量(orphaned_masters)
- 计算出当前slave节点所在的master好的slave节点数量(ok_slaves),记录最大的那个(max_slaves)
- orphaned_master > 0 && max_slaves > 2 && this_ok_slaves == max_slaves 时开始出发备份迁移。
- 如果this_okslaves <= server.cluster_migration_barrier 则终止迁移
- 找出迁移的目标master,target
- 找出候选slave,candidate(符合条件的node ID最小的那个一个)
- 如果候选人是当前节点,则将当前节点的master设置成target。 clusterSetMaster(target)
9 集群的创建
在创建集群之间,先了解一下集群相关的命令和配置
9.1 相关的命令
集群(cluster)相关
>> cluster info 打印集群的信息
cluster_state:fail 集群状态,fail下线,ok上线
cluster_slots_assigned:0 已分配的slot数量
cluster_slots_ok:0 ok的slot数量
cluster_slots_pfail:0 可能失效的slot数量
cluster_slots_fail:0 已失效的slot数量
cluster_known_nodes:2 集群中node的数量
cluster_size:0 及群众设置的分片个数
cluster_current_epoch:1 集群中最大的epoch
cluster_my_epoch:1 当前节点的epoch
cluster_stats_messages_ping_sent:5237 发送ping数量
cluster_stats_messages_pong_sent:5254 发送pong数量
cluster_stats_messages_meet_sent:1 发送meet数量
cluster_stats_messages_sent:10492 总发送的数量
cluster_stats_messages_ping_received:5254 接收ping数量
cluster_stats_messages_pong_received:5238 接收pong数量
cluster_stats_messages_received:10492 总接收数量
>> cluster nodes 列出集群当前的所有节点及相关信息
f3c17749f1c773a7d323362e770ada5c76dec427 127.0.0.1:6380@16380 master - 0 1531364863652 0 connected
cb93f2bd8b75c877f44a5789234dcce9499c7957 127.0.0.1:6379@16379 myself,master - 0 0 1 connected
节点ID ip:port@cport 角色(mater|slave|myself) -或主节点id 最近一次发送ping的时间 最近一次收到pong的时间 状态(connected|disconnected)
>> cluster reset 重置集群
节点(node)相关
>> cluster meet 将ip和port指定的节点添加到集群当中
>> cluster forget 从集群中移除node_id所指定的节点
>> cluster replicate 将当前节点指定为node_id的从节点
>> cluster saveconfig 将节点的配置文件保存到硬盘
>> cluster slaves 列出node_id的所有从节点
>> cluster set-config-epoch 强者设置configEpoch
>> cluster myid 返回节点的id
槽(slot)相关
>> cluster addslots [ ...] 将一个或多个slot指派给当前节点
>> cluster delslots [ ...] 将一个或多个slot从当前节点移除
>> cluster flushslots 移除当前节点所负责的所有slot
>> cluster setslot node 将slot指派给node_id节点
>> cluster setslot migrating 将当前节点的slot迁移到node_id节点
>> cluster setslot importing 将slot从node_id节点导入当前节点
>> cluster keyslot 计算key应该被放置在哪个slot上
>> cluster countkeysinslot 计算slot目前包含的keys的数量
>> cluster getkeysinslot 返回slot中count数量的Key
>> cluster slots 返回当前节点负责的所有slot
9.2 相关的配置
- cluster-enabled yes/no
yes表示开启集群模式,此实例作为集群中的一个节点,no 表示此实例为普通单一的实例
- cluster-config-file
集群中某个节点的配置文件,不能人工编辑,有节点自动维护,记录节点的状态以及持久化一些参数
- cluster-node-timeout 1500
集群中节点能够失联的最大时间,超过这个时间,该节点就会被认为故障。如果是主节点,则它的从节点就会启动故障转移,升级成主节点。
- cluster-slave-validity-factor 10
如果设置成0,无论从节点与主节点失联多久,都会尝试升级成主节点。如果设置成正数,cluster-node-timeout*cluster-slave-validity-factor的到的时间是从节点失联后数据的最大有效时间,超过这个时间从节点不会启动故障转移。
- cluster-migration-barrier
主节点需要的最小从节点数,只有超过这个数,它的从节点才会进行迁移
- cluster-require-full-coverage yes/no
如果部分key所在的节点不可用时,yes表示此集群不可用,no表示集群依然可为可达的key提供读操作
9.3 创建集群
以创建一个拥有3个主节点和3个从节点的集群为例.
端口号6381-6386,对应的配置文件config/redis-6381.conf - config/redis-6386.conf,都开启了集群模块.
# 启动服务
>$ for((i=1;i<=6;i++)); do redis-server config/redis-638${i}.conf; done
>$ ps aux |grep redis-server
root 28994 1.8 0.5 151448 9728 ? Ssl 16:34 0:00 redis-server *:6381 [cluster]
root 28996 8.7 0.5 151448 9728 ? Ssl 16:34 0:00 redis-server *:6382 [cluster]
root 29001 1.5 0.5 151448 9732 ? Ssl 16:34 0:00 redis-server *:6383 [cluster]
root 29006 7.5 0.5 151448 9728 ? Ssl 16:34 0:00 redis-server *:6384 [cluster]
root 29011 12.5 0.5 151448 9728 ? Ssl 16:34 0:00 redis-server *:6385 [cluster]
root 29016 8.0 0.5 151448 9732 ? Ssl 16:34 0:00 redis-server *:6386 [cluster]
# 客户端连接6381端口
>$ redis-cli -c -p 6381
127.0.0.1:6381>cluster meet 127.0.0.1 6382
# 查看节点信息
127.0.0.1:6381>cluster nodes #
c3f67ff931e4cd86a36eea98798a298302fdea36 127.0.0.1:6381@16381 myself,master - 0 0 0 connected
176ac4c6e7af6acb9382bd772f0c14ccee4b60ba 127.0.0.1:6382@16382 master - 0 1531820376592 1 connected
# 同样的方法将其他节点也加入到集群
设置主从
# 连接6384端口,将6384端口对应的redis设置为6381的slave
127.0.0.1:6384>cluster replicate c3f67ff931e4cd86a36eea98798a298302fdea36
#依次将6385、6386分别设为6382、6383的slave
127.0.0.1:6384>cluster nodes
176ac4c6e7af6acb9382bd772f0c14ccee4b60ba 127.0.0.1:6382@16382 master - 0 1531821352000 1 connected
c3f67ff931e4cd86a36eea98798a298302fdea36 127.0.0.1:6381@16381 master - 0 1531821352233 3 connected
1a6da4f52163a421a8b6e6968e1027af6d2e913c 127.0.0.1:6383@16383 master - 0 1531821352735 2 connected
2160f749e4b7eb136feadea65a564439244fcfa3 127.0.0.1:6384@16384 slave c3f67ff931e4cd86a36eea98798a298302fdea36 0 1531821352000 5 connected
e1f942ff497da8d0c3f5d0c5427b2e554efd5d5a 127.0.0.1:6385@16385 slave 176ac4c6e7af6acb9382bd772f0c14ccee4b60ba 0 1531821353240 1 connected
8acd737734670e850d9d34578118ba791bca547d 127.0.0.1:6386@16386 myself,slave 1a6da4f52163a421a8b6e6968e1027af6d2e913c 0 1531821351000 4 connected
分配slots
127.0.0.1:6381>cluster info
127.0.0.1:6381> cluster info
cluster_state:fail
cluster_slots_assigned:0
cluster_slots_ok:0
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:0
cluster_current_epoch:5
cluster_my_epoch:3
cluster_stats_messages_ping_sent:1576
cluster_stats_messages_pong_sent:1566
cluster_stats_messages_meet_sent:5
cluster_stats_messages_sent:3147
cluster_stats_messages_ping_received:1566
cluster_stats_messages_pong_received:1581
cluster_stats_messages_received:3147
# 集群还处于fail状态,是因为没有分配slots
# 给6381分配slots 0-5
127.0.0.1:6381>cluster addslots 0 1 2 3 4 5
# 停掉所有redis,修改nodes-xxx.conf文件的slots,6381[0-5000],6382[5001-10000],6382[10001-16383]
>127.0.0.1:6381>cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:6
cluster_size:3
cluster_current_epoch:5
cluster_my_epoch:3
cluster_stats_messages_ping_sent:41
cluster_stats_messages_pong_sent:32
cluster_stats_messages_sent:73
cluster_stats_messages_ping_received:32
cluster_stats_messages_pong_received:36
cluster_stats_messages_received:68
# 此时集群状态正常,可提供服务了
10 重新分片
Redis Cluster支持集群在运行期间动态添加节点和删除节点。不管是添加节点还是删除节点,都是将一部分slots的处理从一个节点移动到另一个节点,移出的节点处于MIGRATING状态,移入的节点处于IMPORTING状态。
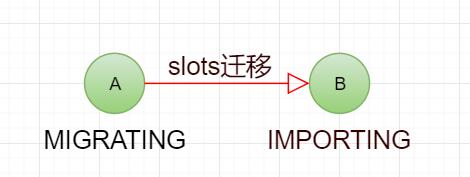 重新分片
重新分片
有以下三种情况会引起slots迁移
- 向集群添加新的空节点,将一部分slots从原来的节点迁移到新节点
- 删除集群中的一个节点,会将待删除的节点上的slots迁移到其他的节点
- 为了重新平衡每个节点处理的slots,移动一部分slots
slots迁移相关的命令
- CLUSTER ADDSLOTS slot1 [ slot2 ] ... [slotN]
- CLUSTER DELSLOTS slot1 [ slot2 ] ... [slotN]
- CLUSTER SETSLOT slot NODE node
- CLUSTER SETSLOT slot MIGRATING node
- CLUSTER SETSLOT slot IMPORTING node
迁移过程如下
假设A为迁出的节点,B为迁入的节点
- 连接A,把A节点上要迁出的slots设置成MIGRATING状态
CLUSTER SETSLOT
MIGRATING
- 连接节点B,把B节点上要迁入的slots设置成IMPORTING状态
cluster SETSLOT
IMPORTING
- 向A发送以下命令迁移对应的Key
CLUSTER GETKEYSINSLOT
获取slot对应的keys,如果对应的keys特别大,将会是一个问题
MIGRATE B_host B_port "" destination-db timeout [KEYS key [key ...]]
节点A会将数据随RESTORE(RESTORE-ASKING)命令给节点B
- 连接节点A和B执行如下命令分配slot到指定节点
CLUSTER SETSLOT
NODE
11 重定向
Redis 将所有的key划分成16384个slot,cluster中的每个节点处理一部分的slots,客户端可连接集群中任意master进行操作,有可能就会出现操作的key不在当前连接的,就会出现重定向
重定向会出现以下l情况
- MOVED重定向
当用户操作的key对应的slot不在当前连接的节点时,节点会返回MOVED slot ip:port,此时客户端需要连接ip:port对应的节点再做相应的操作。MOVED表示下一次这个slot的操作也需要到ip:port对应的节点
- ASK重定向
当用户访问的Key对应的slot所在的节点正在进行migrating,并且访问的Key已经迁移走,则返回ASK,表示这个slot的下一次请求去对应的节点上。