本文实例为大家分享了celery动态设置定时任务的具体代码,供大家参考,具体内容如下
首先celery是一种异步任务队列,如果还不熟悉这个开源软件的请先看看官方文档,快速入门。
这里讲的动态设置定时任务的方法不使用数据库保存定时任务的信息,所以是项目重启后定时任务配置就会丢失,如果想保存成永久配置,可以考虑保存到数据库、redis或者使用pickle、json保存成文件,在项目启动时自动载入。
方法原理介绍
先来看一下celery的beat运行过程。

上图是beat的主要组成结构,beat中包含了一个service对象,service中包含了一个scheduler对象,scheduler中包含了一个schedule字典,schedule中key对应的的value才是真正的定时任务,是整个beat中最小的单元。
首先分别介绍一下各个对象和它们运行的过程,beat是celery.apps.beat.Beat类创建的对象,调用beat.run()方法就可以启动beat,下面是beat.run()方法的源码。
def run(self):
print(str(self.colored.cyan(
'celery beat v{0} is starting.'.format(VERSION_BANNER))))
self.init_loader()
self.set_process_title()
self.start_scheduler()
重点是在run()方法里调用了start_scheduler()方法,而start_scheduler()方法本质上是创建了一个service对象(celery.beat.Service类),并调用service.start()方法,下面是beat.start_scheduler()方法的源码。
def start_scheduler(self):
if self.pidfile:
platforms.create_pidlock(self.pidfile)
service = self.Service(
app=self.app,
max_interval=self.max_interval,
scheduler_cls=self.scheduler_cls,
schedule_filename=self.schedule,
)
print(self.banner(service))
self.setup_logging()
if self.socket_timeout:
logger.debug('Setting default socket timeout to %r',
self.socket_timeout)
socket.setdefaulttimeout(self.socket_timeout)
try:
self.install_sync_handler(service)
service.start()
except Exception as exc:
logger.critical('beat raised exception %s: %r',
exc.__class__, exc,
exc_info=True)
raise
调用了service.start()之后,会进入一个死循环,先使用self.scheduler.tick()获取下一个任务a的定时点到现在时间的间隔,然后进入睡眠,睡眠结束之后判断如果self.scheduler里的下一个任务a可以执行,就立即执行,并获取self.scheduler里的下下一个任务b的定时点到现在时间的间隔,进入下一次循环。下面是service.start()的源码。
def start(self, embedded_process=False):
info('beat: Starting...')
debug('beat: Ticking with max interval->%s',
humanize_seconds(self.scheduler.max_interval))
signals.beat_init.send(sender=self)
if embedded_process:
signals.beat_embedded_init.send(sender=self)
platforms.set_process_title('celery beat')
try:
while not self._is_shutdown.is_set():
interval = self.scheduler.tick()
if interval and interval > 0.0:
debug('beat: Waking up %s.',
humanize_seconds(interval, prefix='in '))
time.sleep(interval)
if self.scheduler.should_sync():
self.scheduler._do_sync()
except (KeyboardInterrupt, SystemExit):
self._is_shutdown.set()
finally:
self.sync()
service.scheduler默认是celery.beat.PersistentScheduler类的实例对象,而celery.beat.PersistentScheduler其实是celery.beat.Scheduler的子类,所以scheduler.schedule是celery.beat.Scheduler类中的字典,保存的是celery.beat.ScheduleEntry类型的对象。ScheduleEntry的实例对象保存了定时任务的名称、参数、定时信息、过期时间等信息。celery.beat.Scheduler类实现了对schedule的更新方法即update_from_dict(self, dict_)方法。下面是update_from_dict(self, dict_)方法的源码。
def _maybe_entry(self, name, entry):
if isinstance(entry, self.Entry):
entry.app = self.app
return entry
return self.Entry(**dict(entry, name=name, app=self.app))
def update_from_dict(self, dict_):
self.schedule.update({
name: self._maybe_entry(name, entry)
for name, entry in items(dict_)
})
可以看到update_from_dict(self, dict_)方法实际上是向schedule中更新了self.Entry的实例对象,而self.Entry从celery.beat.Scheduler的源码知道是celery.beat.ScheduleEntry。
到这里整个流程就粗略的介绍完了,基本过程是这个样子。
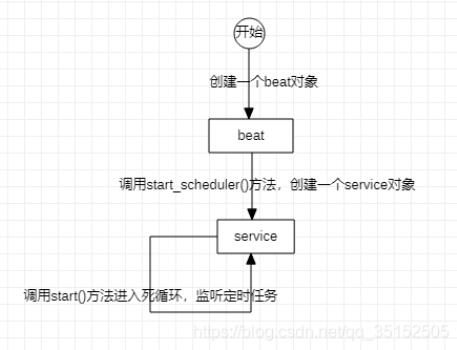
但是从前面start_scheduler()的源码可以看到,beat在内部创建一个service之后,就直接进入死循环了,所以从外面无法拿到service对象,就不能对service里的scheduler对象操作,就不能对scheduler的schedule字典操作,所以就无法在beat运行的过程中动态添加定时任务。
方法介绍
前面介绍完原理,现在来讲一下解决思路。主要思路就是让start_scheduler方法中创建的service暴露出来。所以就想到手写一个类去继承Beat,重写start_scheduler()方法。
import socket
from celery import platforms
from celery.apps.beat import Beat
class MyBeat(Beat):
'''
继承Beat 添加一个获取service的方法
'''
def start_scheduler(self):
if self.pidfile:
platforms.create_pidlock(self.pidfile)
# 修改了获取service的方式
service = self.get_service()
print(self.banner(service))
self.setup_logging()
if self.socket_timeout:
logger.debug('Setting default socket timeout to %r',
self.socket_timeout)
socket.setdefaulttimeout(self.socket_timeout)
try:
self.install_sync_handler(service)
service.start()
except Exception as exc:
logger.critical('beat raised exception %s: %r',
exc.__class__, exc,
exc_info=True)
raise
def get_service(self):
'''
这个是自定义的 目的是为了把service暴露出来,方便对service的scheduler操作,因为定时任务信息都存放在service.scheduler里
:return:
'''
service = getattr(self, "service", None)
if service is None:
service = self.Service(
app=self.app,
max_interval=self.max_interval,
scheduler_cls=self.scheduler_cls,
schedule_filename=self.schedule,
)
setattr(self, "service", service)
return self.service
在MyBeat类中添加一个get_service()方法,如果beat没有servic对象就创建一个,如果有就直接返回,方便对service的scheduler操作。
然后在此基础上实现对定时任务的增删改查操作。
def add_cron_task(task_name: str, cron_task: str, minute='*', hour='*', day_of_week='*', day_of_month='*',
month_of_year='*', **kwargs):
'''
创建或更新定时任务
:param task_name: 定时任务名称
:param cron_task: task名称
:param minute: 以下是时间
:param hour:
:param day_of_week:
:param day_of_month:
:param month_of_year:
:param kwargs:
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
entries = dict()
entries[task_name] = {
'task': cron_task,
'schedule': crontab(minute=minute, hour=hour, day_of_week=day_of_week, day_of_month=day_of_month,
month_of_year=month_of_year, **kwargs),
'options': {'expires': 3600}}
scheduler.update_from_dict(entries)
def del_cron_task(task_name: str):
'''
删除定时任务
:param task_name:
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
if scheduler.schedule.get(task_name, None) is not None:
del scheduler.schedule[task_name]
def get_cron_task():
'''
获取当前所有定时任务的配置
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
ret = [{k: {"task": v.task, "crontab": v.schedule}} for k, v in scheduler.schedule.items()]
return ret
但是仅仅是这样还不能解决问题,从前面的serive.start()的源码看到,beat启动后会进入一个死循环,如果直接在主线程启动beat,必然会阻塞在死循环中,所以需要为beat创建一个子线程,这样才影响主线程的其他操作。
flag = False beat = MyBeat(max_interval=10, app=celery_app, socket_timeout=30, pidfile=None, no_color=None, loglevel='INFO', logfile=None, schedule=None, scheduler='celery.beat.PersistentScheduler', scheduler_cls=None, # XXX use scheduler redirect_stdouts=None, redirect_stdouts_level=None) # 设置主动启动beat是为了避免使用celery -A celery_demo worker 命令重复启动worker def run(): ''' 启动Beat :return: ''' beat.run() def new_thread(): ''' 创建一个线程启动Beat 最多只能创建一个 :return: ''' global flag if not flag: t = threading.Thread(target=run, daemon=True) t.start() # 启动成功2s后才能操作定时任务 否则可能会报错 time.sleep(2) flag = True
可能看到上面的代码有人会想,为什么不在主程序加载完成就启动为beat创建一个子线程,还非要写个函数等待主动调用?这是因为例如在使用django+celery组合时,一般启动django和启动celery woker是两个独立的进程,如果让django在加载代码的时候自动启动beat的子线程,那么在使用celery -A demo_name worker 启动celery时,会重新加载一边django的代码,因为celery需要扫描每个app下的tasks.py文件,加载异步任务函数,这时启动celery woker就会也启动一个beat子线程,可能会造成定时任务重复执行的情况。所以在这里设置成主动开启beat子线程,目的就是为了celery worker启动不重复创建beat线程。
完整的代码如下:
import socket
import time
import threading
from celery import platforms
from celery.schedules import crontab
from celery.apps.beat import Beat
from celery.utils.log import get_logger
from celery_demo import celery_app
logger = get_logger('celery.beat')
flag = False
class MyBeat(Beat):
'''
继承Beat 添加一个获取service的方法
'''
def start_scheduler(self):
if self.pidfile:
platforms.create_pidlock(self.pidfile)
# 修改了获取service的方式
service = self.get_service()
print(self.banner(service))
self.setup_logging()
if self.socket_timeout:
logger.debug('Setting default socket timeout to %r',
self.socket_timeout)
socket.setdefaulttimeout(self.socket_timeout)
try:
self.install_sync_handler(service)
service.start()
except Exception as exc:
logger.critical('beat raised exception %s: %r',
exc.__class__, exc,
exc_info=True)
raise
def get_service(self):
'''
这个是自定义的 目的是为了把service暴露出来,方便对service的scheduler操作,因为定时任务信息都存放在service.scheduler里
:return:
'''
service = getattr(self, "service", None)
if service is None:
service = self.Service(
app=self.app,
max_interval=self.max_interval,
scheduler_cls=self.scheduler_cls,
schedule_filename=self.schedule,
)
setattr(self, "service", service)
return self.service
beat = MyBeat(max_interval=10, app=celery_app, socket_timeout=30, pidfile=None, no_color=None,
loglevel='INFO', logfile=None, schedule=None, scheduler='celery.beat.PersistentScheduler',
scheduler_cls=None, # XXX use scheduler
redirect_stdouts=None,
redirect_stdouts_level=None)
# 设置主动启动beat是为了避免使用celery -A celery_demo worker 命令重复启动worker
def run():
'''
启动Beat
:return:
'''
beat.run()
def new_thread():
'''
创建一个线程启动Beat 最多只能创建一个
:return:
'''
global flag
if not flag:
t = threading.Thread(target=run, daemon=True)
t.start()
# 启动成功2s后才能操作定时任务 否则可能会报错
time.sleep(2)
flag = True
def add_cron_task(task_name: str, cron_task: str, minute='*', hour='*', day_of_week='*', day_of_month='*',
month_of_year='*', **kwargs):
'''
创建或更新定时任务
:param task_name: 定时任务名称
:param cron_task: task名称
:param minute: 以下是时间
:param hour:
:param day_of_week:
:param day_of_month:
:param month_of_year:
:param kwargs:
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
entries = dict()
entries[task_name] = {
'task': cron_task,
'schedule': crontab(minute=minute, hour=hour, day_of_week=day_of_week, day_of_month=day_of_month,
month_of_year=month_of_year, **kwargs),
'options': {'expires': 3600}}
scheduler.update_from_dict(entries)
def del_cron_task(task_name: str):
'''
删除定时任务
:param task_name:
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
if scheduler.schedule.get(task_name, None) is not None:
del scheduler.schedule[task_name]
def get_cron_task():
'''
获取当前所有定时任务的配置
:return:
'''
service = beat.get_service()
scheduler = service.scheduler
ret = [{k: {"task": v.task, "crontab": v.schedule}} for k, v in scheduler.schedule.items()]
return ret
另外还可以参考我的github,相关的注释在代码里写的较为清晰。
注意:使用这种方式添加/删除定时任务只是保存在内存中的,项目重启后就会丢失。如果想要持久化,可以参照上面的方法,把相关信息保存到数据库或其他可持久保存文件中,在beat线程启动时加载相关任务信息,在对定时任务修改做增删改时及时修改数据库或文件中内容。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。