迄今为止最好用的Flink SQL教程:Flink SQL Cookbook on Zeppelin
对于初学者来说,学习 Flink 可能不是一件容易的事情。看文档是一种学习,更重要的是实践起来。但对于一个初学者来说要把一个 Flink SQL 跑起来还真不容易,要搭各种环境,真心累。很幸运的是,Flink 生态圈里有这样一款工具可以帮助你更有效率地学习 Flink:Zeppelin。本文不讲 Flink on Zeppelin 相关的内容,更关注于如何用 Zeppelin 来学习 Flink。
给大家介绍一个可能是迄今为止用户体验最好的 Flink SQL 教程:Flink Sql Cookbook on Zeppelin。你无需写任何代码,只要照着这篇文章轻松几步就能跑各种类型的 Flink SQL 语句。废话不多说,我们开始吧。
这个教程其实就是 ververica 的 flink-sql-cookbook (https://github.com/ververica/flink-sql-cookbook/ )的改进版。这里所有的例子你都可以在 Zeppelin 里跑起来,而且不用写任何代码。我已经把里面的例子都移植到了 Zeppelin。
准备环境
Step 1
git clone https://github.com/zjffdu/flink-sql-cookbook-on-zeppelin.git
这个 repo 里是一些 Zeppelin notebook,里面都是 flink-sql-cookbook 里的例子。
Step 2
下载 Flink 1.12.1 (我没有试过其他版本的 Flink,有兴趣的同学可以试下),并解压。
Step 3
编译 Flink faker,地址:https://github.com/knaufk/flink-faker/。
把编译出来的 flink-faker-0.2.0.jar 拷贝到 Flink 的 lib 目录下。这个 Flink faker 是一个特制的 table source,用来生成测试数据。我们的很多例子里都会用到这个 Flink faker。
Step 4
运行下面的命令启动最新版本的 Zeppelin。
docker run -p 8081:8081 -p 8080:8080 --rm -v $PWD/logs:/logs -v /Users/jzhang/github/flink-sql-cookbook-on-zeppelin:/notebook -v /Users/jzhang/Java/lib/flink-1.12.1:/flink -e ZEPPELIN_LOG_DIR='/logs' -e ZEPPELIN_NOTEBOOK_DIR='/notebook' --name zeppelin apache/zeppelin:0.9.0
需要注意的是这里的 2 个目录:
/Users/jzhang/github/flink-sql-cookbook-on-zeppelin(这是Step 1 里clone 下来的 repo 目录)
/Users/jzhang/Java/lib/flink-1.12.1 (这是 Step 2 下载下来并解压之后的 Flink 目录)
这两个目录是我自己本地目录,请替换成你自己的目录。
体验 Flink Sql Cookbook 教程
好了,现在教程环境已经 ready 了,浏览器打开 http://localhost:8080 开始你的 Flink Sql 学习之旅吧。

这是 Zeppelin 的 UI,里面已经有了一个文件夹 Flink Sql Cookbook,内含所有 Flink Sql 教程。首先我们需要配置下 Flink 解释器,点击右上角的菜单,选择 interpreter,找到 Flink interpreter,修改其中的 FLINK_HOME 为 /flink (也就是上面 docker 命令里我们挂载的 flink),然后点击重启 interpreter。

如果你碰到如下的错误的话,请往下拉,看 Depenendies 里是不是有个用户名在那里,如果是的话,把它删掉再 save(这是 Zeppelin 的一个前端 bug,社区正在 fix)


例子1:Filtering Data
接下来我们就选择其中里的 Foundations/04 Filtering Data 来体验下。
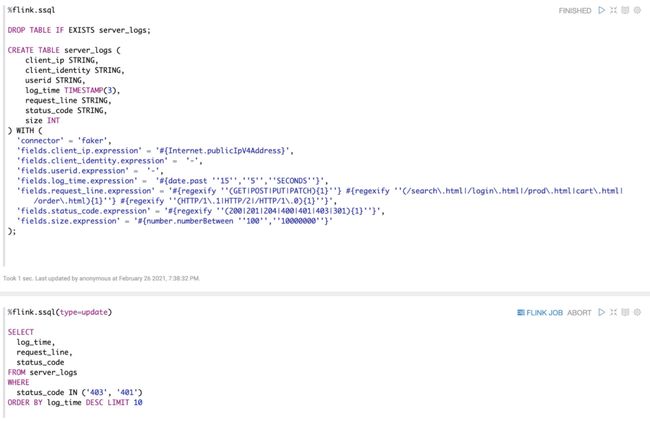
这里有 2 个段落(Paragraph),第一个段落是创建一个 server_logs 表,第二个段落是用 select where 语句去过滤这张表里的数据,并按时间排序取最新的 10 条数据。下图就是执行完 select 语句的效果,大家可以看到里面的数据每隔 3 秒钟会更新下,并且 status_code 的确永远都是 401 或者 403,验证了我们的 SQL 逻辑。右上角还有一个 FLINK JOB 的链接,点进去之后你还能看个这个 Job 的详细信息。

例子2:Lateral Table Join
接下来我们来看一个 Lateral Table Join 的例子,这是 Flink SQL 里的其中一种 Join 类型。初学者看到这个名词第一感觉会有点懵逼,上网查完资料之后也是似懂非懂的感觉,如果这时候有个比较直观的例子给你,应该会对你的理解非常有帮助。这个教程里就自带了这么一个例子,打开 Joins/06 Lateral Table Join,运行之后,你就能看到如下的效果。

这里我就举这 2 个例子,里面还有很多很多有用的例子(如下图所示),大家可以自己去学习,可以尝试修改下 SQL 再运行看看结果有什么不一样。

以上是我花了周末 2 天时间整理出来的学习资料,希望对大家学习 Flink 有所帮助,共同进步。不过这个教程还有改进的空间,有兴趣的同学可以一起来改进,目前还有如下 3 个点可以改进:
每个Note里的说明文档都是英文的,可以翻译成中文,让更多人学习起来方便些。
现在每个教程都是文字形式,如果有谁能为每个教程都做个小视频,配合讲解的话,我觉得效果会更好。
增加更多案例教程,现在虽然内容很多,但还有空间增加更多教程。
有兴趣想为这个教程做贡献的同学请发邮件到这个地址联系我:[email protected], 对 Flink on Zeppelin 感兴趣的可以加入钉钉群:32803524
Flink on Zeppelin 这个项目是从 Flink 1.10 开始,目前为止已经支持了 3 个 Flink 的大版本。接下来我们还有很多有挑战的事情要去做,比如 Application Mode 的支持、K8s 的支持、调度的支持等等。Flink on Zeppelin 是我们做的工作的其中一部分,其他开源引擎的支持我们也会去做,我们的目标是做一个用户体验最好的基于开源组件的数据开发平台,有兴趣的同学可以看看下面的招聘详情,欢迎加入我们的数据开发团队。
我们的主要职责是为阿里云上的各大中小企业客户提供大数据和 AI 的基础服务。你的工作将是围绕 Spark、Flink、Hadoop、Tensorflow、PyTorch 等开源组件构建一个易用的,企业级的大数据和 AI 开放平台。不仅有技术的挑战,也需要做产品的激情。我们采用大量的开源技术(Hadoop、Flink、Spark、Zeppelin、 Kubernetes、Tensorflow、Pytorch 等等),并且致力于回馈到开源社区。
如果你对开源,大数据或者 AI 感兴趣,这里有最好的土壤。拥有在 Apache Flink、 Apache Kafka、Apache Zeppelin、Apache Beam、Apache Druid、Apache HBase 等诸多开源领域的 Committer & PMC。感兴趣的同学请发简历到:[email protected]。
▼ 关注「Flink 中文社区」,获取更多技术干货 ▼

???? 你也「在看」吗?