三维点云学习(8)5-3D Feature Description 实现FPFH
三维点云学习(8)5-3D Feature Description 实现FPFH
本次python实现FPFH代码,大部分参考:大神的GitHub
参考博客:【PCL学习笔记】之快速点特征直方图FPFH - pcl::FPFHSignature33
本次使用的数据集是:modelNet40 的 airplane_0001.txt
modelNet40 数据集下载
为40种物体的三维点云数据集
链接:https://pan.baidu.com/s/1LX9xeiXJ0t-Fne8BCGSjlQ
提取码:es14
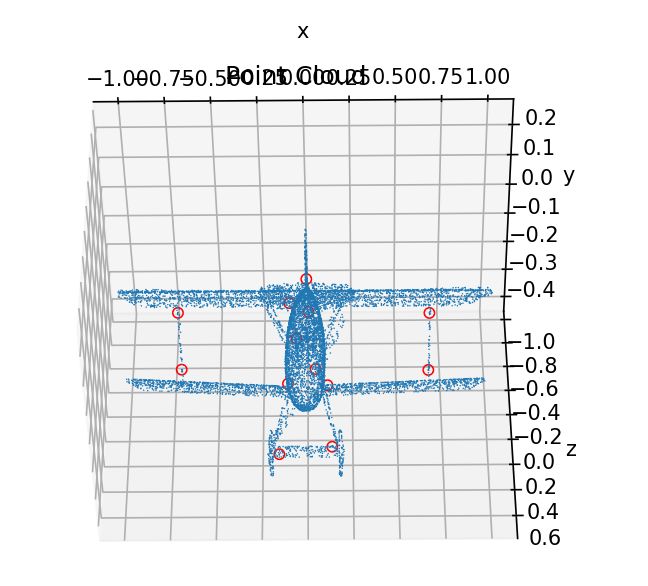
效果图:
使用 ISS 特征点提取出的 keypoints:
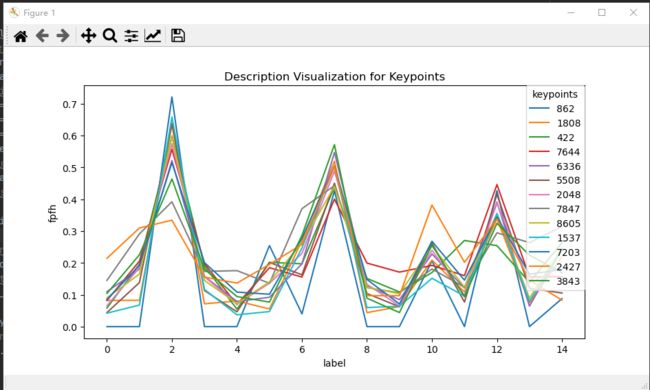
所有特征点的 FPFH:
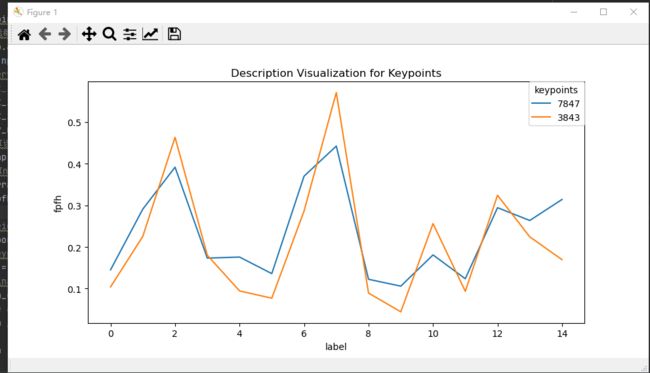
相似的特征点 FPFH比较:
代码流程:
iss 代码参考 三维点云学习(7)5-Feature 实现ISS
step1 使用iss 找出所有keypoint,并以label的形式输出
step2 求出所有点的法向量,在modelNet40数据集中,每个数据点的后三位为该点的法向量
step3 构建radius nn tree
step4 求解每个keypoint的 fpfh:
step5 寻找每个keypoint 的nearest points
step6 计算该关键点群 权重 weights
step7 计算该关键点的邻近点的 spfh
step8 计算 u,v,w
step9 计算直方图 histogram
step10 拼接直方图 histogram
step11 该关键点的邻近点的 spfh 和
step12 计算该关键点的 spfh
step12 计算该关键点FPFH = spfh(keypoint) + spfh(nearest)
测试FPFH:
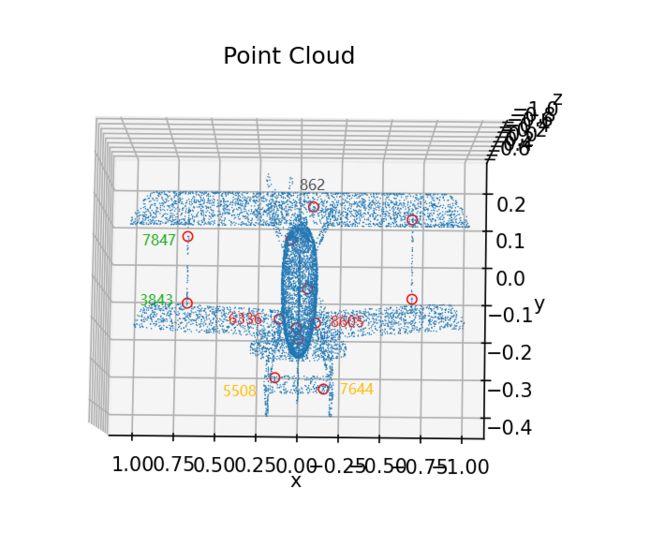
测试方法:通过比较相同特征点的FPFH分布情况,判断FPFH算法是否合适,如下颜色相同为经过测试得出的相近特征点,若相似关键点的FPFH分布大致相等,则可验证该FPFH算法效果良好:
测试模块:
#visualization test similar feature description ,相近的点 7847-3843 ; 6336-8605 ; 5508-7644
test_keypoint_idx = [7847,3843] # [7847,3843] , [6336,8605] , [5508,7644]
test_FPFH = np.asarray(
[describe(point_cloud_raw, nearest_idx, keypoint_id, radius, B) for keypoint_id in test_keypoint_idx]
)
visual_feature_description(test_FPFH, test_keypoint_idx)
测试结果:
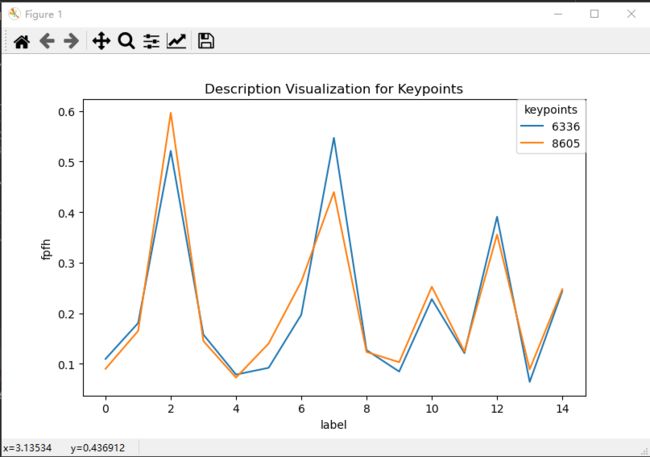
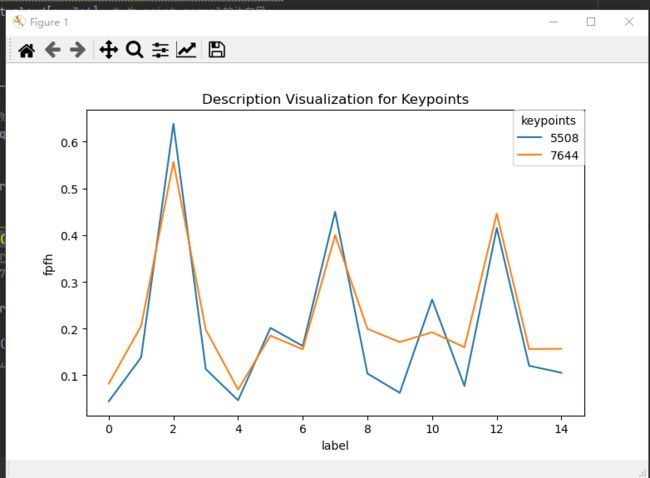
部分代码模块:
FPFH折线图可视化:
def visual_feature_description(fpfh,keypoint_idx):
for i in range(len(fpfh)):
x = [i for i in range(len(fpfh[i]))]
y = fpfh[i]
plt.plot(x,y,label=keypoint_idx[i])
#添加显示图例
plt.title('Description Visualization for Keypoints')
plt.legend(bbox_to_anchor=(1, 1), # 图例边界框起始位置
loc="upper right", # 图例的位置
ncol=1, # 列数
mode="None", # 当值设置为“expend”时,图例会水平扩展至整个坐标轴区域
borderaxespad=0, # 坐标轴和图例边界之间的间距
title="keypoints", # 图例标题
shadow=False, # 是否为线框添加阴影
fancybox=True) # 线框圆角处理参数
plt.xlabel("label")
plt.ylabel("fpfh")
plt.show()
求解 sfph
def get_spfh(point_cloud, nearest_idx, keypoint_id, radius, B): # single pfh
points = np.asarray(point_cloud)
keypoint = np.asarray(point_cloud)[keypoint_id]
#remove query point 去除关键点 :
key_nearest_idx = nearest_idx[keypoint_id]
key_nearest_idx = list(set(nearest_idx[keypoint_id]) - set([keypoint_id]))
key_nearest_idx = np.asarray(key_nearest_idx)
##step8 计算 u,v,w
#向量 p2_p1
diff = points[key_nearest_idx] - keypoint # p2 - p1,shape: (k,3) k为该点有多少个nearest points
diff /= np.linalg.norm(diff,ord=2,axis=1)[:,None] #[:,None]的效果就是将二维数组按每行分割,最后形成一个三维数组 ,eg shape : (k,1)
#compute n1 n2
n1 = np.asarray(point_cloud_normals[keypoint_id]) #keypoint 邻近点的法向量
n2 = np.asarray(point_cloud_normals[key_nearest_idx]) #keypoint 邻近点的邻近点的法向量
#compute u v w
u = n1
v = np.cross(u,diff)
w = np.cross(u,v)
#compute alpha phi theta 三元组
alpha = (v*n2).sum(axis=1)
phi = (u * diff).sum(axis=1)
theta = np.arctan2((w * n2).sum(axis=1), (u * n2).sum(axis=1))
##step9 计算直方图 histogram
# get alpha histogram:
alpha_histogram = np.histogram(alpha, bins=B, range=(-1.0, +1.0))[0]
alpha_histogram = alpha_histogram / alpha_histogram.sum()
# get phi histogram:
phi_histogram = np.histogram(phi, bins=B, range=(-1.0, +1.0))[0]
phi_histogram = phi_histogram / phi_histogram.sum()
# get theta histogram:
theta_histogram = np.histogram(theta, bins=B, range=(-np.pi, +np.pi))[0]
theta_histogram = theta_histogram / theta_histogram.sum()
##step10 拼接直方图 histogram
# build signature:
signature = np.hstack(
(
# alpha:
alpha_histogram,
# phi:
phi_histogram,
# theta:
phi_histogram
)
)
return signature
describe feature
def describe(point_cloud, nearest_idx, keypoint_id, radius, B): # single pfh
##step5 寻找每个keypoint 的nearest points
points = np.asarray(point_cloud)
keypoint = np.asarray(point_cloud)[keypoint_id]
#remove query point 去除关键点 :
key_nearest_idx = nearest_idx[keypoint_id]
key_nearest_idx = list(set(nearest_idx[keypoint_id]) - set([keypoint_id]))
key_nearest_idx = np.asarray(key_nearest_idx)
k = len(key_nearest_idx) #keypoint的临近点个数
##step6 计算该关键点 群 权重 weights:
W = 1.0 / np.linalg.norm(points[key_nearest_idx] - keypoint , ord=2, axis=1)
##step7 计算nearest points 的spfh
X = np.asarray(
[get_spfh(point_cloud,nearest_idx,i,radius,B) for i in key_nearest_idx]
)
##step11 neighbor 的 spfh 权重和
spfh_neighborhood = 1.0 / (k) * np.dot(W, X)
##step12 keypoints 的 spfh
spfh_query = get_spfh(point_cloud,nearest_idx,keypoint_id,radius,B)
##step13 finally
spfh = spfh_query + spfh_neighborhood
# normalize again:
spfh = spfh / np.linalg.norm(spfh)
return spfh
全部代码:
FPFH.py
#FPFH.py
import open3d as o3d
import os
import numpy as np
from pyntcloud import PyntCloud
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.neighbors import KDTree # KDTree 进行搜索
import random
from ISS import iss,Point_Cloud_Show # iss feature detection
from pandas import DataFrame
def visual_feature_description(fpfh,keypoint_idx):
for i in range(len(fpfh)):
x = [i for i in range(len(fpfh[i]))]
y = fpfh[i]
plt.plot(x,y,label=keypoint_idx[i])
#添加显示图例
plt.title('Description Visualization for Keypoints')
plt.legend(bbox_to_anchor=(1, 1), # 图例边界框起始位置
loc="upper right", # 图例的位置
ncol=1, # 列数
mode="None", # 当值设置为“expend”时,图例会水平扩展至整个坐标轴区域
borderaxespad=0, # 坐标轴和图例边界之间的间距
title="keypoints", # 图例标题
shadow=False, # 是否为线框添加阴影
fancybox=True) # 线框圆角处理参数
plt.xlabel("label")
plt.ylabel("fpfh")
plt.show()
def get_spfh(point_cloud, nearest_idx, keypoint_id, radius, B): # single pfh
points = np.asarray(point_cloud)
keypoint = np.asarray(point_cloud)[keypoint_id]
#remove query point 去除关键点 :
key_nearest_idx = nearest_idx[keypoint_id]
key_nearest_idx = list(set(nearest_idx[keypoint_id]) - set([keypoint_id]))
key_nearest_idx = np.asarray(key_nearest_idx)
##step8 计算 u,v,w
#向量 p2_p1
diff = points[key_nearest_idx] - keypoint # p2 - p1,shape: (k,3) k为该点有多少个nearest points
diff /= np.linalg.norm(diff,ord=2,axis=1)[:,None] #[:,None]的效果就是将二维数组按每行分割,最后形成一个三维数组 ,eg shape : (k,1)
#compute n1 n2
n1 = np.asarray(point_cloud_normals[keypoint_id]) #keypoint 邻近点的法向量
n2 = np.asarray(point_cloud_normals[key_nearest_idx]) #keypoint 邻近点的邻近点的法向量
#compute u v w
u = n1
v = np.cross(u,diff)
w = np.cross(u,v)
#compute alpha phi theta 三元组
alpha = np.multiply(v,n2).sum(axis=1)#alpha = (v*n2).sum(axis=1)
phi = np.multiply(u,diff).sum(axis=1)#phi = (u * diff).sum(axis=1)
theta = np.arctan2(np.multiply(w,n2).sum(axis=1), (u * n2).sum(axis=1))#theta = np.arctan2((w * n2).sum(axis=1), (u * n2).sum(axis=1))
##step9 计算直方图 histogram
# get alpha histogram:
alpha_histogram = np.histogram(alpha, bins=B, range=(-1.0, +1.0))[0]
alpha_histogram = alpha_histogram / alpha_histogram.sum()
# get phi histogram:
phi_histogram = np.histogram(phi, bins=B, range=(-1.0, +1.0))[0]
phi_histogram = phi_histogram / phi_histogram.sum()
# get theta histogram:
theta_histogram = np.histogram(theta, bins=B, range=(-np.pi, +np.pi))[0]
theta_histogram = theta_histogram / theta_histogram.sum()
##step10 拼接直方图 histogram
# build signature:
signature = np.hstack(
(
# alpha:
alpha_histogram,
# phi:
phi_histogram,
# theta:
theta_histogram
)
)
return signature
def describe(point_cloud, nearest_idx, keypoint_id, radius, B): # single pfh
##step5 寻找每个keypoint 的nearest points
points = np.asarray(point_cloud)
keypoint = np.asarray(point_cloud)[keypoint_id]
#remove query point 去除关键点 :
key_nearest_idx = nearest_idx[keypoint_id]
key_nearest_idx = list(set(nearest_idx[keypoint_id]) - set([keypoint_id]))
key_nearest_idx = np.asarray(key_nearest_idx)
k = len(key_nearest_idx) #keypoint的临近点个数
##step6 计算该关键点 群 权重 weights:
W = 1.0 / np.linalg.norm(points[key_nearest_idx] - keypoint , ord=2, axis=1)
##step7 计算nearest points 的spfh
X = np.asarray(
[get_spfh(point_cloud,nearest_idx,i,radius,B) for i in key_nearest_idx]
)
##step11 neighbor 的 spfh 权重和
spfh_neighborhood = 1.0 / (k) * np.dot(W, X)
##step12 keypoints 的 spfh
spfh_query = get_spfh(point_cloud,nearest_idx,keypoint_id,radius,B)
##step13 finally
spfh = spfh_query + spfh_neighborhood
# normalize again:
spfh = spfh / np.linalg.norm(spfh)
return spfh
if __name__ == '__main__':
point_cloud = np.genfromtxt(r"airplane_0001.txt", delimiter=",")
point_cloud_raw = point_cloud[:, 0:3] # 为 xyz的 N*3矩阵
##step1 使用iss 找出所有关键点,并以label的形式输出
keypoint_idx = iss(point_cloud_raw)
print(keypoint_idx)
feature_point = point_cloud[keypoint_idx]
#visualization feature points
#Point_Cloud_Show(point_cloud,feature_point)
##step2 求出所有点的法向量,在modelNet40数据集中,每个数据点的后三位为该点的法向量
point_cloud_normals = point_cloud[:, 3:6] # 为 point normal的法向量
##step3 构建radius nn tree
leaf_size = 4
radius = 0.05
search_tree = KDTree(point_cloud_raw,leaf_size) #构建 kd_tree
##step4 求解每个关键点的 spfh
B = 5 # 每个 直方图 bin的个数
nearest_idx = search_tree.query_radius(point_cloud_raw, radius) #求解每个点的最邻近点
#description the keypoints
FPFH = np.asarray(
[describe(point_cloud_raw, nearest_idx, keypoint_id, radius, B) for keypoint_id in keypoint_idx]
)
#visualization all feature description
visual_feature_description(FPFH,keypoint_idx)
#visualization test similar feature description ,相近的点 7847-3843 ; 6336-8605 ; 5508-7644
test_keypoint_idx = [7847,3843] # [7847,3843] , [6336,8605] , [5508,7644]
test_FPFH = np.asarray(
[describe(point_cloud_raw, nearest_idx, keypoint_id, radius, B) for keypoint_id in test_keypoint_idx]
)
visual_feature_description(test_FPFH, test_keypoint_idx)
# describe(point_cloud_raw, nearest_idx, keypoint_idx[0], radius, B)
ISS.py
#ISS.py
import open3d as o3d
import os
import numpy as np
from pyntcloud import PyntCloud
import matplotlib.pyplot as plt
from sklearn.neighbors import KDTree # KDTree 进行搜索
import random
from pandas import DataFrame
# matplotlib显示点云函数
def Point_Cloud_Show(point_cloud,feature_point):
fig = plt.figure(dpi=150)
ax = fig.add_subplot(111, projection='3d')
ax.scatter(point_cloud[:, 0], point_cloud[:, 1], point_cloud[:, 2], cmap='spectral', s=2, linewidths=0, alpha=1, marker=".")
ax.scatter(feature_point[:, 0], feature_point[:, 1], feature_point[:, 2], cmap='spectral', s=2, linewidths=5, alpha=1,marker=".",color='red')
# ax.scatter(feature_point[0], feature_point[1], feature_point[2], cmap='spectral', s=2, linewidths=5,
# alpha=1, marker=".", color='red')
plt.title('Point Cloud')
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
plt.show()
def compute_cov_eigval(point_cloud):
x = np.asarray(point_cloud[:,0])
y = np.asarray(point_cloud[:,1])
z = np.asarray(point_cloud[:,2])
M = np.vstack((x, y, z)) # 每行表示一个属性, 每列代表一个点
cov = np.cov(M) # 使用每个点的坐标求解cov
eigval, eigvec = np.linalg.eigh(cov) # 求解三个特征值,升序排列 linda1 < linda2 < linda3
eigval = eigval[np.argsort(-eigval)] # 改为降序排列 linda1 > linda2 > linda3
return eigval #返回特征值
def iss(data):
#parameters
eigvals = []
feature = []
T = set() #T 关键点的集合
linda3_threshold = None #阈值,初步筛选 ,各文件参数 airplane_0001:0.001; chair_0001:0.0001
#构建 kd_tree
leaf_size = 4
radius = 0.1 # 各文件参数 airplane_00001:0.1; chair_0001:0.1
tree = KDTree(data,leaf_size)
#step1 使用radius NN 得到n个初始关键点, threshold 阈值 :每个radius内的linda大于某个数值
nearest_idx = tree.query_radius(data,radius)
for i in range(len(nearest_idx)):
eigvals.append(compute_cov_eigval(data[nearest_idx[i]]))
eigvals = np.asarray(eigvals) # 求解每个点在各自的 radius 范围内的linda
# print(eigvals) #打印所有的 特征值,供调试用
# 根据linda3的数值 确定linda3_threshold(linda的阈值)
linda3_threshold = np.median(eigvals,axis=0)[2]*5 #阈值取大约 是所有linda3的 中值得5倍, eg 为什么取5倍是个人调试决定,也可取1倍
# print(linda3_threshold)
for i in range(len(nearest_idx)):
if eigvals[i,2] > linda3_threshold: # compute_cov_eigval(data[nearest_idx[i]])[2] -> 每个radius 里的最小的特征值 linda3
T.add(i) #获得初始关键点的索引
# print(T) #输出 初始关键点
#step2 有 重叠(IOU)的 关键点群
unvisited = T #未访问集合
while len(T):
unvisited_old = unvisited #更新访问集合
core = list(T)[np.random.randint(0,len(T))] #从 关键点集T 中随机选取一个 关键点core
unvisited = unvisited - set([core]) #把核心点标记为 visited,从 unvisited 集合中剔除
visited = []
visited.append(core)
while len(visited): #遍历所有初始关键点
new_core = visited[0]
if new_core in T:
S = unvisited & set(nearest_idx[new_core]) #S : 当前 关键点(core) 的范围内所包含的其他关键点
# print(T)
# print(S)
visited += (list(S))
unvisited = unvisited - S
visited.remove(new_core) #new core 已做检测,去掉new core
cluster = unvisited_old - unvisited #cluster, 有 重叠(IOU)的 关键点群
T = T - cluster #去掉该类对象里面包含的核心对象,差集
#step3 NMS 非极大抑制,求解 一个关键点群的linda3最大 为 关键点
cluster_linda3 = []
for i in list(cluster):
cluster_linda3.append(eigvals[i][2]) #获取 每个关键点 的 linda3
cluster_linda3 = np.asarray(cluster_linda3)
NMS_OUTPUT = np.argmax(cluster_linda3)
feature.append(list(cluster)[NMS_OUTPUT]) #添加到 feature 特征点数组中
#output
return feature
if __name__ == '__main__':
point_cloud = np.genfromtxt(r"airplane_0001.txt", delimiter=",")
point_cloud = point_cloud[:, 0:3] # 为 xyz的 N*3矩阵
feature_idx = iss(point_cloud)
feature_point = point_cloud[feature_idx]
print(feature_point)
Point_Cloud_Show(point_cloud,feature_point)