python动态网页抓取实例_Python网络爬虫:利用逆向工程实现动态网页的抓取,python,实战,爬取...
前言
之前写过介绍过网络爬虫的文章,都是一些基础知识,所以在接下来我们完成一个小任务——利用逆向工程爬取一个动态网页,360壁纸网站(
https://image.so.com/z?ch=wallpaper#/
),爬取前十页图片:
面临问题
网页是采用JavaScript做的异步加载,通俗来说就是网页一直往下滑都有,但是url从来没有变过,这就是一个异步加载,所以关键问题就是怎么找真正的url。
异步加载寻找真正的url
1.第一步,打开开发者工具,点到XHR,XHR就是专门存放异步加载的网页组件的。

2.进行刷新,并且往下滑。注意观察XHR下的name,会出现新的XHR,点进去。


3.如下图出现的Request URL可能就是我们需要找的真实URL,但是不能绝对,我们打开看看是不是。
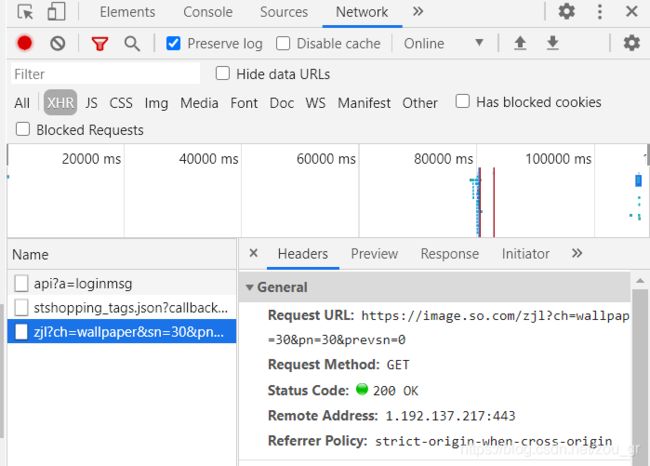
4.部分展示如下,可以观察原始URL

编写程序
#导入相关库
from bs4 import BeautifulSoup
import requests
from lxml import etree
import requests
import os
# 原始数据获取URL
raw_url = 'https://image.so.com/zjl?ch=wallpaper&sn=30&pn=300&prevsn=30'
# 根据开发者工具中的request header信息来设置headers
#headers的作用就是为了我们的爬虫能够模拟浏览器去查找,让系统以为是人为操作的下载的
headers = {
'Host':'www.image.so.com',
'X-Requested-With': 'XMLHttpRequest',
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'
}
先实现简单的爬取第一张图片
raw_url = 'https://image.so.com/zjl?ch=wallpaper&sn=30&pn=300&prevsn=30'
## 实现爬取单张图片
res = requests.get(raw_url, headers=headers) #发出get请求
_json = res.json() #拿到源代码的json文件,是用列表形式
_1_dic = _json.get('list')[0] #拿到第一张图片的信息
_1_url = _1_dic.get('imgurl') #到第一张图片的信息的url
res1 = requests.get(_1_url) #请求
img = res1.content #拿到图片信息
with open('picture.jpg', 'wb') as f: #利用字节的方式进行保存图片
f.write(img)
注释已经把代码解释的很清楚了,有点模糊的话,就把值打印出来看看,这样就明白多了。接着我们现在要做的事就是把用函数封装起来,这样使用方便。
name = []
i = 0
def save_image(url):
# filename = url.lstrip('http://').replace('.', '').replace('/', '').rstrip('jpg')+'.jpg'
global i
filename = name[i]+'.jpg'
filename = 'pic_360/'+filename #修改放在指定文件夹
# 将图片地址转化为图片文件名
try:
res = requests.get(url)
if res.ok:
img = res.content
if not os.path.exists(filename): # 检查该图片是否已经下载过
with open(filename, 'wb') as f:
f.write(img)
print("图片下载完成")
i += 1
except Exception:
print('Failed to load the picture')
def get_json():
try:
res = requests.get(raw_url, headers=headers)
if res.ok: # 成功访问
return res.json() # 返回json
else:
print('not ok')
return False
except Exception as e:
print('Error here:\t', e)
def json_parser(json):
if json is not None:
news_list = json.get('list')
if not news_list:
return False
for news_item in news_list:
name.append(news_item.get('title'))
pic_url = news_item.get('imgurl')
yield pic_url # 使用生成器yield方法
def worker():
raw_json = get_json() # 获取原始JSON数据
print(raw_json)
urls = json_parser(raw_json)
for url in urls:
save_image(url)
if __name__ == '__main__':
worker()
整个思路和爬取单张图片区别不大,比较大的改变就是增加了异常捕捉,爬虫这个不搞异常捕捉就真的郁闷的,因为第一站能爬,第二章也能,说不定第n不能爬,结果前面爬的都没用。如果还不能理解函数式这段代码,重要就是拆开看看,对于函数式程序我的建议都是如此。
爬取结果部分展示: