《Python自然语言处理(第二版)-Steven Bird等》学习笔记:第01章 语言处理与Python
第01章 语言处理与Python
- 1.1 语言计算:文本和单词
-
- Python入门
- NLTK 入门
- 搜索文本
- 计数词汇
- 1.2 近观Python:将文本当做词链表
-
- 链表(list,也叫列表)
- 索引列表
- 变量
- 字符串
- 1.3 计算语言:简单的统计
-
- 频率分布
- 细粒度的选择词
- 词语搭配和双连词(bigrams)
- 计数其他东西
- 1.4 回到Python决策与控制
-
- 条件
- 对每个元素进行操作
- 嵌套代码块
- 条件循环
- 1.5 自动理解自然语言
-
- 词意消歧
- 指代消解
- 自动生成语言
- 机器翻译
- 人机对话系统
- 文本的含义
- NLP 的局限性
- 1.6 小结
1.1 语言计算:文本和单词
Python入门
- 输入一些你自己的表达式
交互式解释器——将要运行你的Python 代码的程序——里面直接打字。在Windows 中,你可以在“程序→Python”中找到。
1+5*2-3
8
1/3
0.3333333333333333
1.0/3.0
0.3333333333333333
- 无意义的表达式
NLTK 入门
首先应该安装NLTk。可以从http://www.nltk.org/免费下载。按照说明下载适合你的操作系统的版本。安装完NLTK 之后,像前面那样启动Python解释器。
import nltk
nltk.download()
showing info https://raw.githubusercontent.com/nltk/nltk_data/gh-pages/index.xml
True
from nltk.book import * #从NLTK 的book 模块加载所有的东西
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
任何时候我们想要找到这些文本,只需要在Python 提示符后输入它们的名字。
text1
text2
搜索文本
- 词语索引视图显示一个指定单词的每一次出现,连同一些上下文一起显示。
text1.concordance("monstrous") #查一下《白鲸记》中的词monstrous
Displaying 11 of 11 matches:
ong the former , one was of a most monstrous size . ... This came towards us ,
ON OF THE PSALMS . " Touching that monstrous bulk of the whale or ork we have r
ll over with a heathenish array of monstrous clubs and spears . Some were thick
d as you gazed , and wondered what monstrous cannibal and savage could ever hav
that has survived the flood ; most monstrous and most mountainous ! That Himmal
they might scout at Moby Dick as a monstrous fable , or still worse and more de
th of Radney .'" CHAPTER 55 Of the Monstrous Pictures of Whales . I shall ere l
ing Scenes . In connexion with the monstrous pictures of whales , I am strongly
ere to enter upon those still more monstrous stories of them which are to be fo
ght have been rummaged out of this monstrous cabinet there is no telling . But
of Whale - Bones ; for Whales of a monstrous size are oftentimes cast up dead u
text2.concordance("affection") #搜索《理智与情感》中的词affection
Displaying 25 of 79 matches:
, however , and , as a mark of his affection for the three girls , he left them
t . It was very well known that no affection was ever supposed to exist between
deration of politeness or maternal affection on the side of the former , the tw
d the suspicion -- the hope of his affection for me may warrant , without impru
hich forbade the indulgence of his affection . She knew that his mother neither
rd she gave one with still greater affection . Though her late conversation wit
can never hope to feel or inspire affection again , and if her home be uncomfo
m of the sense , elegance , mutual affection , and domestic comfort of the fami
, and which recommended him to her affection beyond every thing else . His soci
ween the parties might forward the affection of Mr . Willoughby , an equally st
the most pointed assurance of her affection . Elinor could not be surprised at
he natural consequence of a strong affection in a young and ardent mind . This
opinion . But by an appeal to her affection for her mother , by representing t
every alteration of a place which affection had established as perfect with hi
e will always have one claim of my affection , which no other can possibly shar
f the evening declared at once his affection and happiness . " Shall we see you
ause he took leave of us with less affection than his usual behaviour has shewn
ness ." " I want no proof of their affection ," said Elinor ; " but of their en
onths , without telling her of his affection ;-- that they should part without
ould be the natural result of your affection for her . She used to be all unres
distinguished Elinor by no mark of affection . Marianne saw and listened with i
th no inclination for expense , no affection for strangers , no profession , an
till distinguished her by the same affection which once she had felt no doubt o
al of her confidence in Edward ' s affection , to the remembrance of every mark
was made ? Had he never owned his affection to yourself ?" " Oh , no ; but if
text3.concordance("lived") #搜索《创世纪》找出某人活了多久
Displaying 25 of 38 matches:
ay when they were created . And Adam lived an hundred and thirty years , and be
ughters : And all the days that Adam lived were nine hundred and thirty yea and
nd thirty yea and he died . And Seth lived an hundred and five years , and bega
ve years , and begat Enos : And Seth lived after he begat Enos eight hundred an
welve years : and he died . And Enos lived ninety years , and begat Cainan : An
years , and begat Cainan : And Enos lived after he begat Cainan eight hundred
ive years : and he died . And Cainan lived seventy years and begat Mahalaleel :
rs and begat Mahalaleel : And Cainan lived after he begat Mahalaleel eight hund
years : and he died . And Mahalaleel lived sixty and five years , and begat Jar
s , and begat Jared : And Mahalaleel lived after he begat Jared eight hundred a
and five yea and he died . And Jared lived an hundred sixty and two years , and
o years , and he begat Eno And Jared lived after he begat Enoch eight hundred y
and two yea and he died . And Enoch lived sixty and five years , and begat Met
; for God took him . And Methuselah lived an hundred eighty and seven years ,
, and begat Lamech . And Methuselah lived after he begat Lamech seven hundred
nd nine yea and he died . And Lamech lived an hundred eighty and two years , an
ch the LORD hath cursed . And Lamech lived after he begat Noah five hundred nin
naan shall be his servant . And Noah lived after the flood three hundred and fi
xad two years after the flo And Shem lived after he begat Arphaxad five hundred
at sons and daughters . And Arphaxad lived five and thirty years , and begat Sa
ars , and begat Salah : And Arphaxad lived after he begat Salah four hundred an
begat sons and daughters . And Salah lived thirty years , and begat Eber : And
y years , and begat Eber : And Salah lived after he begat Eber four hundred and
begat sons and daughters . And Eber lived four and thirty years , and begat Pe
y years , and begat Peleg : And Eber lived after he begat Peleg four hundred an
text4.concordance("nation") #text4,《就职演说语料》,回到1789 年看看那时英语的例子,搜索如nation, terror,god 这样的词,看看随着时间推移这些词的使用如何不同;
Displaying 25 of 302 matches:
to the character of an independent nation seems to have been distinguished by
f Heaven can never be expected on a nation that disregards the eternal rules o
first , the representatives of this nation , then consisting of little more th
, situation , and relations of this nation and country than any which had ever
, prosperity , and happiness of the nation I have acquired an habitual attachm
an be no spectacle presented by any nation more pleasing , more noble , majest
party for its own ends , not of the nation for the national good . If that sol
tures and the people throughout the nation . On this subject it might become m
if a personal esteem for the French nation , formed in a residence of seven ye
f our fellow - citizens by whatever nation , and if success can not be obtaine
y , continue His blessing upon this nation and its Government and give it all
powers so justly inspire . A rising nation , spread over a wide and fruitful l
ing now decided by the voice of the nation , announced according to the rules
ars witness to the fact that a just nation is trusted on its word when recours
e union of opinion which gives to a nation the blessing of harmony and the ben
uil suffrage of a free and virtuous nation , would under any circumstances hav
d spirit and united councils of the nation will be safeguards to its honor and
iction that the war with a powerful nation , which forms so prominent a featur
out breaking down the spirit of the nation , destroying all confidence in itse
ed on the military resources of the nation . These resources are amply suffici
the war to an honorable issue . Our nation is in number more than half that of
ndividually have been happy and the nation prosperous . Under this Constitutio
rights , and is able to protect the nation against injustice from foreign powe
great agricultural interest of the nation prospers under its protection . Loc
ak our Union , and demolish us as a nation . Our distance from Europe and the
text5.concordance("im")#《NPS 聊天语料库》,你可以在里面搜索一些网络词,如im, ur,lol。
Displaying 25 of 149 matches:
now im left with this gay name :P PART hey e
what did you but on e-bay i feel like im in the wrong room yeee haw U30 im con
ike im in the wrong room yeee haw U30 im considering changing my nickname to "
the hell outta my freaking PM box .. Im with my fiance !!!!!!!!!!!!!!!! answe
m impressed . PART hiya room lmao !!! im doin alright thanks omg Finger .. Dee
th lol JOIN so read it . thanks U7 .. Im happy to have my fiance here !! forwa
i didnt me phone you . . . sheesh now im that phone perv guy lets hope not U12
to spain ? i need to go this summer . im a HUGE phone perv ok seriously who wa
an ... . ACTION video tapes . hey U20 Im blind now . ACTION has left the room
T u got that right , i dont do shit , im the supervisor Hello U165 . hey U165
him in the " untouchable " list U115 im good U6 lmao U7 how r u U128 hehe how
can I ask where ya all are from ..... im here in kentucky as I said ... too wi
ic but had to resize and stuff U37 no im an equal oppertunity hater LOL Hi , U
he cover weeeeeeeee thanks U19 ! PART im out in cal now U3 looking at some new
:) hi U58 lol wb U29 hi U29 U13 .... im down to time now PART Hello U24 , wel
, I 'd never kick you outta my box hi im good thanks U16 yerself ?? PART inter
ke wth . . who are you even ty U34 yw Im glad he 's back . awwww U16 i like ps
ha U23 !!! wow ... are you the U39 ? Im talkin about all yer typin . . It 's
... you ??? Apparently , I 'm not U41 im good U23 dear . How are you U23 ~wink
~ U35 ... I love that 5 am phone call im good ... me and eric r back together
, I am happy . You know i LuverZ YOU im the same busy busy oh ok then U1 nm l
))) . ACTION stretches . ty U19 Ugh , Im so sore ! Repeatedly , with a big sti
'm a size queen U41 Why U45 ? naw U23 im cheating on you with Jayse hes hawt t
oeer is sum1 gonna ghet fuked up ? :) im always hungry yeah U45 .. i believe i
without first asking permission . U35 im sorry U35 i tried to refrain me too U
词语索引使我们看到词的上下文。
- 看到monstrous 出现的上下文,如the___ pictures 和the ___ size。还有哪些词出现在相似的上下文中?通过函数similar,来查找到这些上下文相似的词
text1.similar("monstrous")
reliable curious imperial gamesome vexatious pitiable impalpable
maddens delightfully tyrannical exasperate subtly passing loving
candid perilous mystifying lamentable lazy doleful
text2.similar("monstrous")
very so exceedingly heartily sweet great extremely good amazingly vast
a remarkably as
观察我们从不同的文本中得到的不同结果。Austen(奥斯丁,英国女小说家)使用这些词与Melville 完全不同;在她那里,monstrous 是正面的意思,有时它的功能像词very 一样作强调成分。
- 函数common_contexts允许我们研究两个或两个以上的词共同的上下文
text2.common_contexts(["monstrous", "very"])
be_glad a_pretty am_glad a_lucky is_pretty
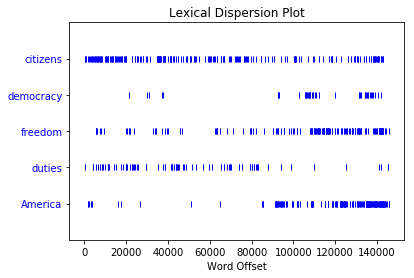
- 判断词在文本中的位置:从文本开头算起在它前面有多少词。这个位置信息可以用离散图表示,每一个竖线代表一个单词,每一行代表整个文本。
text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"])
- 函数generate,不同风格产生一些随机文本。
text3.generate("freedom")
计数词汇
- 标识符
词和标点符号或者叫标识符(tokens),一个标识符是表示一个我们想要放在一组对待的字符序列——如:hairy、his
len(text3) #《创世纪》
44764
- 类型
print(sorted(set(text3))) #set(text3)获得text3 的词汇表
['!', "'", '(', ')', ',', ',)', '.', '.)', ':', ';', ';)', '?', '?)', 'A', 'Abel', 'Abelmizraim', 'Abidah', 'Abide', 'Abimael', 'Abimelech', 'Abr', 'Abrah', 'Abraham', 'Abram', 'Accad', 'Achbor', ... 'yielded', 'yielding', 'yoke', 'yonder', 'you', 'young', 'younge', 'younger', 'youngest', 'your', 'yourselves', 'youth']
len(set(text3))
2789
不同的词汇或词类型。一个词类型是指一个词在一个文本中独一无二的出现形式或拼写。也就是说,这个词在词汇表中是唯一的。我们计数的2,789 个项目中包括标点符号,所以我们把这些叫做唯一项目类型而不是词类型。
- 词汇多样性
len(text3)/len(set(text3)) #文本词汇丰富度进行测量,每个字平均被使用了16 次
16.050197203298673
text3.count("smote") #计数一个词在文本中出现的次数
5
100*text4.count("a")/len(text4) #计算一个特定的词在文本中占据的百分比
1.4643016433938312
- 函数
使用关键字def 给函数定义一个简短的名字
def lexical_diversity(text): #指定了一个text 参数。这个参数是我们想要计算词汇多样性的实际文本的一个“占位符”
return len(text) / len(set(text))
def percentage(count,total): #定义了两个参数:count 和total
return 100 * count / total
调用一个如lexical_diversity()这样的函数,任务名——如:lexical_diversity()——与任务将要处理的数据——如:text3。调用函数时放在参数位置的数据值叫做函数的实参。
lexical_diversity(text3) #调用lexical_diversity()这样的函数
16.050197203298673
lexical_diversity(text5)
7.420046158918563
percentage(4,5)
80.0
percentage(text4.count("a"),len(text4))
1.4643016433938312
1.2 近观Python:将文本当做词链表
链表(list,也叫列表)
sent1 = ['Call','me','Ishmeal','.'] #文本不外乎是词和标点符号的序列。
sent1
['Call', 'me', 'Ishmeal', '.']
len(sent1)
4
每个文本开始的句子定义为sent2…sent9
print(sent2) #如果错误说:sent2 没有定义,需要先输入from nltk.book import *)
['The', 'family', 'of', 'Dashwood', 'had', 'long', 'been', 'settled', 'in', 'Sussex', '.']
print(sent3)
['In', 'the', 'beginning', 'God', 'created', 'the', 'heaven', 'and', 'the', 'earth', '.']
ex1 = ['Monty', 'Python', 'and', 'the', 'Holy', 'Grail']
sorted(ex1)
['Grail', 'Holy', 'Monty', 'Python', 'and', 'the']
len(set(ex1))
6
ex1.count('the')
1
['Monty', 'Python'] + ['and', 'the', 'Holy', 'Grail'] #链表加法运算
['Monty', 'Python', 'and', 'the', 'Holy', 'Grail']
print(sent4 + sent1) #加法的特殊用途叫做连接;它将多个链表组合为一个链表。
['Fellow', '-', 'Citizens', 'of', 'the', 'Senate', 'and', 'of', 'the', 'House', 'of', 'Representatives', ':', 'Call', 'me', 'Ishmeal', '.']
sent1.append("Some") #追加,向链表中增加一个元素
sent1
['Call', 'me', 'Ishmeal', '.', 'Some']
索引列表
- 索引
表示词在文本中位置,这个位置的数字叫做这个元素的索引
text4[173] #第173个位置词
'awaken'
text4.index('awaken') #反过来做;找出一个词第一次出现的索引。
173
sent = ['word1', 'word2', 'word3', 'word4', 'word5',
... 'word6', 'word7', 'word8', 'word9', 'word10']
sent[0]
'word1'
sent[9]
'word10'
sent[10]
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
in ()
----> 1 sent[10]
IndexError: list index out of range
注意,索引从零开始:第0 个元素写作sent[0],其实是第1 个词“word1”;而句子的第9 个元素是“word10”。
- 切片
子链表,从大文本中任意抽取语言片段,术语叫做切片。
print(text5[16715:16735])
['U86', 'thats', 'why', 'something', 'like', 'gamefly', 'is', 'so', 'good', 'because', 'you', 'can', 'actually', 'play', 'a', 'full', 'game', 'without', 'buying', 'it']
print(text6[1600:1625])
['We', "'", 're', 'an', 'anarcho', '-', 'syndicalist', 'commune', '.', 'We', 'take', 'it', 'in', 'turns', 'to', 'act', 'as', 'a', 'sort', 'of', 'executive', 'officer', 'for', 'the', 'week']
print(sent[5:8])
['word6', 'word7', 'word8']
按照惯例,m:n 表示元素m…n-1。
sent[:3]
['word1', 'word2', 'word3']
sent[8:]
['word9', 'word10']
- 修改链表中的元素
sent[0] = 'First'
sent[9] = 'Last'
len(sent)
10
sent[1:9] = ['Second', 'Third']
sent
['First', 'Second', 'Third', 'Last']
sent[9]
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
in ()
----> 1 sent[9]
IndexError: list index out of range
变量
变量必须以字母开头,可以包含数字和下划线。变量名不能是Python 的保留字,如def,if ,not 和import。名称是大小写敏感的。这意味着myVar 和myvar 是不同的变量。
- 赋值
my_sent = ['Bravely', 'bold', 'Sir', 'Robin', ',', 'rode',
... 'forth', 'from', 'Camelot', '.']
使用…提示符表示期望更多的输入,在这些连续的行中有多少缩进都没有关系,只是加入缩进通常会便于阅读。
noun_phrase = my_sent[1:4]
noun_phrase
['bold', 'Sir', 'Robin']
wOrDs = sorted(noun_phrase) #排序表中大写字母出现在小写字母之前
wOrDs
['Robin', 'Sir', 'bold']
not = 'Camelot' #使用了保留字,会产生一个语法错误
File "", line 1
not = 'Camelot' #使用了保留字,会产生一个语法错误
^
SyntaxError: invalid syntax
使用变量来保存计算的中间步骤,尤其是当这样做使代码更容易读懂时
vocab = set(text1)
vocab_size = len(vocab)
vocab_size
19317
字符串
访问链表元素的一些方法也可以用在单独的词或字符串
name = 'Monty'
name[0] #索引一个字符串
'M'
name[:4] #切片一个字符串
'Mont'
name * 2 #对字符串执行乘法
'MontyMonty'
name + '!' #对字符串执行加法
'Monty!'
''.join(['Monty','Python']) #把词用链表连接起来组成单个字符串
'MontyPython'
'Monty Python'.split() #把字符串分割成一个链表
['Monty', 'Python']
1.3 计算语言:简单的统计
saying = ['After', 'all', 'is', 'said', 'and', 'done',
... 'more', 'is', 'said', 'than', 'done']
tokens = set(saying)
tokens = sorted(tokens)
tokens[-2:]
['said', 'than']
频率分布
如何能自动识别文本中最能体现文本的主题和风格的词汇?频率分布,它告诉我们在文本中的每一个词项的频率。
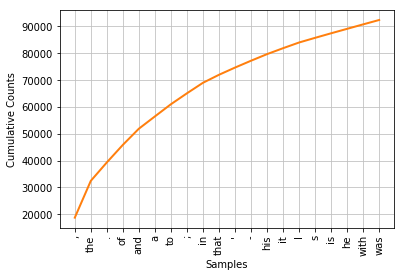
- FreqDist 寻找《白鲸记》中最常见的20 个词。
fdist1 = FreqDist(text1)
print(fdist1)
print(fdist1.most_common(20))
[(',', 18713), ('the', 13721), ('.', 6862), ('of', 6536), ('and', 6024), ('a', 4569), ('to', 4542), (';', 4072), ('in', 3916), ('that', 2982), ("'", 2684), ('-', 2552), ('his', 2459), ('it', 2209), ('I', 2124), ('s', 1739), ('is', 1695), ('he', 1661), ('with', 1659), ('was', 1632)]
fdist1['whale']
906
fdist1.plot(20, cumulative=True) #高频词
len(fdist1.hapaxes()) #低频词 ,只出现了一次的词
9002
细粒度的选择词
- 长词
a. {w | w ∈ V & P(w)}
b. [w for w in V if p(w)]
定义长词性质为P,则P(w)为真当且仅当词w 的长度大余XX个字符。此集合中所有w 都满足w 是集合V(词汇表)的一个元素且w 有性质P。
V = set(text1)
long_words = [w for w in V if len(w) > 15] #文本词汇表长度中超过15 个字符的词
print(sorted(long_words))
['CIRCUMNAVIGATION', 'Physiognomically', 'apprehensiveness', 'cannibalistically', 'characteristically', 'circumnavigating', 'circumnavigation', 'circumnavigations', 'comprehensiveness', 'hermaphroditical', 'indiscriminately', 'indispensableness', 'irresistibleness', 'physiognomically', 'preternaturalness', 'responsibilities', 'simultaneousness', 'subterraneousness', 'supernaturalness', 'superstitiousness', 'uncomfortableness', 'uncompromisedness', 'undiscriminating', 'uninterpenetratingly']
- 短高频词(如the)和长低频词(如antiphilosophists)
fdist5 = FreqDist(text5)
print(sorted(w for w in set(text5) if len(w) > 7 and fdist5[w] > 7)) #聊天语料库中所有长度超过7 个字符出现次数超过7 次的词:
['#14-19teens', '#talkcity_adults', '((((((((((', '........', 'Question', 'actually', 'anything', 'computer', 'cute.-ass', 'everyone', 'football', 'innocent', 'listening', 'remember', 'seriously', 'something', 'together', 'tomorrow', 'watching']
至此,我们已成功地自动识别出与文本内容相关的高频词。
词语搭配和双连词(bigrams)
- 搭配
一个搭配的特点是其中的词不能被类似的词置换。red wine 是一个搭配而the wine 不是,maroon wine(粟色酒)听起来就很奇怪。 - 双连词
搭配基本上就是频繁的双连词
list(bigrams(['more', 'is', 'said', 'than', 'done']))
[('more', 'is'), ('is', 'said'), ('said', 'than'), ('than', 'done')]
text4.collocations() #基于单个词的频率预期得到的更频繁出现的双连词
United States; fellow citizens; four years; years ago; Federal
Government; General Government; American people; Vice President; Old
World; Almighty God; Fellow citizens; Chief Magistrate; Chief Justice;
God bless; every citizen; Indian tribes; public debt; one another;
foreign nations; political parties
text8.collocations()
would like; medium build; social drinker; quiet nights; non smoker;
long term; age open; Would like; easy going; financially secure; fun
times; similar interests; Age open; weekends away; poss rship; well
presented; never married; single mum; permanent relationship; slim
build
计数其他东西
text1_w_len = [len(w) for w in text1]
text1_w_len[:10]
[1, 4, 4, 2, 6, 8, 4, 1, 9, 1]
fdist = FreqDist([len(w) for w in text1])
list(fdist)
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20]
fdist.items()
dict_items([(1, 47933), (2, 38513), (3, 50223), (4, 42345), (5, 26597), (6, 17111), (7, 14399), (8, 9966), (9, 6428), (10, 3528), (11, 1873), (12, 1053), (13, 567), (14, 177), (15, 70), (16, 22), (17, 12), (18, 1), (20, 1)])
fdist.max()
3
fdist[3]
50223
fdist.freq(3)
0.19255882431878046
表1-2. NLTK 频率分布类中定义的函数
| 例子 | 描述 |
|---|---|
| fdist = FreqDist(samples) | 创建包含给定样本的频率分布 |
| fdist[sample] += 1 | 增加样本 |
| fdist[‘monstrous’] | 计数给定样本出现的次数 |
| fdist.freq(‘monstrous’) | 给定样本的频率 |
| fdist.N() | 样本总数 |
| fdist.most_common(n) | 以频率递减顺序排序的样本链表 |
| for sample in fdist: | 以频率递减的顺序遍历样本 |
| fdist.max() | 数值最大的样本 |
| fdist.tabulate() | 绘制频率分布表 |
| fdist.plot() | 绘制频率分布图 |
| fdist.plot(cumulative=True) | 绘制累积频率分布图 |
| fdist1 = | fdist2 update fdist1 with counts from fdist2 |
| fdist1 < | fdist2 测试样本在fdist1 中出现的频率是否小于fdist2 |
1.4 回到Python决策与控制
条件
- 关系运算符
表1-3. 数值比较运算符
| 运算符 | 关系 |
|---|---|
| < | 小于 |
| <= | 小于等于 |
| == | 等于(注意是两个“=”号而不是一个) |
| != | 不等于 |
| > | 大于 |
| >= | 大于等于 |
print(sent7)
['Pierre', 'Vinken', ',', '61', 'years', 'old', ',', 'will', 'join', 'the', 'board', 'as', 'a', 'nonexecutive', 'director', 'Nov.', '29', '.']
[w for w in sent7 if len(w) < 4]
[',', '61', 'old', ',', 'the', 'as', 'a', '29', '.']
[w for w in sent7 if len(w)<=4]
[',', '61', 'old', ',', 'will', 'join', 'the', 'as', 'a', 'Nov.', '29', '.']
[w for w in sent7 if len(w)==4]
['will', 'join', 'Nov.']
[w for w in sent7 if len(w)!=4]
['Pierre',
'Vinken',
',',
'61',
'years',
'old',
',',
'the',
'board',
'as',
'a',
'nonexecutive',
'director',
'29',
'.']
表1-4. 一些词比较运算符
| 函数 | 含义 |
|---|---|
| s.startswith(t) | 测试s 是否以t 开头 |
| s.endswith(t) | 测试s 是否以t 结尾 |
| t in s | 测试s 是否包含t |
| s.islower() | 测试s 中所有字符是否都是小写字母 |
| s.isupper() | 测试s 中所有字符是否都是大写字母 |
| s.isalpha() | 测试s 中所有字符是否都是字母 |
| s.isalnum() | 测试s 中所有字符是否都是字母或数字 |
| s.isdigit() | 测试s 中所有字符是否都是数字 |
| s.istitle() | 测试s 是否首字母大写(s 中所有的词都首字母大写) |
sorted(w for w in set(text1) if w.endswith('ableness')) #以-ableness 结尾的词
['comfortableness',
'honourableness',
'immutableness',
'indispensableness',
'indomitableness',
'intolerableness',
'palpableness',
'reasonableness',
'uncomfortableness']
sorted([term for term in set(text4) if 'gnt' in term]) #包含gnt 的词
['Sovereignty', 'sovereignties', 'sovereignty']
sorted([item for item in set(text6) if item.istitle()]) #首字母大写的词
['A',
'Aaaaaaaaah',
'Aaaaaaaah',
'Aaaaaah',
'Aaaah',....
sorted([item for item in set(sent7) if item.isdigit()]) #完全由数字组成的词
['29', '61']
sorted(w for w in set(text7) if '-' in w and 'index' in w)
['Stock-index',
'index-arbitrage',
'index-fund',
'index-options',
'index-related',
'stock-index']
sorted(wd for wd in set(text3) if wd.istitle() and len(wd) > 10)
['Abelmizraim',
'Allonbachuth',
'Beerlahairoi',
'Canaanitish',
'Chedorlaomer',
'Girgashites',
'Hazarmaveth',
'Hazezontamar',
'Ishmeelites',
'Jegarsahadutha',
'Jehovahjireh',
'Kirjatharba',
'Melchizedek',
'Mesopotamia',
'Peradventure',
'Philistines',
'Zaphnathpaaneah']
sorted(w for w in set(sent7) if not w.islower())
[',', '.', '29', '61', 'Nov.', 'Pierre', 'Vinken']
sorted(t for t in set(text2) if 'cie' in t or 'cei' in t)
['ancient',
'ceiling',
'conceit',
'conceited',
'conceive',
'conscience',
'conscientious',
'conscientiously',
'deceitful',
'deceive',
'deceived',
'deceiving',
'deficiencies',
'deficiency',
'deficient',
'delicacies',
'excellencies',
'fancied',
'insufficiency',
'insufficient',
'legacies',
'perceive',
'perceived',
'perceiving',
'prescience',
'prophecies',
'receipt',
'receive',
'received',
'receiving',
'society',
'species',
'sufficient',
'sufficiently',
'undeceive',
'undeceiving']
对每个元素进行操作
[len(w) for w in text1] #形式为[f(w) for ...]或[w.f() for ...],其中f 是一个函数
[1,4, 4,2,...,
[w.upper() for w in text1]
['[','MOBY','DICK', 'BY',.......]
len(text1)
260819
len(set(text1))
19317
len(set([word.lower() for word in text1])) #不重复计算像This 和this 这样仅仅大小写不同的词
17231
len(set([word.lower() for word in text1 if word.isalpha()])) #通过过滤掉所有非字母元素,从词汇表中消除数字和标点符号
16948
嵌套代码块
- if 语句
word = 'cat'
if len(word) < 5: #if 语句叫做一个控制结构
print("word length is less than 5")
#使用Python 解释器时,我们必须添加一个额外的空白行?,这样它才能检测到嵌套块结束。
word length is less than 5
- for 循环
for word in ['Call', 'me', 'Ishmael', '.']:
print(word)
Call
me
Ishmael
.
条件循环
sent1 = ['Call', 'me', 'Ishmael', '.']
for xyzzy in sent1: #冒号表示当前语句与后面的缩进块有关联
if xyzzy.endswith('l'):
print(xyzzy)
Call
Ishmael
for token in sent1:
if token.islower():
print(token, 'is a lowercase word')
elif token.istitle():
print(token, 'is a titlecase word')
else:
print(token, 'is punctuation')
Call is a titlecase word
me is a lowercase word
Ishmael is a titlecase word
. is punctuation
tricky = sorted([w for w in set(text2) if 'cie' in w or 'cei' in w])
for word in tricky:
print(word,end=' ') #同一行输出
ancient ceiling conceit conceited conceive conscience conscientious conscientiously deceitful deceive deceived deceiving deficiencies deficiency deficient delicacies excellencies fancied insufficiency insufficient legacies perceive perceived perceiving prescience prophecies receipt receive received receiving society species sufficient sufficiently undeceive undeceiving
1.5 自动理解自然语言
词意消歧
指代消解
自动生成语言
机器翻译
人机对话系统
文本的含义
文本含义识别(Recognizing Textual Entailment 简称RTE)
NLP 的局限性
尽管NLP在很多如RTE这样的任务中研究取得了进展,但在现实世界的应用中已经部署的语言理解系统仍不能进行常识推理或以一种一般的可靠的方式描绘这个世界的知识。我们在等待这些困难的人工智能问题得到解决的同时,接受一些在推理和知识能力上存在严重限制的自然语言系统是有必要的。因此,从一开始,自然语言处理研究的一个重要目标一直是使用浅显但强大的技术代替无边无际的知识和推理能力,促进构建“语言理解”技术的艰巨任务的不断取得进展。
1.6 小结
- 在Python 中文本用链表来表示:[‘Monty’, ‘Python’]。我们可以使用索引、分片和len()函数对链表进行操作。
- 词“token”(标识符)是指文本中给定词的特定出现;词“type”(类型)则是指词作为一个特定序列字母的唯一形式。我们使用len(text)计数词的标识符,使用len(set(text))计数词的类型。
- 我们使用sorted(set(t))获得文本t 的词汇表。
- 我们使用[f(x) for x in text]对文本的每一项目进行操作。
- 为了获得没有大小写区分和忽略标点符号的词汇表,我们可以使用set([w.lower() for w in text if w.isalpha()])。
- 我们使用for 语句对文本中的每个词进行处理,例如for w in t:或者for word in text:。后面必须跟冒号和一块在每次循环被执行的缩进的代码。
- 我们使用if 语句测试一个条件:if len(word)<5:。后面必须跟冒号和一块仅当条件为真时执行的缩进的代码。
- 频率分布是项目连同它们的频率计数的集合(例如:一个文本中的词与它们出现的频率)。
- 函数是指定了名字并且可以重用的代码块。函数通过def 关键字定义,例如在def mult(x, y)中x 和y 是函数的参数,起到实际数据值的占位符的作用。
- 函数是通过指定它的名字及一个或多个放在括号里的实参来调用,就像这样:mult(3,4)或者len(text1)。
致谢
《Python自然语言处理》123 4,作者:Steven Bird, Ewan Klein & Edward Loper,是实践性很强的一部入门读物,2009年第一版,2015年第二版,本学习笔记结合上述版本,对部分内容进行了延伸学习、练习,在此分享,期待对大家有所帮助,欢迎加我微信(验证:NLP),一起学习讨论,不足之处,欢迎指正。

参考文献
http://nltk.org/ ↩︎
Steven Bird, Ewan Klein & Edward Loper,Natural Language Processing with Python,2009 ↩︎
(英)伯德,(英)克莱因,(美)洛普,《Python自然语言处理》,2010年,东南大学出版社 ↩︎
Steven Bird, Ewan Klein & Edward Loper,Natural Language Processing with Python,2015 ↩︎