基于0.10.1版本
整体流程
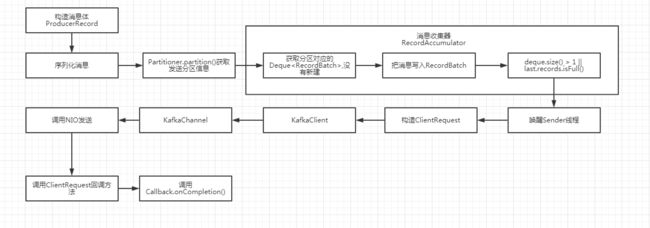
发送消息流程.png
Producer.send()入口
private Future doSend(ProducerRecord record, Callback callback) {
TopicPartition tp = null;
try {
// 获取集群信息
ClusterAndWaitTime clusterAndWaitTime = waitOnMetadata(record.topic(), record.partition(), maxBlockTimeMs);
long remainingWaitMs = Math.max(0, maxBlockTimeMs - clusterAndWaitTime.waitedOnMetadataMs);
Cluster cluster = clusterAndWaitTime.cluster;
//省略序列化serializedKey,serializedValue
//获取分区
int partition = partition(record, serializedKey, serializedValue, cluster);
int serializedSize = Records.LOG_OVERHEAD + Record.recordSize(serializedKey, serializedValue);
//校验消息体大小
ensureValidRecordSize(serializedSize);
tp = new TopicPartition(record.topic(), partition);
long timestamp = record.timestamp() == null ? time.milliseconds() : record.timestamp();
log.trace("Sending record {} with callback {} to topic {} partition {}", record, callback, record.topic(), partition);
// producer callback will make sure to call both 'callback' and interceptor callback
Callback interceptCallback = this.interceptors == null ? callback : new InterceptorCallback<>(callback, this.interceptors, tp);
//把消息写入消息收集器
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
//如果最后一个RecordBatch已经写满,或者Deque队列大小>1就唤醒发送线程
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;
// handling exceptions and record the errors;
// for API exceptions return them in the future,
// for other exceptions throw directly
}
doSend.png
RecordAccumulator.append方法利用了分段锁,当并发出现时,前一个线程需要的内存空间比较大,不满足写入,后一个线程需要的内存空间比较小,满足写入。提高了并发,此处也可以看出,如果消息需要有发送顺序的保证,一个Producer实例不要在多处调用。
public RecordAppendResult append(TopicPartition tp,
long timestamp,
byte[] key,
byte[] value,
Callback callback,
long maxTimeToBlock) throws InterruptedException {
appendsInProgress.incrementAndGet();
try {
//从ConcurrentMap>中换取分区对应的Deque队列
Deque dq = getOrCreateDeque(tp);
synchronized (dq) {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
if (appendResult != null)
return appendResult;
}
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
//再次尝试写入
RecordAppendResult appendResult = tryAppend(timestamp, key, value, callback, dq);
//如果写入成功,说明别的线程new了一个新的RecordBatch
if (appendResult != null) {
// 释放之前申请的buffer
free.deallocate(buffer);
return appendResult;
}
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(timestamp, key, value, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true);
}
} finally {
appendsInProgress.decrementAndGet();
}
}
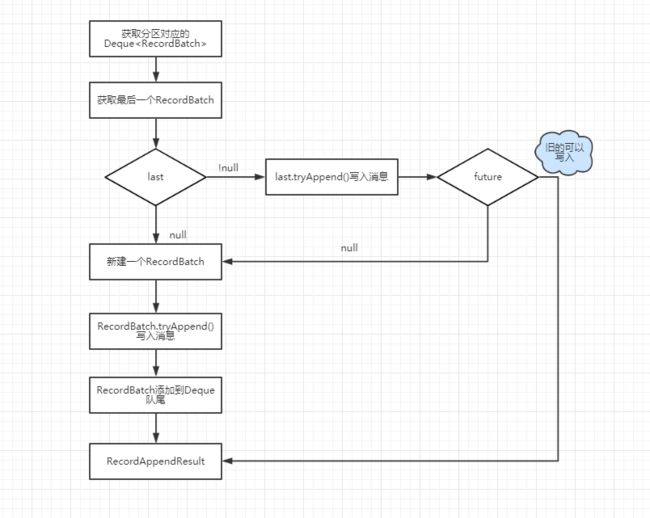
消息写入收集器流程.png
RecordAccumulator.tryAppend方法,获取最后一个RecordBatch尝试写入
private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Callback callback, Deque deque) {
RecordBatch last = deque.peekLast();
if (last != null) {
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, callback, time.milliseconds());
//写入失败,需要把MemoryRecords置为不可写状态,buffer.flip()切换到读
if (future == null)
last.records.close();
else
//判断是否可以唤醒Sender发送线程,deque.size() > 1 || last.records.isFull()
return new RecordAppendResult(future, deque.size() > 1 || last.records.isFull(), false);
}
return null;
}
RecordBatch.tryAppend写入
public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Callback callback, long now) {
//判断是否需要新创建RecordBatch来存储消息
if (!this.records.hasRoomFor(key, value)) {
return null;
} else {
long checksum = this.records.append(offsetCounter++, timestamp, key, value);
this.maxRecordSize = Math.max(this.maxRecordSize, Record.recordSize(key, value));
this.lastAppendTime = now;
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture, this.recordCount,
timestamp, checksum,
key == null ? -1 : key.length,
value == null ? -1 : value.length);
//如果需要回调把回调加入thunks
if (callback != null)
thunks.add(new Thunk(callback, future));
this.recordCount++;
return future;
}
}
判断是否需要new RecordBatch
public boolean hasRoomFor(byte[] key, byte[] value) {
//当前不是写模式,说明消息已经写满,正在发送,或者在发送中
if (!this.writable)
return false;
/**
* MemoryRecords是否写入过消息?
* 没写过,申请Buffer初始化内存大小是否>=消息体大小
* 写入过,batch.size是否>=已写入的内存大小+消息体大小
* 考虑这两种情况是因为如果曾经写入了消息体大小大于batch.size,则该Buffer只会保存这一条消息,
* 从BufferPool获取的Buffer大小都是batch.size,此时initialCapacity=writeLimit
*
*/
return this.compressor.numRecordsWritten() == 0 ?
this.initialCapacity >= Records.LOG_OVERHEAD + Record.recordSize(key, value) :
this.writeLimit >= this.compressor.estimatedBytesWritten() + Records.LOG_OVERHEAD + Record.recordSize(key, value);
}
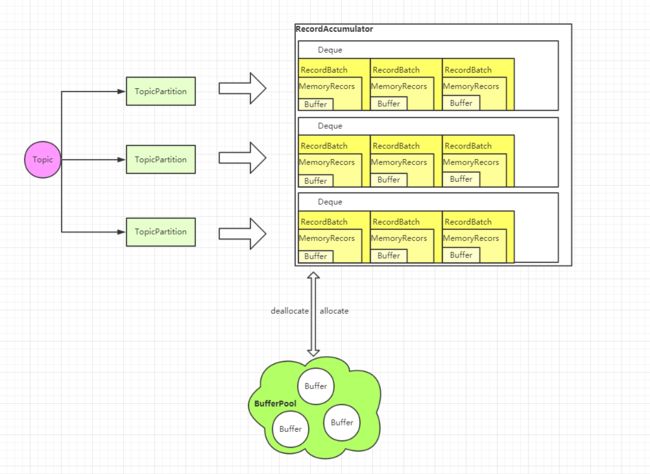
BufferPool源码解读
BufferPool是Buffer缓冲区,创建出来的Buffer大小都等于batch.size,如果控制每条消息都小于或者等于batch.size,充分利用了缓冲区,性能会更好。
BufferPool 类主要变量
public final class BufferPool {
/**
* BufferPool缓冲池最大的字节大小,也就是配置buffer.memory
*/
private final long totalMemory;
/**
* 每个Buffer固定大小,也就是配置batch.size
*/
private final int poolableSize;
private final ReentrantLock lock;
/**
* 空闲的buffer队列
*/
private final Deque free;
/**
* 等待分配Buffer的队列
*/
private final Deque waiters;
/**
* 可用的内存大小
*/
private long availableMemory;
private final Metrics metrics;
private final Time time;
private final Sensor waitTime;
}
通过下面的代码获取当前需要申请的Buffer内存空间大小
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
如果超过batch.size,通过ByteBuffer.allocate(size)来申请空间,不从BufferPool中获取。
BufferPool主要方法就是申请空间allocate,释放空间deallocate,具体流程如下
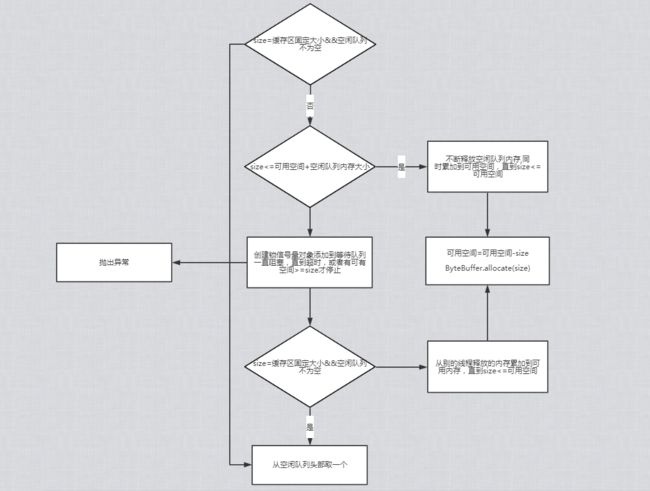
申请空间流程.png

释放空间流程.png
Sender 发送线程
每次往消息收集器写完消息,都会检验下,是否需要唤醒发送线程Sender
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, interceptCallback, remainingWaitMs);
//如果最后一个RecordBatch已经写满,或者Deque队列大小>1就唤醒发送线程
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
KafkaClient 分析
KafkaClient 关键字段
public class NetworkClient implements KafkaClient {
/* the selector used to perform network i/o */
//执行NIO的选择器
private final Selectable selector;
/* the state of each node's connection */
//每个连接Node的状态
private final ClusterConnectionStates connectionStates;
/* the set of requests currently being sent or awaiting a response */
//准备发送或者等待响应的消息
private final InFlightRequests inFlightRequests;
}
Sender 分析
Sender 关键字段
public class Sender implements Runnable {
/* the state of each nodes connection */
//每个连接的状态
private final KafkaClient client;
/* the record accumulator that batches records */
//消息收集器
private final RecordAccumulator accumulator;
/* the flag indicating whether the producer should guarantee the message order on the broker or not. */
//是否需要保证一个topic正在发送的RecordBatch只有一个,max.in.flight.requests.per.connection 设置为1时会保证
private final boolean guaranteeMessageOrder;
/* the maximum request size to attempt to send to the server */
private final int maxRequestSize;
/* the number of acknowledgements to request from the server */
private final short acks;
}
Sender是一个线程类,看看它的核心方法run
void run(long now) {
Cluster cluster = metadata.fetch();
// 获取满足发送条件的RecordBatch对应的nodes
RecordAccumulator.ReadyCheckResult result = this.accumulator.ready(cluster, now);
// 如果有任何一个leader node未知,则强制更新标示
if (!result.unknownLeaderTopics.isEmpty()) {
for (String topic : result.unknownLeaderTopics)
this.metadata.add(topic);
this.metadata.requestUpdate();
}
// 移除没有连接的Node的,并且初始化网络连接,等待下次再调用
Iterator iter = result.readyNodes.iterator();
long notReadyTimeout = Long.MAX_VALUE;
while (iter.hasNext()) {
Node node = iter.next();
if (!this.client.ready(node, now)) {
iter.remove();
notReadyTimeout = Math.min(notReadyTimeout, this.client.connectionDelay(node, now));
}
}
//把TopicPartition->List 转化为 NodeId(每个Broker节点Id)->List
Map> batches = this.accumulator.drain(cluster,
result.readyNodes,
this.maxRequestSize,
now);
//max.in.flight.requests.per.connection 设置为1时,保证一个topic只有一个RecordBatch在发送,保证有序性
if (guaranteeMessageOrder) {
// Mute all the partitions drained
for (List batchList : batches.values()) {
for (RecordBatch batch : batchList)
this.accumulator.mutePartition(batch.topicPartition);
}
}
//移除发送超时的RecordBatch,并执行RecordBatch对应的done,最后执行callback.onCompletion方法,可以根据自定义是否补发
List expiredBatches = this.accumulator.abortExpiredBatches(this.requestTimeout, now);
for (RecordBatch expiredBatch : expiredBatches)
this.sensors.recordErrors(expiredBatch.topicPartition.topic(), expiredBatch.recordCount);
sensors.updateProduceRequestMetrics(batches);
//把NodeId(每个Broker节点Id)->List转化为List
List requests = createProduceRequests(batches, now);
long pollTimeout = Math.min(result.nextReadyCheckDelayMs, notReadyTimeout);
if (result.readyNodes.size() > 0) {
log.trace("Nodes with data ready to send: {}", result.readyNodes);
log.trace("Created {} produce requests: {}", requests.size(), requests);
pollTimeout = 0;
}
//写入待发送的KafkaChannel中的Send
for (ClientRequest request : requests)
client.send(request, now);
this.client.poll(pollTimeout, now);
}
client.send(request, now)需要满足下面的条件,才能写入待发送的Send中
private boolean canSendRequest(String node) {
//该Node是否连接状态&&该Node是否已准备好发送&&是否可以发送更多
return connectionStates.isConnected(node) && selector.isChannelReady(node) && inFlightRequests.canSendMore(node);
}
//inFlightRequests.canSendMore
public boolean canSendMore(String node) {
Deque queue = requests.get(node);
return queue == null || queue.isEmpty() ||
(queue.peekFirst().request().completed() && queue.size() < this.maxInFlightRequestsPerConnection);
}
看看NetworkClient.poll方法
public List poll(long timeout, long now) {
long metadataTimeout = metadataUpdater.maybeUpdate(now);
try {
//真正操作NIO的地方
this.selector.poll(Utils.min(timeout, metadataTimeout, requestTimeoutMs));
} catch (IOException e) {
log.error("Unexpected error during I/O", e);
}
// process completed actions
long updatedNow = this.time.milliseconds();
List responses = new ArrayList<>();
//处理已发送的消息
handleCompletedSends(responses, updatedNow);
//处理已发送成功响应的消息
handleCompletedReceives(responses, updatedNow);
//处理已断开的连接,重新请求 meta
handleDisconnections(responses, updatedNow);
//处理新建立的连接,需要验证通过
handleConnections();
//处理超时请求
handleTimedOutRequests(responses, updatedNow);
// invoke callbacks
for (ClientResponse response : responses) {
if (response.request().hasCallback()) {
try {
//回调Callback的onComplete方法
response.request().callback().onComplete(response);
} catch (Exception e) {
log.error("Uncaught error in request completion:", e);
}
}
}
return responses;
}
来看看真正操作NIO的
public void poll(long timeout) throws IOException {
if (timeout < 0)
throw new IllegalArgumentException("timeout should be >= 0");
clear();
if (hasStagedReceives() || !immediatelyConnectedKeys.isEmpty())
timeout = 0;
/* check ready keys */
long startSelect = time.nanoseconds();
int readyKeys = select(timeout);
long endSelect = time.nanoseconds();
this.sensors.selectTime.record(endSelect - startSelect, time.milliseconds());
if (readyKeys > 0 || !immediatelyConnectedKeys.isEmpty()) {
//处理已经就绪的连接
pollSelectionKeys(this.nioSelector.selectedKeys(), false, endSelect);
//处理新建立的连接
pollSelectionKeys(immediatelyConnectedKeys, true, endSelect);
}
addToCompletedReceives();
long endIo = time.nanoseconds();
this.sensors.ioTime.record(endIo - endSelect, time.milliseconds());
// we use the time at the end of select to ensure that we don't close any connections that
// have just been processed in pollSelectionKeys
//关闭空闲的连接,根据配置的最大空闲时间connections.max.idle.ms判断
maybeCloseOldestConnection(endSelect);
}
private void pollSelectionKeys(Iterable selectionKeys,
boolean isImmediatelyConnected,
long currentTimeNanos) {
Iterator iterator = selectionKeys.iterator();
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
iterator.remove();
KafkaChannel channel = channel(key);
sensors.maybeRegisterConnectionMetrics(channel.id());
if (idleExpiryManager != null)
idleExpiryManager.update(channel.id(), currentTimeNanos);
try {
if (isImmediatelyConnected || key.isConnectable()) {
if (channel.finishConnect()) {
this.connected.add(channel.id());
this.sensors.connectionCreated.record();
SocketChannel socketChannel = (SocketChannel) key.channel();
log.debug("Created socket with SO_RCVBUF = {}, SO_SNDBUF = {}, SO_TIMEOUT = {} to node {}",
socketChannel.socket().getReceiveBufferSize(),
socketChannel.socket().getSendBufferSize(),
socketChannel.socket().getSoTimeout(),
channel.id());
} else
continue;
}
if (channel.isConnected() && !channel.ready())
channel.prepare();
//读取消息操作,一次读完所有可读buffer
if (channel.ready() && key.isReadable() && !hasStagedReceive(channel)) {
NetworkReceive networkReceive;
while ((networkReceive = channel.read()) != null)
addToStagedReceives(channel, networkReceive);
}
//写消息事件操作
if (channel.ready() && key.isWritable()) {
Send send = channel.write();
if (send != null) {
this.completedSends.add(send);
this.sensors.recordBytesSent(channel.id(), send.size());
}
}
//不是有效的事件操作
if (!key.isValid()) {
close(channel);
this.disconnected.add(channel.id());
}
} catch (Exception e) {
String desc = channel.socketDescription();
if (e instanceof IOException)
log.debug("Connection with {} disconnected", desc, e);
else
log.warn("Unexpected error from {}; closing connection", desc, e);
close(channel);
this.disconnected.add(channel.id());
}
}
}