本文基于jdk1.8
- 线程安全性
HashMap是线程不安全的,不适合在多线程内使用
HashTable线程安全,每个方法都加了锁
2.Key,Value值限制
HashMap,key可以为null,只能有一个,value可以为null
HashTable,key,value都不能为null
可以从HashTable的put方法看出来,value为null会直接抛出异常,而key为null,在调用key.hashCode()的时候也会抛出空指针异常,不知道为什么不提前手动去判断key为null,个人感觉HashTable唯一存在于jdk的理由是兼容历史代码,毕竟现在都不维护了,而且性能也没有ConcurrentHashMap好
public synchronized V put(K key, V value) {
// Make sure the value is not null
if (value == null) {
throw new NullPointerException();
}
// Makes sure the key is not already in the hashtable.
Entry tab[] = table;
int hash = key.hashCode();
......
......
return null;
}
3.实现的抽象类不同
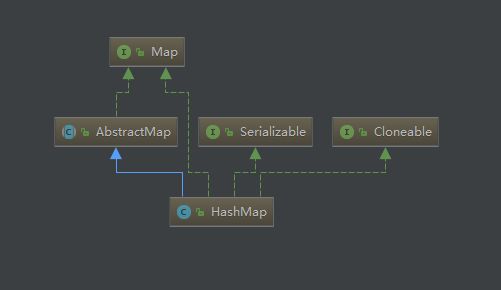
HashMap继承AbstractMap,AbstractMap里面封装了一些常用的map操作,并且开放抽象方法给子类实现
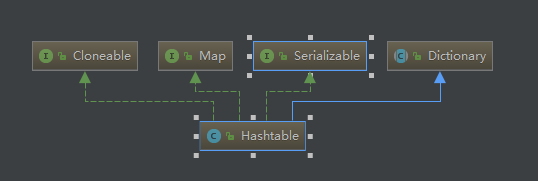
HashTable继承Dictionary,Dictionary里面只是约束了子类需要实现的方法,并且这些方法和Map接口重复,并且从类注释中看到,Dictionary是1.1出现的,而Map接口是1.2出现的,所以推断,Dictionary的残留,也是为了兼容老代码
4.哈希桶初始化时机不同
HashTable中哈希桶初始化放在构造函数里面
HashMap中哈希桶初始化在第一次put的时候触发,并且逻辑封装在resize()方法里面
Hashtable的构造函数
public Hashtable(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal Load: "+loadFactor);
if (initialCapacity==0)
initialCapacity = 1;
this.loadFactor = loadFactor;
table = new Entry[initialCapacity];
threshold = (int)Math.min(initialCapacity * loadFactor, MAX_ARRAY_SIZE + 1);
}
HashMap的构造函数
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
this.threshold = tableSizeFor(initialCapacity);
}
HashMap的putVal方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node[] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
......
......
}
可以看到在putVal方法中,如果table为空,会调用resize方法,resize逻辑以后再讲,在里面进行table初始化
5.哈希表的长度不同
HashMap的长度都是2的幂次方,最小为16
HashTable的默认长度为11,没有限定为2的幂次方
为什么HashMap的长度都为2的幂次方,这是为了方便扩容以及定位哈希桶序号
HashMap中定位哈希桶逻辑为
first = tab[(n - 1) & hash]) != null
n为哈希桶的长度,因为n是2的幂次方,所以可以用&去取余数
但是HashTable的长度不是2的幂次方,所以只能用一下方式
int index = (hash & 0x7FFFFFFF) % tab.length;
6.扩容方式不同
HashTable的扩容方式很简单,建一个双倍长度的哈希表,然后循环老的哈希表中的元素,依次计算其新哈希表中的位子,放入新的哈希表
而HashMap基于2的幂次方长度对扩容算法进行了优化,下面截取resize方法中扩容的算法
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode)e).split(this, newTab, j, oldCap);
else { // preserve order
Node loHead = null, loTail = null;
Node hiHead = null, hiTail = null;
Node next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
算法逻辑如下:
循环哈希表,如果哈希桶只有一个元素,直接计算他在新哈希表的位子并且放入,如果哈西桶是一个红黑树节点,调用红黑树的算法复制到新的哈希表,如果是链表,将链表拆分为2个链表,一个链表不需要换哈西桶的位子,另外一个链表需要换位子,分别将这2个链表放到新的哈希表中
最后这个拆分链表的算法很巧妙
if ((e.hash & oldCap) == 0)
因为是哈希表长度是2的幂次方,所以做扩容后,计算哈西桶位子时,由原来的hash值&2的n次方-1,改为hash值&2的n+1次方-1,那么我们判断链表中这个元素是否会调换位子的时候,只需要判断&n+1位是否为1,也就是用hash值&2的n次方来判断。
计算新位子的时候也方便了,新的位子就是老的位子加上2的n次方,也就是老哈希表的长度。
这个算法我也理解了很久,不太懂的朋友,可以自己计算推敲下,十分有趣
7.哈希桶内元素类型不同
HashTable桶内元素直接为Entry
HashMap针对这个又加了优化,如果链表长度超过8个时,会转换为红黑树节点,如果红黑树内节点少于6个时,再转换为链表
这个红黑树我要在单独研究下,代码真特么多