整个工程量其实不大,截止到现在 dpvs 代码量只有不到 2w 行,相当轻量级了,和当年 redis 开源时体量相当。
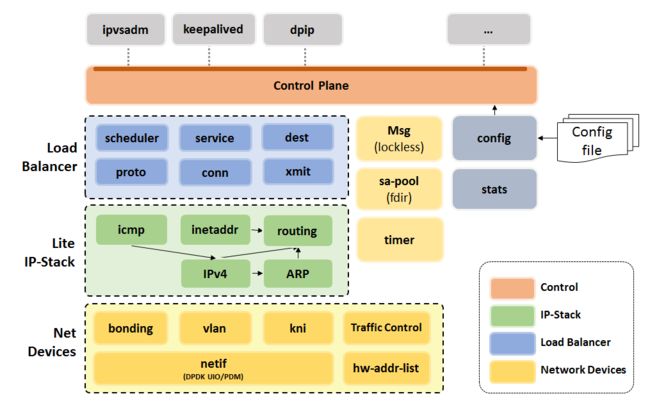
先看架构图,对外交互层 control plane 比较像
lvs,不会陌生。Load Balancer 模块根据
lvs 翻译而来,支持大家常用的几种转发模式。和
lvs 差别最大的地方就是,
dpvs 自己实现了轻量级的 tcp 协义栈,并且在用户层模拟了网卡,就是最下面的 Net Devices 层。为什么要自己实现设备层呢?
了解配置文件
先熟悉配置文件对了解整体框架很有帮助,查看源码库自带的配置文件 dpvs.conf.sample,包含几个模块:
- global_defs 全局配置模块:日志级别,路径等等
global_defs {
log_level WARNING
! log_file /var/log/dpvs.log
}
- netif_defs 网卡设备模块:
netif_defs {
pktpool_size 2097151
pktpool_cache 256
device dpdk0 {
rx {
queue_number 8
descriptor_number 1024
rss tcp
}
tx {
queue_number 8
descriptor_number 1024
}
! promisc_mode
kni_name dpdk0.kni
}
}
pktpool 是内存池相关的,代码里再细说。device 就是定义的网卡设备,由于 dpdk 程序会将网卡劫持,所以流量不会经过内核,如果其它程序,比如 ssh 想使用网卡,就需要额外配置 kni kernel nic interface 模块,dpdk 不感兴趣的流量会透传到内核。tx, rx 是网卡硬件队列个数配置,现代网卡标配。
- worker_defs 工作核心
worker_defs {
worker cpu0 {
type master
cpu_id 0
}
worker cpu1 {
type slave
cpu_id 1
port dpdk0 {
rx_queue_ids 0
tx_queue_ids 0
! isol_rx_cpu_ids 9
! isol_rxq_ring_sz 1048576
}
port dpdk1 {
rx_queue_ids 0
tx_queue_ids 0
! isol_rx_cpu_ids 9
! isol_rxq_ring_sz 1048576
}
}
}
dpdk 程序将 cpu 称为 lcore,即逻辑核。分为 master, slave 两种类型,一般 master 做管理相关的,slave cpu 是真正处理业务的核,每个 lcore 可以负责多个网卡的多个队列,dpdk 中将网卡叫做 port. rx_queue_ids 和 tx_queue_ids 分别是接收和发送队列号。其中 isol_rx_cpu_ids 表示当前 lcore 专职负责接收数据,isol_rxq_ring_sz 专职接收数据的 ring buffer 大小。
- timer_defs 定时器相关
timer_defs {
# cpu job loops to schedule dpdk timer management
schedule_interval 500
}
- neight_defs 邻居子系统
neigh_defs {
unres_queue_length 128
timeout 60
}
由于自己实现 tcp 协义,那邻居子系统和路由系统肯定也要实现,只不过比较精简专用
- ipv4_defs
ipv4_defs {
ipv4_forward off ! set this to on, dpvs will forward packets that NOT hit rules directly
default_ttl 64
fragment {
bucket_number 4096
bucket_entries 16
max_entries 4096
ttl 1
}
}
以后一定会有 ipv6_defs
- ctrl_defs 控制配置
ctrl_defs {
lcore_msg {
ring_size 4096
multicast_queue_length 256
sync_msg_timeout_us 2000
}
ipc_msg {
unix_domain /var/run/dpvs_ctrl
}
}
交互命令通过 unix socket
- ipvs_defs 核心配置
ipvs_defs {
conn {
conn_pool_size 2097152
conn_pool_cache 256
conn_init_timeout 3
}
udp {
defence_udp_drop
timeout {
normal 300
last 3
}
}
tcp {
defence_tcp_drop
timeout {
none 2
established 90
syn_sent 3
syn_recv 30
fin_wait 7
time_wait 7
close 3
close_wait 7
last_ack 7
listen 120
synack 30
last 2
}
synproxy {
synack_options {
mss 1452
ttl 63
sack
}
rs_syn_max_retry 3
ack_storm_thresh 10
max_ack_saved 3
conn_reuse_state {
close
time_wait
}
}
}
}
conn 连接相关的配置,udp, tcp 也好理解,其中 synproxy 是 syn flood 相关的,后文会重点分析。
程序初始化
代码比较简洁,main.c 即是入口,配置文件如何解析暂时忽略
// numa 个数,一般服务器都是2个,也就是 2个 cpu socket
if (get_numa_nodes() > DPVS_MAX_SOCKET) {
fprintf(stderr, "DPVS_MAX_SOCKET is smaller than system numa nodes!\n");
return -1;
}
获取 numa 节点个数,dpdk 程序的特点之一吧,为了高性能支持 numa
// 设置所有 cpu 关和性
if (set_all_thread_affinity() != 0) {
fprintf(stderr, "set_all_thread_affinity failed\n");
exit(EXIT_FAILURE);
}
设置亲和性,绑定所有 cpu
err = rte_eal_init(argc, argv);
if (err < 0)
rte_exit(EXIT_FAILURE, "Invalid EAL parameters\n");
argc -= err, argv += err;
初始化 dpdk runtime environment ,虚拟运行时抽像层,具体实现需要看 dpdk 库。
RTE_LOG(INFO, DPVS, "dpvs version: %s, build on %s\n", DPVS_VERSION, DPVS_BUILD_DATE);
rte_timer_subsystem_init();
rte 定时器子系统初始化
if ((err = cfgfile_init()) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "Fail init configuration file: %s\n",
dpvs_strerror(err));
if ((err = netif_virtual_devices_add()) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "Fail add virtual devices:%s\n",
dpvs_strerror(err));
如果没用到 bond 那么忽略
if ((err = dpvs_timer_init()) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "Fail init timer on %s\n", dpvs_strerror(err));
dpvs 定时器初始化,实际上每个核都有自己的定时器,每个核调用 timer_lcore_init 初始化
if ((err = tc_init()) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "Fail to init traffic control: %s\n",
dpvs_strerror(err));
traffic control 流控初始化,这块也是重点,之后单独说
if ((err = netif_init(NULL)) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "Fail to init netif: %s\n", dpvs_strerror(err));
/* Default lcore conf and port conf are used and may be changed here
* with "netif_port_conf_update" and "netif_lcore_conf_set" */
netif_init 是初始化核心点,核心处理函数在这里注册
if ((err = ctrl_init()) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "Fail to init ctrl plane: %s\n",
dpvs_strerror(err));
if ((err = tc_ctrl_init()) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "Fail to init tc control plane: %s\n",
dpvs_strerror(err));
control plane 交互初始化,通过本地 socket file 交互
if ((err = vlan_init()) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "Fail to init vlan: %s\n", dpvs_strerror(err));
vlan 初始化
if ((err = inet_init()) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "Fail to init inet: %s\n", dpvs_strerror(err));
tcp4 初始化,核心处理函数在这里注册
if ((err = sa_pool_init()) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "Fail to init sa_pool: %s\n", dpvs_strerror(err));
sa fdir 初始化,这里也是重点,后文单独讲
if ((err = ip_tunnel_init()) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "Fail to init tunnel: %s\n", dpvs_strerror(err));
tunnel 初始化,仅在 tunnel 转发模式下才用
if ((err = dp_vs_init()) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "Fail to init ipvs: %s\n", dpvs_strerror(err));
dp_vs_init 初始化原 lvs 层的功能
if ((err = netif_ctrl_init()) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "Fail to init netif_ctrl: %s\n",
dpvs_strerror(err));
netif 交互控制初始化
/* config and start all available dpdk ports */
// 这里的 dpdk port 就是网卡的意思
nports = rte_eth_dev_count(); //rte runtime environment
for (pid = 0; pid < nports; pid++) {
dev = netif_port_get(pid);
if (!dev) {
RTE_LOG(WARNING, DPVS, "port %d not found\n", pid);
continue;
}
err = netif_port_start(dev);
if (err != EDPVS_OK)
RTE_LOG(WARNING, DPVS, "Start %s failed, skipping ...\n",
dev->name);
}
dpdk 开启网卡,开始提供服务
/* start data plane threads */
netif_lcore_start();
netif_lcore_start 开始正式提供服务,看下代码实现
int netif_lcore_start(void)
{
rte_eal_mp_remote_launch(netif_loop, NULL, SKIP_MASTER); // 在每一个 slave lcore 上执行 netif_loop
return EDPVS_OK;
}
rte_eal_mp_remote_launch 表示在每个 slave 核心调用 netif_loop 进入死循环,假如机器有 32 个核,那么相当于有 32 个绑定到每个核的线程在运行。
netif_loop源码分析
static int netif_loop(void *dummy)
{
struct netif_lcore_loop_job *job;
lcoreid_t cid = rte_lcore_id(); // 获取当前 lcore id
// 调试,记录运行时间长的任务
#ifdef CONFIG_RECORD_BIG_LOOP
char buf[512];
uint32_t loop_time;
uint64_t loop_start, loop_end;
#endif
assert(LCORE_ID_ANY != cid);
// 某个核可能专用来收取包,死循环,如果没有配置那么继续
try_isol_rxq_lcore_loop();
if (0 == lcore_conf[lcore2index[cid]].nports) { // 没有对应的网卡
RTE_LOG(INFO, NETIF, "[%s] Lcore %d has nothing to do.\n", __func__, cid);
return EDPVS_IDLE;
}
// 先运行每个核上的 NETIF_LCORE_JOB_INIT 初始化任务
list_for_each_entry(job, &netif_lcore_jobs[NETIF_LCORE_JOB_INIT], list) {
do_lcore_job(job);
}
while (1) {
#ifdef CONFIG_RECORD_BIG_LOOP
loop_start = rte_get_timer_cycles();
#endif
lcore_stats[cid].lcore_loop++;
// 运行所有 NETIF_LCORE_JOB_LOOP 类型的任务
list_for_each_entry(job, &netif_lcore_jobs[NETIF_LCORE_JOB_LOOP], list) {
do_lcore_job(job);
}
++netif_loop_tick[cid];
// 慢速任务 NETIF_LCORE_JOB_SLOW 每隔一定时间才会运行
list_for_each_entry(job, &netif_lcore_jobs[NETIF_LCORE_JOB_SLOW], list) {
if (netif_loop_tick[cid] % job->skip_loops == 0) {
do_lcore_job(job);
//netif_loop_tick[cid] = 0;
}
}
// 记录运行时间长的任务
#ifdef CONFIG_RECORD_BIG_LOOP
loop_end = rte_get_timer_cycles();
loop_time = (loop_end - loop_start) * 1E6 / cycles_per_sec;
if (loop_time > longest_lcore_loop[cid]) {
RTE_LOG(WARNING, NETIF, "update longest_lcore_loop[%d] = %d (<- %d)\n",
cid, loop_time, longest_lcore_loop[cid]);
longest_lcore_loop[cid] = loop_time;
}
if (loop_time > BIG_LOOP_THRESH) {
print_job_time(buf, sizeof(buf));
RTE_LOG(WARNING, NETIF, "lcore[%d] loop over %d usecs (actual=%d, max=%d):\n%s\n",
cid, BIG_LOOP_THRESH, loop_time, longest_lcore_loop[cid], buf);
}
#endif
}
return EDPVS_OK;
}
- 首先判断当前核心 lcore, 是否用来专职接收数据,如果是,那么 try_isol_rxq_lcore_loop 会死循环,下面不会执行。
- 运行初始化任务 NETIF_LCORE_JOB_INIT
- 进入 while 大循环,分别执行 NETIF_LCORE_JOB_LOOP, NETIF_LCORE_JOB_SLOW 类型任务。
- 如果某个循环耗时长,那么记录下来。
JOB注册
上面提到运行不同类型的 JOB,那么是在哪里注册的呢?回头看初始化函数 netif_init
int netif_init(const struct rte_eth_conf *conf)
{
cycles_per_sec = rte_get_timer_hz(); // hz
netif_pktmbuf_pool_init(); // 每个 numa 节点创建一个 mbuf pool, mbuf 类似 kernel skb_buffer
netif_arp_ring_init();
netif_pkt_type_tab_init();
netif_lcore_jobs_init();
// use default port conf if conf=NULL
netif_port_init(conf);
netif_lcore_init();
return EDPVS_OK;
}
netif_pktmbuf_pool_init 初始化 pkt pool 内存池,netif_arp_ring_init 二层数据包环形数组初始化,netif_pkt_type_tab_init inet 处理类型初始化,netif_lcore_jobs_init 初始化 jobs 数组,重点讲解另外两个 netif_port_init, netif_lcore_init
/* Allocate and register all DPDK ports available */
// dpdk 中所谓的 DPDK PORT 就是网卡的意思,这么叫真的很别扭
inline static void netif_port_init(const struct rte_eth_conf *conf)
{
int nports, nports_cfg;
portid_t pid;
struct netif_port *port;
struct rte_eth_conf this_eth_conf;
char *kni_name;
// 获取网卡个数
nports = rte_eth_dev_count();
if (nports <= 0)
rte_exit(EXIT_FAILURE, "No dpdk ports found!\n"
"Possibly nic or driver is not dpdk-compatible.\n");
// 物理网卡+bonding虚拟网卡,如果个数不一致,说明 dpdk rte 没有检测到 bonding 网卡,有失败地方
nports_cfg = list_elems(&port_list) + list_elems(&bond_list);
if (nports_cfg < nports)
rte_exit(EXIT_FAILURE, "ports in DPDK RTE (%d) != ports in dpvs.conf(%d)\n",
nports, nports_cfg);
port_tab_init();
port_ntab_init();
if (!conf)
conf = &default_port_conf;
this_eth_conf = *conf;
rte_kni_init(NETIF_MAX_KNI); // 初始化 kernel nic interface
kni_init();
for (pid = 0; pid < nports; pid++) {
/* queue number will be filled on device start */
port = netif_rte_port_alloc(pid, 0, 0, &this_eth_conf);
if (!port)
rte_exit(EXIT_FAILURE, "Port allocate fail, exiting...\n");
if (netif_port_register(port) < 0)
rte_exit(EXIT_FAILURE, "Port register fail, exiting...\n");
}
if (relate_bonding_device() < 0)
rte_exit(EXIT_FAILURE, "relate_bonding_device fail, exiting...\n");
/* auto generate KNI device for all build-in
* phy ports and bonding master ports, but not bonding slaves */
for (pid = 0; pid < nports; pid++) {
port = netif_port_get(pid);
assert(port);
// 每个网卡还要增加 kni 网卡接口,比如原来是 dpdk0, 那么 kni 就叫 dpdk0.kni
if (port->type == PORT_TYPE_BOND_SLAVE)
continue;
kni_name = find_conf_kni_name(pid);
/* it's ok if no KNI name (kni_name is NULL) */
if (kni_add_dev(port, kni_name) < 0)
rte_exit(EXIT_FAILURE, "add KNI port fail, exiting...\n");
}
}
- 获取网卡个数
- 初始化 kni 模块,用于将不关心的网络数据包透传到内核
- 注册网卡
- 注册生成 kni 网卡,每个网卡还要增加 kni 网卡接口,比如原来是 dpdk0, 那么 kni 就叫 dpdk0.kni
static void netif_lcore_init(void)
{
int ii, res;
lcoreid_t cid;
timer_sched_interval_us = dpvs_timer_sched_interval_get();
for (cid = 0; cid < DPVS_MAX_LCORE; cid++) {
if (rte_lcore_is_enabled(cid))
RTE_LOG(INFO, NETIF, "%s: lcore%d is enabled\n", __func__, cid);
else
RTE_LOG(INFO, NETIF, "%s: lcore%d is disabled\n", __func__, cid);
}
/* build lcore fast searching table */
lcore_index_init();
/* init isolate rxqueue table */
isol_rxq_init();
/* check and set lcore config */
config_lcores(&worker_list);
if ((res = check_lcore_conf(rte_lcore_count(), lcore_conf)) != EDPVS_OK)
rte_exit(EXIT_FAILURE, "[%s] bad lcore configuration (err=%d),"
" exit ...\n", __func__, res);
/* build port fast searching table */
port_index_init();
/* register lcore jobs*/
snprintf(netif_jobs[0].name, sizeof(netif_jobs[0].name) - 1, "%s", "recv_fwd");
netif_jobs[0].func = lcore_job_recv_fwd; // 接收并转发到后端
netif_jobs[0].data = NULL;
netif_jobs[0].type = NETIF_LCORE_JOB_LOOP;
snprintf(netif_jobs[1].name, sizeof(netif_jobs[1].name) - 1, "%s", "xmit");
netif_jobs[1].func = lcore_job_xmit; // 将接收过来的,发送出去
netif_jobs[1].data = NULL;
netif_jobs[1].type = NETIF_LCORE_JOB_LOOP;
snprintf(netif_jobs[2].name, sizeof(netif_jobs[2].name) - 1, "%s", "timer_manage");
netif_jobs[2].func = lcore_job_timer_manage;
netif_jobs[2].data = NULL;
netif_jobs[2].type = NETIF_LCORE_JOB_LOOP;
for (ii = 0; ii < NETIF_JOB_COUNT; ii++) {
res = netif_lcore_loop_job_register(&netif_jobs[ii]);
if (res < 0) {
rte_exit(EXIT_FAILURE,
"[%s] Fail to register netif lcore jobs, exiting ...\n", __func__);
break;
}
}
}
-
lcore_index_init建立一个快查表,将 lcore 映射一个索引 -
isol_rxq_init如果配置了某个核专职接收数据包,那么初始化 -
port_index_init建立一个快查表,将网卡映射一个索引 - 注册 NETIF_LCORE_JOB_LOOP 任务,我们看到有三个
lcore_job_recv_fwd,lcore_job_xmit,lcore_job_timer_manage,这是三个核心函数,分别负责接收并转发数据包,发送网卡数据包和定时器管理。
小结
联系上下文,我们知道,dpvs 最终每个 slave 核运行死循环,一直运行 lcore_job_recv_fwd,lcore_job_xmit, lcore_job_timer_manage 处理数据,然后 master 核会专职运行 main 函数 while 大循环做其它非核心业务处理。从这里也可以看到,dpvs 抛弃了传统网卡的 中断+轮循模式,而是只采用轮循。具体 dpvs 如何转发数据包,各种模式的细节再慢慢分析。